Category: Amazon Kinesis
Process Streaming Data with Kinesis and Elastic MapReduce
Regular readers of this blog already know that Amazon Kinesis is a fully managed service for real-time processing of streaming data at massive scale.
As I noted last month when we introduced the Kinesis Storm Spout, Kinesis is but one component of a complete end-to-end streaming data application. In order to build such an application, you can use the Kinesis Client Library for load-balancing of streaming data and coordination of distributed services and the Kinesis Connector Library to communicate with other data storage and processing services.
New EMR Connector to Kinesis
Today we are adding an Elastic MapReduce Connector to Kinesis. With this connector, you can analyze streaming data using familiar Hadoop tools such as Hive, Pig, Cascading, and Hadoop Streaming. If you build the analytical portion of your streaming data application around the combination of Kinesis and Amazon Elastic MapReduce, you will benefit from the fully managed nature of both services. You won’t have to worry about building deploying, or maintaining the infrastructure needed to do real-time processing at world-scale. This connector is available in version 3.0.4 of the Elastic MapReduce AMI.
Here’s how all of the pieces mentioned above fit together:
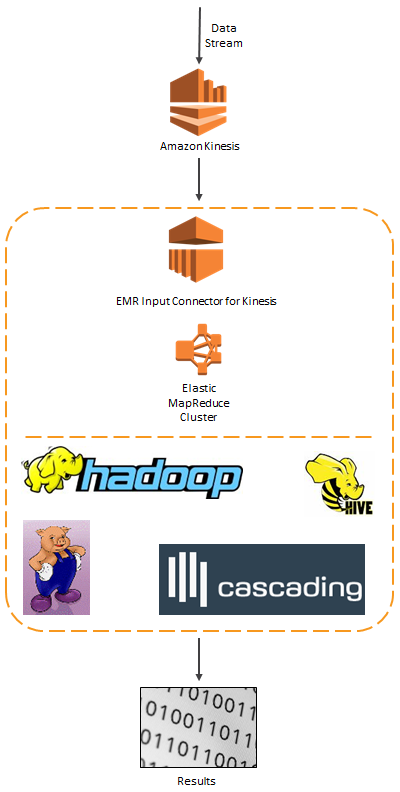
Interesting Use Cases
So, what can you do with this pair of powerful services? Here are a few ideas to get you started:
On the IT side, you can analyze your log files to generate operational intelligence. Stream your web logs into Kinesis, analyze them every few minutes, and generate a Top 10 error list broken down by region and page.
On the business side, you can join Kinesis stream with data stored in S3, DynamoDB tables, and HDFS to drive comprehensive data workflows. For example, you can write queries that join clickstream data from Kinesis with advertising campaign information stored in a DynamoDB table to identify the most effective categories of ads that are displayed on particular websites.
You can also use Elastic MapReduce to filter or pre-process incoming data before you store it (perhaps in Amazon DynamoDB, Amazon S3, or Amazon Redshift) for further analysis. Perhaps you need to exclude certain record types, perform some preliminary calculations, or aggregate multiple records.
Finally, you can run ad-hoc queries on data flowing through a Kinesis stream. You can form and test out queries before embedding them in your code. You can periodically load draft from Kinesis into HDFS and make it available as a local Impala table for fast, interactive analytic queries.
You have two different options when it comes to running your queries:
First, you can perform incremental queries. In this case the connector tracks the starting and ending records in each shard, returning only newly available records in each batch. The checkpoint information is stored in Amazon DynamoDB. A unique iteration number is assigned to each batch in order to simplify downstream processing.
Alternatively, you can disable the checkpointing behavior and query the entire stream. This will give you access to all of the data present in the stream. This query gives you a sliding window into the last 24 hours (the duration that data persists in Kinesis).
Mapping Streams to Tables in Hive
If you are using Hive to process data that arrives via Kinesis, your table definition can reference a Kinesis stream by ending it as follows:
STORED BY
'com.amazon.emr.kinesis.hive.KinesisStorageHandler'
TBLPROPERTIES("kinesis.stream.name"="AccessLogStream");
You can create Hive tables for multiple streams and then join them in the usual way. If checkpointing is enabled, these queries will process data corresponding to the same iteration number and logical name from both of the tables.
Kinesis Log4J Appender
If you are interested in pushing large amounts of log-style data into Kinesis, I encourage you to take a look at the Kinesis Log4J Appender (download the jar). We have developed a Log4J Appender implementation that makes it easy to continuously push log directly to a Kinesis stream. You can use it, along with the new connector described in this blog post, to implement the following processing model:
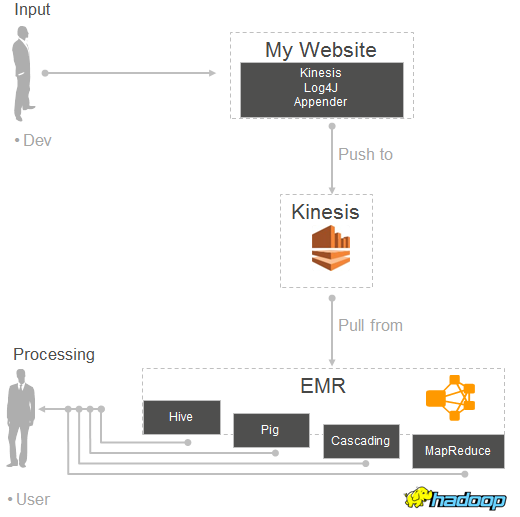
Getting Started
If you are already familiar with Elastic MapReduce and Hadoop, you can put your hard-won skills to good use at once by reading our new Streaming Data Analysis Tutorials. If not, you’ll want to study the Kinesis Getting Started Guide and the Word Count example in the Elastic MapReduce documentation.
To learn more about this feature, read the new Analyze Real-Time Data from Kinesis Streams chapter of the Elastic MapReduce documentation. The Elastic MapReduce FAQ has also been updated and should also be helpful.
— Jeff;
Marry Amazon Kinesis and Storm Using the New Kinesis Storm Spout
Amazon Kinesis is a fully managed service for real-time processing of streamed data at massive scale. When we launched Kinesis in November of 2013, we also introduced the Kinesis Client Library. You can use the client library to build applications that process streaming data. It will handle complex issues such as load-balancing of streaming data, coordination of distributed services, while adapting to changes in stream volume, all in a fault-tolerant manner.
Kinesis Connector Library
In many streaming data applications, Kinesis is an important central component, but just one component nevertheless. We know that many developers want to consume and process incoming streams using a variety of other AWS and non-AWS services.
In order to meet this need, we released the Kinesis Connector Library late last year with support for Amazon DynamoDB, Amazon Redshift, and Amazon S3.
Today we are expanding the Kinesis Connector Library with support for the popular Storm real-time computation system. We call this new offering the Kinesis Storm Spout!
All About Storm
A Storm cluster processes streaming messages on a continuous basis. Individual logical processing units (Bolts in Storm terminology) are connected together in pipeline fashion to express the series of transformations steps while also exposing opportunities for concurrent processing.
A Storm’s stream is sourced by a Spout. Each Spout emits one or more sequences of tuples into a cluster for processing. A given Bolt can consume any number of input streams, process the data, and emit transformed tuples. A Topology is a multi-stage distributing computation composed of a network of Spouts and Bolts. A Topology (which you can think of as a full application) runs continuously in order to process incoming data.
Kinesis and Storm
The new Kinesis Storm Spout routes data from Kinesis to a Storm cluster for processing.
In the illustration below, Spout A is an example of a Kinesis Storm Spout wired to consume a data record from the Kinesis stream and emit a tuple into the Storm Cluster. Constructing the Spout only requires pointing to the Kinesis Stream, the Zookeeper configuration and AWS credentials to access the stream.
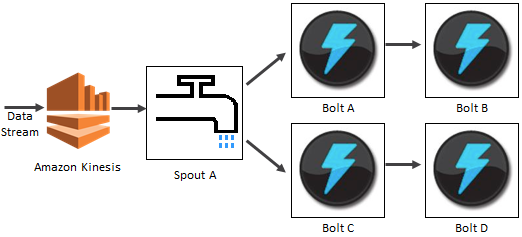
Getting Started
Your Java code has three duties:
- Constructing the Kinesis Storm Spout
- Setting up the Storm Topology
- Submitting the Topology to the Storm cluster
Here’s how you construct the Kinesis Storm Spout:
final KinesisSpoutConfig config =
new KinesisSpoutConfig(streamName, zookeeperEndpoint)
.withZookeeperPrefix(zookeeperPrefix)
.withInitialPositionInStream(initialPositionInStream);
final KinesisSpout spout =
new KinesisSpout(config, new CustomCredentialsProviderChain(), new ClientConfiguration());
The Kinesis Spout implements Storms IRichSpout, and is constructed by just specifying the stream name, Zookeper configs and your AWS credentials. Note that a Storm Spout is expected to push one record at a time when the nextTuple API is called. However, the Kinesis GetRecords API call is optimized to get a batch of records. The Kinesis Spout buffers a batch of records internally, and emits one tuple at a time.
Here’s how you create a topology with one Kinesis Spout (2 parallel tasks) and one Storm Bolt (2 parallel tasks). Note that they are connected using Storm’s field grouping feature. This feature supports routing of tuples to specific tasks based on the value found in a particular field.
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kinesis_spout", spout, 2);
builder.setBolt("print_bolt",
new SampleBolt(), 2).fieldsGrouping("kinesis_spout",
new Fields(DefaultKinesisRecordScheme.FIELD_PARTITION_KEY));
And here’s how you submit the topology to your Storm cluster to begin processing the Kinesis stream:
StormSubmitter.submitTopology(topologyName, topoConf, builder.createTopology());
You will have to package up the compiled form of the code above and all of the dependencies in (including Kinesis Storm Spout) into a single JAR file. This file must also include the sample.properties and AWSCredentials.properties files.
The Kinesis Storm Spout is available on GitHub now and you can start using it today.
— Jeff;
Amazon Kinesis – Public Beta Now Open
 We announced a limited preview of Amazon Kinesis last month at AWS re:Invent. If you aren’t familiar with Kinesis, take a quick look at my recent post, Amazon Kinesis – Real-Time Processing of Streaming Big Data, to learn more.
We announced a limited preview of Amazon Kinesis last month at AWS re:Invent. If you aren’t familiar with Kinesis, take a quick look at my recent post, Amazon Kinesis – Real-Time Processing of Streaming Big Data, to learn more.
I am pleased to announce that Kinesis is now available in public beta form, and that you can start using it today.
With the launch of the public beta we are also adding support for the CORS (Cross-Origin Resource Sharing) standard developed by the W3C. This means that JavaScript running in a web browser can put data into Amazon Kinesis directly, potentially eliminating the need for an intermediate layer of proxy servers for certain use cases.
Here are a pair of re:Invent presentations that will tell you a lot more than I can. First, General Manager Ryan Waite introduces Kinesis:
Next, VP & Distinguished Engineer Marvin Theimer goes in to detail:
We have plenty of documentation to get you started including a full set of Frequently Asked Questions (FAQ). You can start with the Kinesis Developer Guide (PDF):

And then dive in to the Kinesis API Reference (PDF):

I’m looking forward to seeing some cool Kinesis apps emerge in the near future. Let me know what you come up with!
— Jeff;
Amazon Kinesis – Real-Time Processing of Streaming Big Data
 Imagine a situation where fresh data arrives in a continuous stream, 24 hours a day, 7 days a week. You need to capture the data, process it, and turn it into actionable conclusions as soon as possible, ideally within a matter of seconds. Perhaps the data rate or the compute power required for the analytics varies by an order of magnitude over time. Traditional batch processing techniques are not going to do the job.
Imagine a situation where fresh data arrives in a continuous stream, 24 hours a day, 7 days a week. You need to capture the data, process it, and turn it into actionable conclusions as soon as possible, ideally within a matter of seconds. Perhaps the data rate or the compute power required for the analytics varies by an order of magnitude over time. Traditional batch processing techniques are not going to do the job.
Amazon Kinesis is a managed service designed to handle real-time streaming of big data. It can accept any amount of data, from any number of sources, scaling up and down as needed.
You can use Kinesis in any situation that calls for large-scale, real-time data ingestion and processing. Logs for servers and other IT infrastructure, social media or market data feeds, web clickstream data, and the like are all great candidates for processing with Kinesis.
Let’s dig into Kinesis now…
Important Concepts
 Your application can create any number of Kinesis streams to reliably capture, store and transport data. Streams have no intrinsic capacity or rate limits. All incoming data is replicated across multiple AWS Availability Zones for high availability. Each stream can have multiple writers and multiple readers.
Your application can create any number of Kinesis streams to reliably capture, store and transport data. Streams have no intrinsic capacity or rate limits. All incoming data is replicated across multiple AWS Availability Zones for high availability. Each stream can have multiple writers and multiple readers.
When you create a stream you specify the desired capacity in terms of shards. Each shard has the ability to handle 1000 write transactions (up to 1 megabyte per second — we call this the ingress rate) and up to 5 read transactions (up to 2 megabytes per second — the egress rate). You can scale a stream up or down at any time by adding or removing shards without affecting processing throughput or incurring any downtime, with new capacity ready to use within seconds. Pricing (which I will cover in depth in just a bit) is based on the number of shards in existence and the number of writes that you perform.
The Kinesis client library is an important component of your application. It handles the details of load balancing, coordination, and error handling. The client library will take care of the heavy lifting, allowing your application to focus on processing the data as it becomes available.
Applications read and write data records to streams. Records can be up to 50 Kilobytes in length and are comprised of a partition key and a data blob, both of which are treated as immutable sequences of bytes. The record’s partition determines which shard will handle the data blob; the data blob itself is not inspected or altered in any way. A sequence number is assigned to each record as part of the ingestion process. Records are automatically discarded after 24 hours.
The Kinesis Processing Model
The “producer side” of your application code will use the PutRecord function to store data in a stream, passing in the stream name, the partition key, and the data blob. The partition key is hashed using an MD5 hashing function and the resulting 128-bit value will be used to select one of the shards in the stream.
The “consumer” side of your application code reads through data in a shard sequentially. There are two steps to start reading data. First, your application uses GetShardIterator to specify the position in the shard from which you want to start reading data. GetShardIterator gives you the following options for where to start reading the stream:
- AT_SEQUENCE_NUMBER to start at given sequence number.
- AFTER_SEQUENCE_NUMBER to start after a given sequence number.
- TRIM_HORIZON to start with the oldest stored record.
- LATEST to start with new records as they arrive.
Next, your application uses GetNextRecords to retrieve up to 2 megabytes of data per second using the shard iterator. The easiest way to use GetNextRecords is to create a loop that calls GetNextRecords repeatedly to get any available data in the shard. These interfaces are, however, best thought of as a low-level interfaces; we expect most applications to take advantage of the higher-level functions provided by the Kinesis client library.
The client library will take care of a myriad of details for you including fail-over, recovery, and load balancing. You simply provide an implementation of the IRecordProcessor interface and the client library will “push” new records to you as they become available. This is the easiest way to get started using Kinesis.
After processing the record, your consumer code can pass it along to another Kinesis stream, write it to an Amazon S3 bucket, a Redshift data warehouse, or a DynamoDB table, or simply discard it.
Scaling and Sharding
You are responsible for two different aspects of scalability – processing and sharding. You need to make sure that you have enough processing power to keep up with the flow of records. You also need to manage the number of shards.
Let’s start with the processing aspect of scalability. The easiest way to handle this responsibility is to implement your Kinesis application with the Kinesis client library and to host it on an Amazon EC2 instance within an Auto Scaling group. By setting the minimum size of the group to 1 instance, you can recover from instance failure. Set the maximum size of the group to a sufficiently high level to ensure plenty of headroom for scaling activities. If your processing is CPU-bound, you will want to scale up and down based on the CloudWatch CPU Utilization metric. On the other hand, if your processing is relatively lightweight, you may find that scaling based on Network Traffic In is more effective.
Ok, now on to sharding. You should create the stream with enough shards to accommodate the expected data rate. You can then add or delete shards as the rate changes. The APIs for these operations are SplitShard and MergeShards, respectively. In order to use these operations effectively you need to know a little bit more about how partition keys work.
As I have already mentioned, your partition keys are run through an MD5 hashing function to produce a 128-bit number, which can be in the range of 0 to 2127-1. Each stream breaks this interval into one or more contiguous ranges, each of which is assigned to a particular shard.
Let’s start with the simplest case, a stream with a single shard. In this case, the entire interval maps to a single shard. Now, things start to heat up and you begin to approach the data handling limit of a single shard. It is time to scale up! If you are confident that the MD5 hash of your partition keys results in values that are evenly distributed across the 128-bit interval, then you can simply split the first shard in the middle. It will be responsible for handling values from 0 to 2126-1, and the new shard will be responsible for values from 2126 to 2127-1.
Reality is never quite that perfect, and it is possible that the MD5 hash of your partition keys isn’t evenly distributed. In this case, splitting the partition down the middle would be a sub-optimal decision. Instead, you (in the form of your sharding code) would like to make a more intelligent decision, one that takes the actual key distribution into account. To do this properly, you will need to track the long-term distribution of hashes with respect to the partitions, and to split the shards accordingly.
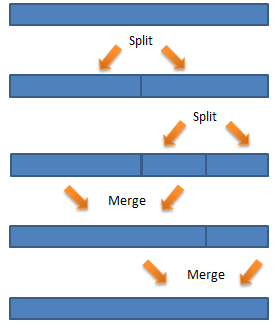
You can reduce your operational costs by merging shards when traffic declines. You can merge adjacent shards; again, an intelligent decision will maintain good performance and low cost. Here’s a diagram of one possible sequence of splits and merges over time:
Kinesis Pricing
Kinesis pricing is simple: you pay for PUTs and for each shard of throughput capacity. Lets assume that you have built a game for mobile devices and you want to track player performance, top scores, and other metrics associated with your game in real-time so that you can update top score dashboards and more.
Lets also assume that each mobile device will send a 2 kilobyte message every 5 seconds and that at peak youll have 10,000 devices simultaneously sending messages to Kinesis. You can scale up and down the size of your stream, but for simplicity lets assume its a constant rate of data.
Use this data to calculate how many Shards of capacity youll need to ingest the incoming data. The Kinesis console helps you estimate using a wizard, but lets do the math here. 10,000 (PUTs per second) * 2 kilobytes (per PUT) = 20 megabytes per second. You will need 20 Shards to process this stream of data.
Kinesis uses simple pay as you go pricing. You pay $0.028 per 1,000,000 PUT operations and you pay $0.015 per shard per hour. For one hour of collecting game data youd pay $0.30 for the shards and about $1.01 for the 36 million PUT calls, or $1.31.
Kinesis From the Console
You can create and manage Kinesis streams using the Kinesis APIs, the AWS CLI, and the AWS Management Console. Here’s a brief tour of the console support.
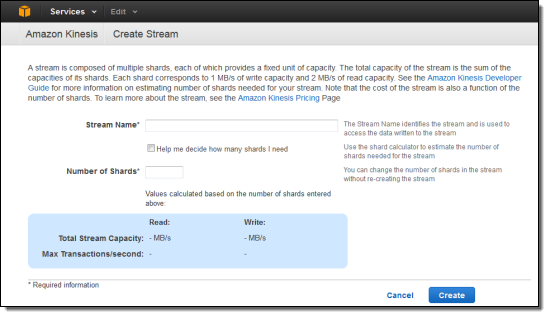
Click on the Create Stream button to get started. You need only enter a stream name and the number of shards to get started:
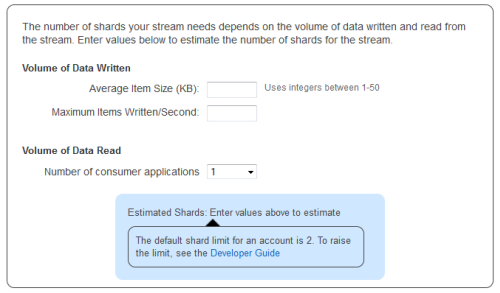
The console includes a calculator to help you estimate the number of shards you need:
You can see all of your streams at a glance:
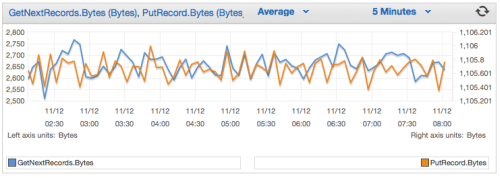
And you can view the CloudWatch metrics for each stream:
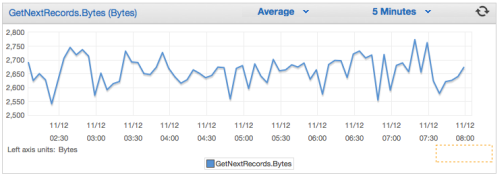
Getting Started
Amazon Kinesis is available in limited preview and you can request access today.
— Jeff;