Category: Amazon Rekognition
AWS GovCloud (US) and Amazon Rekognition – A Powerful Public Safety Tool
I’ve already told you about Amazon Rekognition and described how it uses deep neural network models to analyze images by detecting objects, scenes, and faces.
Today I am happy to tell you that Rekognition is now available in the AWS GovCloud (US) Region. To learn more, read the Amazon Rekognition FAQ, and the Amazon Rekognition Product Details, review the Amazon Rekognition Customer Use Cases, and then build your app using the information on the Amazon Rekognition for Developers page.
Motorola Solutions for Public Safety
While I have your attention, I would love to tell you how Motorola Solutions is exploring how Rekognition can enhance real-time intelligence for public safety personnel in the field and at the command center.
Motorola Solutions provides over 100,000 public safety and commercial customers in more than 100 countries with software, services, and tools for mobile intelligence and digital evidence management, many powered by images captured using body, dashboard, and stationary cameras. Due to the exceptionally sensitive nature of these images, they must be stored in an environment that meets stringent CJIS (Criminal Justice Information Systems) security standards defined by the FBI.
For several years, researchers at Motorola Solutions have been exploring the use of artificial intelligence. For example, they have built prototype applications that use Rekognition, Lex, and Polly in conjunction with their own software to scan images from a body-worn camera for missing persons and to raise alerts without requiring continuous human attention or interaction. With approximately 100,000 missing people in the US alone, law enforcement agencies need to bring powerful tools to bear. At re:Invent 2016, Dan Law (Chief Data Scientist for Motorola Solutions) described how they use AWS to aid in this effort. Here’s the video (Dan’s section is titled AI for Public Safety):
AWS and CJIS
The applications that Dan described can run in AWS GovCloud (US). This is an isolated cloud built to protect and preserve sensitive IT data while meeting the FBI’s CJIS requirements (and many others). AWS GovCloud (US) resides on US soil and is managed exclusively by US citizens. AWS routinely signs CJIS security agreements with our customers and can either perform or allow background checks on our employees, as needed.
Here are some resources that you can use to learn more about AWS and CJIS:
- AWS GovCloud (US) FAQ
- AWS CJIS Compliance
- AWS CJIS Compliance White Paper
- AWS CJIS Addendums for US States and Cities
- AWS CJIS Workbook (Excel spreadsheet)
— Jeff;
Amazon Rekognition Update – Celebrity Recognition
We launched Amazon Rekognition at re:Invent (Amazon Rekognition – Image Detection and Recognition Powered by Deep Learning) and added Image Moderation earlier this year.
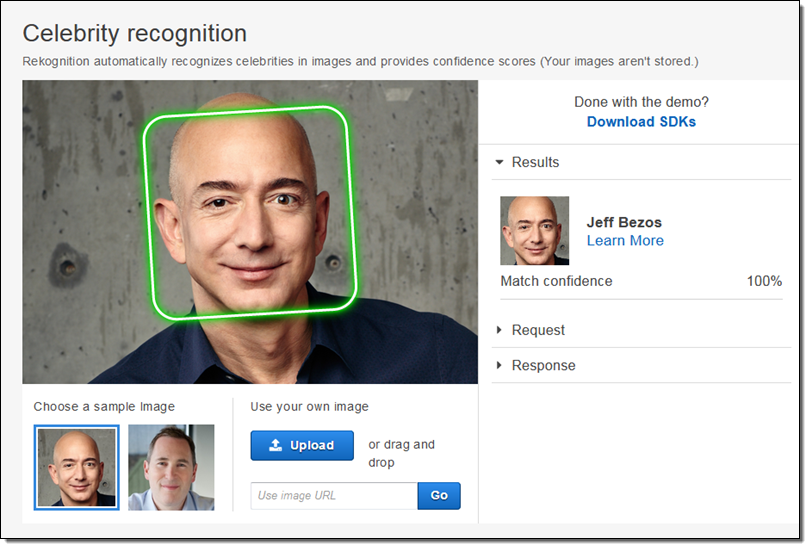
Today we are adding celebrity recognition!
Rekognition has been trained to identify hundreds of thousands of people who are famous, noteworthy, or prominent in fields that includes politics, sports, entertainment, business, and media. The list is global, and is updated frequently.
To access this feature, simply call the new RecognizeCelebrities function. In addition to the bounding box and facial landmark feature returned by the existing DetectFaces function, the new function returns information about any celebrities that it recognizes:
The Urls provide additional information about the celebrity. The API currently return links to IMDB content; we may add other sources in the future.
You can use the Celebrity Recognition Demo in the AWS Management Console to experiment with this feature:
 If you have an image archive you can now index it by celebrity. You could also use a combination of celebrity recognition and object detection to build all kinds of search tools. If your images are already stored in S3, you can process them in-place.
If you have an image archive you can now index it by celebrity. You could also use a combination of celebrity recognition and object detection to build all kinds of search tools. If your images are already stored in S3, you can process them in-place.
I’m sure that you will come up with all sorts of interesting uses for this new feature. Leave me a comment and let me know what you build!
— Jeff;
Amazon Rekognition Update – Image Moderation
We launched Amazon Rekognition late last year and I told you about it in my post Amazon Rekognition – Image Detection and Recognition Powered by Deep Learning. As I explained at the time, this service was built by our Computer Vision team over the course of many years and analyzes billions of images daily.
Today we are adding image moderation to Rekognition. If your web site or application allows users to upload profile photos or other imagery, you will love this new Rekognition feature.
Rekognition can now identify images that contain suggestive or explicit content that may not be appropriate for your site. The moderation labels provide detailed sub-categories, allowing you to fine-tune the filters that you use to determine what kinds of images you deem acceptable or objectionable. You can use this feature to improve photo sharing sites, forums, dating apps, content platforms for children, e-commerce platforms and marketplaces, and more.
To access this feature, call the DetectModerationLabels function from your code. The response will include a set of moderation labels drawn from a built-in taxonomy:
You can use the Image Moderation Demo in the AWS Management Console to experiment with this feature:
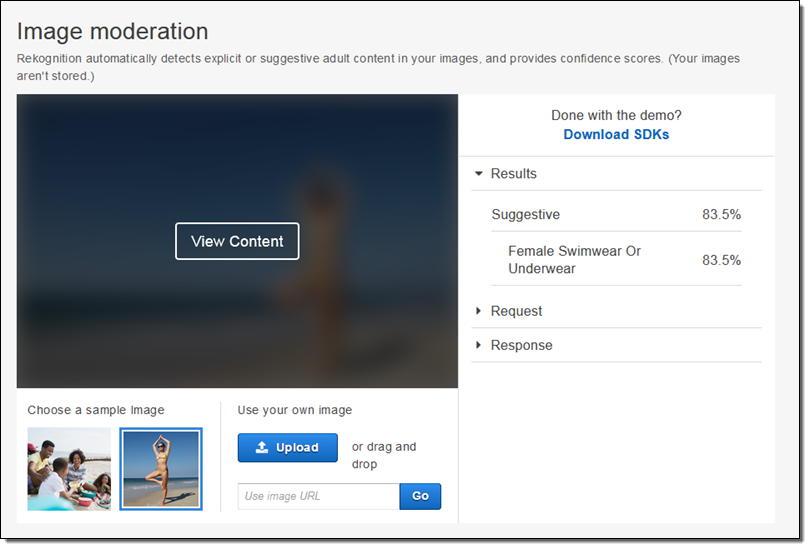
Image moderation is available now and you can start using it today!
— Jeff;
Amazon Rekognition Update – Estimated Age Range for Faces
Amazon Rekognition is one of our artificial intelligence services. In addition to detecting objects, scenes, and faces in images, Rekognition can also search and compare faces. Behind the scenes, Rekognition uses deep neural network models to analyze billions of images daily (read Amazon Rekognition – Image Detection and Recognition Powered by Deep Learning to learn more).
Amazon Rekognition returns an array of attributes for each face that it locates in an image. Today we are adding a new attribute, an estimated age range. This value is expressed in years, and is returned as a pair of integers. The age ranges can overlap; the face of a 5 year old might have an estimated range of 4 to 6 but the face of a 6 year old might have an estimated range of 4 to 8. You can use this new attribute to power public safety applications, collect demographics, or to assemble a set of photos that span a desired time frame.
In order to have some fun with this new feature (I am writing this post on a Friday afternoon), I dug into my photo archives and asked Rekognition to estimate my age. Here are the results.
Let’s start at the beginning! I was probably about 2 years old here:

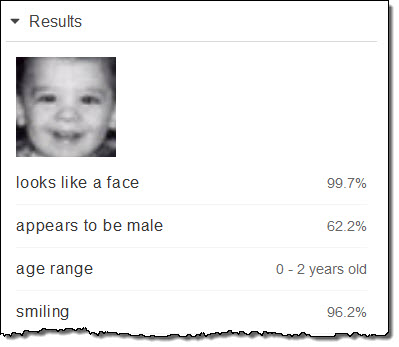
This picture was taken at my grandmother’s house in the spring of 1966:

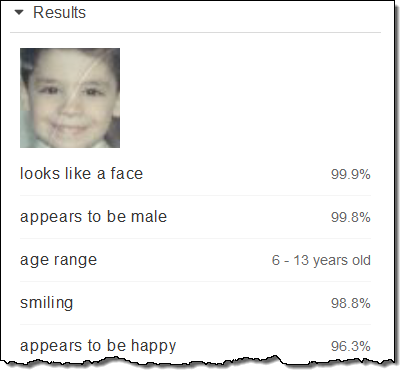
I was 6 years old; Rekognition estimated that I was between 6 and 13:
My first official Amazon PR photo from 2003 when I was 43:

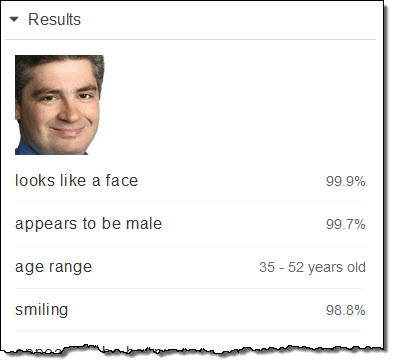
That’s a range of 17 years and my actual age was right in the middle.
And my most recent (late 2015) PR photo, age 55:

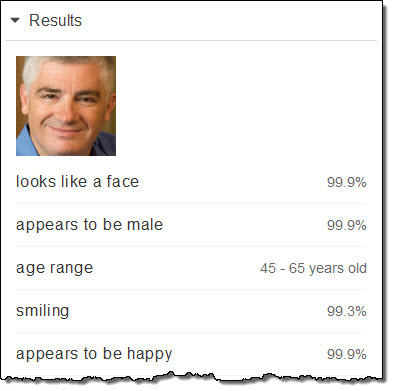
Again a fairly wide range, and I’m right in the middle of it! In general, Rekognition the actual age for each face will fall somewhere within the indicated range, but you should not count on it falling precisely in the middle.
This feature is available now and you can start using it today.
— Jeff;
Amazon Rekognition – Image Detection and Recognition Powered by Deep Learning
What do you see when you look at this picture?

You might simply see an animal. Maybe you see a pet, a dog, or a Golden Retriever. The association between the image and these labels is not hard-wired in to your brain. Instead, you learned the labels after seeing hundreds or thousands of examples. Operating on a number of different levels, you learned to distinguish an animal from a plant, a dog from a cat, and a Golden Retriever from other dog breeds.
Deep Learning for Image Detection
Giving computers the same level of comprehension has proven to be a very difficult task. Over the course of decades, computer scientists have taken many different approaches to the problem. Today, a broad consensus has emerged that the best way to tackle this problem is via deep learning. Deep learning uses a combination of feature abstraction and neural networks to produce results that can be (as Arthur C. Clarke once said) indistinguishable from magic. However, it comes at a considerable cost. First, you need to put a lot of work into the training phase. In essence, you present the learning network with a broad spectrum of labeled examples (“this is a dog”, “this is a pet”, and so forth) so that it can correlate features in the image with the labels. This phase is computationally expensive due to the size and the multi-layered nature of the neural networks. After the training phase is complete, evaluating new images against the trained network is far easier. The results are traditionally expressed in confidence levels (0 to 100%) rather than as cold, hard facts. This allows you to decide just how much precision is appropriate for your applications.
Introducing Amazon Rekognition
Today I would like to tell you about Amazon Rekognition. Powered by deep learning and built by our Computer Vision team over the course of many years, this fully-managed service already analyzes billions of images daily. It has been trained on thousands of objects and scenes, and is now available for you to use in your own applications. You can use the Rekognition Demos to put the service through its paces before dive in and start writing code that uses the Rekognition API.
Rekognition was designed from the get-go to run at scale. It comprehends scenes, objects, and faces. Given an image, it will return a list of labels. Given an image with one or more faces, it will return bounding boxes for each face, along with attributes. Let’s see what it has to say about the picture of my dog (her name is Luna, by the way):
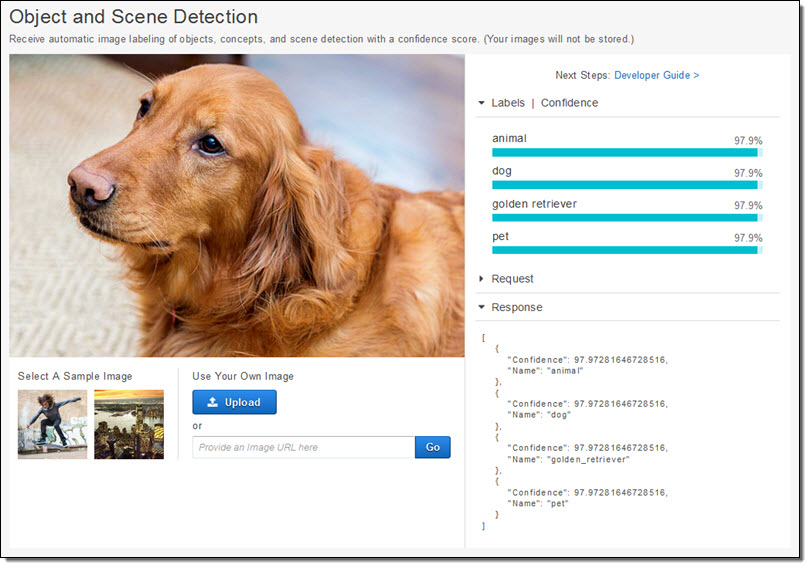
As you can see, Rekognition labeled Luna as an animal, a dog, a pet, and as a golden retriever with a high degree of confidence. It is important to note that these labels are independent, in the sense that the deep learning model does not explicitly understand the relationship between, for example, dogs and animals. It just so happens that both of these labels were simultaneously present on the dog-centric training material presented to Rekognition.
Let’s see how it does with a picture of my wife and I:
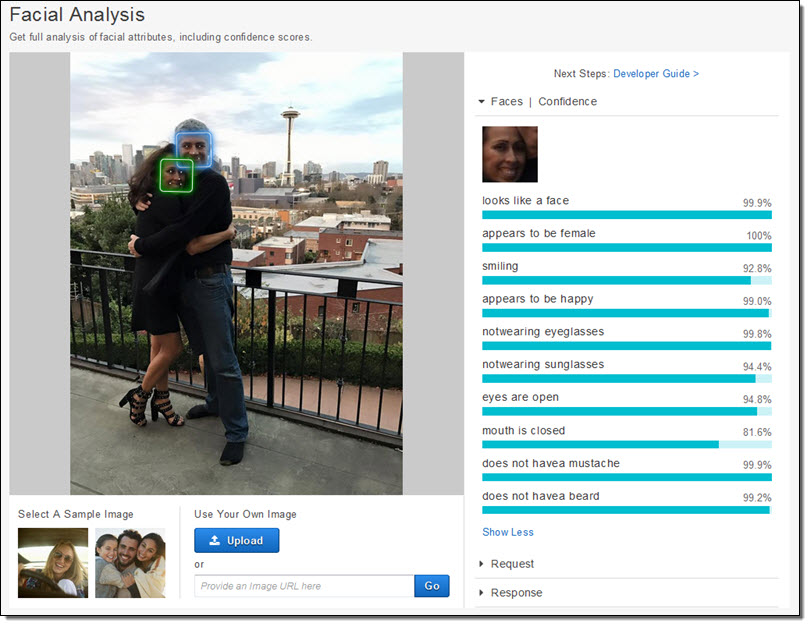
Amazon Rekognition found our faces, set up bounding boxes, and let me know that my wife was happy (the picture was taken on her birthday, so I certainly hope she was).
You can also use Rekognition to compare faces and to see if a given image contains any one of a number of faces that you have asked it to recognize.
All of this power is accessible from a set of API functions (the console is great for quick demos). For example, you can call DetectLabels to programmatically reproduce my first example, or DetectFaces to reproduce my second one. You can make multiple calls to IndexFaces to prepare Rekognition to recognize some faces. Each time you do this, Rekognition extracts some features (known as face vectors) from the image, stores the vectors, and discards the image. You can create one or more Rekognition collections and store related groups of face vectors in each one.
Rekognition can directly process images stored in Amazon Simple Storage Service (S3). In fact, you can use AWS Lambda functions to process newly uploaded photos at any desired scale. You can use AWS Identity and Access Management (IAM) to control access to the Rekognition APIs.
Applications for Rekognition
So, what can you use this for? I’ve got plenty of ideas to get you started!
If you have a large collection of photos, you can tag and index them using Amazon Rekognition. Because Rekognition is a service, you can process millions of photos per day without having to worry about setting up, running, or scaling any infrastructure. You can implement visual search, tag-based browsing, and all sorts of interactive discovery models.
You can use Rekognition in several different authentication and security contexts. You can compare a face on a webcam to a badge photo before allowing an employee to enter a secure zone. You can perform visual surveillance, inspecting photos for objects or people of interest or concern.
You can build “smart” marketing billboards that collect demographic data about viewers.
Now Available
Rekognition is now available in the US East (Northern Virginia), US West (Oregon), and EU (Ireland) Regions and you can start using it today. As part of the AWS Free Tier tier, you can analyze up to 5,000 images per month and store up to 1,000 face vectors each month for an entire year. After that (and at higher volume), you will pay tiered pricing based on the number of images that you analyze and the number of face vectors that you store.
Ready to learn even more? We have a webinar on December 13th. Register here.
— Jeff;