Amazon Web Services ブログ
Apache MXNetとApple Core MLを使った機械学習をiOSアプリケーションに組み込む
AppleのWWDC2017で発表されたCore MLを使えば、iOSやmacOS、watchOS、tvOSの開発者は、 自分のアプリケーションに機械学習モデルを簡単に統合することができるようになります。Core MLによって、開発者はほんの数行のコードを追加するだけで、インテリジェントな新しい機能をユーザに提供できるようになります。Core MLを使えば、モバイルアプリケーションの開発者が機械学習を簡単に利用出来るようになり、プロトタイプを素早く構築することが出来ますし、これまでのアプリよりもパワフルなアプリを開発するために、カメラやGPSなどの様々なセンサーを使用できるようにもなります。
MXNetコミュニティーのメンバー達(AppleやAWSの社員もcontributorとして活動しています)は、MXNetを使って作られた機械学習モデルをCore MLのフォーマットに変換するためのツールを作りました。このツールを使えば、 Appleのデバイス向けのアプリに機械学習を簡単に組み込むことが 出来ますし 、Deep Learningを組み込んだアプリケーションのための高速なパイプラインを手にすることになります。つまり、AWSクラウド上で スケーラブルかつ効率的に、MXNetを使用した分散モデルトレーニングを行なった結果を用いて,Apple デバイス上で高速な推論処理を行うことが可能となります。
この変換ツールのリリースをサポートするために、我々はcoolなiOSアプリケーションを構築することにしました。本アプリは、以前のAWS AI Blogの「AWS EC2上でのMXNetと Multimedia Commonsデータセットを用いた 画像の場所の推測」という投稿を参考にしています。この投稿では、LocationNetモデルを使って写真がどこで撮影されたのかを予測しています。
本記事では、MXNetのモデルからCore MLに変換するための環境の構築方法および、既存のモデルの変換方法 、変換したモデルをSwiftで開発したiOSアプリケーションにimportする方法について説明します。このアプリケーションは、写真の撮影場所を予測するモデルに写真を入力し、撮影場所をマップ上に表示します。実行環境としては、iOS 11 betaがインストールされたiPhoneなどの物理iOSデバイスをおすすめします。シミュレータを使う場合にはXCode 9.0 beta付属のシミュレータで試してみてください。
本記事の執筆時点では、Xcode9、iOS11、Core MLはまだbeta版のため、XcodeやiOSのダウンロードのためにはApple Developer Programアカウントが必要となります。2017年中にはすべてリリースされる予定なので、リリース後であれば、MacのApp StoreやiOSデバイスのSoftware UpdateからXcode9やiOS11を入手できるようになります。
MXNetと変換ツールのインストール
変換ツールはmacOS High Sierra 10.13 beta 8にインストールして動かしてみました。Core ML Modelを使った推論をせずに、変換ツールを動かすだけならmacOS El Capitan (10.11)以上であれば大丈夫です。
変換ツールを利用するにはPython2.7のインストールが必要です。
MXNet frameworkおよびmxnet-to-coreml toolをインストールするためには下記のコマンドを実行します。
MXNetモデルの変換
LocationNetモデルはp2.16xlargeのAmazon EC2インスタンス1台と、AWS Multimedia Commonsのデータセットの中のgeoタグの付いた画像を使ってトレーニングしています。これはMXNet Model Zooで一般に公開されています。
他のMXNetモデルと同様に、LocationNetも2個の要素を持っています。
- モデル定義を含んだJSONファイル
- パラメータを含んだバイナリファイル
まず、Amazon S3に格納されている .json model definition と.params model parametersファイルをダウンロードしましょう。
加えて、GitHubリポジトリから、モデルのトレーニングに利用する位置情報を含んでいるgrids.txtファイルもダウンロードしましょう。このファイルはGoogleのS2 Geometry Libraryを用いたトレーニングデータから作られています。このテキストファイルの各行は、S2 Cell Token、緯度、軽度(例えば、8644b594 30.2835162512 -97.7271641272)の形式になっています。今回Swiftを使って作るiOSアプリケーションでは、S2 Cell Tokenの情報は利用せず、座標情報のみを利用します。
変換ツールのGitHubリポジトリで説明してあるように、モデルを変換してみましょう。
同じディレクトリにすべてのファイルをダウンロードした後、次のコマンドを実行します。
内部では、MXNetによってモデルが最初にロードされて、メモリ上に全体のsymbolic graphとして再形成されます。変換ツールはこのsymbolic graphの各オペレーターを、Core ML における等価な表現へと変換していきます.。変換ツールに与えたいくつかの引数はMXNetによってグラフを生成するために使われますが、その他の引数は特定の方法にて、Core MLの(ニューラルネットワークを通す前の)入力の前処理か、ニューラルネットワークの出力の処理かのどちらかに使われます。
変換ツールがモデルの多数のレイヤーを処理していることを確認できるでしょう。そして、SUCCESSという結果とともに、生成されたファイル名(この例ではRN1015k500.mlmodel)が確認できます。後の段階で、Xcodeプロジェクトにこのファイルをimportして利用します。
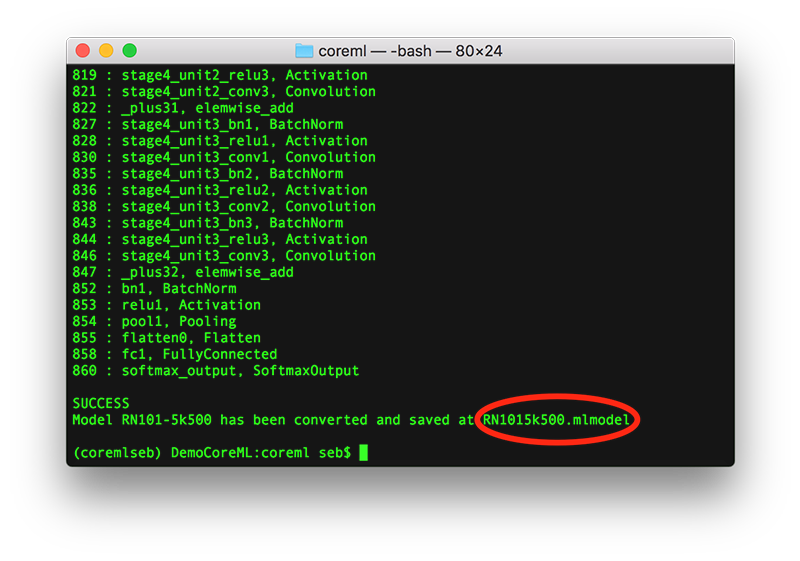
Xcodeがインストール済みであれば、このモデルファイルをダブルクリックすれば、このモデルファイルについての、サイズや名前、Swiftコード内で通常使用されるパラメータなどの情報を確認できます。

iOSアプリケーションのコードのダウンロードおよび設定
このサンプルiOSアプリケーションはmacOS Sierra 10.12.6のMac上でXcode 9 beta 6を使ってSwiftで開発されており、iOS 11 beta 8がインストールされたiPhone7にてテストされています。
我々はCore MLで画像を扱いやすくするために、Appleの新しいVision frameworkを利用することにしました。Vision frameworkは、 Core MLのモデルが要求するフォーマットおよびサイズに画像を自動で変換してくれます。このフレームワークはコンピュータ上で画像や映像を扱う際の課題に対して、一貫性のあるインターフェースおよび、各種機能(顔追跡や顔検出、ランドマークや文字検出、矩形検出、バーコード検出、オブジェクト追跡、画像登録)を提供します。
開始するために、次のリソースを使用しました。
- Core ML Modelをアプリケーションに組み込む方法
- Matthijs Hollemans氏のCoreMLHelpersのApple Vision frameworkのコードサンプル
では、アプリケーションをビルドしてみましょう。
GitHubリポジトリ(MXNet2CoreML_iOS_sample_app)からiOSのサンプルアプリケーションのソースコード をダウンロードします。
MXNet2CoreML.xcodeprojをXcodeで開きます。
下図のように、変換ツールで生成したファイル(RN1015k500.mlmodel)をXcodeプロジェクトのnavigatorにドラッグ&ドロップし、画面右下のTarget Membershipでチェックを入れます。
変換ツールをインストールせずに、iOSアプリケーションを試してみたい場合には、RN1015k500.mlmodelをアップロードしていますので、ダウンロードすれば、Xcodeプロジェクトのnavigatorにドラッグ&ドロップして利用可能です。

アプリケーションを実行してみましょう
前述したとおり、アプリケーションを実行する際には、iOS11(本記事の執筆時点ではβ版)をインストールした実機で実行することをおすすめしています。
Xcodeのシミュレータでも実行することが出来ますが、アプリケーションの実行速度やMAPの移動や拡大の際のアニメーションがイマイチな可能性があります。
次のスクリーンショットで示すように、iOSの実機でアプリケーションを実行するのであれば、Teamの設定をあなたのものに変更するのを忘れないでください。
前述したとおり、こちらの実行をするためにはApple Developer accountが必要となります。
iPhone上でアプリケーションをビルドして実行するためにplayを押下します。
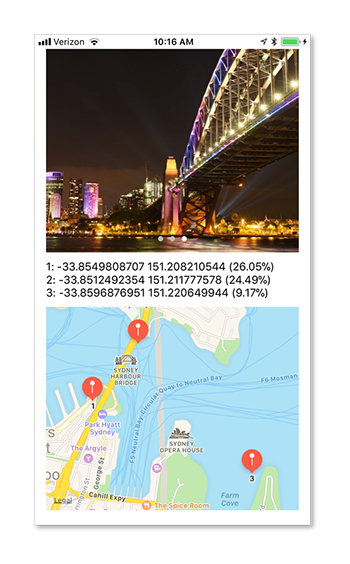
アプリケーションがiPhoneにインストールされて、次の画面が確認できるはずです。
画面には3個のセクションがあります。
上部のセクションには世界のどこかで撮影された写真が表示されます。左右にスワイプすることでアプリケーションに組み込んである3枚の画像のうちの1枚が表示されます。これらの画像は人間が見れば比較的容易に場所を識別できます。しかし、 素晴らしいことに、このモデルはGPS情報が一切含まれていない画像データから非常に正確な位置情報を予測します!
中央のセクションでは、リアルタイムの推論結果を上位3位まで表示しています。実際には、モデルは何百という予測を出しますが、その中で上位3件のみを表示しています。
下部のセクションでは、モデルで予測した上位3位までの位置情報をインタラクティブなMAP上にPinで表示しています。拡大や移動などの操作も自由にできます。
スクリーンショット1:

スクリーンショット2:
まとめ
本記事では、AWS上でMXNetを使って洗練された機械学習モデルの構築とトレーンングが可能なこと、MXNetでトレーニングしたモデルをCore MLのフォーマットに変換ツールを使って変換可能なこと、そして、変換したモデルをXcodeに素早くimport可能なことを紹介しました。iOSやその他のAppleデバイス用のアプリで、新しく素晴らしい機能を試してみましょう。
次のステップ
自分のコンピュータに保存されている写真をこのアプリケーションで試してみたいのであれば、Xcodeプロジェクトのnavigatorから1.jpgを削除して、1.jpgにリネームした、あなたの写真をドラッグ&ドロップするだけで試すことができます。どうやってこの写真の予測をするのかはCore MLモデルについての部分で説明しました。
このサンプルアプリケーションに手を入れて、カメラ機能を実装することも出来ます。写真を撮影する機能を追加するか、カメラロールから読み出せる機能を追加することで、これから撮影する写真もしくは過去に撮影した写真に対してリアルタイムで位置の予測をすることが出来ます。
この記事からインスパイヤされて様々な活用方法を発見してもらえれば大変嬉しいです。 ご質問、ご意見、ご提案がありましたら、下記のコメント欄に投稿してください。
Have fun!
原文: Bring Machine Learning to iOS apps using Apache MXNet and Apple Core ML (翻訳: SA石井・志村)