Category: Amazon Athena
発表: Amazon Athena が暗号化されたデータのクエリのサポートを追加
昨年 11 月に、当社は毎日膨大な量のデータに安全にアクセスして調べる必要があるお客様を支援するための重要なステップとなることを期待して、サービスをマーケットに投入しました。このサービスは Amazon Athena にほかなりません。私はこれを、オブジェクトストレージのクエリにより「1 回のジャンプで背の高いクエリを飛び越える」ことを試みるマネージド型サービスであると考えています。AWS のお客様が、Amazon S3 に保存された大量のデータを簡単に分析してクエリを実行できるようにするサービスです。

Amazon Athena は、ユーザーが標準 SQL を使用して Amazon S3 のデータを簡単に分析できるようにする、サーバーレスでインタラクティブなクエリサービスです。Athena の中核となるのは、ANSI SQL のサポートによりクエリを実行する分散 SQL エンジンの Presto と、Athena が CSV、JSON、ORC、Avro、Parquet などのよく使用されるデータ形式に対応できるようにし、create table、drop table、alter table などのよく使用されるデータ定義言語 (DDL) オペレーションを追加する Apache Hive です。Athena は、構造化されたデータ形式および構造化されていないデータ形式で Amazon Simple Storage Service (S3) に保存されたデータセットへのパフォーマンスの高いクエリアクセスを可能にします。Hive 対応 DDL ステートメントと ANSI SQL ステートメントは、AWS マネジメントコンソールから、または Athena JDBC ドライバーをダウンロードして利用することで SQL Workbench などの SQL クライアントから、Athena Query Editor で記述できます。さらに、JDBC ドライバーを使用することで、目的の BI ツールからプログラムでクエリを実行できます。Amazon Athena サービスの詳細については、11 月のサービスリリース時の Jeff のブログ投稿を参照してください。Athena チームは、Amazon Athena サービスの初期の機能をリリースした後で、お客様を中心に考えるという Amazon の伝統に従い、サービスのカスタマーエクスペリエンスを向上させるよう勤勉に努力してきました。これにより、チームは今回発表する機能を追加し、Amazon Athena は Amazon S3 での暗号化されたデータのクエリをサポートするようになりました。この新機能により、Athena は Amazon S3 で暗号化されたデータのクエリのサポートを提供できるだけではなく、Athena のクエリ結果からデータの暗号化を可能にします。Amazon S3 に保存された機密データを暗号化する要件または規制がある業種やお客様は、Athena が暗号化されたデータで提供する、サーバーレスな動的クエリを活用できます。 暗号化のサポート Athena の新機能の使用について説明する前に、データの保護と暗号化の必要があるお客様向けに S3 と Athena がサポートする暗号化オプションについて時間をかけて見てみましょう。現在、S3 は AWS Key Management Service (KMS) を使用したデータの暗号化をサポートしています。AWS KMS は、データの暗号化に使用される暗号化キーの作成と管理のためのマネージド型サービスです。さらに、S3 は、お客様による独自の暗号化キーを使用したデータの暗号化をサポートします。S3 に保存されたデータセットに対して Athena がサポートする暗号化オプションを理解することが重要であるため、S3 と Athena でサポートされる暗号化オプションの詳細と、暗号化されたデータアクセスに新しい Athena テーブルプロパティ has_encrypted_data が必要となる場合を、次の表に示します。
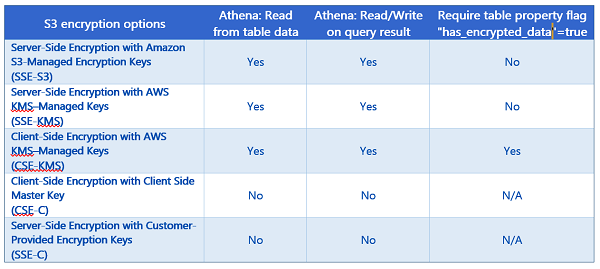
AWS KMS または Amazon S3 の暗号化オプションを使用した Amazon S3 の暗号化の詳細については、AWS KMS 開発者ガイドの「Amazon Simple Storage Service (Amazon S3) が AWS KMS を使用する方法」および Amazon S3 開発者ガイドの「暗号化を使用したデータの保護」の情報をそれぞれ参照してください。 暗号化されたデータベースとテーブルの作成とアクセス 前に説明したように、Athena へのアクセス方法はいくつかあります。もちろん、AWS マネジメントコンソールを通じて Athena にアクセスできますが、SQL Workbench などの SQL クライアントや他のビジネスインテリジェンスツールで JDBC ドライバーを使用するオプションもあります。さらに、JDBC ドライバーでは、プログラムによるクエリアクセスもできます。十分に説明したので、データベースといくつかのテーブルを作成し、テーブルからクエリを実行してクエリ結果を暗号化することにより、Athena サービスのこの新機能について詳しく見てみましょう。これらの操作はすべて、Amazon S3 に保存されている暗号化されたデータを使用して行います。初めてサービスにログインすると、次に示すような [Amazon Athena Getting Started] 画面が表示されます。Athena Query Editor に移動するには、[Get Started] ボタンをクリックする必要があります。

Athena Query Editor に移動したので、データベースを作成しましょう。Query Editor を開くときにサンプルデータベースが表示される場合は、[Query Editor] ウィンドウでクエリステートメントの入力を開始してサンプルクエリを消去し、新しいデータベースを作成します。[Query Editor] ウィンドウ内で Hive DDL コマンド CREATE DATABASE <dbname> を発行して、データベース tara_customer_db を作成します。
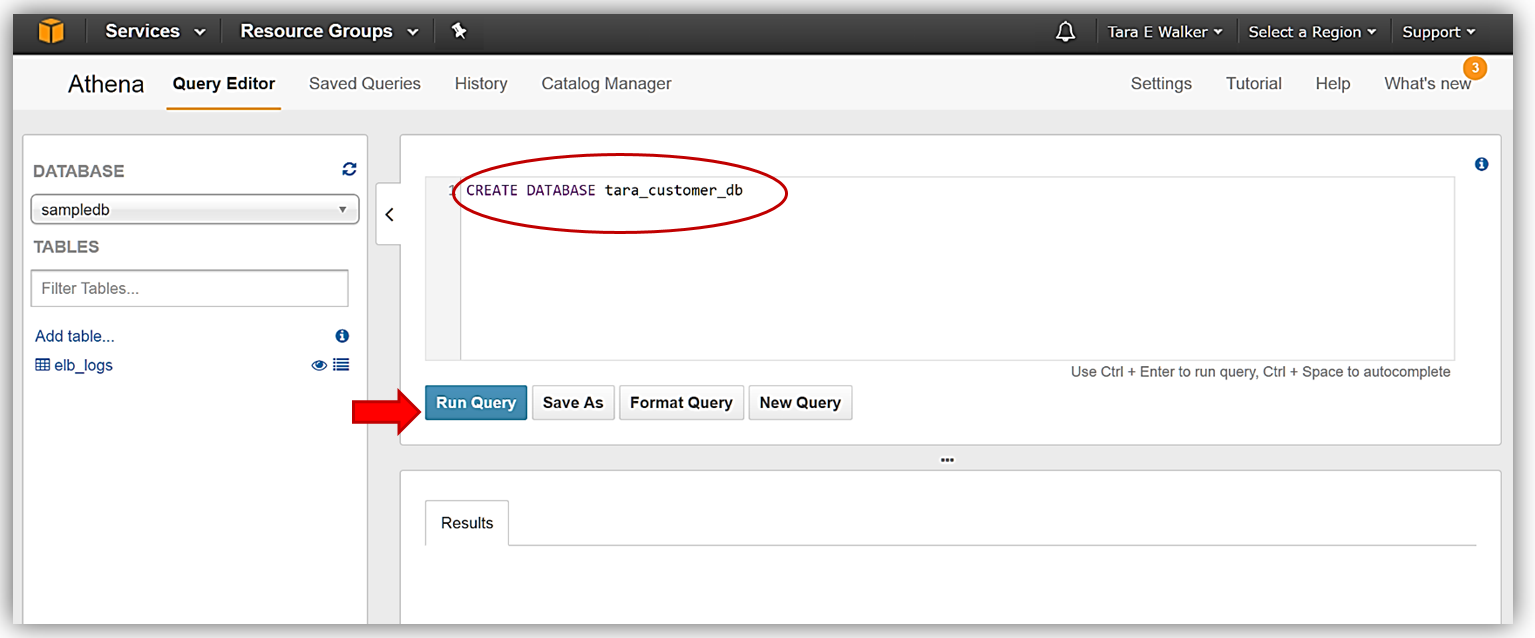
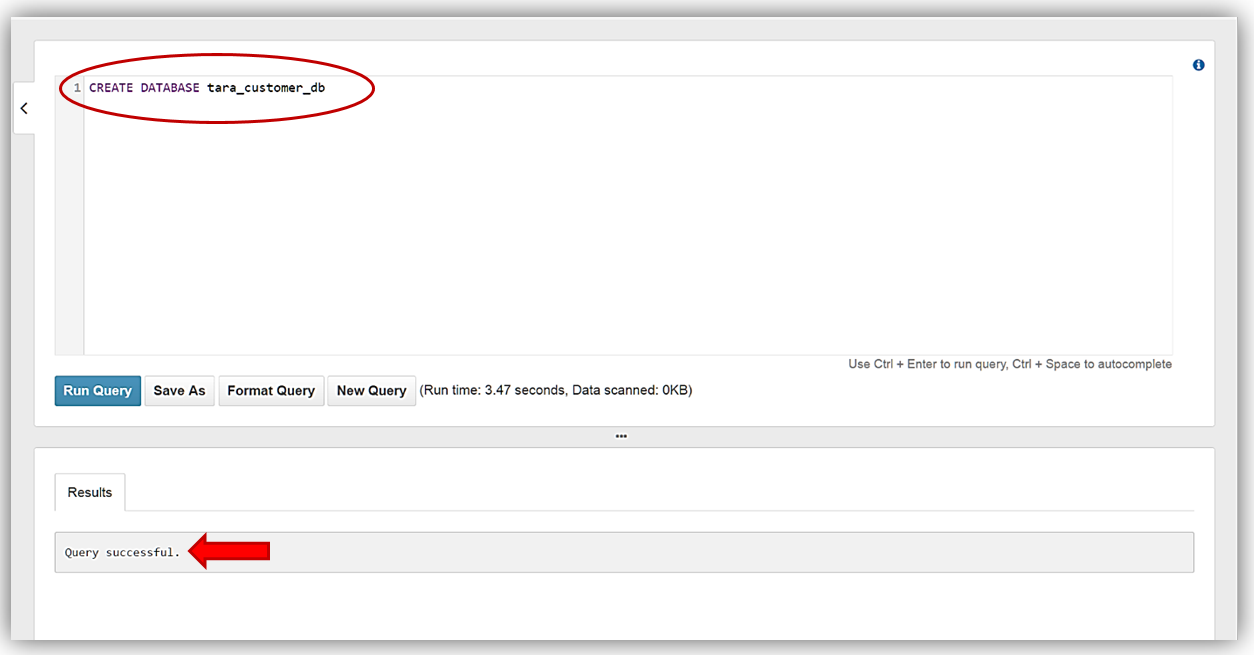
Query Editor の [Results] タブで、クエリの実行が成功したことの確認が表示されたら、データベースは作成され、ドロップダウンで選択できる状態です。
ここで、ドロップダウンで選択したデータベースを、新しく作成したデータベース tara_customer_db に変更します。  データベースを作成したので、S3 に保存されているデータからテーブルを作成できます。私はさまざまな暗号化タイプでデータを暗号化しなかったため、製品グループが、S3 バケットに保存するサンプルデータファイルを渡してくれました。私が受け取った最初のバッチのサンプルデータは SSE-KMS で暗号化されていて、上記の暗号化テーブルマトリックスで示したように、この暗号化タイプは AWS KMS で管理されたキーによるサーバー側の暗号化です。私は暗号化されたデータのこのセットを、適切に名前を付けた S3 バケットである aws-blog-tew-posts/SSE_KMS_EncryptionData に保存しました。私が受け取った 2 番目のバッチのサンプルデータは CSE-KMS です。この暗号化タイプは AWS を使用したクライアント側の暗号化で、aws-blog-tew-posts/ CSE_KMS_EncryptionData S3 バケットに保存されています。私が受け取った最後のバッチのデータは、古き良きプレーンテキストで、このデータは S3 バケット aws-blog-tew-posts/PlainText_Table に保存しました。
データベースを作成したので、S3 に保存されているデータからテーブルを作成できます。私はさまざまな暗号化タイプでデータを暗号化しなかったため、製品グループが、S3 バケットに保存するサンプルデータファイルを渡してくれました。私が受け取った最初のバッチのサンプルデータは SSE-KMS で暗号化されていて、上記の暗号化テーブルマトリックスで示したように、この暗号化タイプは AWS KMS で管理されたキーによるサーバー側の暗号化です。私は暗号化されたデータのこのセットを、適切に名前を付けた S3 バケットである aws-blog-tew-posts/SSE_KMS_EncryptionData に保存しました。私が受け取った 2 番目のバッチのサンプルデータは CSE-KMS です。この暗号化タイプは AWS を使用したクライアント側の暗号化で、aws-blog-tew-posts/ CSE_KMS_EncryptionData S3 バケットに保存されています。私が受け取った最後のバッチのデータは、古き良きプレーンテキストで、このデータは S3 バケット aws-blog-tew-posts/PlainText_Table に保存しました。
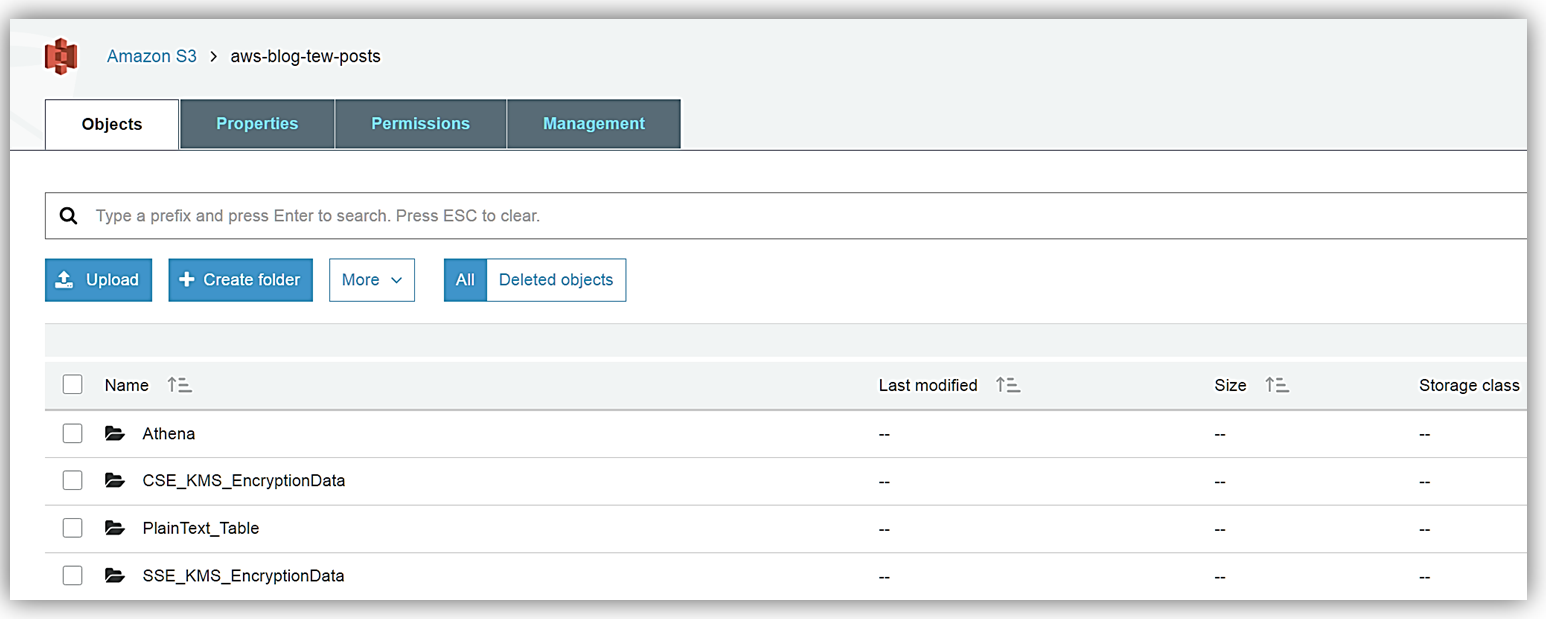
S3 バケットのこのデータは Athena サービスからアクセスすることを覚えておいてください。各バケットとそこに保存されているデータへの Athena によるアクセスを許可するため、データバケットに正しいアクセス権限があることを確認する必要があります。さらに、AWS KMS で暗号化されたデータを操作するには、ユーザーには適切な KMS キーポリシーを含むロールが必要です。KMS で暗号化されたデータを正しく読み取るには、ユーザーには S3、Athena、および KMS にアクセスするための正しいアクセス権限が必要です。S3 と Athena サービスの間で適切なアクセス権限を提供するには、いくつかの方法があります。
- ユーザーポリシーを通じてアクセスを許可する
- バケットポリシーを通じてアクセスを許可する
- バケットポリシーとユーザーポリシーを通じてアクセスを許可する。
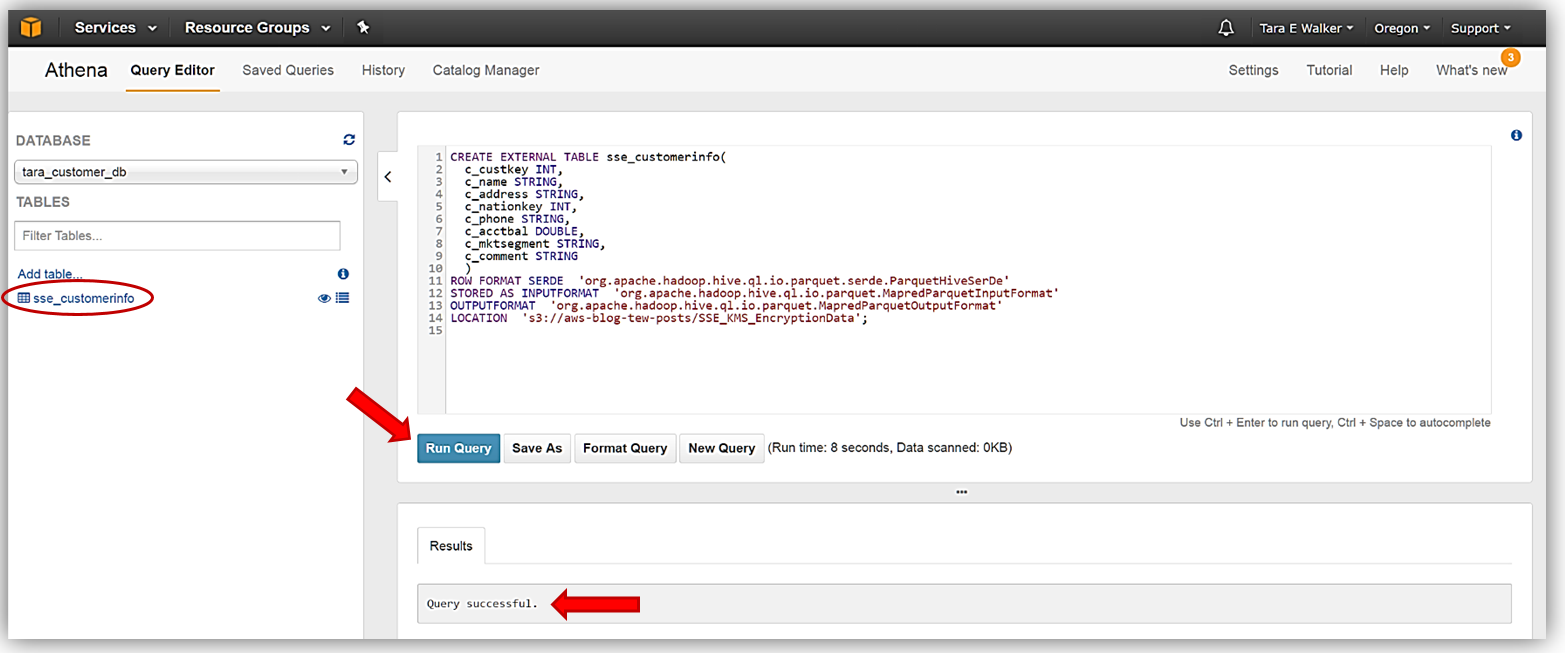
Amazon Athena のアクセス権限、Amazon S3 のアクセス権限、またはその両方の詳細については、Athena のドキュメントの「ユーザーおよび Amazon S3 バケットのアクセス権限の設定」を参照してください。S3 バケットでデータの準備と設定ができたので、後は Athena Query Editor に移動して、SSE-KMS 暗号化データから最初の新しいテーブルを作成するだけです。新しいテーブル sse_customerinfo を作成するために使用する DDL コマンドは次のとおりです。
CREATE EXTERNAL TABLE sse_customerinfo(
c_custkey INT,
c_name STRING,
c_address STRING,
c_nationkey INT,
c_phone STRING,
c_acctbal DOUBLE,
c_mktsegment STRING,
c_comment STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://aws-blog-tew-posts/SSE_KMS_EncryptionData';
sse_customerinfo テーブルを作成する DDL コマンドステートメントを Athena Query Editor に入力し、[Run Query] ボタンをクリックします。[Results] タブに、クエリが正常に実行されたことが示され、tara_customer_db データベースで利用できるテーブルの下に、新しいテーブルが表示されます。
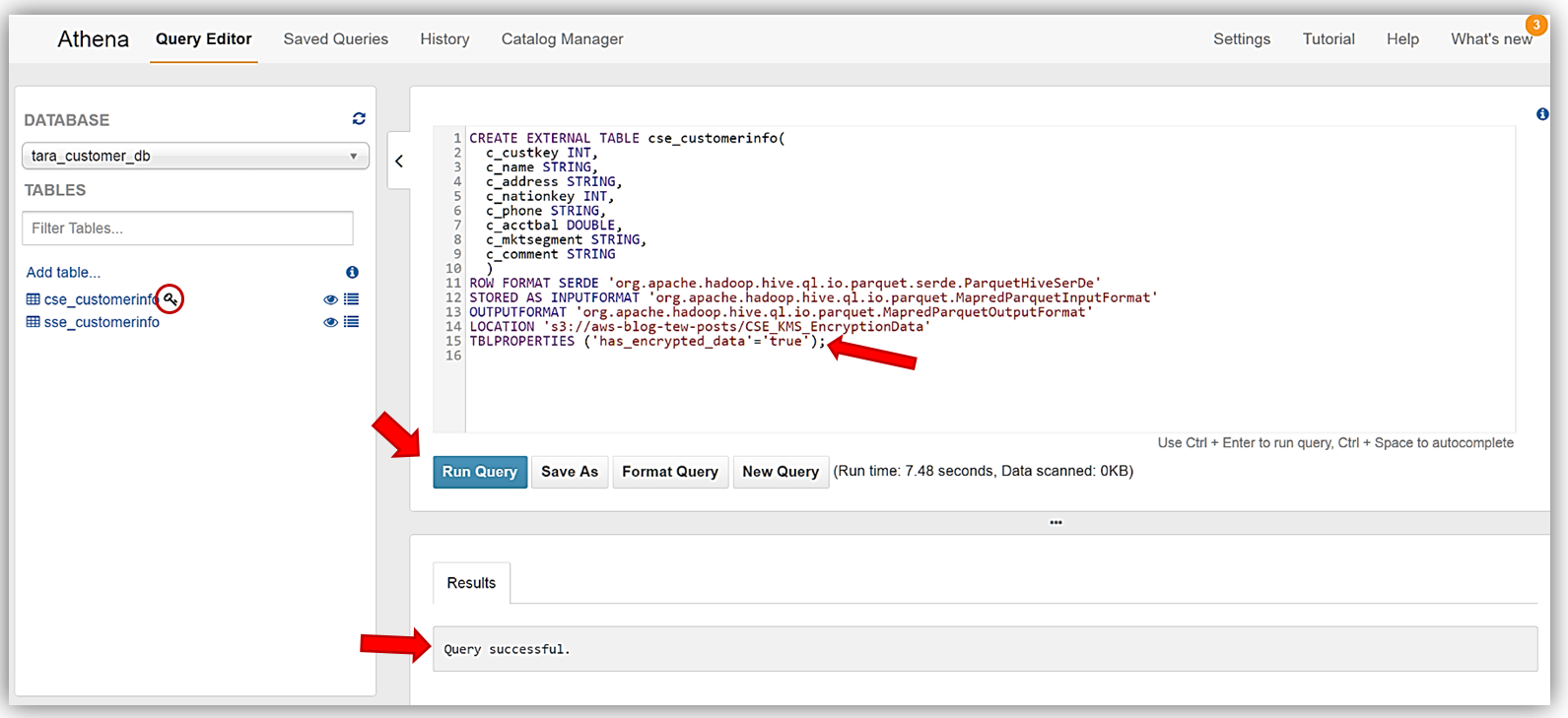
このプロセスを繰り返して、CSE-KMS で暗号化されたデータのバッチから cse_customerinfo テーブルを作成し、S3 バケットに保存されている暗号化されていないデータソースから plain_customerinfo テーブルを作成します。cse_customerinfo テーブルを作成するために使用する DDL ステートメントは次のとおりです。
CREATE EXTERNAL TABLE cse_customerinfo (
c_custkey INT,
c_name STRING,
c_address STRING,
c_nationkey INT,
c_phone STRING,
c_acctbal DOUBLE,
c_mktsegment STRING,
c_comment STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://aws-blog-tew-posts/CSE_KMS_EncryptionData'
TBLPROPERTIES ('has_encrypted_data'='true');
ここでも、Athena Query Editor に上記の DDL ステートメントを入力し、[Run Query] ボタンをクリックします。cse_customerinfo テーブルの作成に使用された DDL ステートメントを注意深く確認すると、新しいテーブルプロパティ (TBLPROPERTIES) フラグ has_encrypted_data が、新しい Athena 暗号化機能に導入されたことがわかります。このフラグは、指定されたテーブルのクエリに使用する S3 のデータは暗号化されたデータであることを Athena に指定するために使用します。時間を取って、Athena と S3 暗号化オプションについて前に確認した暗号化マトリックステーブルをもう一度参照してください。このフラグが必要なのは、[Client-Side Encryption with AWS KMS–Managed Keys] オプションを使用するときだけであることがわかります。cse_customerinfo テーブルが正しく作成されると、鍵の記号がテーブルの横に表示され、テーブルは暗号化されたデータテーブルであることが識別されます。
最後に、サンプルデータから最後のテーブル plain_customerinfo を作成します。前のテーブルに対して実行したのと同じステップです。このテーブルの DDL コマンドは次のとおりです。
CREATE EXTERNAL TABLE plain_customerinfo(
c_custkey INT,
c_name STRING,
c_address STRING,
c_nationkey INT,
c_phone STRING,
c_acctbal DOUBLE,
c_mktsegment STRING,
c_comment STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://aws-blog-tew-posts/PlainText_Table';
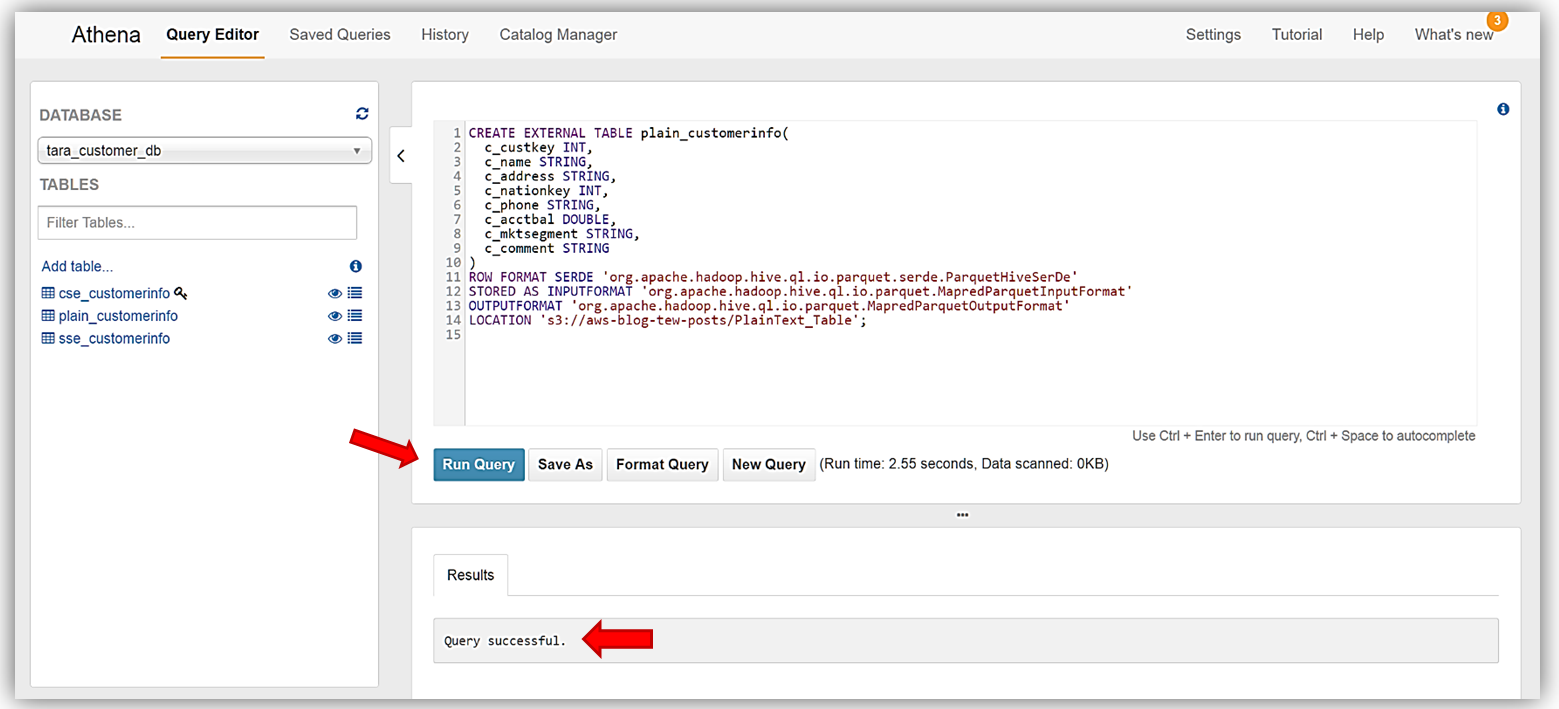
よくできました。Athena を使用して S3 から暗号化されたデータを正常に読み取り、暗号化されたデータに基づいてテーブルを作成しました。ここで、新しく作成した、暗号化されたデータテーブルに対してクエリを実行できます。 クエリの実行 新しいデータベーステーブルに対するクエリの実行は、非常に簡単です。ここでも、一般的な DDL ステートメントやコマンドを使用して、Amazon S3 に保存されたデータに対してクエリを作成できます。クエリの確認のため、Athena のデータのプレビュー機能を使用します。テーブルの一覧で、テーブルの横に 2 つのアイコンが表示されます。1 つのアイコンはテーブルプロパティアイコンで、これを選択すると、選択されたテーブルプロパティが表示されます。もう 1 つのアイコンは目の記号で表示され、テーブル用の単純な SELECT クエリステートメントを生成するデータのプレビュー機能です。
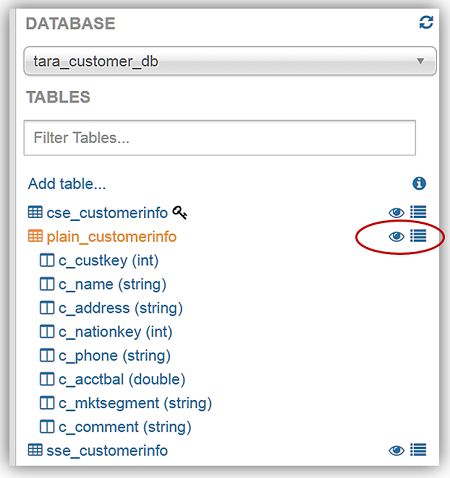
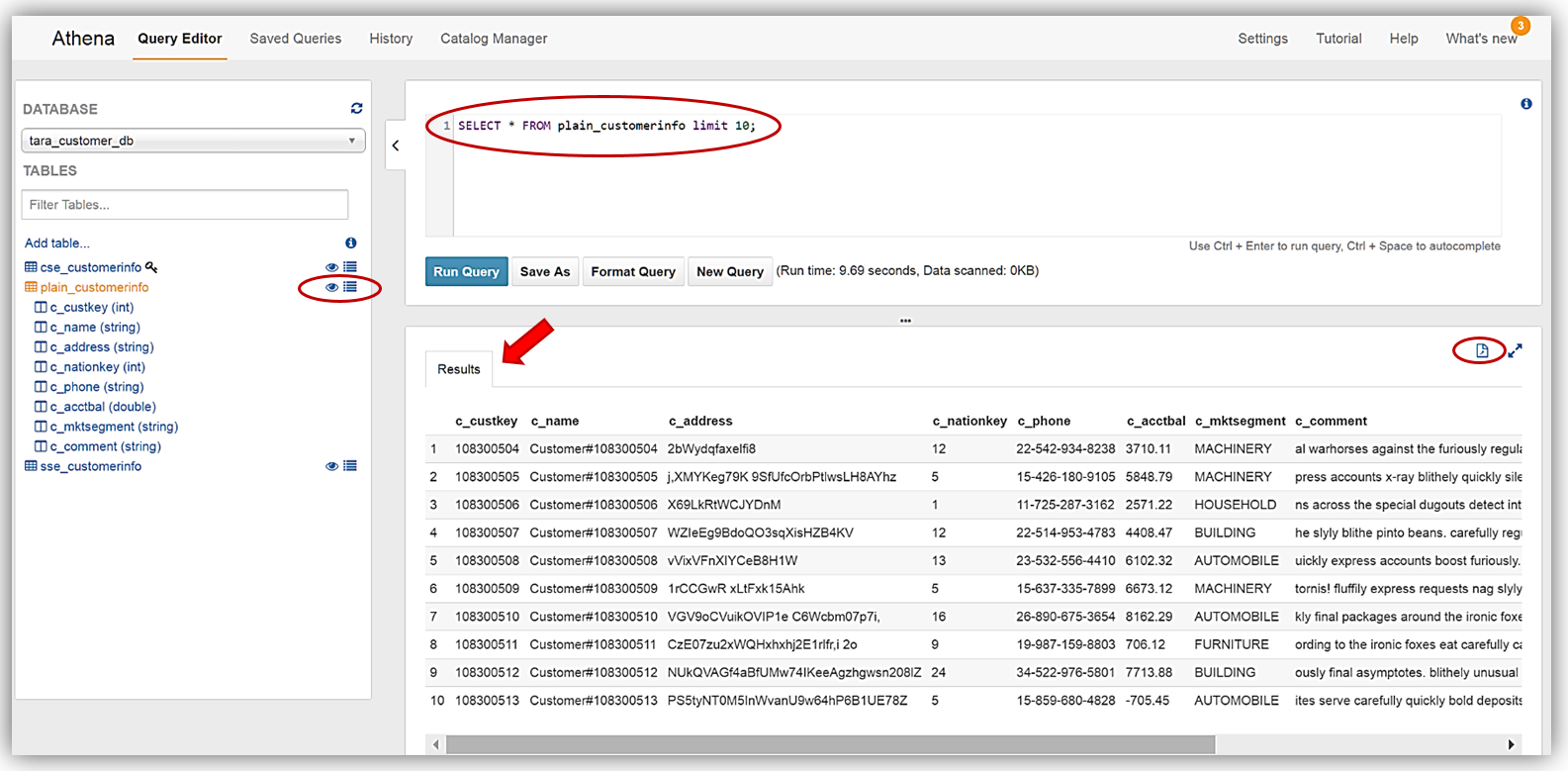
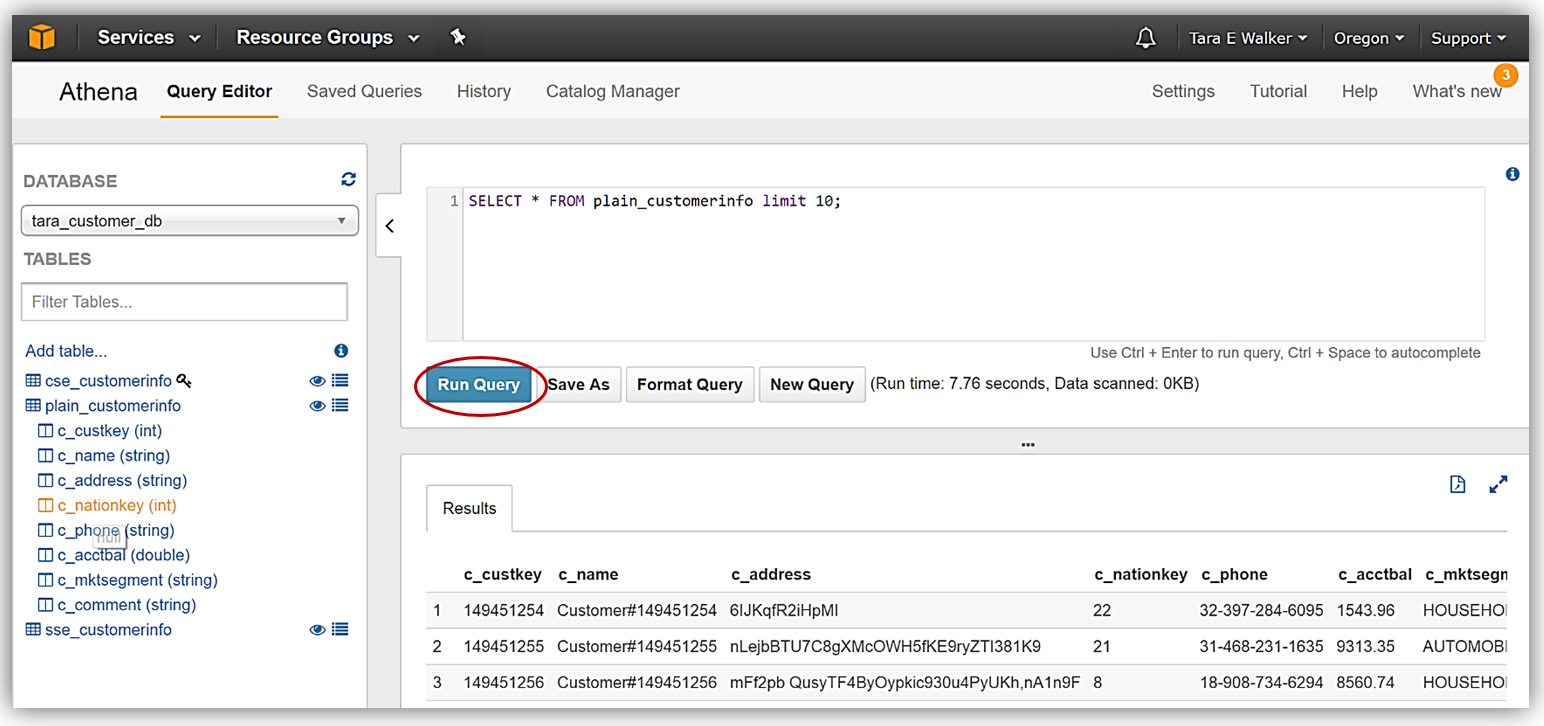
Athena を使用したクエリの実行を紹介するため、テーブルの横にある目のアイコンを選択して、plain_customerinfo のデータのプレビューを選択しました。データのプレビュー機能により、次の DDL ステートメントが作成されます。
SELECT * FROM plain_customerinfo limit 10;plain_customerinfo テーブルでデータのプレビュー機能を使用したクエリ結果が、Athena Query Editor の [Results] タブに表示され、オプションでファイルアイコンをクリックすると、クエリ結果をダウンロードできます。
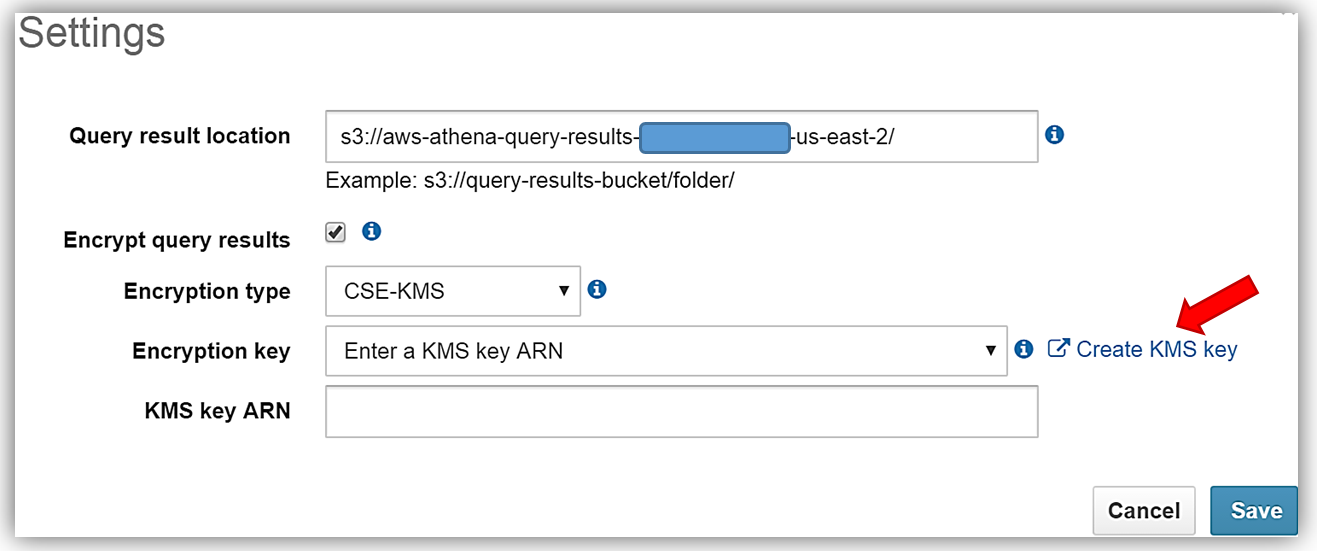
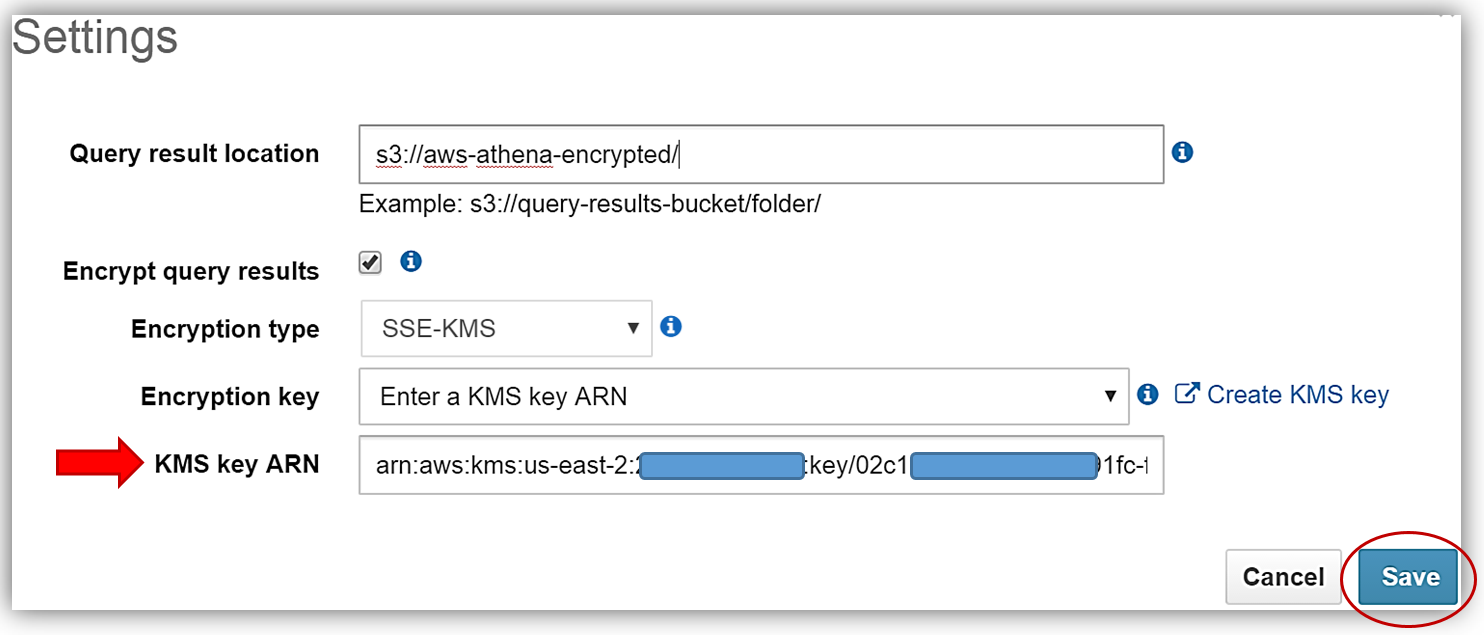
Athena の新しい暗号化されたデータ機能では、クエリ結果の暗号化と、結果の Amazon S3 への保存もサポートされます。クエリ結果でこの機能を活用するため、クエリデータを暗号化し、選択したバケットに保存します。現在、選択したデータテーブルは暗号化されていません。最初に Athena の [Settings] メニューを選択し、クエリ結果の現在のストレージ設定を確認します。暗号化に使用する KMS キーがないため、[Create KMS key] ハイパーリンクを選択し、クエリ結果を Athena と S3 で暗号化するために使用する KMS キーを作成します。KMS キーを作成し、適切なユーザーアクセス権限を設定する方法の詳細については、http://docs.aws.amazon.com/kms/latest/developerguide/create-keys.html を参照してください。

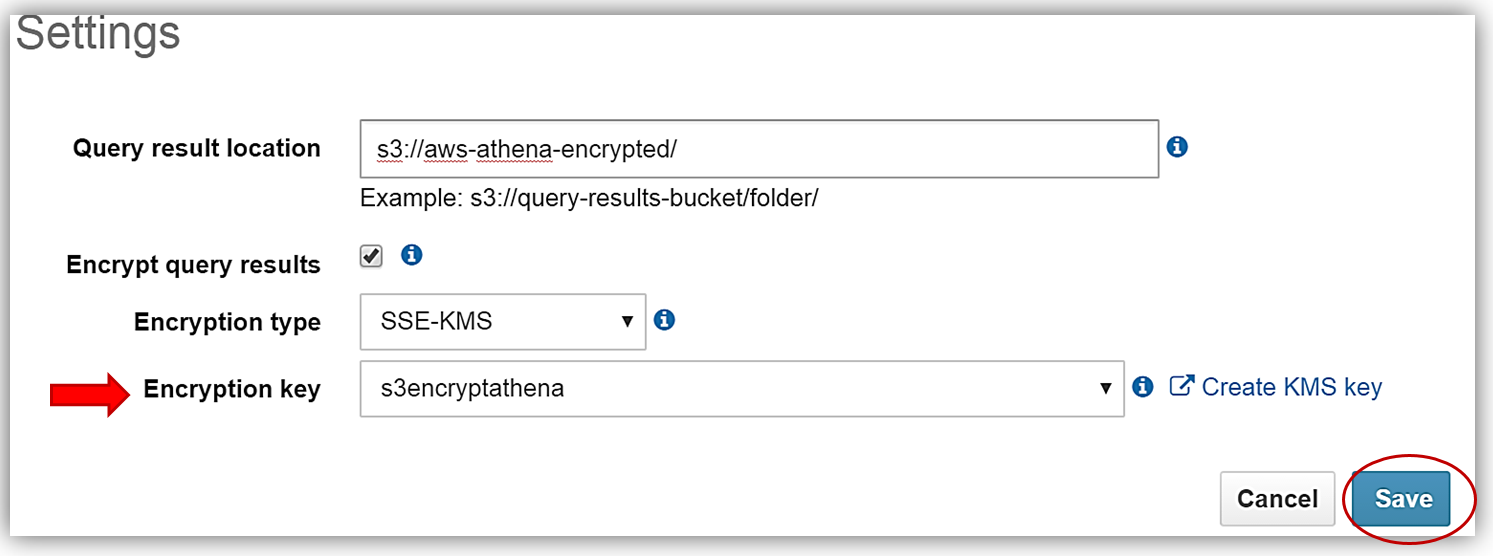
s3encryptathena KMS キーを正しく作成し、Athena 設定で使用するキー ARN をコピーしたら、Athena コンソールの [Settings] ダイアログに戻り、[Encrypt query results] テキストボックスを選択します。次に、[Query result location] テキストボックスを更新し、s3 バケット aws-athena-encrypted を指します。これは暗号化されたクエリ結果を保存する場所となります。残っている唯一のことは、暗号化タイプの選択と KMS キーの入力です。これを行うには、[Encryption key] ドロップダウンから s3encryptathena キーを選択するか、[KMS key ARN] テキストボックスに ARN を入力します。この例では、暗号化タイプに SSE-KMS を使用するよう選択しました。以下で、KMS キーを選択する両方の例を参照できます。[Save] ボタンをクリックすると、プロセスが完了します。
ここで、plain_customerinfo テーブルの現在のクエリを再実行します。このテーブルは暗号化されていませんが、クエリ結果に暗号化を追加するために行われた Athena の設定変更により、このテーブルに対して実行されたクエリ結果が、KMS キーを使用して SSE-KMS 暗号化により保存されるようにしました。
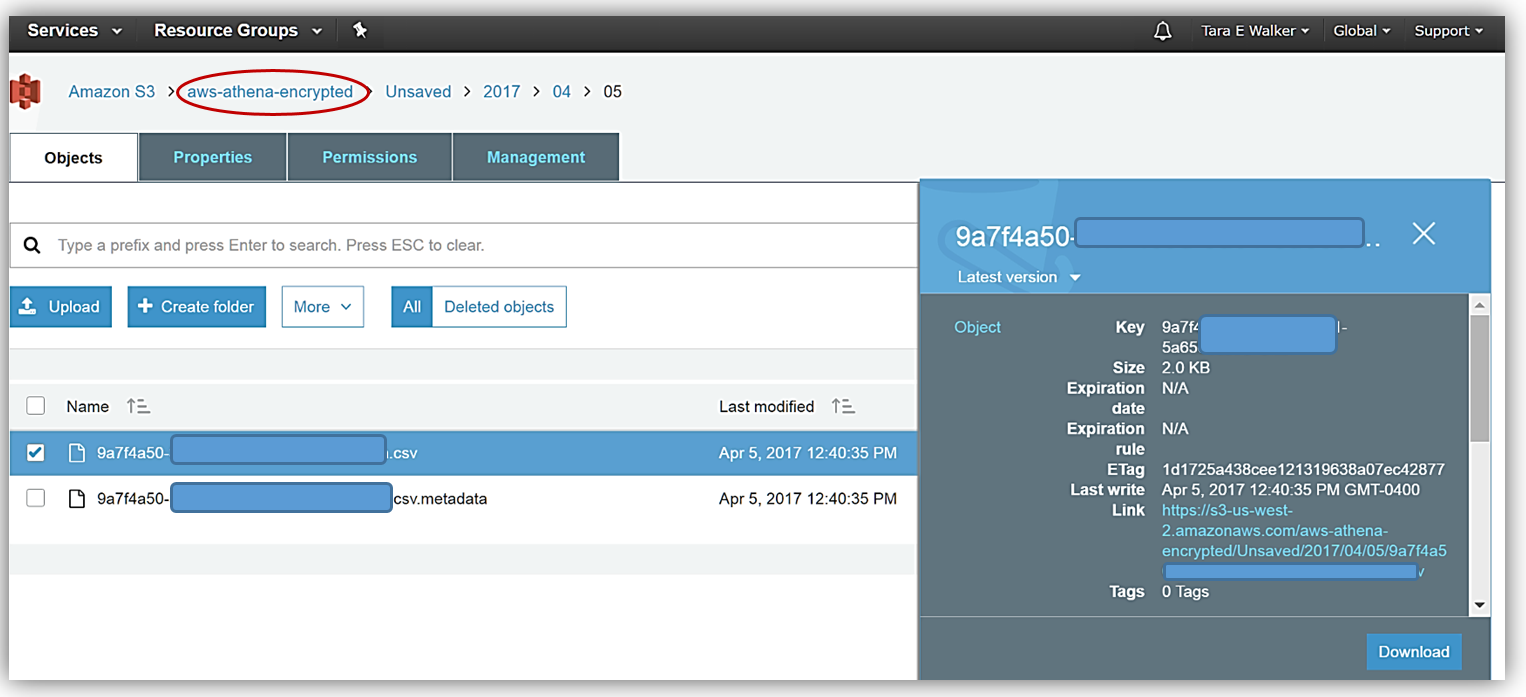
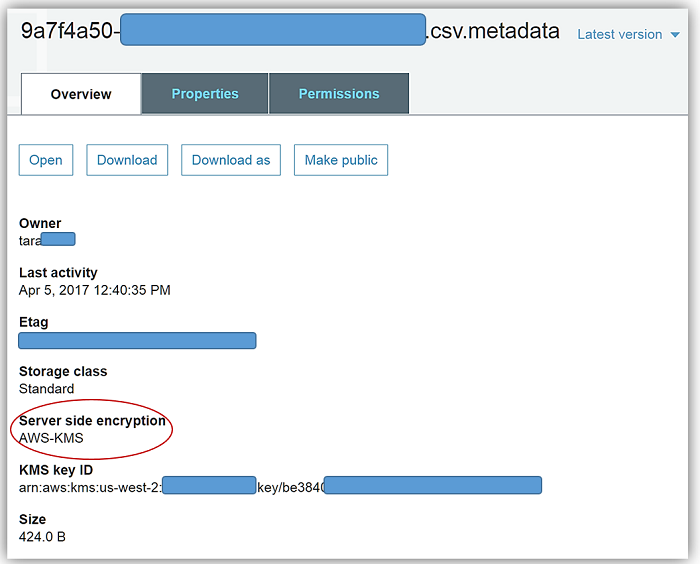
再実行の後で Amazon S3 コンソールに移動し、指定したバケット aws-athena-encrypted に保存した CSV データファイルと、バケットおよびファイルの SSE-KMS 暗号化を表示すると、作業の成果を確認できます。
概要 言うまでもなく、この Athena の発表には、暗号化によりデータを保護しながら、さまざまなデータ形式で保存されているデータのクエリと分析を実行する機能を維持したいお客様にとって複数の利点があります。さらに、このリリースにはこのブログ投稿で説明しなかった機能強化が含まれています。
- 新しい暗号化機能とキーの更新をサポートする、JDBC ドライバーの新しいバージョン。
- ALTER TABLE を使用して列を追加、置換、変更する機能の追加。
- LZO 圧縮データのクエリのサポートの追加。
詳細については、Athena ユーザーガイドのリリースドキュメントを参照してください。また、Athena ドキュメントの「暗号化オプションの設定」セクションを参照し、Amazon S3 に保存された暗号化されたデータのクエリを、Athena を利用して開始してください。Athena と Amazon S3 でのサーバーレスクエリの詳細については、Athena 製品ページを参照するか、Athena ユーザーガイドを確認してください。さらに、Athena の機能および S3 を使用したデータの暗号化の詳細については、AWS ビッグデータのブログ投稿「Amazon Athena を使用した S3 のデータの分析」および AWS KMS 開発者ガイドを参照できます。それでは、暗号化をご活用ください。- Tara
【開催報告】Amazon Athena Meetup – Startup and AdTech
こんにちは、ソリューションアーキテクトの篠原英治です。
Amazon AthenaおよびAmazon EMRのGeneral ManagerであるRahul Pathakの来日に伴い、AWSをご利用いただいているスタートアップおよびアドテクのエンジニアの皆さまをAWSジャパンのオフィスにお招きしてAmazon Athenaに関する勉強会を開催しました。

– Amazon Athenaのご紹介
お客様からいただいたフィードバックからAthenaを開発するに至ったという背景や、フィロソフィー、そして特徴などについて、AWSのBigData関連サービスを担当している事業開発マネージャーの一柳による逐次通訳とともに、ご紹介させていただきました。


Amazon QuickSightとの連携や、JDBCコネクタを使った実装、Apache ParquetやApache ORCといったカラムナフォーマット利用の推奨、Apache Spark on EMRで既存ファイルをカラムナフォーマットに変換する方法から、実際にご利用いただいているお客様のユースケースのご紹介にいたるまで、多岐にわたる内容となりました。


– Q&Aセッション
Q&A形式で活発なディスカッションが行われました。


非常に実践的で詳細なご質問や大変貴重なフィードバックを数多くいただきました。またRafulからもスキャンデータの圧縮によるコスト効率の改善などのTIPSも共有させていただきました。こちらに関しましては、先日データサイエンス領域をメインに担当させていただいているSAの志村が翻訳した『 Amazon Athena のパフォーマンスチューニング Tips トップ 10 | Amazon Web Services ブログ 』も併せてご覧ください。


Rahulおよび一柳は『 お客様からAthenaに対する期待やフィードバックを直接いただくことができ、今後の改善のアイデア得ることができました。このMeetupを開催できて本当に良かったです。お忙しい中ご参加くださった皆様ありがとうございました! 』と申しておりました。


—
Amazon Athenaに関しまして、フィードバック等ございましたら、お近くのAWSジャパンの人間にお声がけいただければと思いますので、今後ともよろしくお願い致します。
また、日本語でAmazon Athenaの概要を知るには [PDF] AWS Black Belt Online Seminar Amazon Athena もおすすめですので、是非ご覧くださいませ。
Amazon Athena のパフォーマンスチューニング Tips トップ 10
Amazon Athena は、S3 に保存されたデータに対して標準 SQL で簡単に分析を行える、インタラクティブクエリサービスです。Athena はサーバーレスのためインフラ管理の必要がなく、また実行したクエリのぶんだけ料金を支払うかたちになります。Athena は簡単に使えます。Amazon S3 上のデータに対してスキーマを定義し、標準 SQL でクエリを投げるだけです。
このブログポストでは、クエリパフォーマンスを改善するための 10 個の Tips をご紹介します。Tips には、Amazon S3 に置かれたデータに関するものと、クエリチューニングに関するものがあります。Amazon Athena は Presto を実行エンジンとして使用しているため、ここでご紹介する Tips のうちのいくつかは、Amazon EMR 上で Presto を動かす際にも当てはまります。
このポストは、読者の方が Parquet, ORC, Text files, Avro, CSV, TSV, and JSON といった、さまざまなファイルフォーマットについての知識を持っていることを前提としています。
ベストプラクティス: ストレージ
このセクションでは Athena を最大限に活用するために、どのようなデータ構造にするべきかについて議論します。ここで議論する内容は、Amazon EMR 上の Spark, Presto, Hive で Amazon S3 のデータを処理する場合にも、同様に当てはまります。
1. データをパーティションに分ける
パーティショニングとは、テーブルをいくつかに分割し、日付や国、地域といったカラムの値単位でまとめることをさします。パーティションは仮想カラムとして動作します。パーティションをテーブルの作成時に定義することで、クエリでスキャンするデータ量を減らすことができ、その結果パフォーマンスが向上します。パーティションに基づいてフィルタを指定することで、クエリで読み込むデータ量を制限することができます。より詳細については、Partitioning Data を参照してください。
Athena では Hive のパーティショニングをサポートしており、以下のいずれかの記法を使用します。
- カラム名のあとに = 記号をつけ、そのあとに値を記述する
データセットがこの形でパーティションわけされている場合には、テーブルにパーティションを一括で認識させるために、MSCK REPAIR TABLE を実行します
- もしデータの “Path” が上記のフォーマットでない場合には、個々のパーティションに対して、ALTER TABLE ADD PARTITION コマンドを実行することで、パーティションを認識させることができます
注意: このやり方を用いることで、S3 上のどの場所にあるオブジェクトに対してでも、パーティションを認識させることができます
以下の例は、S3 バケットに置かれたフライトテーブルが、year でパーティションわけされているものになります。
year カラムに対して ‘WHERE’ 句を用いることで、読み込むデータ量を制限できます。
パーティションキーには、複数のカラムを指定することができます。同様に、そのカラムが特定の値のものだけをスキャンすることができます。
パーティション対象のカラムを決める際には、以下の点を考慮してください:
- フィルタとして使われるカラムは、パーティションの有力候補になります
- パーティショニング自体にコストがかかります。テーブル内のパーティション数が増えるにつれ、パーティションのメタデータを取得して処理するためのオーバーヘッドが大きくなり、かつ 1 パーティションあたりのデータサイズは小さくなります。過剰に細かくパーティショニングすると、パフォーマンス上の利点が失われます
- データが特定パーティションに偏っており、かつ多くのクエリがその値を使う場合には、同様にパフォーマンス上の利点が失われます
例:
以下のテーブルでは、パーティション分けされたテーブルと、そうでないテーブルのクエリ実行時間を比較しています。両テーブルには、無圧縮のテキストフォーマットデータが 74GB 含まれています。パーティション分けされたテーブルは、l_shipdate カラムによって 2526 個のパーティションに分けられています。
| クエリ | パーティション分けされていないテーブル | コスト | パーティション分けされたテーブル | コスト | 削減度合い | ||
| 実行時間 | スキャンされたデータ量 | 実行時間 | スキャンされたデータ量 | ||||
| SELECT count(*) FROM lineitem WHERE l_shipdate = '1996-09-01' | 9.71 秒 | 74.1 GB | $0.36 | 2.16 秒 | 29.06 MB | $0.0001 |
99% 価格削減 77% 速度向上 |
| SELECT count(*) FROM lineitem WHERE l_shipdate >= '1996-09-01' AND l_shipdate < '1996-10-01' | 10.41 秒 | 74.1 GB | $0.36 | 2.73 秒 | 871.39 MB | $0.004 | 98% 価格削減
73% 速度向上 |
ただし以下に示すように、パーティショニングにはペナルティもあります。過剰にパーティション分けしないように気をつけてください。
| クエリ | パーティション分けされていないテーブル | コスト | パーティション分けされたテーブル | コスト | 削減度合い | ||
| 実行時間 | スキャンされたデータ量 | 実行時間 | スキャンされたデータ量 | ||||
| SELECT count(*) FROM lineitem; | 8.4 秒 | 74.1 GB | $0.36 | 10.65 秒 | 74.1 GB | $0.36 | 27% 速度低下 |
2. ファイルを圧縮・分割する
各ファイルが適切なサイズ(詳しくは次のセクションを参照)であるか、ファイルが分割可能であれば、データの圧縮によってクエリの実行速度は著しく向上します。データサイズが小さいほど、S3 から Athena へのネットワークトラフィックが軽減されます。
分割可能なファイルの場合には並列実行性を増すために、Athena の実行エンジンがファイルを分割して、複数のリーダーで処理します。単一の分割不可能なファイルを扱う場合には、単一リーダーのみがファイルを読み込むことができ、そのほかのリーダーは待機状態のままです。すべての圧縮アルゴリズムが分割可能なわけではありません。一般的な圧縮フォーマットとその属性について、以下のテーブルにまとめました。
| アルゴリズム | 分割可能か否か | 圧縮の度合い | 圧縮 + 解凍速度 |
| Gzip (DEFLATE) | いいえ | 高い | 普通 |
| bzip2 | はい | 非常に高い | 遅い |
| LZO | いいえ | 低い | 速い |
| Snappy | いいえ | 低い | とても速い |
一般的に、アルゴリズムの圧縮率が高くなるほど、圧縮および解凍に必要な CPU リソースが増えます。
Athena の場合は、デフォルトでデータ圧縮が行われ、かつ分割可能な Apache Parquet や Apache ORC といったファイルフォーマットの利用をおすすめします(訳注: ここでは、ファイルフォーマットと圧縮フォーマットが混ざっている点に注意してください。Parquet や ORC はファイルフォーマットであり、圧縮フォーマットではありません。ですが、Parquet や ORC はデフォルトのエンコーディング法の中に、辞書エンコーディングという簡単な圧縮処理が含まれています。ここの記述は、そのことを表しています。また Tips の 4 番目で述べているように、Parquet/ORC に対して、さらに Snappy のような圧縮アルゴリズムを指定することが可能です)。もしそれらを利用できない場合には、適切なサイズに分割した BZip2 や Gzip を試してください。
3. ファイルサイズを最適化する
データ読み込みが並列で行われ、データブロックがシーケンシャルに読み込まれる場合に、クエリが効率的に実行されます。分割可能なファイルフォーマットであるようにしておくことで、ファイルの大きさに関わらず並列処理が行われます。
ただしファイルサイズが非常に小さい場合、特に 128MB 未満の場合には、実行エンジンは S3ファイルのオープン、ディレクトリのリスト表示、オブジェクトメタデータの取得、データ転送のセットアップ、ファイルヘッダーの読み込み、圧縮ディレクトリの読み込み、といった処理に余分な時間がかかります。その一方で、ファイルが分割不可能でサイズが非常に大きいときには、単一のリーダーがファイル全体の読み込みを完了するまで、クエリ自体の処理は行われません。この場合、並列性が下がってしまいます。
細切れファイル問題に対する解決法のひとつとして、EMR の S3DistCP ユーティリティがあります。これを使うことで、小さなファイル群を大きなオブジェクトへとまとめることができます。S3DistCP は、大量のデータを最適なやり方で HDFS から S3、S3 からS3 、S3 から HDFS へと移動させる際にも利用できます。
大きなファイルにまとめるのは、複数の利点があります:
- 高速な一覧表示
- S3 へのリクエスト数の削減
- 管理するメタデータの削減
例:
以下では、単一の大きなファイルのテーブルと、5000 個の小さなファイルのテーブルとで、クエリ実行時間を比較しています。データはテキストフォーマットで、サイズは 7GB です。
| クエリ | ファイル数 | 実行時間 |
| SELECT count(*) FROM lineitem | 5000 files | 8.4 秒 |
| SELECT count(*) FROM lineitem | 1 file | 2.31 秒 |
| 実行速度 | 72% 向上 |
4. 列指向データの作成を最適化する
Apache Parquet と Apache ORC はポピュラーな列指向データフォーマットです。両者には列方向圧縮、さまざまなエンコーディング、データ型に合わせた圧縮、プレディケイトプッシュダウン(訳注: プレディケイトプッシュダウンとは、WHERE 句や GROUP BY 句などの処理を効率的に行うための手法です。例えば GROUP BY に対するプレディケイトプッシュダウンでは、各リーダーで読み込んだデータについて、全データで GROUP BY を行う前に、各ワーカー内であらかじめ GROUP BY をしておき、その結果を集約ワーカーに転送する、といったプロセスをとります。各ワーカーで先に集約を行うことでデータの転送コストが下がり、結果的にパフォーマンスが向上します。このように、クエリの実行パイプラインの最後で行う処理を、効率化のためにあらかじめ各プロセスでおこなっておく(= プッシュダウン)のが、プレディケイトプッシュダウンの役割となります)といった、データを効率的に持つための機能があります。両者はともに分割可能です。一般的に、高い圧縮率やデータブロックのスキップによって、S3 から読み込むデータが減り、その結果よりよいクエリパフォーマンスが得られます。
チューニング可能なパラメーターのひとつとして、ブロックサイズまたはストライプのサイズがあります。Parquet におけるブロックサイズ、 ORC におけるストライプサイズというのは、バイトサイズ単位で表されるもので、単一ブロックで保持できる最大行数を意味します。ブロックまたはストライプのサイズが大きいほど、単一ブロックで格納できる行数も多くなります。デフォルトでは Parquet のブロックサイズは 128MB で、ORC のストライプサイズは 64MB になります。テーブル内に大量のカラムがある場合は、各カラムのブロック単位で効率的にシーケンシャル I/O を行えるように、より大きなブロックサイズにすることをおすすめします。
そのほかのパラメーターとして、データブロックの圧縮アルゴリズムが挙げられます。Parquet のデフォルト圧縮フォーマットは Snappy ですが、それ以外に圧縮なし、 GZIP、そして LZO も使用可能です。ORC のデフォルトは ZLIB ですが、それ以外に圧縮なしと Snappy が利用可能です。デフォルトの圧縮アルゴリズムからはじめて、10GB 以上のデータサイズになった場合には、それ以外の圧縮アルゴリズムを試してみることをおすすめします。
Parquet/ORC ファイルフォーマットは、ともにプレディケイトプッシュダウン(プレディケイトフィルタリングとも呼ばれます)をサポートしています。Parquet/ORC はともに、ブロック内にカラムの値を保持するだけでなく、最大値/最小値のようなブロックごとの統計データも持っています。クエリが実行される際に、統計情報によって当該ブロックを読み込む必要があるか、スキップしてよいかを判断します。スキップするブロック数を最適化するための一つの方法として、Parquet や ORC で書き出す前に、よくフィルタされるカラムでデータをソートしておくやり方があります。これによって、各ブロックにおける最小値と最大値の差分が、全体としてもっとも小さくなることが保証されます。これによって、フィルタ効率を向上させることができます。
Amazon EMR 上で Spark や Hive を実行することで、既存のデータを Parquet や ORC に変換できます。 詳細については、S3のデータをAmazon Athenaを使って分析する のブログポストを参照してください。また以下のリソースもあります:
- aws-blog-spark-parquet-conversion Spark GitHub リポジトリ
- Converting to Columnar Formats (hive によるフォーマットの変換)
ベストプラクティス: クエリ
Athena ではクエリの実行エンジンとして Presto を使用しています。クエリ実行時に Presto がどのように動いているか理解することで、クエリの最適化方法について把握することができます。
5. ORDER BY を最適化する
ORDER BY 句はクエリの実行結果をソートして返します。ソートを実行するために、Presto はデータのすべてのレコードを単一のワーカーに送り、それからソートを実行します。この処理は Presto のメモリを大量に消費するため、クエリの実行時間が非常に長くなります。最悪の場合には、クエリが失敗します。
トップ N の値をみるために ORDER BY 句を使用する場合には、単一ワーカーでソートを実行するのではなく、LIMIT 句によって各ワーカーにソートとリミットの処理をプッシュし、ソートにかかるコストを大きく削減してください。
例:
データセット: 7.25GB、無圧縮、テキストフォーマット、6000万行
| クエリ | 実行時間 |
| SELECT * FROM lineitem ORDER BY l_shipdate | 528 秒 |
| SELECT * FROM lineitem ORDER BY l_shipdate LIMIT 10000 | 11.15 秒 |
| 速度 | 98% 向上 |
6. JOIN を最適化する
2 つのテーブルを結合する際には、両者のうち大きなほうを左側に、小さなほうを右側に指定してください。Presto は JOIN 句の右側で指定されたテーブルを各ワーカーノードに転送して、左側のテーブルを順になめていくことで結合を行います。右側のテーブルを小さくすることで、メモリ消費量を少なく、クエリを高速に実行することができます。
例:
データセット: 74GB、無圧縮、テキストフォーマット、6億200万行
| クエリ | 実行時間 |
| SELECT count(*) FROM lineitem, part WHERE lineitem.l_partkey = part.p_partkey | 22.81 秒 |
| SELECT count(*) FROM part, lineitem WHERE lineitem.l_partkey = part.p_partkey | 10.71 秒 |
| 価格削減 / 速度向上 | 53% 速度向上 |
例外として、複数のテーブルをまとめて結合する場合と、クロス結合が行われる場合があります。Presto は結合の実行順序の最適化をサポートしていないため、が左側から右側に対して結合処理が行われます。そのためテーブルを左側から大きい順に並べることにより、結合条件に合わせたテーブルの並びにならない場合、クロス結合が実行されてしまいます(訳注: 以下の例の上側のクエリの場合、まず lineitem と customer とで結合処理が行われます。しかし結合条件にあるのは lineitem と orders、ccustomer と orders のため、lineitem と customer の間ではクロス結合が行われてしまいます。その結果得られた巨大なテーブルと orders の間で,次の結合処理が行われます。クロス結合は非常にコストの高い処理のため、この場合は 30 分以内にクエリが完了せず、タイムアウトしてしまっています)。
例:
データセット: 9.1GB、無圧縮、テキストフォーマット、7600万行
| クエリ | 実行時間 |
| SELECT count(*) FROM lineitem, customer, orders WHERE lineitem.l_orderkey = orders.o_orderkey AND customer.c_custkey = orders.o_custkey | Timed Out |
| SELECT count(*) FROM lineitem, orders, customer WHERE lineitem.l_orderkey = orders.o_orderkey AND customer.c_custkey = orders.o_custkey | 3.71 seconds |
7. GROUP BY を最適化する
GROUP BY 演算子は、指定されたカラムの値に応じてレコードを各ワーカーノードに分散し、各ノードはメモリ内に対象の値を保持します。レコードが追加されると、メモリ内の GROUP BY 対象のカラムを比較します。一致した場合には、対象となる値を集約します。
クエリ内で GROUP BY を使う際には、カーディナリティ(訳注: カラム内のユニークな値の個数)が高い順にカラムを並べてください(これはユニークな値の数が多いほど、データが各ワーカーに均等に分散するためです)。
もうひとつの最適化方法は、可能ならば GROUP BY の対象を文字列でなく数字にすることです。数字は文字列に比べて必要とするメモリが少ないため、高速に処理することができます。
またその他の方法として、SELECT の中で扱うカラム数を制限することによって、レコードをメモリに確保したり、GROUP BY で集約する際に必要とするメモリ総量を減らすやり方があります。
8. LIKE 演算子を最適化する
文字列のカラムに対して、複数の値でフィルタリングする際には、一般的に LIKE よりも RegEx を使う方が望ましいです。LIKE を使う回数が多いほど、また文字列カラムのサイズが大きいほど、RegEx の効果も大きくなります。
例:
データセット: 74GB、無圧縮、テキストフォーマット、6億行
| クエリ | 実行時間 |
| SELECT count(*) FROM lineitem WHERE l_comment LIKE '%wake%' OR l_comment LIKE '%regular%' OR l_comment LIKE '%express%' OR l_comment LIKE '%sleep%' OR l_comment LIKE '%hello% | 20.56 秒 |
| SELECT count(*) FROM lineitem WHERE regexp_like(l_comment, 'wake|regular|express|sleep|hello') | 15.87 秒 |
| 速度向上 | 17% 向上 |
9. 近似関数を使う
大規模なデータセットを処理する際の典型的なユースケースとして、COUNT(DISTINCT column) を使って、特定のカラムのユニークな値ごとのレコード数を求めるというものがあります。例として挙げられるのは、ウェブサイトを訪れたユニークユーザーを求めるというものです。
もし正確な値が必要ない場合、例えばサイト内のどのウェブページを突っ込んで調べるべきか判断するといったケースでは、approx_distinct() の使用を検討してみてください。この関数は、全文字列を捜査するかわりに、ユニークなハッシュの数をカウントすることで、メモリ使用量を最小限におさえます。この手法の欠点は、得られた値に 2.3% の標準誤差を持つことです。
例:
データセット: 74GB、無圧縮、テキストフォーマット、6億行
| クエリ | 実行時間 |
| SELECT count(distinct l_comment) FROM lineitem; | 13.21 秒 |
| SELECT approx_distinct(l_comment) FROM lineitem; | 10.95 秒 |
| 速度向上 | 17% 向上 |
詳しくは Presto ドキュメントの Aggregate Functions を参照してください。
10. 必要なカラムだけを読み込む
クエリを実行する際に、すべてのカラムを使用するかわりに、最後の SELECT 句で必要なカラムだけに絞ってください。処理対象のカラム数を減らすことで、クエリの実行パイプライン全体で処理しなければいけないデータ総量を削減できます。これは特に、大量のカラムがあるテーブルや、文字列ベースのカラムが主体のテーブルにクエリを投げるときに有効です。
例:
データセット: 7.25GB、無圧縮、テキストフォーマット、6000万行
| クエリ | 実行時間 |
| SELECT * FROM lineitem, orders, customer WHERE lineitem.l_orderkey = orders.o_orderkey AND customer.c_custkey = orders.o_custkey; | 983 秒 |
| SELECT customer.c_name, lineitem.l_quantity, orders.o_totalprice FROM lineitem, orders, customer WHERE lineitem.l_orderkey = orders.o_orderkey AND customer.c_custkey = orders.o_custkey; | 6.78 秒 |
| 価格削減 / 速度向上 | 145 倍速度向上 |
結論
このポストでは、Amazon Athena および Presto エンジンにおけるインタラクティブ分析を最適化するための、ベストプラクティスについて述べました。これらは Amazon EMR 上で Presto を動かす際にも、同様に適用可能です。
原文: Top 10 Performance Tuning Tips for Amazon Athena (翻訳: SA志村)
R で Amazon Athena を活用する
データサイエンティストはしばしば、R から SQL クエリを投げるときに、その裏側のビッグデータ基盤のインフラ管理を気に掛けなければなりません。Amazon Athena はインフラ管理の必要がなく、標準 SQL で簡単に S3 上のデータを直接分析できる、インタラクティブクエリサービスです。R と Amazon Athena の連携によって、データサイエンティストはインタラクティブな分析ソリューションのための、強力なプラットフォームを手に入れることができます。
このブログポストでは、Amazon EC2 インスタンス上で動作する R/RStudio から Athena に接続します。
事前準備
Athena との連携を開始する前に、以下のステップを完了してください。
- AWS アカウントの管理者に依頼して、Athena にアクセスするのに必要な権限を、Amazon の Identity and Access Management (IAM) コンソール経由で、自身の AWS アカウントに付与してもらってください。具体的には、IAM にあるデータサイエンティストのユーザーグループに対して、関連する Athena のポリシーをアタッチします

- Amazon S3 バケットに、ステージングディレクトリを作成してください。Athena はクエリする対象のデータセットと、クエリ結果を置く場所として、このバケットを利用します。このポストでは、ステージングバケットを s3://athenauser-athena-r とします
注意: このブログポストでは、すべての AWS リソースは us-east-1 リージョンに作成します。ほかのリージョンでも Athena が利用可能かどうか、製品およびサービス一覧で確認してください。
EC2 上での R と RStudio の起動
- “AWS上でRを実行する” のインストラクションにしたがって、EC2 インスタンス(t2.medium かそれ以上のサイズ)で Amazon Linux を動かし、R のセットアップを行います。始める前に、以下のステップを確認しておいてください
- このブログポストの “高度な詳細” の記述で、ステップ 3 まできたら、最新バージョンの RStudio をインストールするため、以下の bash スクリプトを実行してください。必要であれば、RStudion のパスワードも修正してください
#!/bin/bash
#install R
yum install -y R
#install RStudio-Server
wget https://download2.rstudio.org/rstudio-server-rhel-1.0.136-x86_64.rpm
yum install -y --nogpgcheck rstudio-server-rhel-1.0.136-x86_64.rpm
#add user(s)
useradd rstudio
echo rstudio:rstudio | chpasswdJava 8 のインストール
- EC2 instance に SSH でログインします
- 古いバージョンの Java を削除します
- Java 8 をインストールします。これは Athena を動かすために必要です
- コマンドライン上で、以下のコマンドを実行します
#install Java 8, select ‘y’ from options presented to proceed with installation
sudo yum install java-1.8.0-openjdk-devel
#remove version 7 of Java, select ‘y’ from options to proceed with removal
sudo yum remove java-1.7.0-openjdk
#configure java, choose 1 as your selection option for java 8 configuration
sudo /usr/sbin/alternatives --config java
#run command below to add Java support to R
sudo R CMD javareconf
#following libraries are required for the interactive application we build later
sudo yum install -y libpng-devel
sudo yum install -y libjpeg-turbo-devel.Renviron のセットアップ
R の環境変数 .Renviron に対して、必要となる Athena のクレデンシャルを追加します。
- AWS 管理者から、必要なクレデンシャルを AWS_ACCESS_KEY_ID および AWS_SECRET_ACCESS_KEY の形式で取得します
- Linux のコマンドプロンプトから以下のコマンドを打ち込んで、vi エディタを立ち上げます
sudo vim /home/rstudio/.Renviron Provide your Athena credentials in the following form into the editor: ATHENA_USER=< AWS_ACCESS_KEY_ID > ATHENA_PASSWORD=< AWS_SECRET_ACCESS_KEY> - 編集結果をセーブして、エディタを終了します
RStudio にログイン
続いて、EC2 上の RStudio にログインします。
- EC2 のダッシュボードからインスタンスのパブリック IP アドレスを取得して、ブラウザのアドレス欄に貼り付け、後ろに :8787(RStudio のポート番号)を付けます
- EC2 インスタンスに関連付けられたセキュリティグループm設定で、アクセス元の IP アドレスから 8787 ポートへのアクセスが許可されていることを確認してください
- 先ほど設定したユーザ名とパスワードで、RStudio にログインします
R パッケージのインストール
続いて、必要な R パッケージをインストールして、ロードします。
#--following R packages are required for connecting R with Athena
install.packages("rJava")
install.packages("RJDBC")
library(rJava)
library(RJDBC)
#--following R packages are required for the interactive application we build later
#--steps below might take several minutes to complete
install.packages(c("plyr","dplyr","png","RgoogleMaps","ggmap"))
library(plyr)
library(dplyr)
library(png)
library(RgoogleMaps)
library(ggmap)Athena への接続
以下の R のスクリプトで、Athena ドライバーのダウンロードと、コネクションの設定を行います。アクセスしたいリージョンの JDBC URL に接続してください。
#verify Athena credentials by inspecting results from command below
Sys.getenv()
#set up URL to download Athena JDBC driver
URL <- 'https://s3.amazonaws.com/athena-downloads/drivers/AthenaJDBC41-1.0.0.jar'
fil <- basename(URL)
#download the file into current working directory
if (!file.exists(fil)) download.file(URL, fil)
#verify that the file has been downloaded successfully
fil
#set up driver connection to JDBC
drv <- JDBC(driverClass="com.amazonaws.athena.jdbc.AthenaDriver", fil, identifier.quote="'")
#connect to Athena using the driver, S3 working directory and credentials for Athena
#replace ‘athenauser’ below with prefix you have set up for your S3 bucket
con <- jdbcConnection <- dbConnect(drv, 'jdbc:awsathena://athena.us-east-1.amazonaws.com:443/',
s3_staging_dir="s3://athenauser-athena-r",
user=Sys.getenv("ATHENA_USER"),
password=Sys.getenv("ATHENA_PASSWORD"))
#in case of error or warning from step above ensure rJava and RJDBC packages have #been loaded
#also ensure you have Java 8 running and configured for R as outlined earlierこれで RStudio から Athena に接続する準備ができました。
サンプルクエリでテスト
# get a list of all tables currently in Athena
dbListTables(con)
# run a sample query
dfelb=dbGetQuery(con, "SELECT * FROM sampledb.elb_logs limit 10")
head(dfelb,2)
インタラクティブなユースケース
次に、分析と可視化のために R から Athena に対してインタラクティブなクエリを行ってみましょう。S3 上にあるパブリックデータセットの GDELT を使います。
GDELT データセットに対して、R から Athena のテーブルを作成します。このステップは “Amazon Athena – Amazon S3上のデータに対話的にSQLクエリを” で紹介されているように、AWS のマネジメントコンソール上からも実行することができます。
#---sql create table statement in Athena
dbSendQuery(con,
"
CREATE EXTERNAL TABLE IF NOT EXISTS sampledb.gdeltmaster (
GLOBALEVENTID BIGINT,
SQLDATE INT,
MonthYear INT,
Year INT,
FractionDate DOUBLE,
Actor1Code STRING,
Actor1Name STRING,
Actor1CountryCode STRING,
Actor1KnownGroupCode STRING,
Actor1EthnicCode STRING,
Actor1Religion1Code STRING,
Actor1Religion2Code STRING,
Actor1Type1Code STRING,
Actor1Type2Code STRING,
Actor1Type3Code STRING,
Actor2Code STRING,
Actor2Name STRING,
Actor2CountryCode STRING,
Actor2KnownGroupCode STRING,
Actor2EthnicCode STRING,
Actor2Religion1Code STRING,
Actor2Religion2Code STRING,
Actor2Type1Code STRING,
Actor2Type2Code STRING,
Actor2Type3Code STRING,
IsRootEvent INT,
EventCode STRING,
EventBaseCode STRING,
EventRootCode STRING,
QuadClass INT,
GoldsteinScale DOUBLE,
NumMentions INT,
NumSources INT,
NumArticles INT,
AvgTone DOUBLE,
Actor1Geo_Type INT,
Actor1Geo_FullName STRING,
Actor1Geo_CountryCode STRING,
Actor1Geo_ADM1Code STRING,
Actor1Geo_Lat FLOAT,
Actor1Geo_Long FLOAT,
Actor1Geo_FeatureID INT,
Actor2Geo_Type INT,
Actor2Geo_FullName STRING,
Actor2Geo_CountryCode STRING,
Actor2Geo_ADM1Code STRING,
Actor2Geo_Lat FLOAT,
Actor2Geo_Long FLOAT,
Actor2Geo_FeatureID INT,
ActionGeo_Type INT,
ActionGeo_FullName STRING,
ActionGeo_CountryCode STRING,
ActionGeo_ADM1Code STRING,
ActionGeo_Lat FLOAT,
ActionGeo_Long FLOAT,
ActionGeo_FeatureID INT,
DATEADDED INT,
SOURCEURL STRING )
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION 's3://support.elasticmapreduce/training/datasets/gdelt'
;
"
)
dbListTables(con)上記のステートメントを実行すると、RStudio のコンソールに ‘gdeltmaster’ というテーブルが新しく作成されたのを確認できます。

2015 年に US で開かれた CAMEO イベントの回数をカウントするクエリを、Athena テーブルに投げましょう。
#--get count of all CAMEO events that took place in US in year 2015
#--save results in R dataframe
dfg<-dbGetQuery(con,"SELECT eventcode,count(*) as count
FROM sampledb.gdeltmaster
where year = 2015 and ActionGeo_CountryCode IN ('US')
group by eventcode
order by eventcode desc"
)
str(dfg)
head(dfg,2)
#--get list of top 5 most frequently occurring events in US in 2015
dfs=head(arrange(dfg,desc(count)),5)
dfs
上記の R の出力結果から、CAMEO イベントは 42 回という高頻度で行われたことがわかります。CAMEO のマニュアルから、このイベントの概要が “会議やその他のイベントのための、他の地域への出張” となります。
次に、この分析から得られる知見を使い、この特定のイベントに関連したすべての地域の座標リストを、Athena テーブルから取得します。
#--get a list of latitude and longitude associated with event “042”
#--save results in R dataframe
dfgeo<-dbGetQuery(con,"SELECT actiongeo_lat,actiongeo_long
FROM sampledb.gdeltmaster
where year = 2015 and ActionGeo_CountryCode IN ('US')
and eventcode = '042'
"
)
#--duration of above query will depend on factors like size of chosen EC2 instance
#--now rename columns in dataframe for brevity
names(dfgeo)[names(dfgeo)=="actiongeo_lat"]="lat"
names(dfgeo)[names(dfgeo)=="actiongeo_long"]="long"
names(dfgeo)
#let us inspect this R dataframe
str(dfgeo)
head(dfgeo,5)
続いて、アメリカ合衆国の地図を生成します。
#--generate map for the US using the ggmap package
map=qmap('USA',zoom=3)
map
これで、Athena テーブルから得られた地理データが、地図上にプロットされました。これにより、2015 年に US でひらかれたすべての当該イベントについて、開催場所を可視化することができました
。
#--plot our geo-coordinates on the US map
map + geom_point(data = dfgeo, aes(x = dfgeo$long, y = dfgeo$lat), color="blue", size=0.5, alpha=0.5)
結果を可視化することによって、あるイベントの開催場所が US の北東部に極めて集中していることを把握できました。
結論
この記事では Athena と R を使って、簡単なインタラクティブアプリケーションを構築する方法を説明しました。Athena は標準 SQL を用いて、ビッグデータを保存し、それに対してクエリをかけるのに使うことができます。またその一方で、R の持つ強力なライブラリ群を活用することで、Athena に対してインタラクティブにクエリを投げ、分析のインサイトを得ることができます。
質問やアドバイスなどがありましたら、コメント欄にフィードバックをお願いします。
原文: Running R on Amazon Athena (翻訳: SA志村)
AWSでの疎結合データセットの適合、検索、分析
あなたは刺激的な仮説を思いつきました。そして今、あなたは、それを証明する(あるいは反論する)ためにできるだけ多くのデータを見つけて分析したいと思っています。適用可能な多くのデータセットがありますが、それらは異なる人によって異なる時間に作成され、共通の標準形式に準拠していません。異なるものを意味する変数に対して同じ名前を、同じものを意味する変数に対して異なる名前を使用しています。異なる測定単位と異なるカテゴリを使用しています。あるものは他のものより多くの変数を持っています。そして、それらはすべてデータ品質の問題を抱えています(例えば、日時が間違っている、地理座標が間違っているなど)。
最初に、これらのデータセットを適合させ、同じことを意味する変数を識別し、これらの変数が同じ名前と単位を持つことを確認する方法が必要です。無効なデータでレコードをクリーンアップまたは削除する必要もあります。
データセットが適合したら、データを検索して、興味のあるデータセットを見つける必要があります。それらのすべてにあなたの仮説に関連するレコードがあるわけではありませんので、いくつかの重要な変数に絞り込んでデータセットを絞り込み、十分に一致するレコードが含まれていることを確認する必要があります。
関心のあるデータセットを特定したら、そのデータにカスタム分析を実行して仮説を証明し、美しいビジュアライゼーションを作成して世界と共有することができます。
このブログ記事では、これらの問題を解決する方法を示すサンプルアプリケーションについて説明します。サンプルアプリケーションをインストールすると、次のようになります。
- 異なる3つのデータセットを適合させて索引付けし、検索可能にします。
- 事前分析を行い、関連するデータセットを見つけるために、データセットを検索するための、データ駆動のカスタマイズ可能なUIを提示します。
- Amazon AthenaやAmazon QuickSightとの統合により、カスタム解析やビジュアライゼーションが可能です
S3のデータをAmazon Athenaを使って分析する
Amazon Athenaは対話型クエリサービスで、標準的なSQLを使ってAmazon S3の直接データを直接分析することを簡単にしてくれます。Athenaはサーバレスなので、インフラを構築したり管理する必要はなく、今すぐにデータ分析を始めることができます。Athenaはデータをロードしたり、複雑なETL処理をする必要すらありません。S3に保存されているデータに直接クエリすることができます。
Athenaは、クエリを実行する際に分散SQLエンジンのPrestoを利用しています。また、テーブルを作成、削除、変更、パーティションするためにApache Hiveも利用しています。Hive互換のDDL文や、ANSI SQL文をAthenaクエリエディタ内で書くことができます。複雑なJOINやウィンドウ関数、そして複雑なデータ型をAthenaで使うこともできます。Athenaはschema-on-readとして知られるアプローチを取っていて、クエリを実行する時にデータに対してスキーマを定義することができます。これによって、データロードやETLを必要としていません。
Athenaはクエリ毎にスキャンしたデータの量に応じて課金します。データをパーティションしたり、圧縮したり、またはApache Parquet等の列指向フォーマットに変換することでコストを抑えパフォーマンスを向上させることができます。詳しくはAthenaの料金ページをご覧ください。
この記事では、既に決められた形式のテキストファイルで生成されるElastic Load Balancingのログに対して、どのようにAthenaを使うかをお見せします。テーブルを作成し、Athenaで使われる形式でデータをパーティションして、それをParquetに変換してから、クエリのパフォーマンスを比較してみます。