Category: Amazon EMR
HBase on Amazon S3を使用してリードレプリカクラスタをセットアップする
多くのお客様は、低コスト、データ耐久性、スケーラビリティなど、Amazon S3をデータストレージとしてApache HBaseを実行することの利点を活用しています。 FINRAのような顧客は、HBase on S3アーキテクチャーに移行し、ストレージをコンピュートから切り離し、S3をストレージレイヤーとして使用するという多くの運用上の利点とともに、コストを60%削減しました。 HBase on S3を使用すると、クラスタを起動して、長いスナップショット復元プロセスを経る必要がなく、S3内のデータに対してすぐにクエリを開始することができます。
Amazon EMR 5.7.0の発表により、HBase on S3の高可用性と耐久性をクラスタレベルにさらに一歩進化させることができます。S3上の同じHBaseルートディレクトリに接続できる複数のHBase読み取り専用クラスタを開始できます。これにより、リードレプリカクラスタを介して常にデータにアクセスできることを保証し、複数のアベイラビリティゾーンにわたってクラスタを実行できます。
この記事では、HBase on S3を使用したリードレプリカクラスタの設定をご案内します。
Amazon EMRでS3DistCpを使用してHDFSとAmazon S3間で効率的にデータを移動するための7つのヒント
Amazon S3とHadoop Distributed File System(HDFS)の間で大量のデータを移動する必要があったものの、データセットが単純なコピー操作には大きすぎるということはありませんでしたか? EMRはこれを救うことができます。ペタバイト級のデータの処理と分析に加えて、EMRは大量のデータの移動もできます。
Hadoopエコシステムでは、DistCpがデータを移動するためによく使用されます。 DistCpは、MapReduceフレームワークの上に構築された分散コピー機能を提供します。 S3DistCpは、S3で動作するように最適化されたDistCpの拡張機能であり、いくつかの便利な機能が追加されています。 S3DistCpは、HDFSとS3の間でデータを移動するだけでなく、ファイル操作のスイスアーミーナイフです。この記事では、S3DistCpを使用するための基本的なユースケースから始めて、さらに高度なシナリオまでのヒントについて説明します。
HDFSからAmazon S3へApache HBaseを移行するためのヒント
Amazon EMR 5.2.0以降、Amazon S3上でApache HBaseを実行することができます。 S3上でHBaseを実行すると、コストの削減、データ耐久性の向上、スケーラビリティの向上など、いくつかの利点が追加されます。
HBaseには、HBaseテーブルの移行およびバックアップに使用できるいくつかのオプションがあります。 S3のHBaseに移行する手順は、Apache Hadoop分散ファイルシステム(HDFS)のHBaseの手順と似ていますが、細かな違いといくつかの「落とし穴」を認識していれば、移行がより簡単になります。
この記事では、一般的なHBase移行オプションのいくつかを使用してS3のHBaseを開始する方法を説明します。
HBaseの移行オプション
正しい移行方法とツールを選択することは、HBaseテーブルの移行を成功させる上で重要なステップです。しかし、正しいものを選ぶことは、必ずしも簡単な作業ではありません。
次のHBaseの機能が、S3のHBaseに移行するのに役立ちます:
- スナップショット
- エクスポートとインポート
- CopyTable
次の図は、各オプションの手順をまとめたものです。

さまざまな要因によって、使用するHBaseの移行方法が決まります。たとえば、EMRでは、S3で実行できる最初のバージョンとしてHBaseバージョン1.2.3が提供されています。したがって、移行元のHBaseバージョンが、移行方法を決決めるのに役立つ重要な要素になります。 HBaseのバージョンと互換性の詳細については、Apache HBaseリファレンスガイドのHBaseのバージョン番号と互換性のマニュアルを参照してください。
旧バージョンのHBase(HBase 0.94など)から移行する場合は、アプリケーションをテストして、新しいHBase APIバージョンと互換性があることを確認する必要があります。アプリケーションとAPIにHBaseバージョンの違いによる問題があることを確認するためだけに、大きなテーブルを移行して数時間を費やすことは望ましくありません。
良い知らせとしては、HBaseはテーブルの一部だけを移行するために使用できるユーティリティを提供していることです。これにより、HBaseテーブル全体を完全に移行することなく、既存のHBaseアプリケーションをテストすることができます。たとえば、Export、Import、またはCopyTableユーティリティを使用して、テーブルの一部分をS3のHBaseに移行できます。アプリケーションが新しいHBaseバージョンで動作することを確認したら、HBaseスナップショットを使用してテーブル全体を移行することができます。
AWS上でApache Flinkを使用してリアルタイムストリーム処理パイプラインを構築する
今日のビジネス環境では、多様なデータソースが着実に増加していく中で、データが継続的に生成されています。したがって、このデータを継続的にキャプチャ、格納、および処理して、大量の生データストリームを実用的な洞察に素早く繋げることは、組織にとって大きな競争上のメリットになっています。
Apache Flinkは、このようなストリーム処理パイプラインの基礎を形成するのに適したオープンソースプロジェクトです。ストリーミングデータの継続的な分析に合わせたユニークな機能を提供しています。しかし、Flinkを基にしたパイプラインの構築と維持には、物理的なリソースと運用上の努力に加え、かなりの専門知識が必要になることがよくあります。
この記事では、Amazon EMR、Amazon Kinesis、Amazon Elasticsearch Serviceを使用してApache Flinkを基にした、一貫性のあるスケーラブルで信頼性の高いストリーム処理パイプラインの参照アーキテクチャの概要を説明します。 AWSLabs GitHubリポジトリは、実際に参照アーキテクチャを深く理解するために必要なアーティファクトを提供します。リソースには、サンプルデータをAmazon Kinesisストリームに取り込むプロデューサアプリケーションと、リアルタイムでデータを分析し、その結果をAmazon ESに可視化するためのFlinkプログラムが含まれています。
EMRFSを利用して、別AWSアカウントからデータを安全に分析する
分析されるデータは、異なるアカウントが所有するバケットに分散されることがあります。データのセキュリティを確保するためには、適切な認証情報管理が必要です。これは、さまざまな部門の異なるAmazon S3バケットにデータを格納している大企業にとって特に当てはまります。例えば、顧客サービス部門は、研究部門が所有するデータにアクセスする必要があるかもしれませんが、研究部門はそのアクセスを安全な方法で提供する必要があります。
データを保護するこの側面は非常に複雑になる可能性があります。 Amazon EMRは、統合メカニズムを使用して、S3に格納されたデータにアクセスするためのユーザー認証情報を提供します。 EMR上でアプリケーション(Hive、Sparkなど)を使用してS3バケットとの間でファイルを読み書きする場合、S3 API呼び出しには認証するための適切な認証情報で署名する必要があります。
通常、これらの認証情報は、クラスターの起動時に指定するEC2インスタンスプロファイルによって提供されます。そのオブジェクトが異なる認証情報セットを必要とするため、EC2インスタンスプロファイルの認証情報がS3オブジェクトにアクセスするのに十分でない場合はどうなるでしょうか?
このポストは、カスタム認証プロバイダを使用して、EMRFSのデフォルトの認証プロバイダがアクセスできないS3オブジェクトにアクセスする方法を示しています。
新機能 – Amazon EMR インスタンスフリート
今日は、インスタンスフリートと呼ばれる Amazon EMR クラスターの新機能をご紹介します。インスタンスフリートは、インスタンスのプロビジョニングに広範囲な選択肢やインテリジェンスをもたらします。対応する加重容量やスポット入札価格 (スポットブロックを含む) を最大 5 つのインスタンスタイプのリストに追加できるようになりました。EMR は、クラスター作成時にこれらのインスタンスタイプの間でオンデマンドおよびスポット容量を自動的にプロビジョニングします。そのため、これまでよりも簡単かつ低コストに、希望のクラスター容量をすばやく取得して管理することができます。また、アベイラビリティーゾーンのリストを指定することもでき、EMR は、このうちのいずれかの AZ で最適にクラスターを起動します。また、EMR は、インスタンスをフリートの利用可能ないずれかのタイプに置換することで、スポットインスタンスの中断に備えてクラスターの再分散を続けます。その結果、クラスター容量全体を容易に管理できます。インスタンスフリートは、インスタンスグループの代わりに使用することもできます。グループと同様、クラスターには、マスター、コア、タスクフリートが作成されます。コンソールのアップデートを確認し、フリートの動作について詳しく調べてみましょう。EMR コンソールを開き、[クラスターの作成] ボタンをクリックします。なじみのある EMR プロビジョニングコンソールが表示されたら、左上隅付近にある詳細オプションに移動します。最新の EMR バージョン (インスタンスフリートは、5.0.x を除く 4.8.0 以上の EMR バージョンで使用可能) を選択し、[次へ] をクリックします。これで正常に表示されます。ハードウェアオプションの新しい [インスタンスフリート] を選択します。
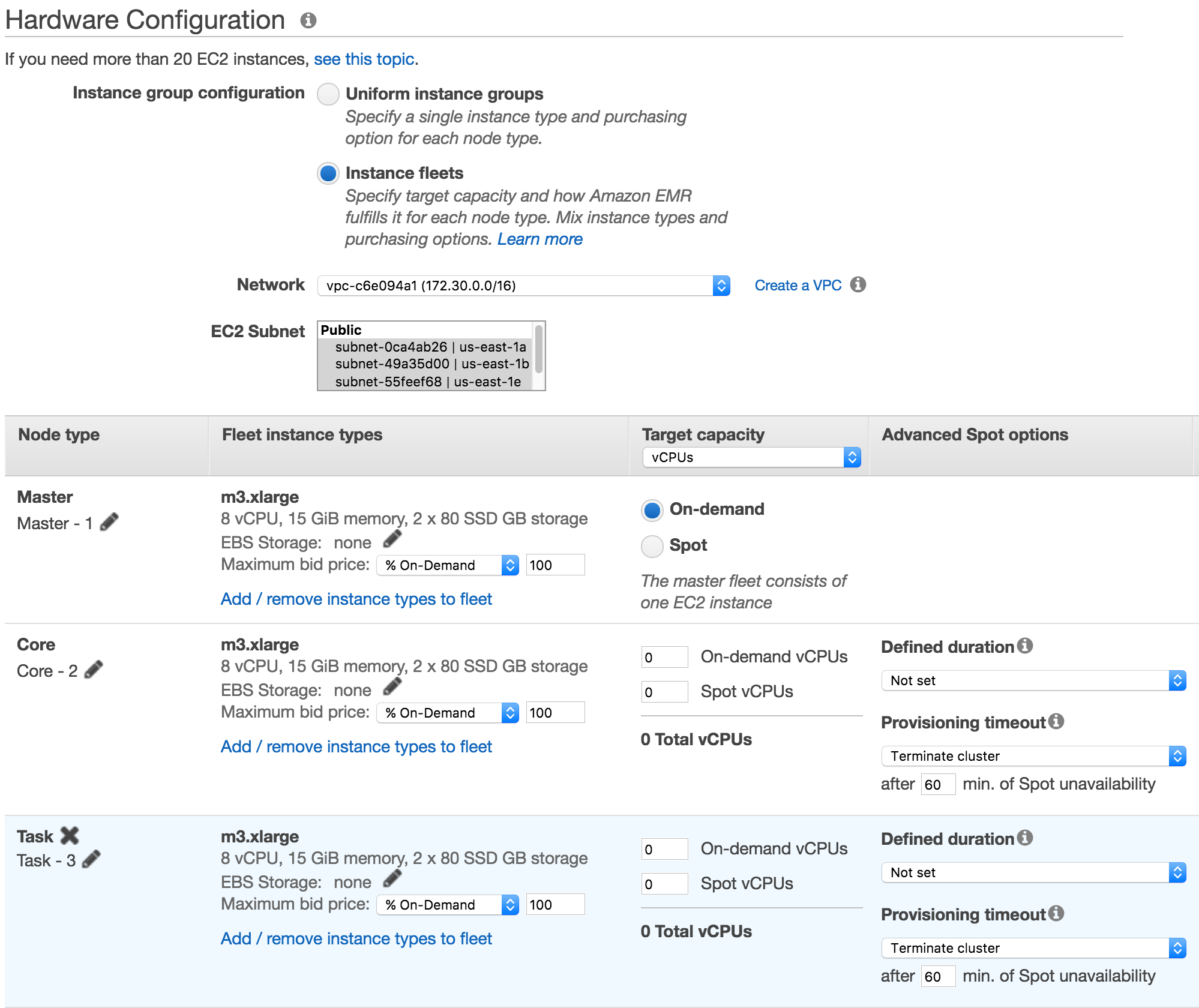 ここで、コアグループを変更して、クラスターのニーズを満たす一組のインスタンスタイプを選択します。
ここで、コアグループを変更して、クラスターのニーズを満たす一組のインスタンスタイプを選択します。
EMR は、最もコスト効率の高い方法で要件を満たせるように、各インスタンスフリートとアベイラビリティーゾーンの容量をプロビジョニングします。EMR コンソールでは、インスタンスタイプごとに vCPU を加重容量と簡単にマッピングできるため、vCPU を容量ユニットとして使用しやすくなります (コアフリートに合計 16 個の vCPU が必要)。vCPU ユニットが、インスタンスタイプの分量指定に関する条件に一致しない場合は、[Target capacity] セレクタを変更して、任意のユニットを追加し、容量を定義します (API/CLI によるキャパシティーユニットの消費量も変更されます)。クラスターがプロビジョニングされており、ユーザー定義のタイムアウト内に希望のスポット容量を入手できない場合は、オンデマンドインスタンスを終了またはフォールバックして、残りのキャパシティーをプロビジョニングできます。また、インスタンスフリートで使用されるこれらの機能はすべて、「AWS SDK」および「CLI」より入手できます。インスタンスフリートをプロビジョニングする方法を詳しく見てみましょう。まず、my-fleet-config.json に configuration json を作成します。
[
{
"Name": "MasterFleet",
"InstanceFleetType": "MASTER",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [{"InstanceType": "m3.xlarge"}]
},
{
"Name": "CoreFleet",
"InstanceFleetType": "CORE",
"TargetSpotCapacity": 11,
"TargetOnDemandCapacity": 11,
"LaunchSpecifications": {
"SpotSpecification": {
"TimeoutDurationMinutes": 20,
"TimeoutAction": "SWITCH_TO_ON_DEMAND"
}
},
"InstanceTypeConfigs": [
{
"InstanceType": "r4.xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 50,
"WeightedCapacity": 1
},
{
"InstanceType": "r4.2xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 50,
"WeightedCapacity": 2
},
{
"InstanceType": "r4.4xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 50,
"WeightedCapacity": 4
}
]
}
]これで、設定が完了し、AWS CLI の「emr」サブコマンドを使用して、この構成で新しいクラスターを作成できるようになりました。
aws emr create-cluster --release-label emr-5.4.0 \
--applications Name=Spark,Name=Hive,Name=Zeppelin \
--service-role EMR_DefaultRole \
--ec2-attributes InstanceProfile="EMR_EC2_DefaultRole,SubnetIds=[subnet-1143da3c,subnet-2e27c012]" \
--instance-fleets file://my-fleet-config.json
追加料金をかけずに、今すぐこの機能を使用する場合は、「開始に役立つドキュメントはこちら」で詳細を確認できます。本記事を寄稿するにあたりご協力いただいた EMR サービスチームの皆様にこの場を借りて御礼申し上げます。
AWSでの疎結合データセットの適合、検索、分析
あなたは刺激的な仮説を思いつきました。そして今、あなたは、それを証明する(あるいは反論する)ためにできるだけ多くのデータを見つけて分析したいと思っています。適用可能な多くのデータセットがありますが、それらは異なる人によって異なる時間に作成され、共通の標準形式に準拠していません。異なるものを意味する変数に対して同じ名前を、同じものを意味する変数に対して異なる名前を使用しています。異なる測定単位と異なるカテゴリを使用しています。あるものは他のものより多くの変数を持っています。そして、それらはすべてデータ品質の問題を抱えています(例えば、日時が間違っている、地理座標が間違っているなど)。
最初に、これらのデータセットを適合させ、同じことを意味する変数を識別し、これらの変数が同じ名前と単位を持つことを確認する方法が必要です。無効なデータでレコードをクリーンアップまたは削除する必要もあります。
データセットが適合したら、データを検索して、興味のあるデータセットを見つける必要があります。それらのすべてにあなたの仮説に関連するレコードがあるわけではありませんので、いくつかの重要な変数に絞り込んでデータセットを絞り込み、十分に一致するレコードが含まれていることを確認する必要があります。
関心のあるデータセットを特定したら、そのデータにカスタム分析を実行して仮説を証明し、美しいビジュアライゼーションを作成して世界と共有することができます。
このブログ記事では、これらの問題を解決する方法を示すサンプルアプリケーションについて説明します。サンプルアプリケーションをインストールすると、次のようになります。
- 異なる3つのデータセットを適合させて索引付けし、検索可能にします。
- 事前分析を行い、関連するデータセットを見つけるために、データセットを検索するための、データ駆動のカスタマイズ可能なUIを提示します。
- Amazon AthenaやAmazon QuickSightとの統合により、カスタム解析やビジュアライゼーションが可能です
暗号化を用いたセキュアな Amazon EMR
ここ数年で、エンタープライズ企業において Apache hadoop エコシステムを用いて、センシティブであったり、きわめて秘匿性が高かったりするデータを扱う、重要なワークロードを走らせるケースが非常に増えてきています。そうしたワークロードの特性により、エンタープライズ企業ではしっかりした組織/業界全体のポリシーや、規制、コンプライアンスのルールを定めています。それに基づいて、機密データの保護や、権限のない人がアクセスできないようにすることが求められています。
こうしたポリシーにおいては一般的に、データストアに保存されているとき、そしてデータを転送しているときの両方で暗号化が要求されます。Amazon EMR では “セキュリティ設定” を使うことで、AWSキーマネジメントサービス (KMS) からお客様自身が用意した暗号化要素まで、さまざまな暗号化キーや証明書を指定することができます。
暗号化設定についてのセキュリティ設定を作り、クラスター作成の際に、その設定を当てることができます。セキィリティ設定を一度作っておくことで、いくつものクラスターにその設定を簡単に適用可能です。

この投稿ではEMRのセキュリティ設定による、複数段階のデータ暗号化のセットアッププロセスを概観します。暗号化について深く見ていく前に、データ暗号化が必要な状況を整理しましょう。
保存時のデータ
- Amazon S3にあるデータ – EMRのS3クライアントサイド暗号化
- ディスク上のデータ – Linux Unified Key System (LUKS) による、Amazon EC2 のインスタンスストアボリューム(ブートボリュームを除く)、クラスターインスタンスにアタッチされた Amazon EBS
ボリューム
転送中のデータ
- EMRからS3に転送中のデータ、またはその逆 – EMR の S3 クライアントサイド暗号化
- クラスター内のノード間で転送中のデータ – Secure Socket Layer (SSL) による MapReduce の in-transit 暗号化と、Simple Authentication と Security Layer (SASL) による Spark の shuffle 暗号化
- ディスクに溢れたデータ、またはシャッフルフェーズの最中にキャッシュされたデータ – Spark の shuffle 暗号化、またはLUKS 暗号化
暗号化の手順
この投稿のために、転送中、保存時の暗号化に使うためのセキュリティ設定を作りましょう。
- EMRやS3にあるデータに対して、LUKS 暗号化やS3 クライアントサイド暗号化のための KMS キー
- MapReduce のshuffle 暗号化で使用する SSL 証明書
- EMR クラスタが立ち上げられる環境。プライベートサブベットで EMR を立ち上げて、S3 からデータを取得するための VPC エンドポイントを設定します
- EMR セキュリティ設定
この手順で説明するすべてのスクリプトとコードスニペットは、aws-blog-emrencryption Github レポジトリから取得できます。
KMS キーの生成
この手順では鍵管理について、データやディスクを暗号化するために使用する暗号化キーを、簡単に生成、管理できるマネージドサービスの、AWS KMS を使用します。
2つの KMS マスターキーを生成します。ひとつは EMR外のデータを暗号化する S3 クライアントサイド暗号化キーとして、もうひとつはローカルディスクを暗号化するための LUKS 暗号化のキーとして使用します。 Hadoop MapReduce フレームワークは HDFS を使用します。Spark は、ワークロードの中でメモリから溢れた中間データを一時的に保存する先として、各スレーブインスタンスのローカルファイルシステムを使用します。
鍵を生成するために、kms.json という AWS CloudFormation スクリプトを使用します。スクリプトの中で、キーの エイリアス名またはディスプレイ名を指定します。エイリアスは “alias/エイリアス名” 形式で、エイリアス名はアルファベット、アンダースコア、ダッシュのみで構成される必要があります。

キーの作成が終わったら、Outputs として ARN が表示されます。

SSL 証明書の作成
SSL 証明書によって、Mapreduce のシャッフル中にデータがノード間を転送されるときに、データの暗号化が行われます。

この手順では、OpenSSL で 2048-bit RSA 秘密鍵による X.509 自己署名証明書を作成します。これを使って EMR クラスタのインスタンスにアクセスします。画面に従って、証明書発行に必要な情報を入力します。
cert-create.sh を使って、zip ファイルに圧縮した SSL 証明書を生成します。zip 圧縮済みの証明書を S3 にアップロードし、S3 のプレフィックスをメモしておきます。セキュリティ設定を構成するときには、この S3 プレフィックスを使用します。
重要
この例は、あくまで proof-of-concept のデモにすぎません。自己署名証明書を使うことは推奨されませんし、潜在的なセキュリティリスクを孕みます。実運用システムでは、信頼できる認証局が発行した証明書を使ってください。
カスタムプロバイダの証明書には、TLSArtifacts プロバイダインタフェースを使用してください。
環境の構築
EMR クラスタをプライベートサブネットに構築します。もしすでに VPC があり、パブリックサブネットにクラスターを立てたい場合には、このセクションを飛ばして、セキュリティ設定の作成のセクションに進んでください。
クラスターをプライベートサブネット内に立てるためには、以下のリソースが必要です。
- VPC
- プライベートサブネット
- パブリックサブネット
- 踏み台サーバ
- マネージド NAT ゲートウェイ
- S3 VPC エンドポイント
EMR クラスターをプライベートサブネットに立てる際には、クラスターに SSH で入るための踏み台サーバかジャンプサーバが必要になります。クラスターの起動が終わったら、KMS からデータキーを取得するためにインターネットに接続する必要があります。プライベートサブネットからは直接インターネットに接続できないので、マネージド NAT ゲートウェイ経由でトラフィックの経路を制御します。S3 に対して、高信頼性を確保して安全に接続するために、S3 VPC エンドポイントを使用します。

CloudFormation コンソールで、environment.json テンプレートを使って、環境構築用の新しいスタックを作成します。
パラメタとして、踏み台サーバのインスタンスタイプと、そのサーバに SSH アクセスするための EC2 キーペアを入力します。適切なスタック名とタグを指定します。例えば、私の作成したスタックのレビューステップのスクリーンショットは、以下の通りになります。

スタックの作成が終わったら、Outputs タブを開いて VPC、踏み台サーバ、プライベートサブネットのIDをメモしておきます。これらはあとで EMR クラスタを立ち上げる際に使用します。

セキュリティ設定の作成
セキュアな EMR クラスタを立ち上げる前の最終ステップは、セキュリティ設定の構成です。EMR の S3 クライアントサイド暗号化と、先ほど作成した KMS キーを用いたローカルファイルの LUKS 暗号化について、セキュリティ設定を作成します。さらに MapReduce のシャッフルで暗号化を行うために、先ほど作成して S3 にアップロードしておいた SSL 証明書も使用します。

EMR クラスターの立ち上げ
さて、これでプライベートサブネットに EMR クラスタを立ち上げることができるようになりました。まずサービスロールとして、サービスポリシー内の AmazonElasticMapReduceRole が EMR に割り当てられていることを確認します。デフォルトのサービスロールは EMR_DefaultRole です。詳しくはIAMロールを使用したユーザーアクセス権限の設定を参照してください。
環境の設定セクションでメモしておいた VPC ID とサブネット ID の中で、EMR クラスタを立ち上げます。Network と EC2 Subnet フィールドで、それらの値を選択してください。続いてクラスタの名前とタグを入力します。

最後のステップはプライベートキーの選択です。ここでは、セキュリティ設定の作成セクションで作っておいたセキュリティ設定を適用します。そして Create Cluster をクリックします。

これで作成した環境の上で、クラスタが立ち上がりました。続いてマスターノードに入ってスクリプトを実行します。EMR コンソールページからクラスタの IP アドレスを取得します。Hardware、Master Instance Group と選択して、マスターノードのプライベート IP アドレスをメモします。

マスターノードはプライベートサブネット内にあるので、まず踏み台サーバに SSH で入り、そこからさらにマスターノードに接続します。踏み台サーバと Hadoop マスタへの SSH については、ssh-commands.txt ファイルをみてください。踏み台サーバへのアクセスについてのさらなる詳細は、Securely Connect to Linux Instances Running in a Private Amazon VPC のエントリーを参照してください。
マスターノードに入った後は、Hive や Spark のスクリプトを実行します。動作確認用として、GitHub /code ディレクトリには PySpark の test.py と Hiveの test.q スクリプトが含まれています。
まとめ
この投稿の中で、データの暗号化が必要な複数のパターンについて述べ、各パターンでどうやって暗号化するかについての手順を説明しました。そして暗号化の前提要件である KMS キーの作成、SSL 証明書の発行、強力なセキュリティ設定による EMR クラスタの立ち上げについて、順を追って解説しました。そして VPC 内のプライベートサブネットでのクラスター起動によって、データをセキュアに
保つとともに、EMR クラスターにアクセスするために踏み台サーバを活用することができました。
もし疑問や助言があれば、ぜひおしらせください。
(翻訳はSA志村が担当しました。原文はこちら)
Auto Scalingを利用して、Amazon EMRのアプリケーションを動的にスケールする
Apache SparkやPresto、Apache Hadoopエコシステムを利用しているお客様は、ワークフローの完了次第クラスターを終了させることや、安価なAmazon EC2スポットインスタンスを利用してクラスターをリサイズをすることよってコスト節約するために、Amazon EMRの弾力性を活用しています。例えば、お客様は日次のETLや機械学習処理のためにクラスターを作成し、それらの処理が完了したらクラスターを終了させるということや、BI分析者がアドホックでレイテンシーの低いSQLをAmazon S3に置かれたデータに対して行えるよう、業務時間帯のみPrestoクラスターをスケールアウトする、ということが可能です。
Amazon EMRリリース4.xと5.xで新しくサポートされたAuto Scalingによって、お客様は、クラスターのノードを、より簡単に追加(スケールアウト)や削除(スケールイン)できます。スケーリングの動作は、EMRから提供される5分間隔のAmazon CloudWatchメトリクスによって、自動的にトリガーされます。トリガーになるメトリクスには、メモリ利用、未実行アプリケーションの状態、HDFS利用、に関連するいくつかのYARNメトリクスも含まれます。
EMRリリース5.1.0には、2つの新しいメトリクスが導入されました。YARNMemoryAvailablePercentageとContainerPendingRatioです。これらは、Apache SparkやApache Tez、そして、Apache Hadoop MapReduceのような、スケーラブルなYARNベースのフレームワーク向けの、クラスターの利用状況を知るのに便利なメトリクスです。さらに、お客様は、カスタムCloudWatchメトリクスをAuto Scalingポリシーに利用することもできます。
以下は、最大40・最小10インスタンスで、一度に1インスタンスずつ増減する、インスタンスグループに対するAuto Scalingポリシーの例示です。インスタンスグループは、YARN内の利用可能なメモリが15%を下回ると、スケールアウトし、75%を上回るとスケールインします。また、インスタンスグループは、割り当てられているYARNコンテナに対するYARNコンテナの未実行率が0.75になった場合も、スケールアウトします。
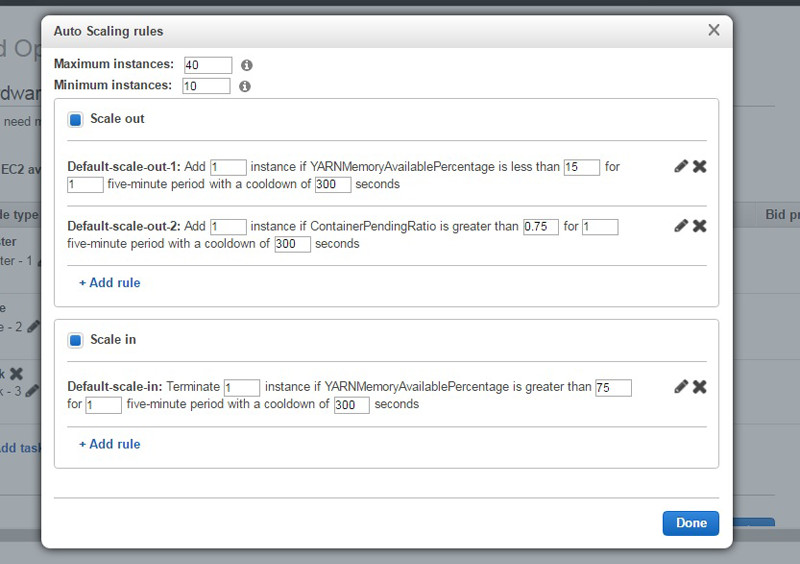
さらに、お客様は、EMR 5.1.0のクラスターによってノードが終了される際に、スケールダウンの振る舞いを設定することができます。デフォルトで、EMRは、いかなるタイミングで終了リクエストが投げられたとしても、インスタンス時間単位の境目に実施されるスケールインイベントの最中のみ、ノードの停止を行います。これは、EC2は、いつインスタンスを終了したかに関わらず、時間単位で請求をするためです。この振る舞いによって、クラスター上で実行されているアプリケーションは、コスト効率をより高く、動的にスケールする環境で、インスタンスを利用することができます。
反対に、5.1.0より前のEMRリリースでは、お客様は、以前のデフォルト設定を利用できます。インスタンス時間単位の境目に近接しているかどうかを考慮せず、ノードを終了する前に、ノードをブラックリストしたり、タスクを排出したり、ということが可能です。いずれの振る舞いにおいても、EMRは、まず最も動きの少ないノードを削除しますし、HDFSの不整合を招き得る場合は、終了処理をブロックします。
EMRコンソール、AWS CLI、または、AWS SDKのEMR APIを利用して、Auto Scalingポリシーの作成や変更ができます。Auto Scalingを有効にするためには、Auto Scalingで容量の追加・削除を行うための権限を付与すべく、追加のIAMロールをEMRに与える必要があります。さらに詳細な情報は、Amazon EMRでのAuto Scalingを確認して下さい。また、もし、EMRでのAuto Scalingに関して、ご質問や公開したい面白い事例などございましたら、コメントを下に書いていただければと存じます。
原文: Dynamically Scale Applications on Amazon EMR with Auto Scaling (翻訳: 半場 光晴)
さあ、Amazon EMRで、Apache Flinkを使って、大規模なリアルタイムストリーム処理を実行しよう
Amazon EMR リリース5.1.0
Amazon EMRリリース5.1.0で、Apache Flink 1.1.3と、バージョンアップしたApache Zeppelin(0.6.2)とApache HBase(1.2.3)が利用できるようになりました。また、Hueのinteractive notebookが、Prestoを用いたクエリをサポートしました。
Apache Flinkは、高スループットのデータソースに対して、簡単にリアルタイムストリーム処理を実行できる、ストリーミングデータフローエンジンです。順不同なイベントに対するイベントタイムセマンティクスや、exactly-onceセマンティクス、バックプレッシャー制御、そして、ストリーミングとバッチ処理どちらにも最適化されたAPIを兼ね備えています。さらに、Flinkは、Amazon Kinesis StreamsやApache Kafka、Elasticsearch、Twitter Streaming API、それから、Cassandraへのコネクターを持っており、さらに、Amazon S3(EMRFS経由)やHDFSにアクセスすることもできます。
AWSマネージメントコンソール、AWS CLI、または、SDKから、リリースラベル「emr-5.1.0」を選択して、リリース5.1.0のAmazon EMRクラスターを作成することができます。Flink、Zeppelin、それから、HBaseを指定して、これらのアプリケーションをクラスターにインストールすることができます。リリース5.1.0や、Flink 1.1.3、Zeppelin 0.6.2、HBase 1.2.3についての、より詳細な情報については、Amazon EMRのドキュメントをぜひご確認下さい。(原文)
Amazon EMRでApache Flinkを利用する
Apache Flinkは、お客様の間でリアルタイムビッグデータアプリケーションを構築するために使われている、並列データ処理エンジンです。Flinkによって、例えばAmazon Kinesis StreamsやApache Cassandraデータベースのような、たくさんの異なるデータソースを変換することができるようになります。バッチとストリーミングどちらのAPIも提供しています。また、Flinkは、これらのストリームやバッチデータセットに対するSQLも、多少サポートしています。多くのFlinkのAPIのアクションは、Apache HadoopやApache Sparkにおける分散オブジェクトコレクションの変換と、非常に類似しています。FlinkのAPIは、DataSetとDataStreamに分類されます。DataSetは、分散データのセットやコレクションの変換ですが、一方で、DataStreamは、Amazon Kinesisに見られるようなストリーミングデータの変換です。
Flinkは、純粋なデータストリーミング実行エンジンです。リアルタイムに以前のデータ変換結果を操作するためのパイプライン並列処理を有しています。つまり、複数の操作を並行して実行できます。Flinkのランタイムは、これらの変換パイプライン間のデータの交換をハンドリングします。また、例えバッチ処理を記述したとしても、同一のFlinkストリーミングデータフローランタイムが、その処理を実行します。
Flinkのランタイムは、2つの異なるタイプのデーモンで構成されています。スケジューリング、チェックポイント、リカバリーといった機能をまとめる責任を担うJobManagerと、アプリケーション内のストリーム間のデータ転送やタスクの実行を担うワーカープロセスであるTaskManagerです。それぞれのアプリケーションは、ひとつのJobManagerと、ひとつ以上のTaskManagerを持ちます。
TaskManagerの数をスケールさせることができますが、同時に「タスクスロット」と呼ばれるものを使って、並列処理をさらに制御しなければなりません。Flink-on-YARNでは、JobManagerは、YARNのApplicationMasterに内包されます。一方で、個々のTaskManagerは、そのアプリケーションのために割り当てられた別々のYARNコンテナに配置されます。
本日(11/3)、Amazon EMRリリース5.1.0でネイティブサポートしたことにより、AWS上でFlinkを実行することが、さらに簡単になりました。EMRがFlink-on-YARNの実行をサポートしたことにより、複数のジョブを受け付けるロングランニングクラスターを作成することも、利用中の料金のみにコストを抑えるために一時的なクラスターでショートランニングのFlinkセッションを作成することも、どちらも可能です。
ロギングや設定パラメータ用の設定分類を、EMRの設定APIを使って、Flinkがインストールされたクラスターに設定することもできます。
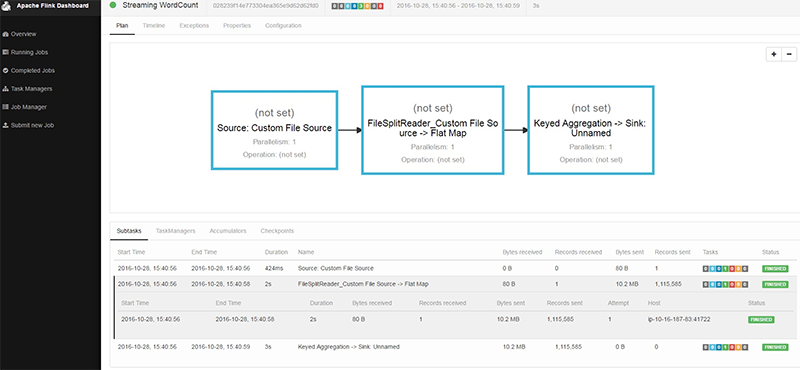
直接EMRコンソールから、もしくは、以下のようにCLIを実行すれば、今日からEMRでFlinkの利用を開始できます。
aws emr create-cluster --release-label emr-5.1.0 \ --applications Name=Flink \ --region us-east-1 \ --log-uri s3://myLogUri \ --instance-type m3.xlarge \ --instance-count 1 \ --service-role EMR_DefaultRole \ --ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
Apache Flinkについてもっと知りたいという方は、Apache Flinkのドキュメントをご確認下さい。そして、EMRでのFlinkについてもっと知りたいという方は、ぜひAmazon EMRリリースガイドのFlinkトピックをご確認下さい。(原文)
翻訳: 半場 光晴