Category: Amazon Kinesis
Amazon Kinesis Streams のサーバーサイド暗号化
昨今ではスマートホーム、ビッグデータ、IoT デバイス、携帯電話、ソーシャルネットワーク、チャットボット、ゲームコンソールなどが一般的に普及しており、ストリーミングデータはごく普通のことになりました。Amazon Kinesis Streams は、何千ものストリーミングデータソースから毎時間ごとにテラバイト単位のデータをキャプチャ、処理、分析、保存できるカスタムアプリケーションの構築を可能にしています。Amazon Kinesis Streams では、アプリケーションが同じ Kinesis ストリームから同時にデータを処理することができるので、並列処理システムを構築することができます。たとえば、処理済みのデータを Amazon S3 だけに送信するようにし、Amazon Redshift で複雑な分析を行ったり、AWS Lambda を使用する堅牢なサーバーレスストリーミングソリューションを構築することもできます。
Kinesis Streams では消費者が複数のストリーミングユースケースを利用できるようにしていますが、今後は Kinesis Streams でサーバー側の暗号化 (SSE) をサポートすることにより、移動中のデータをより効率的に保護できるようになりました。この新しい Kinesis Streams の機能により、データのセキュリティを強化したり、組織のデータストリーミングで必要となる様々な規制とコンプライアンス要件を満たすことができます。
Kinesis Streams は Payment Card Industry Data Security Standard (PCI DSS) のコンプライアンスプログラムで AWS 対象範囲内サービスの 1 つになっているほどです。PCI DSS は、主要な金融機関が設立した PCI Security Standards Council が管轄する専有情報のセキュリティ基準です。PCI DSS コンプライアンスは、カード所有者のデータやサービスプロバイダを含む機密性の高い認証データを保存、処理、転送する機関すべてに適用されます。AWS Artifact を使用して、PCI DSS Attestation of Compliance や Responsibility Summary をリクエストすることができます。Kinesis Streams とのコンプライアンスにおけるメリットはこの他にもあります。Kinesis Streams は AWS GovCloud の FedRAMP にも準拠しています。FedRAMP は Federal Risk and Authorization Management Program の略で、米国政府全体のプログラムであり、クラウド製品およびサービス向けのセキュリティ評価、認証、継続的なモニタリングに関する標準化されたアプローチを提供するものです。AWS サービスの FedRAMP コンプライアンスに関する詳細についてはこちらをご覧ください。
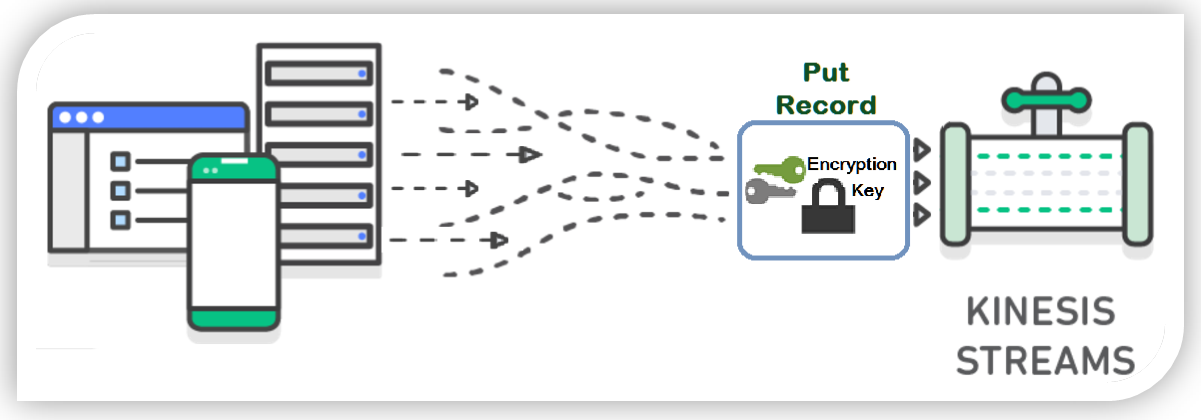
さあ、いかがでしょう? 興味が湧いてきましたか?今すぐ始めてみましょう!でもとりあえず、後もう少し説明してみます。Kinesis Streams の SSE に触れたので、Kinesis におけるサーバー側の暗号化の流れについて解説しておきます。PutRecord または PutRecords API を使用して Kinesis Stream に含んだデータレコードやパーティションキーは AWS Key Management Service (KMS) マスターキーを使用して暗号化されています。AWS Key Management Service (KMS) のマスターキーを使用し、Kinesis Streams は 256 ビットの Advanced Encryption Standard (AES-256 GCM アルゴリズム) を使って受信データに暗号化を追加します。
新規または既存のストリームに Kinesis Streams でサーバー側の暗号化を有効にするには、Kinesis マネジメントコンソールを使用、または利用可能な AWS SDK の 1 つを使います。また、ストリームの暗号化の履歴を監査したり、Kinesis Streams コンソールで特定のストリームの暗号化ステータスの検証や、PutRecord または GetRecord トランザクションが AWS CloudTrail サービスを使用して暗号化されているか確認することができます。
チュートリアル: Kinesis Streams でのサーバー側の暗号化
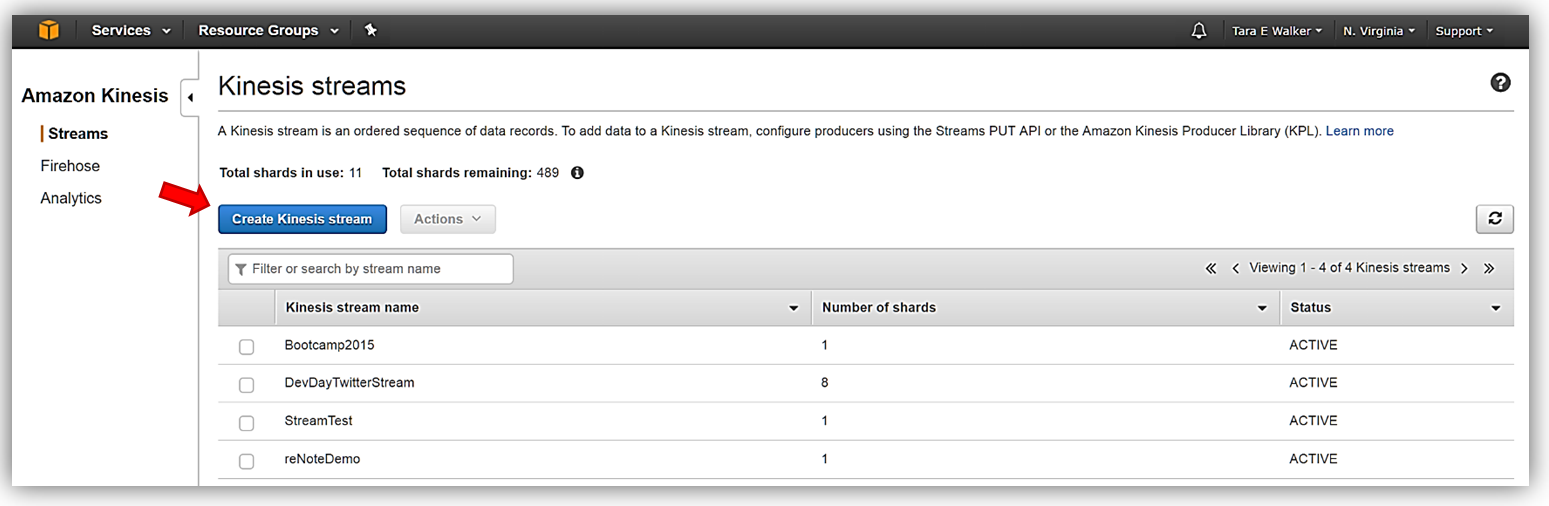
Kinesis Streams でサーバー側の暗号化の演習をしてみましょう。まず [Amazon Kinesis console] にアクセスし [Streams console] オプションを選択します。

Kinesis Streams コンソールにアクセスしたら、既存の Kinesis ストリームの 1 つにサーバー側の暗号を追加または新しい Kinesis ストリームを作成することができます。このチュートリアルでは、Kinesis ストリームを作成したいので [Create Kinesis stream] ボタンを選択します。
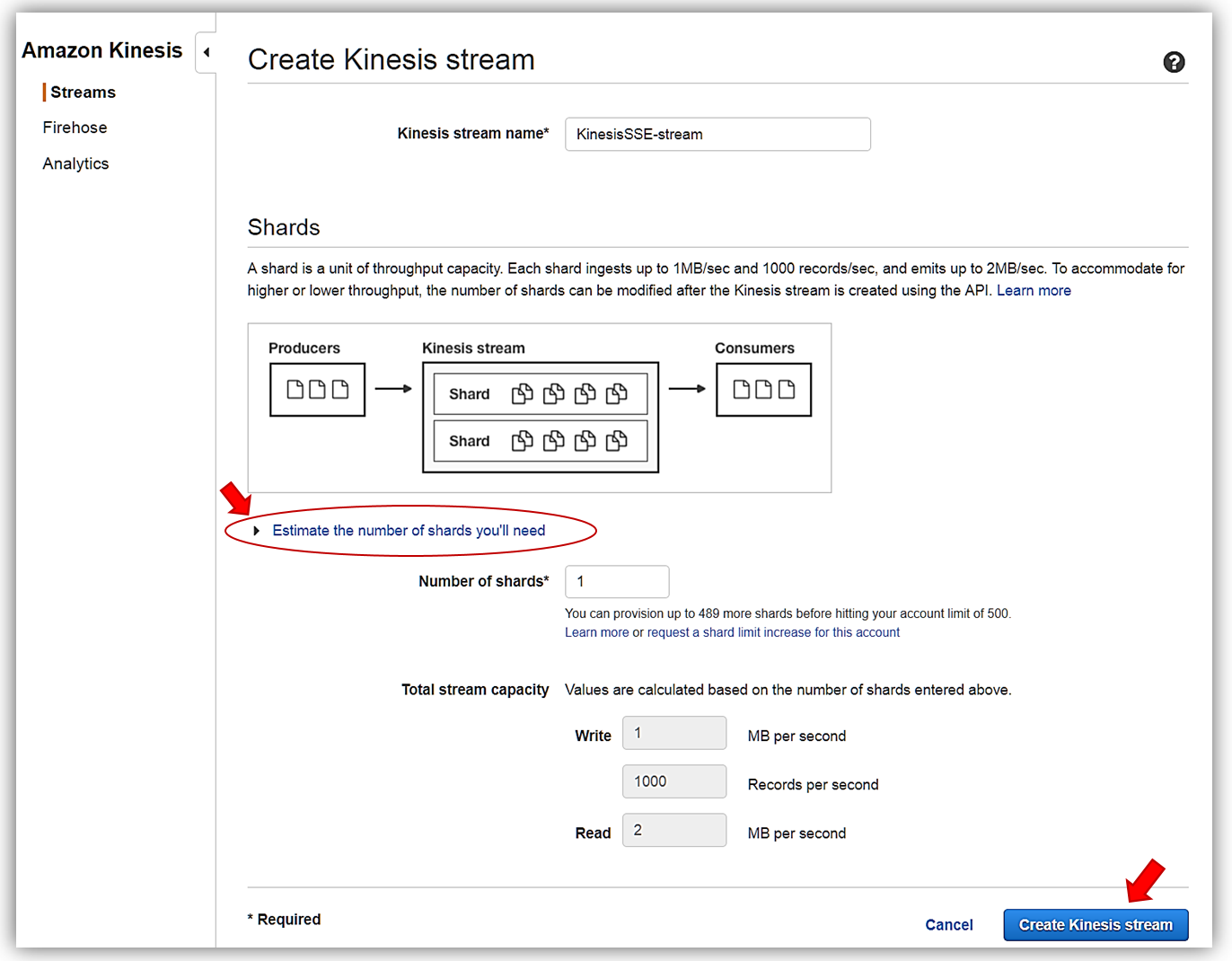
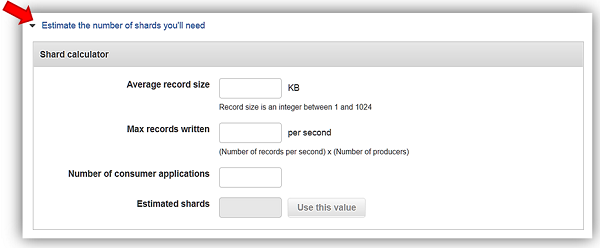
ストリーム名を「KinesisSSE-stream」にし、ストリームにシャードを 1 つ割り当てます。ストリームのデータ容量は、そのストリームで特定されたシャード数をもとに計算されることを忘れないでください。コンソールで [Estimate the number of shards you’ll need ] ドロップダウンを使用するか、こちらでストリームのシャード数を予測する計算に関する詳細をご覧ください。[Create Kinesis stream] ボタンをクリックして、ストリームの作成を完了します。
KinesisSSE-stream を作成したら、ダッシュボードを選択し [Actions] ドロップダウンで [Details] オプションを選択します。
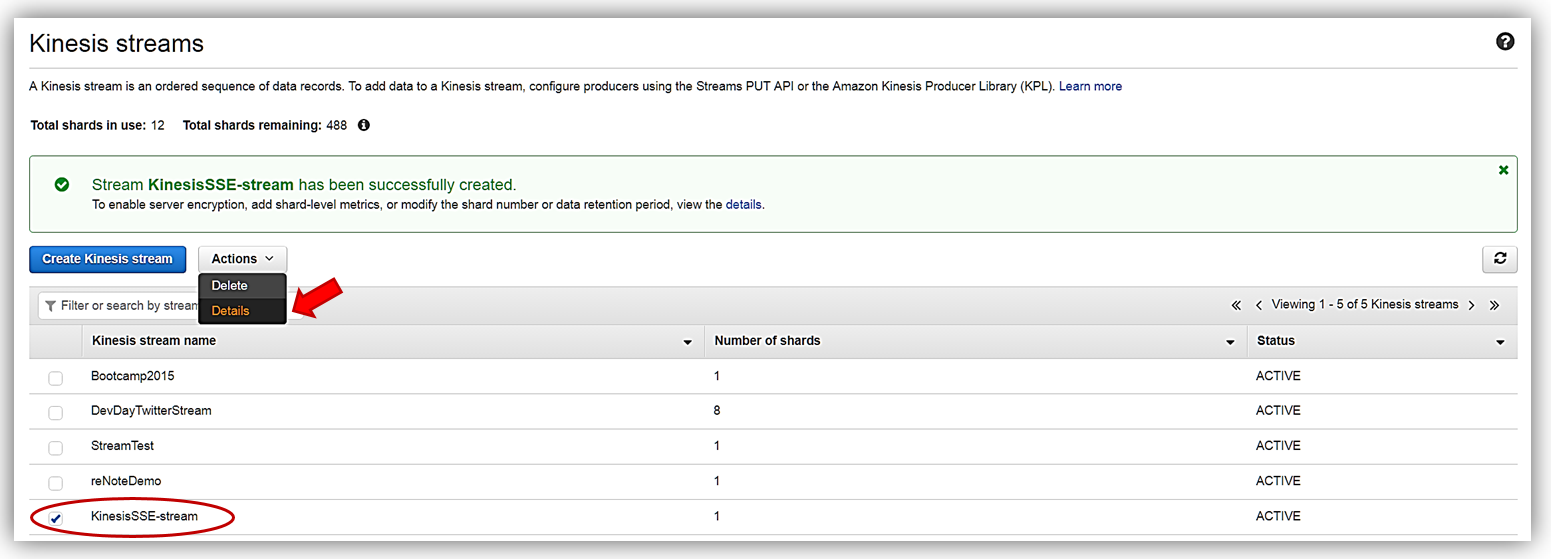
KinesisSSE-stream の [Details] ページに [Server-side encryption] セクションが表示されるようになります。このセクションで [Edit] ボタンを選択します。
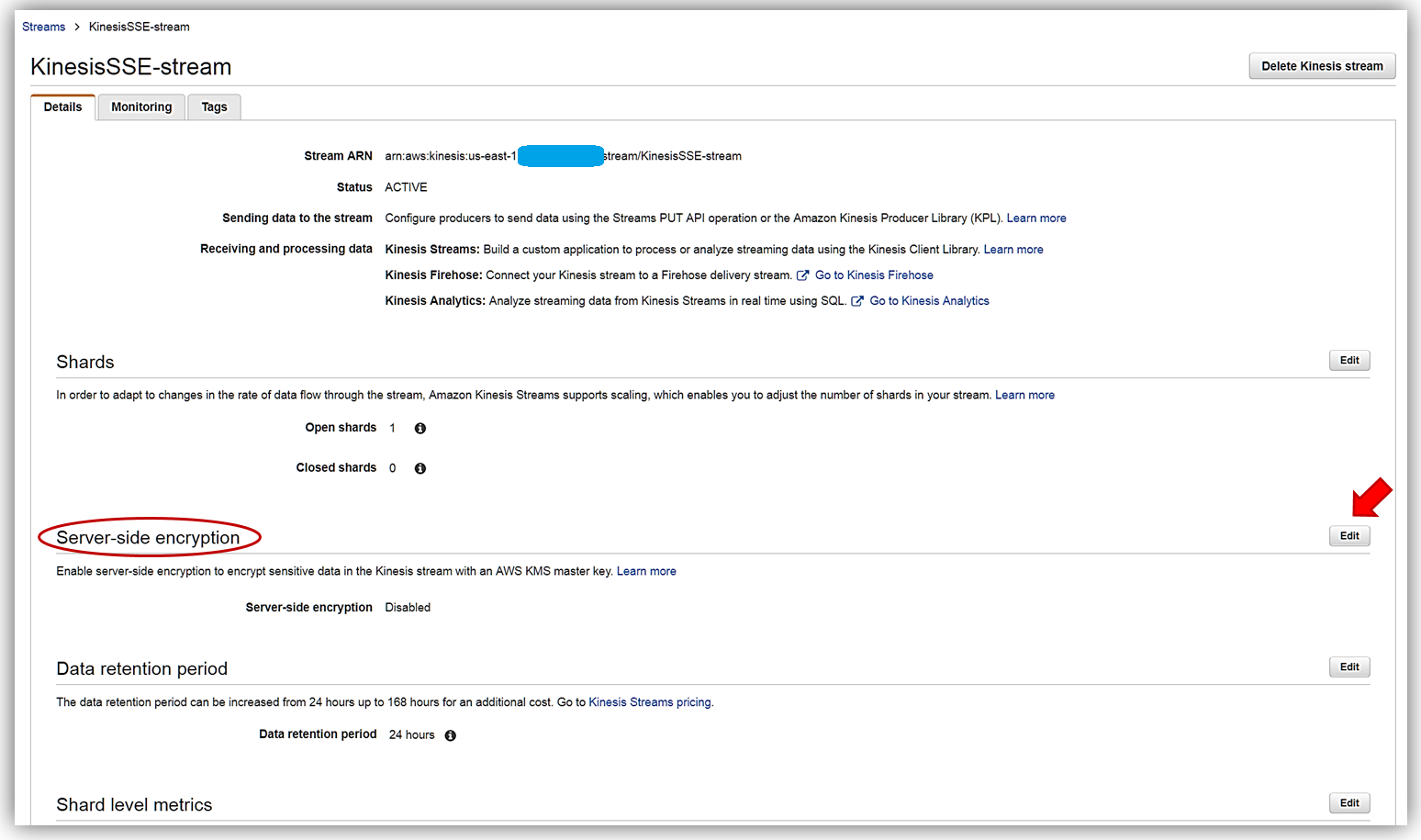
これで、[Enabled] ラジオボタンを選択し AWS KMS のマスターキーでストリームにサーバー側の暗号化を有効にすることができます。このボタンを選択すると、どの AWS KMS マスターキーを KinesisSSE-stream のデータの暗号化に使用するか選択できます。Kinesis サービスが生成した KMS のマスターキーまたは (Default) aws/kinesis、もしくはすでに作成してある KMS マスターキーの 1 つを選択することができます。この例では、デフォルトのマスターキーを選びます。後は [Save] ボタンをクリックするだけです。
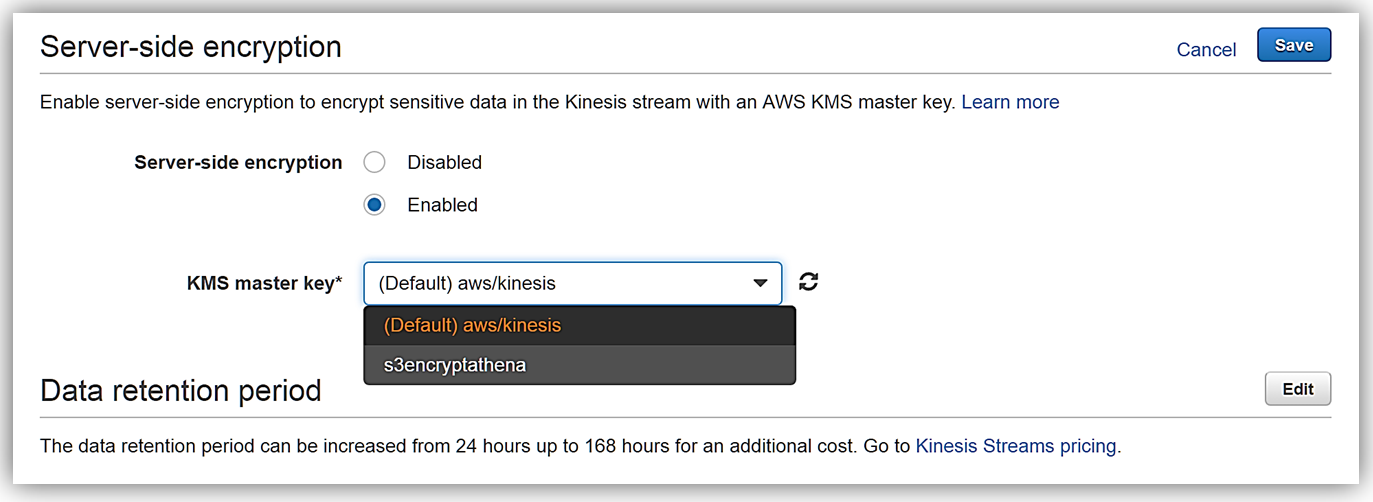
これで完了です。 次のスクリーンショットで表示されているように、約 20 秒後にはサーバー側の暗号化が Kinesis ストリームに追加され、ストリームに送信された受信データはすべて暗号化されるようになります。サーバー側の暗号化では、暗号化が有効になって初めて受信データが暗号化される点にご注意ください。サーバー側の暗号化が有効になる前の Kinesis ストリームにある既存のデータは暗号化されません。

まとめ
AWS KMS キーを使用してサーバー側の暗号化を有効にしている Kinesis Streams では、ストリームに送られてくるストリーミングデータの暗号化の自動化を行いやすくします。AWS マネジメントコンソールまたは AWS SDK を使用して、Kinesis ストリームのサーバー側の暗号化の開始、停止、更新ができます。Kinesis のサーバー側の暗号化に関する詳細や AWS Key Management Service または Kinesis Streams のレビューに関する詳細については「Amazon Kinesis の入門ガイド (Amazon Kinesis getting started guide)」、「AWS Key Management Service の開発者ガイド (AWS Key Management Service developer guide)」または「Amazon Kinesis の製品ページ (Amazon Kinesis product page)」をご覧ください。
ストリーミングをぜひご活用ください。
– Tara
Amazon Kinesis Data Generatorを使用してストリーミングデータソリューションをテストする
ストリーミングデータソリューションを構築する場合、ほとんどのお客様は、本番データと同様のデータを使用してストリーミングデータソリューションをテストしたいと考えています。この、データを作成してソリューションにストリーミングすることは、ソリューションをテストする際の最も退屈な作業かもしれません。
Amazon Kinesis StreamsとAmazon Kinesis Firehoseを使用すると、数十万のソースから1時間にテラバイト級のデータを連続的に捉えて保存できます。 Amazon Kinesis Analyticsでは、標準SQLを使用してリアルタイムでこのデータを分析および集計することができます。 AWS Management Console(またはAWS CLIまたはAmazon Kinesis APIを使用したいくつかのコマンド)で数回クリックするだけで、Amazon KinesisストリームまたはFirehose配信ストリームを簡単に作成できます。ただし、テストデータの連続したストリームを生成するには、AWS SDKまたはCLIを使用してAmazon Kinesisにテストレコードを送信することで、連続して実行されるカスタムプロセスまたはスクリプトを作成する必要があります。この作業はソリューションを適切にテストするために必要ですが、複雑さと開発時間とテスト時間が長くなることを意味します。
テストデータを生成してAmazon Kinesisに送信するユーザーフレンドリーなツールがあれば素晴らしいとは思いませんか?そこで、Amazon Kinesis Data Generator(KDG)の出番です。
Kinesis Firehoseを使用してApache WebログをAmazon Elasticsearch Serviceに送信する
Elasticsearch、Logstash、および、Kibana(ELK)スタックを所有して運用する多くのお客様が、他の種類のログの中でもApache Webログを読み込んで可視化しています。 Amazon Elasticsearch Serviceは、AWSクラウドにElasticsearchとKibanaを提供しており、セットアップと運用が簡単です。 Amazon Kinesis Firehoseは、Amazon Elasticsearch ServiceにApache Webログ(またはその他のログデータ)をサーバーレスで確実に配信します。
Firehoseを使用すると、Firehose内のレコードを変換するAWS Lambda関数への自動呼び出しを追加できます。これらの2つのテクノロジーを使用すると、既存のELKスタックを効果的かつ簡単に管理することができます。
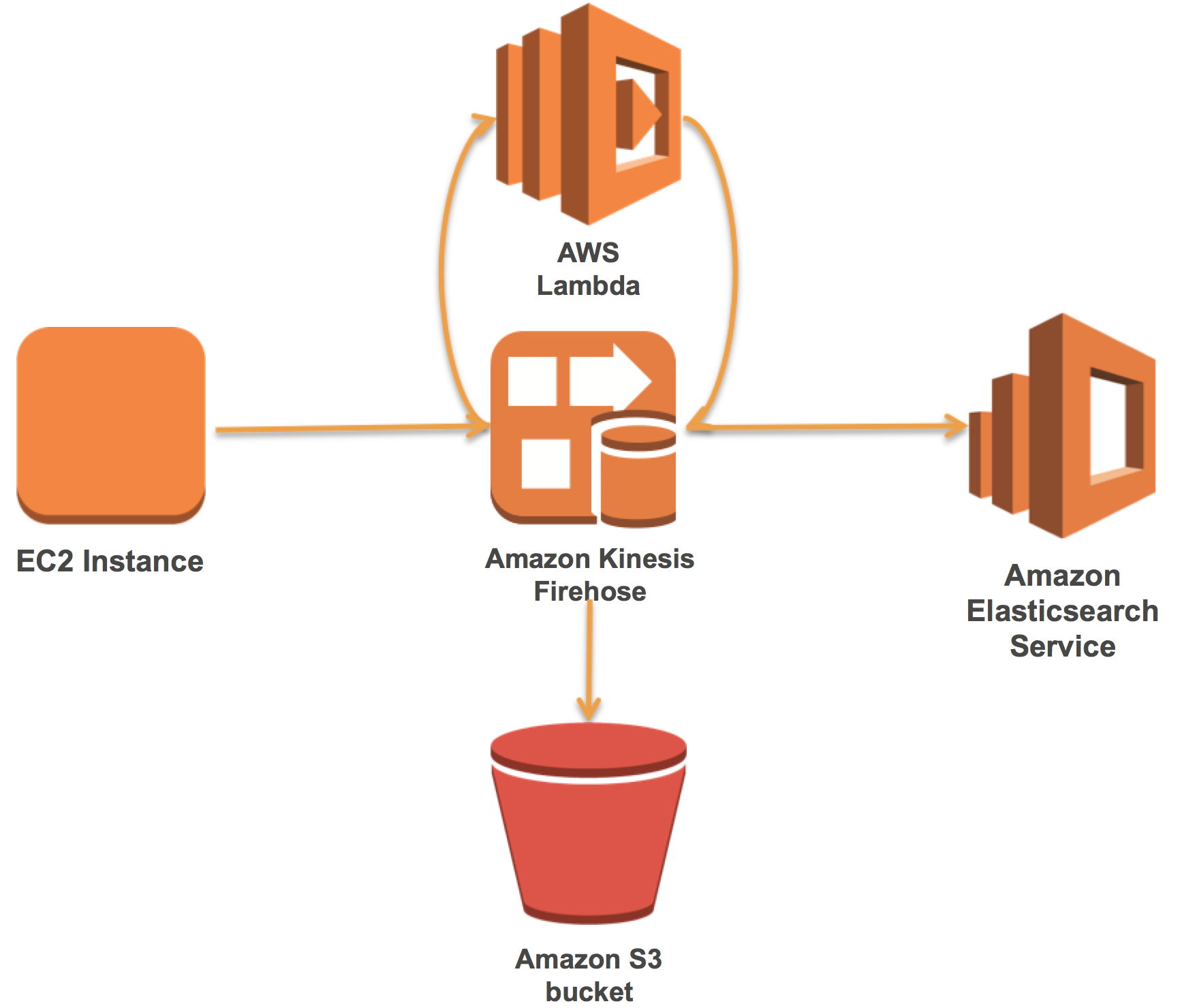
この記事では、最初にAmazon Elasticsearch Serviceドメインを設定する方法を説明します。次に、事前ビルドされたLambda関数を使用してApache Webログを解析するFirehoseストリームを作成して接続する方法を示します。最後に、Amazon Kinesis Agentでデータをロードし、Kibanaで可視化する方法を示します。
AWS上でApache Flinkを使用してリアルタイムストリーム処理パイプラインを構築する
今日のビジネス環境では、多様なデータソースが着実に増加していく中で、データが継続的に生成されています。したがって、このデータを継続的にキャプチャ、格納、および処理して、大量の生データストリームを実用的な洞察に素早く繋げることは、組織にとって大きな競争上のメリットになっています。
Apache Flinkは、このようなストリーム処理パイプラインの基礎を形成するのに適したオープンソースプロジェクトです。ストリーミングデータの継続的な分析に合わせたユニークな機能を提供しています。しかし、Flinkを基にしたパイプラインの構築と維持には、物理的なリソースと運用上の努力に加え、かなりの専門知識が必要になることがよくあります。
この記事では、Amazon EMR、Amazon Kinesis、Amazon Elasticsearch Serviceを使用してApache Flinkを基にした、一貫性のあるスケーラブルで信頼性の高いストリーム処理パイプラインの参照アーキテクチャの概要を説明します。 AWSLabs GitHubリポジトリは、実際に参照アーキテクチャを深く理解するために必要なアーティファクトを提供します。リソースには、サンプルデータをAmazon Kinesisストリームに取り込むプロデューサアプリケーションと、リアルタイムでデータを分析し、その結果をAmazon ESに可視化するためのFlinkプログラムが含まれています。
AWS KMSを使用してAmazon Kinesisレコードを暗号化および復号する
コンプライアンスやデータセキュリティの要件が厳しいお客様は、AWSクラウド内での保存中や転送中など、常にデータを暗号化する必要があります。この記事では、保存中や転送中もレコードを暗号化しながら、Kinesisを使用してリアルタイムのストリーミングアプリケーションを構築する方法を示します。
Amazon Kinesisの概要
Amazon Kinesisプラットフォームを使用すると、要求に特化したストリーミングデータを分析または処理するカスタムアプリケーションを構築できます。 Amazon Kinesisは、ウェブサイトクリックストリーム、金融取引、ソーシャルメディアフィード、ITログ、トランザクショントラッキングイベントなど、何十万ものソースから1時間につき数テラバイトのデータを連続的にキャプチャして保存できます。
Amazon Kinesis Streamsは、HTTPSを使用してクライアント間でデータを暗号化し、転送されているレコードの盗聴を防止します。ただし、HTTPSで暗号化されたレコードは、データがサービスに入ると解読されます。このデータは24時間保管され(最大168時間まで延長可能)、アプリケーションの処理、再処理、処理遅延の際の巻き取りに対して十分なゆとりが確保されています。
ウォークスルー
Amazon Kinesis Producer Library(KPL)、Kinesis Consumer Library(KCL)、AWS KMS、aws-encryption-sdkを使用してサンプルKinesisプロデューサおよびコンシューマアプリケーションへの暗号化と復号を行います。この記事で使用されているKinesisレコードの暗号化と復号に使用される方法とテクニックは、あなたのアーキテクチャに簡単に再現できます。いくつか制約があります:
- AWSは、暗号化と復号のためのKMS APIリクエストの使用料金を請求します。詳しくは、「AWS KMSの料金」を参照してください。
- Amazon Kinesis Analyticsを使用して、このサンプルアプリケーションのクライアントによって暗号化されたレコードのAmazon Kinesis Streamにクエリすることはできません。
- アプリケーションでレイテンシの低い処理が必要な場合は、レイテンシに多少の上乗せがあることに注意してください。
次の図は、ソリューションのアーキテクチャを示しています。
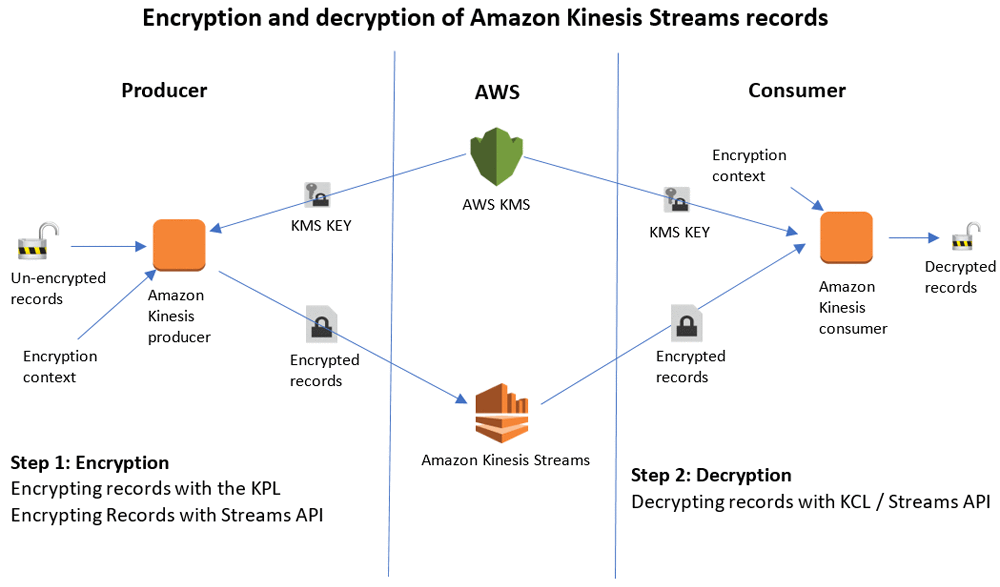
(more…)
Amazon Kinesis Analytics - SQL を使用してリアルタイムにストリーミングデータを処理
ご存知の通り、Amazon Kinesis では、AWS Cloud でリアルタイムにストリーミングデータを操作するプロセスが大幅に簡素化されています。独自のプロセスおよび短期のストレージインフラストラクチャを設定および実行する代わりに、ただ Kinesis ストリームまたは Kinesis Firehose を作成し、そこにデータを流し込むように設定してから、それを処理または分析するアプリケーションを構築するのみです。Kinesis ストリームと Kinesis Firehose を使用してストリーミングデータソリューションを構築するのは比較的簡単なのですが、さらに簡素化したいと考えました。作業開発者、データサイエンティスト、または SQL 開発者であるかどうかにかかわらず、お客様がウェブアプリケーション、テレメトリ、およびセンサーレポートの大量のクリックストリームを、接続されたデバイス、サーバーログなどからすべてリアルタイムに標準クエリ言語を使用して処理できるようにしたいと考えました。
Amazon Kinesis Analytics
 本日より、Amazon Kinesis Analytics がご利用いただけるようになりました。ストリーミングデータに対して SQL クエリを継続的に実行し、データが届くと同時にフィルタリング、変換、および集約できるようになりました。インフラストラクチャで時間を無駄にするのではなく、データの処理とそこからのビジネス価値の抽出に注力できます。強力なエンドツーエンドのストリームプロセスパイプラインを 5 分で構築できます。SQL クエリより複雑なものを作成する必要はありません。
本日より、Amazon Kinesis Analytics がご利用いただけるようになりました。ストリーミングデータに対して SQL クエリを継続的に実行し、データが届くと同時にフィルタリング、変換、および集約できるようになりました。インフラストラクチャで時間を無駄にするのではなく、データの処理とそこからのビジネス価値の抽出に注力できます。強力なエンドツーエンドのストリームプロセスパイプラインを 5 分で構築できます。SQL クエリより複雑なものを作成する必要はありません。
データベーステーブルに対する一連の SQL クエリの実行を考慮する場合、クエリは通常、非常に素早く追加および削除されるのに対して、データはほぼ静的なままです。常に行が追加、変更および削除されますが、これは特定の時点で実行する単一のクエリを考慮する際、一般的には関係ありません。Kinesis Analytics のクエリをストリーミングデータに対して実行すると、このモデルと正反対のことが生じます。クエリは長時間実行され、新しいレコード、監視、またはログエントリが届くと同時に、データは毎秒何度も変化します。一度この仕組みを把握すると、クエリプロセスモデルが非常に理解しやすいことが分かります。レコードが届くと同時に処理する、持続的なクエリを構築するのです。所定のクエリで処理されるレコードのセットを制御するには、プロセス「ウィンドウ」を使用します。Kinesis Analytics では、3 つの異なるタイプのウィンドウがサポートされています。
タンブリングウィンドウは定期的なレポートに使用されます。タンブリングウィンドウを使用して、時間の経過と共にデータをまとめることができます。おそらく毎秒数千~数百万ものリクエストを受信するので、1 分ごとの受信数を知りたいと思うでしょう。現在のタンブリングウィンドウが閉じると、その後に次のウィンドウが開始します。ウィンドウがいっぱいになるたびに、新しい結果が生成されます。
スライディングウィンドウは、モニタリングとその他のタイプのトレンド検出に使用されます。例えば、スライディングウィンドウを使用してリアルタイムで動くエラー率の平均をコンピューティングできます。レコードがウィンドウに入り、レコードがその中にあるかぎり結果に反映され、ウィンドウは進行します。新しいレコードがウィンドウに入るたびに、新しい結果が生成されます。ウィンドウのサイズを調整して、結果の精度を制御できます。
カスタムウィンドウは、適切なグループが厳密に時間に基づいていない場合に使用されます。クリックストリームデータまたはサーバーログを処理している場合、カスタムウィンドウを使用してセッション化として知られるアクションを実行できます。つまり、各ユーザーが実行する最初と最後のアクション (受信データ内のセッション ID により識別される) によって、各クエリをバインドできます。各ユーザーが閲覧したページ数またはサイトで費やした時間をコンピューティングするクエリを作成できます。
これらすべてはいくらか複雑に聞こえるかもしれませんが、実装するのは非常に簡単です。Kinesis Analytics では、受信レコードのサンプルを分析し、最適なスキーマを提案します。それをそのまま使用することも、微調整して実際のデータモデルをさらに反映することもできます。スキーマが定義されると、組み込み SQL エディターを使用できます (ライブデータに対する構文チェックと簡単なテストを含む)。クエリの結果を Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、または Amazon Kinesis Stream を含む最大 4 つの送信先にルーティングするように、Kinesis Analytics を設定できます。初めての Amazon Kinesis Analytics アプリケーションを構築する場合、SQL ステートメントのペアを作成する必要があります (より複雑なアプリケーションには多くを使用する場合がありますが、必要なのは起動と実行の 2 つのみです)。
これは、中間 SQL 結果を保存するアプリケーション内のストリームを作成するためのステートメントです (ストリームは、選択および挿入でき、継続的にアップデートされる SQL テーブルのようなものです)。
1 つのアプリケーション内のストリームから SQL クエリを選択し、別のアプリケーション内のストリームに挿入します。
また、S3 を送信元とするデータを参照するよう、SQL ステートメントもレコードに追加できます。これはレコードを強化または変更し、追加のさらに詳細な情報を含める時に役立ちます。
動作中の Amazon Kinesis Analytics
動作中の Amazon Kinesis Analytics を数分見てみましょう。
Amazon Kinesis Analytics コンソールにログインし、Create new application をクリックします。名前とアプリケーションの説明を記入します。
データソース、クエリ、および送信先を管理できるようになりました。
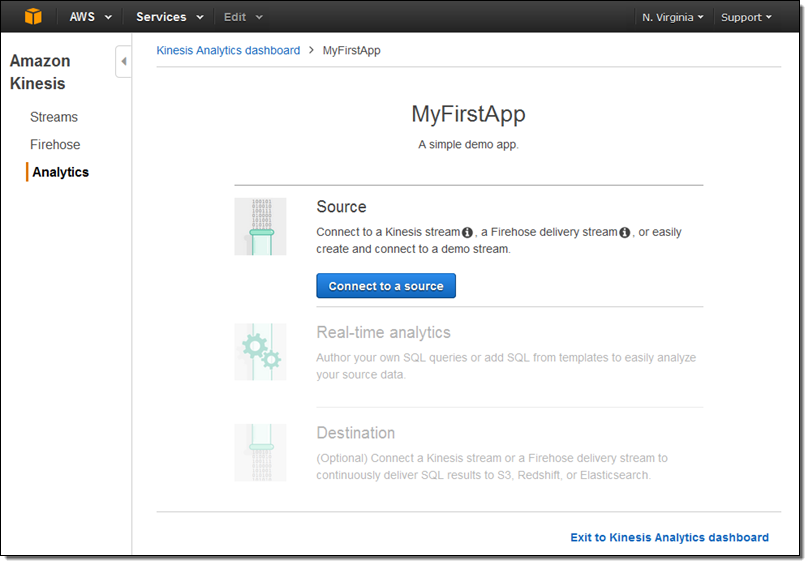
既存の入力ストリームの 1 つを選択できます。
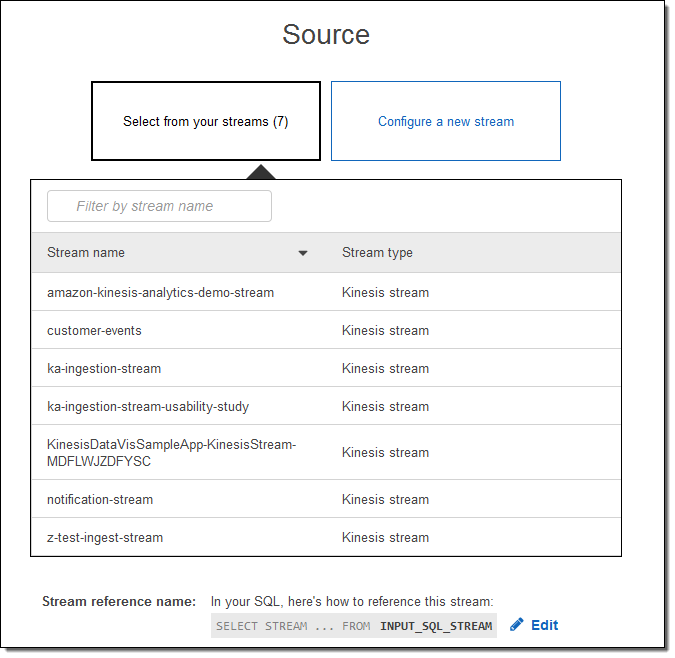
または、新しいストリームを設定できます (こちらを実行します)。
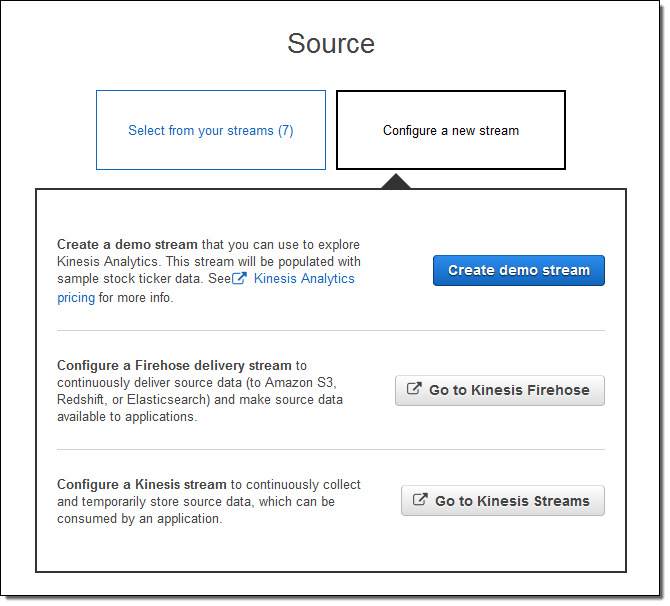
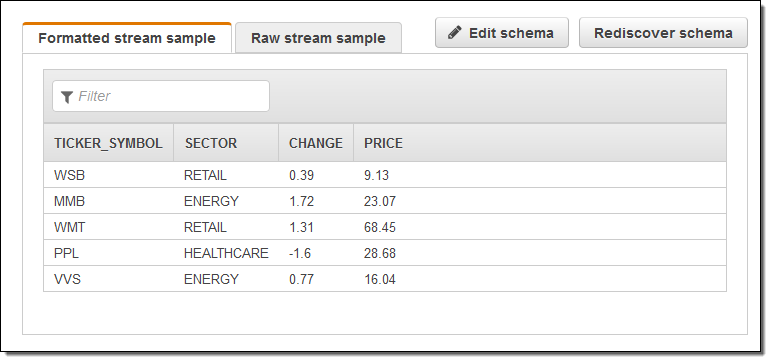
Create demo stream をクリックし、サンプルの株式相場表示機のデータが入力されるストリームを作成します。これには 30~40 秒かかります。Kinesis Analytics はストリームを参照し、スキーマを提案します。それをそのまま承認することも、微調整することもできます。
それから SQL エディターに移動します。アプリケーションの起動を提案しています。良いアイデアだと思うので、同意して Yes をクリックし、アプリケーションを起動します。
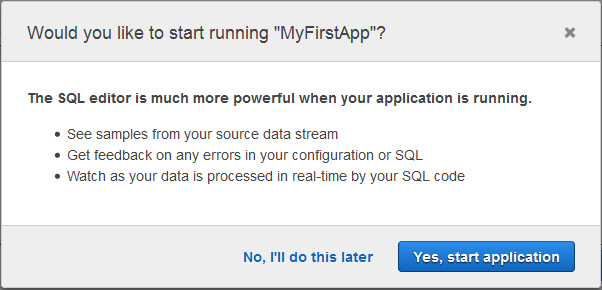
これが実際の SQL エディターです。
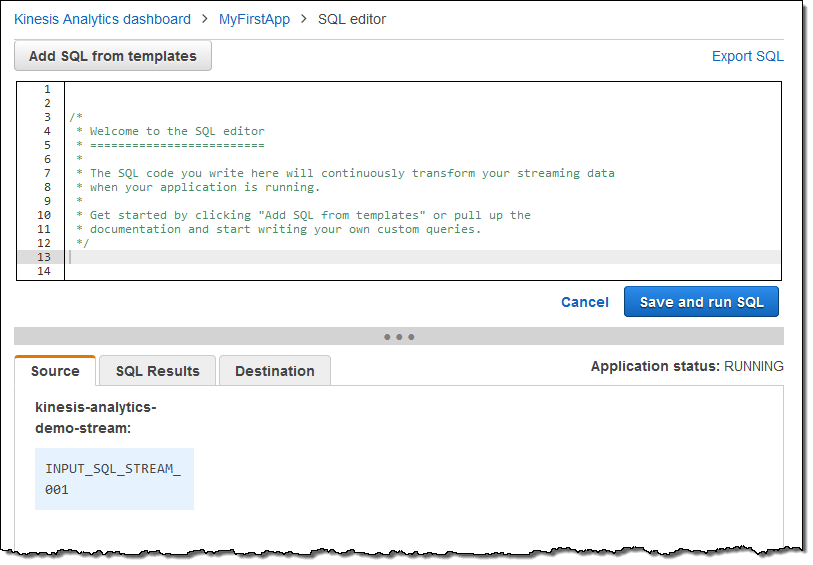
クエリをゼロから作成することも、テンプレートを使用することもできます。
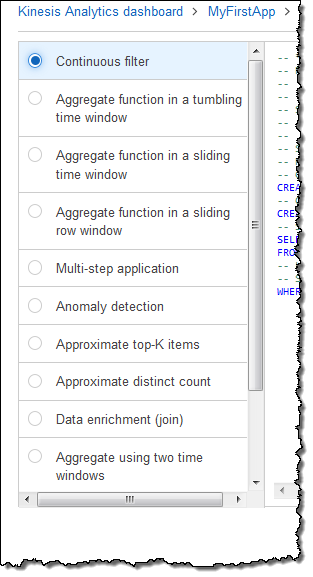
継続的なフィルターを選びました。これが SQL です。
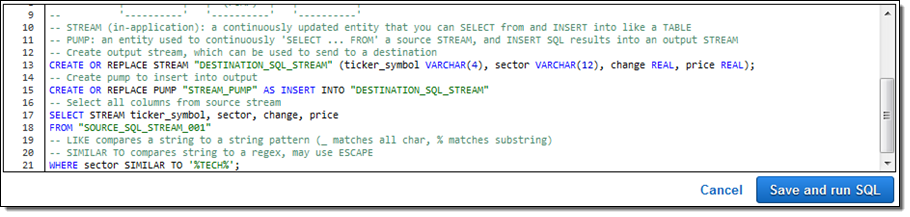
確認し、アグリーメントを承認し、Save and run SQL をクリックしました。数秒以内に結果が流れ始め、コンソールに表示されました。
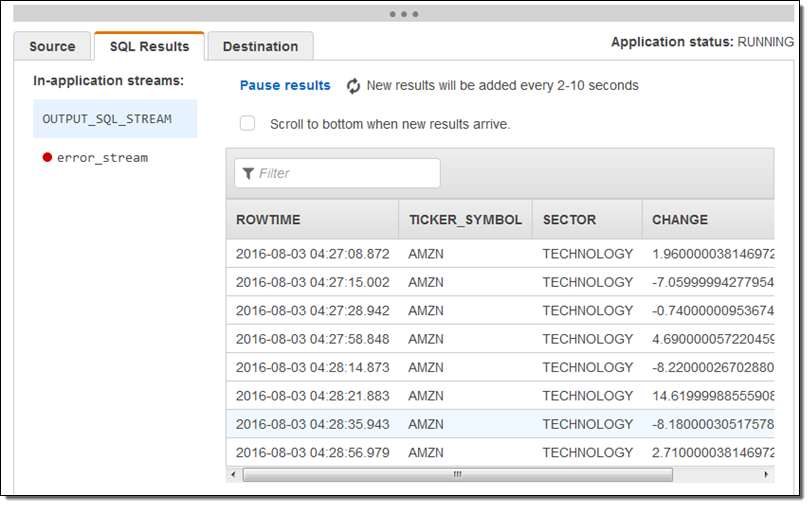
SQL エディターを使用して、部門と料金列を削除するようクエリを変更し、クエリを再度実行しました。この作業を行ってみて、CREATE STREAM ステートメントから列を削除する必要があることを学びました (振り返ってみると明白なのですが、これは長い 1 日の最後の作業でした)。こちらが修正した結果セットです。
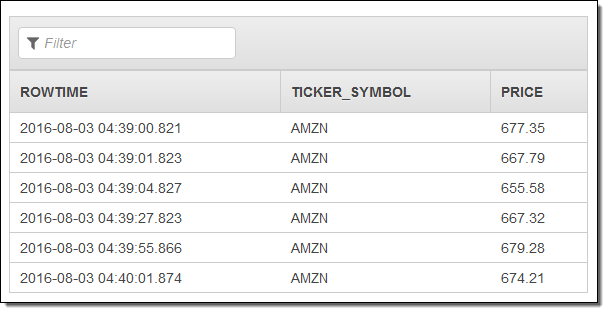
ほとんどの場合、次のステップでは結果を新規または既存のストリームにルーティングすることになるでしょう。これはコンソールから実行できます。
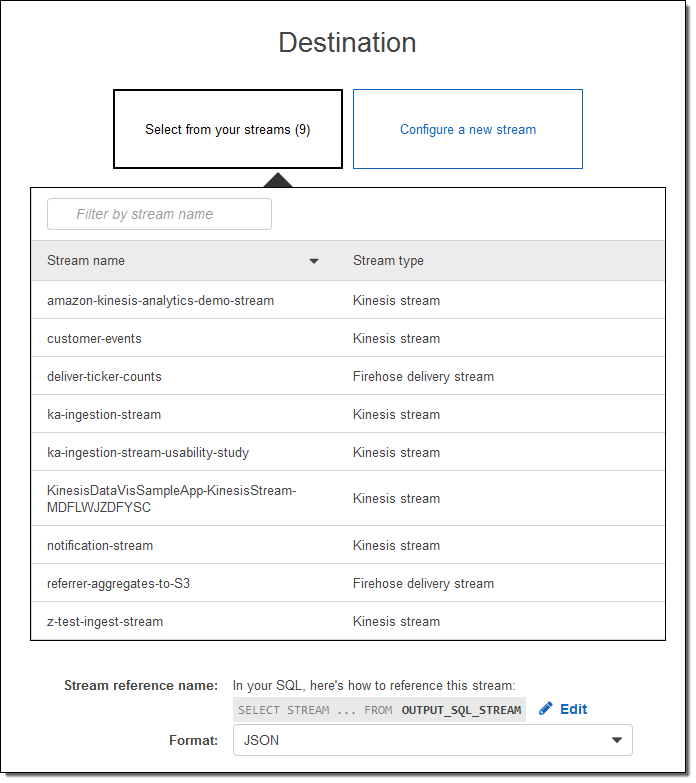
数回のクリックとほんの少しの入力のみで、本番環境規模の株式相場表示機のストリームを処理できる Amazon Kinesis Analytics アプリケーションを作成できました。本番環境で使用される前に、この「デモ」には何の変更も必要ありません。素晴らしいです。
詳細 & お試し
いつものように、このすばらしい新サービスについては、やっと分かり始めたばかりです。詳細については、新しい投稿をご覧ください。Writing SQL on Streaming Data with Amazon Kinesis Analytics上記のステップは 5 分またはそれ以下で再現できるはずです。ぜひお試しされるようにお勧めします。アプリケーションを作成し、SQL クエリをカスタマイズし、大規模なストリーミングデータの処理方法を学んでください。
今すぐご利用可能
今すぐ Amazon Kinesis Analytics をご利用いただけます。今日からストリーミングデータに対してクエリの実行を開始できます。
— Jeff
Amazon Kinesis アップデート – Amazon Elasticsearch Service との統合、シャード単位のメトリクス、時刻ベースのイテレーター
Amazon Kinesis はストリーミングデータをクラウド上で簡単に扱えるようにします。
Amazon Kinesis プラットフォームは3つのサービスから構成されています:Kinesis Streams によって、開発者は独自のストリーム処理アプリケーションを実装することができます;Kinesis Firehose によって、ストリーミングデータを保存・分析するための AWS へのロード処理がシンプルになります;Kinesis Analytics によって、ストリーミングデータを標準的な SQL で分析できます。
多くの AWS のお客様が、ストリーミングデータをリアルタイムに収集・処理するためのシステムの一部として Kinesis Streams と Kinesis Firehose を利用しています。お客様はこれらが完全なマネージドサービスであるがゆえの使い勝手の良さを高く評価しており、ストリーミングデータのためのインフラストラクチャーを独自に管理するかわりにアプリケーションを開発するための時間へと投資をしています。
本日、私たちは Amazon Kinesis Streams と Amazon Kinesis Firehose に関する3つの新機能を発表します。
- Elasticsearch との統合 – Amazon Kinesis Firehose は Amazon Elasticsearch Service へストリーミングデータを配信できるようになりました。
- 強化されたメトリクス – Amazon Kinesis はシャード単位のメトリクスを CloudWatch へ毎分送信できるようになりました。
- 柔軟性 – Amazon Kinesis から時間ベースのイテレーターを利用してレコードを受信できるようになりました。
Amazon Elasticsearch Service との統合
Elasticsearch はポピュラーなオープンソースの検索・分析エンジンです。Amazon Elasticsearch Service は AWS クラウド上で Elasticsearch を簡単にデプロイ・実行・スケールさせるためのマネージドサービスです。皆さんは、Kinesis Firehose のデータストリームを Amazon Elasticsearch Service のクラスターへ配信することができるようになりました。この新機能によって、サーバーのログやクリックストリーム、ソーシャルメディアのトラフィック等にインデックスを作成し、分析することが可能になります。
受信したレコード(Elasticsearch ドキュメント)は指定した設定に従って Kinesis Firehose 内でバッファリングされたのち、複数のドキュメントに同時にインデックスを作成するバルクリクエストを使用して自動的にクラスターへと追加されます。なお、データは Firehose へ送信する前に UTF-8 でエンコーディングされた単一の JSON オブジェクトにしておかなければなりません(どのようにこれを行うかを知りたい方は、私の最近のブログ投稿 Amazon Kinesis Agent Update – New Data Preprocessing Feature を参照して下さい)。
こちらが、AWS マネージメントコンソールを使用したセットアップの方法です。出力先(Amazon Elasticsearch Service)を選択し、配信ストリームの名を入力します。次に、Elasticsearch のドメイン(この例では livedata)を選択、インデックスを指定し、インデックスのローテーション(なし、毎時、日次、週次、月次)を選択します。また、全てのドキュメントもしくは失敗したドキュメントのバックアップを受け取る S3 バケットも指定します:
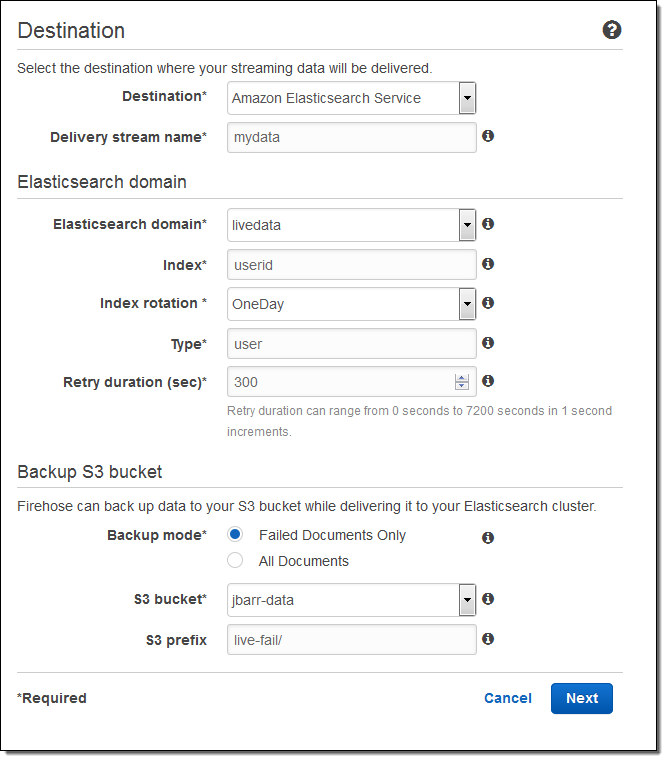
そして、バッファーのサイズを指定し、S3 バケットに送信されるデータの圧縮と暗号化のオプションを選択します。必要に応じてログ出力を有効にし、IAM ロールを選択します:
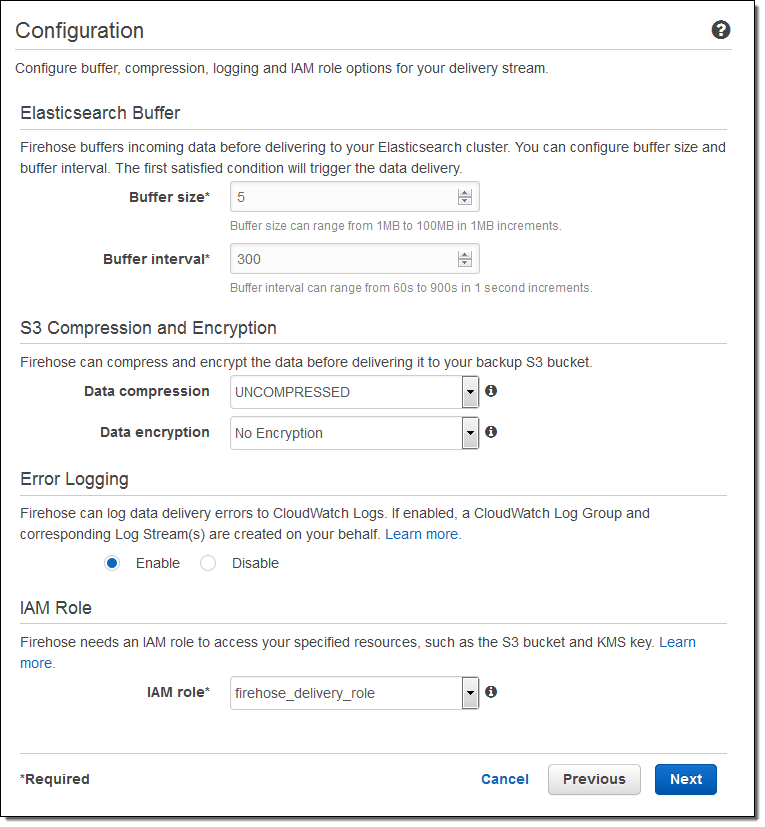
一分程度でストリームの準備が整います:
コンソールで配信のメトリクスを見ることもできます:
データが Elasticsearch へ到達した後は、Kibana や Elasticsearch のクエリー言語による視覚的な検索ができます。
総括すると、この統合によって、皆さんのストリーミングデータを収集し、Elasticsearch に配信するための処理は実にシンプルになります。もはや、コードを書いたり、独自のデータ収集ツールを作成したりする必要はありません。
シャード単位のメトリクス
全ての Kinesis ストリームは、一つ以上のシャードによって構成されており、全てのシャードは一定量の読み取り・書き込みのキャパシティを持っています。ストリームにシャードを追加することで、ストリームのキャパシティは増加します。
皆さんは、それぞれのシャードのパフォーマンスを把握する目的で、シャード単位のメトリクスを有効にすることができるようになりました。シャードあたり6つのメトリクスがあります。それぞれのメトリクスは一分間に一回レポートされ、通常のメトリクス単位の CloudWatch 料金で課金されます。この新機能によって、ある特定のシャードに負荷が偏っていないかを他のシャードと比較して確認したり、ストリーミングデータの配信パイプライン全体で非効率な部分を発見・一掃したりすることが可能になります。例えば、処理量に対して受信頻度が高すぎるシャードを特定したり、アプリケーションから予想よりも低いスループットでデータが読まれているシャードを特定したりできます。
こちらが、新しいメトリクスです:
IncomingBytes – シャードへの PUT が成功したバイト数。
IncomingRecords – シャードへの PUT が成功したレコード数。
IteratorAgeMilliseconds – シャードに対する GetRecords 呼び出しが戻した最後のレコードの滞留時間(ミリ秒)。値が0の場合、読み取られたレコードが完全にストリームに追いついていることを意味します。
OutgoingBytes – シャードから受信したバイト数。
OutgoingRecords – シャードから受信したレコード数。
ReadProvisionedThroughputExceeded – 秒間5回もしくは2MBの上限を超えてスロットリングされた GetRecords 呼び出しの数。
WriteProvisionedThroughputExceeded – 秒間1000レコードもしくは1MBの上限を超えてスロットリングされたレコードの数。
EnableEnhancedMetrics を呼び出すことでこれらのメトリクスを有効にすることができます。いつもどおり、任意の期間で集計を行うために CloudWatch の API を利用することもできます。
時刻ベースのイテレーター
任意のシャードに対して GetShardIterator を呼び出し、開始点を指定してイテレーターを作成することで、アプリケーションは Kinesis ストリームからデータを読み取ることができます。皆さんは、既存の開始点の選択肢(あるシーケンス番号、あるシーケンス番号の後、最も古いレコード、最も新しいレコード)に加え、タイムスタンプを指定できるようになりました。指定した値(UNIX 時間形式)は読み取って処理しようとする最も古いレコードのタイムスタンプを表します。
— Jeff;
翻訳は SA 内海(@eiichirouchiumi)が担当しました。原文はこちらです。
Amazon Kinesis エージェントの更新情報 – 新しいデータ事前処理機能
Amazon Kinesis エージェント用の新しいデータ事前処理機能について同僚の Ray Zhu が説明したゲスト投稿を以下に掲載します。
–
Jeff
Amazon Kinesis エージェントは、Amazon Kinesis Streams や Amazon Kinesis Firehose にデータを信頼性の高い方法で簡単に送信できるようにする、スタンドアロンの Java ソフトウェアアプリケーションです。エージェントはファイルセットを監視して新しいデータを検出し、Kinesis Streams または Kinesis Firehose に連続的に送信します。ファイルのローテーション、チェックポイント処理、および失敗時の再試行も処理します。また、Amazon CloudWatch もサポートするので、エージェントからのデータフローの入念な監視やトラブルシューティングも行えます。
Kinesis エージェントを使用したデータ事前処理
今回、データ事前処理機能がエージェントに追加され、ユーザーはデータを Kinesis Streams または Kinesis Firehose に送信する前に、適切に書式設定できます。 この投稿の記述時点で、エージェントは次の 3 つの処理オプションをサポートしています。エージェントはオープンソースなので、ユーザーはこれらの処理オプションを開発したり、拡張したりできます。
SINGLELINE – このオプションは、改行文字と、行頭および行末のスペースを削除して、複数行のレコードを単一行のレコードに変換します。
CSVTOJSON – このオプションは、区切り文字で区切られた書式から JSON 書式にレコードを変換します。
LOGTOJSON – このオプションは、一般的に使用されている複数のログ書式を JSON 書式に変換します。現在サポートされているログ書式は、Apache Common Log、Apache Combined Log、Apache Error Log、および RFC3164 (syslog) です。
ほぼリアルタイムで Apache Tomcat のアクセスログを分析
ここでは、Kinesis エージェントの事前処理機能、Amazon Kinesis Firehose、および Amazon Redshift を使用して、Tomcat のアクセスログをほぼリアルタイムで分析する例を示します。 次に、全体的な手順を説明します。
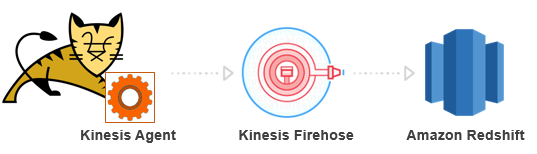
まず、Tomcat アクセスログの保存用に Redshift クラスターでテーブルを作成します。次の SQL 文を使用して、テーブルを作成します。
CREATE TABLE logs(
host VARCHAR(40),
ident VARCHAR(25),
authuser VARCHAR(25),
datetime VARCHAR(60),
request VARCHAR(2048),
response SMALLINT NOT NULL,
bytes INTEGER,
referer VARCHAR(2048),
agent VARCHAR(256));次に、前の手順で作成した Redshift テーブルにデータを連続的に配信する Kinesis Firehose 配信ストリームを作成する必要があります。
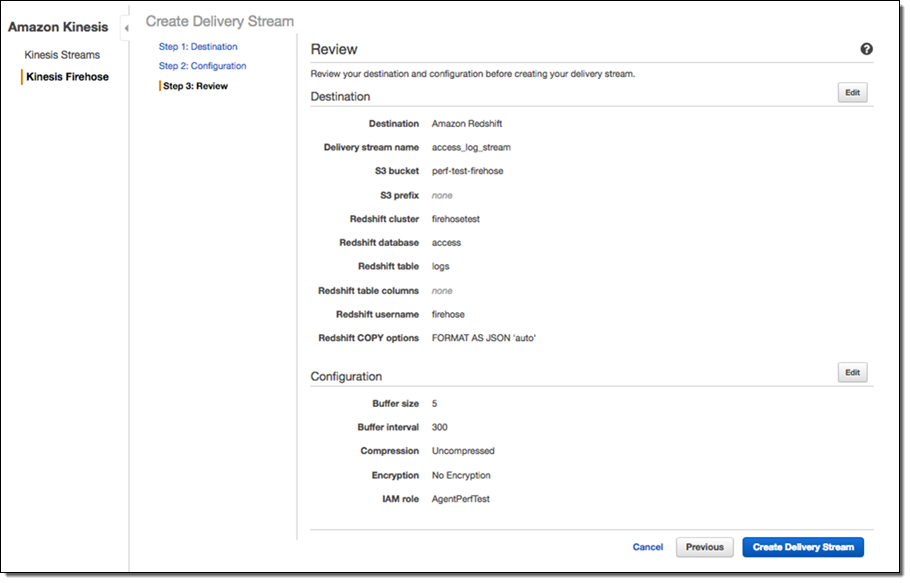
これで、Redshift テーブルと Firehose 配信ストリームをセットアップできました。次に、Kinesis エージェントを Tomcat サーバーにインストールして、Tomcat アクセスログの監視、およびログデータの配信ストリームへの連続的な送信を行う必要があります。次の図は、生の Tomcat アクセスログのスクリーンショットを示しています。
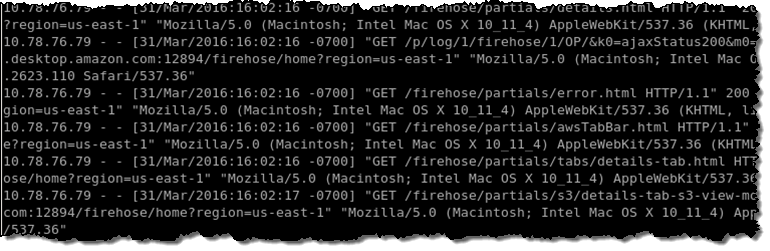
エージェント構成で、LOGTOJSON 処理オプションを使用して、生の Tomcat アクセスログデータを JSON 書式に変換してから、データを配信ストリームに送信します。セットアップの内容は、次のとおりです。
{
"cloudwatch.emitMetrics":true,
"flows":[
{
"filePattern":"/data/access.log*",
"deliveryStream":"access_log_stream",
"initialPosition":"START_OF_FILE",
"dataProcessingOptions":[
{
"optionName":"LOGTOJSON",
"logFormat":"COMBINEDAPACHELOG"
}
]
}
]
}これですべての準備が整ったので、エージェントを起動します。数分後に、Tomcat アクセスログデータが、S3 バケットと Redshift テーブルに現れます。S3 バケットでは、データは次のように表示されます。生ログデータは、正しく JSON 書式になっています。
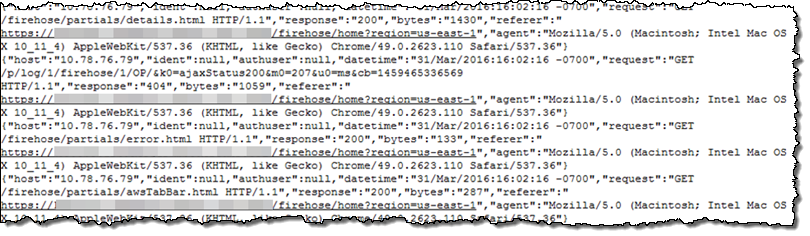
データは Redshift テーブルで次のように表示されます。
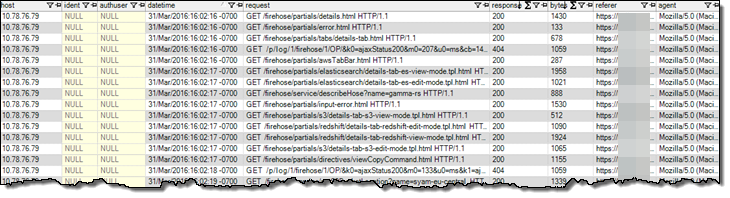
SQL クエリを実行した Tomcat アクセスログの分析や、好みのビジネスインテリジェンスツールを使用したデータ視覚化が可能です。
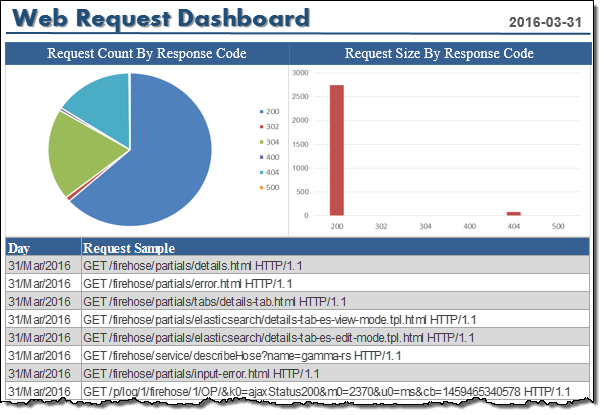
データパイプライン全体をセットアップするのに、1 時間もかかりませんでした。これで、データが Tomcat サーバーで生成された数分後に、お気に入りのビジネスインテリジェンスツールを使用して、アクセスログデータを分析したり視覚化したりできます。
今すぐ利用しましょう
Kinesis エージェントのデータ事前処理機能は、今すぐに利用し始めることができます。Amazon Kinesis エージェントリポジトリにアクセスしてください。詳細については、「Kinesis Firehose Developer Guide」の「Use Agent to Preprocess Data」をご覧ください。
– Ray Zhu、シニア製品マネージャー