Category: Amazon Aurora
Amazon Auroraアップデート – ストアードプロシジャーからLambda Functionの呼び出しと S3からのデータ読み込みに対応 –
多くの AWS serviceはそれ自体だけでもよく動作しますが、組み合わせることで更に良くなります!この大事な我々のモデルは、各サービスを選択し学習を行ない、経験を積み時間とともに他のサービスへ拡張していく事が可能です。一方で、サービスを組み合わせて使う機会は常に存在し、お客様の要望に基づきロードマップへいくつも反映しています。
本日、MySQL互換のリレーショナルデータベースである、Amazon Auroraの2つの新機能をご紹介します。
- Lambda Function Invocation – Amazon Auroraデータベース 内のストアードプロシジャーからAWS Lambdaのfunctionを呼び出すことが可能になりました
- Load Data From S3 – Amazon Simple Storage Service (S3)のバケットに保存されたデータをAmazon Auroraデータベースにロード可能になりました
これら2つの新機能はAmazon Auroraと他のAWSサービスを連携するためにAmazon Auroraに適切な権限を付与する必要があります。IAM Policyや IAM Roleを作成し、作成したRoleをAmazon Auroraデータベースクラスタへ付与します。詳細な手順はドキュメントをご覧ください。
Lambda Function Integration
ハイレベルな機能を実現するために、リレーショナルデータベースではトリガーやストアードプロシジャーを組み合わせて利用します。トリガーは特定のテーブルへの操作の前後で実行することが出来ます。例えば、Amazon AuroraはMySQLと互換性があるため、INSERT, UPDATE, DELETE操作へのトリガーをサポートしています。ストアードプロシジャーは実行されたトリガーへのレスポンスの中で実行可能なスクリプトです。
Lambda functionを呼び出すストアードプロシジャーを利用可能になりました。この拡張された機能を使うことで、Auroraデータベースと他のAWSサービスを結びつけることが出来るようになりました。Amazon Simple Email Service (SES)を利用してemailを送信したり、 Amazon Simple Notification Service (SNS)を利用し問題の通知を行ったり、Amazon CloudWatchにメトリクスを送信したり、 Amazon DynamoDBのテーブルを更新するようなことが可能です。
その他にも、複雑なETLジョブやワークフロー、データベース内のテーブルに対する監査、パフォーマンスモニタリングや分析なども用途として考えられます。
ストアードプロシジャーからはmysql_lambda_asyncプロシジャーを呼び出す必要があります。このプロシジャーは非同期で与えられたLambda functionを実行するため、Lambda functionの完了を待たずに処理を終了します。Lambda functionには利用するAWSサービスやリソースに対する権限を付与しておく必要があります。
詳細は、 Invoking a Lambda Function from an Amazon Aurora DB Clusterをご覧ください。
Load Data From S3
他の形のインテグレーションとして、S3バケットに保存されたデータを直接Auroraにインポート可能になりました (今までは一度Ec2インスタンス上にダウンロードしたあとにインポートする必要がありました)。
Amazon Auroraクラスタからアクセス可能であれば、AWSのどのリージョンにデータが配置されていてもロード可能です。形式はテキストかXML形式に対応しています。
テキスト形式のデータをインポートするためには、新しい LOAD DATA FROM S3コマンドを利用します。このコマンドはMySQLのLOAD DATA INFILEとほぼ同様のオプションをサポートしています。しかし、圧縮形式のデータは現在サポートしていません。特定の行やフィールドデリミタやキャラクタセットを設定可能で、指定した行や列数を無視して取り込むことも可能です。
XML形式のデータをインポートするためには、新しいLOAD XML from S3コマンドを利用します。XMLは以下の様な形式になります。
<row column1="value1" column2="value2" /> ... <row column1="value1" column2="value2" />
や
<row> <column1>value1</column1> <column2>value2</column2> </row> ...
また
<row> <field name="column1">value1</field> <field name="column2">value2</field> </row> ...
の形式に対応しています。
詳細は、Loading Data Into a DB Cluster From Text Files in an Amazon S3 Bucketをご覧ください。
すぐにご利用いただけます
これらの新機能は本日からご利用頂けます!
それぞれの機能には追加で料金はかかりませんが、通常のAmazon Aurora, Lambda, S3のご利用料金が発生します。
Amazon Auroraにリーダーエンドポイントが追加されました – 負荷分散と高可用性向上 –
機能向上を行うたびにAmazon Auroraはパワフルかつ簡単にご利用頂けるようになってきました。ここ数ヶ月で、MySQLバックアップからAuroraクラスタを作成する機能や、クロスリージョンレプリケーション、アカウント間でのスナップショットの共有、フェイルオーバー順を指定可能になったり、他のクラウドやオンプレミス環境のデータベースからAuroraへ移行などを追加してきました。
本日、Auroraのリードレプリカの機能を向上する、クラスタレベルのリードエンドポイントを追加しました。皆様のアプリケーションは今まで通り特定のレプリカに対して直接クエリを実行することが可能です。しかし、今回追加したリードエンドポイントを利用するように変更することで、負荷分散や高可用性といった2つの大きな利点を得ることが出来ます。
Load Balancing – クラスタエンドポイントに接続することでDBクラスタ内のリードレプリカ間でコネクションのロードバランシングが可能になります。これは、リードワークロードを分散することで利用可能なレプリカ間でリソースを効率的に活用することができ、よりよりパフォーマンスを得ることが可能になります。フェイルオーバーの際には、もしアプリケーションが接続しているレプリカがプライマリインスタンスに昇格した場合コネクションは一旦クローズされます。その後、再接続を行うことでクラスタ内の他のレプリカにリードクエリを実行することが可能です。
Higher Availability – 複数のAuroraレプリカをAvailability Zone毎に配置し、リードエンドポイント経由で接続することが出来ます。Availability Zoneの可用性の問題が万が一発生した場合、リードエンドポイントを利用することで最小限のダウンタイムでリードトラフィックを他のレプリカに実行可能です。
Find the Endpoint
リーダーエンドポイントはAurora Consoleで確認可能です:
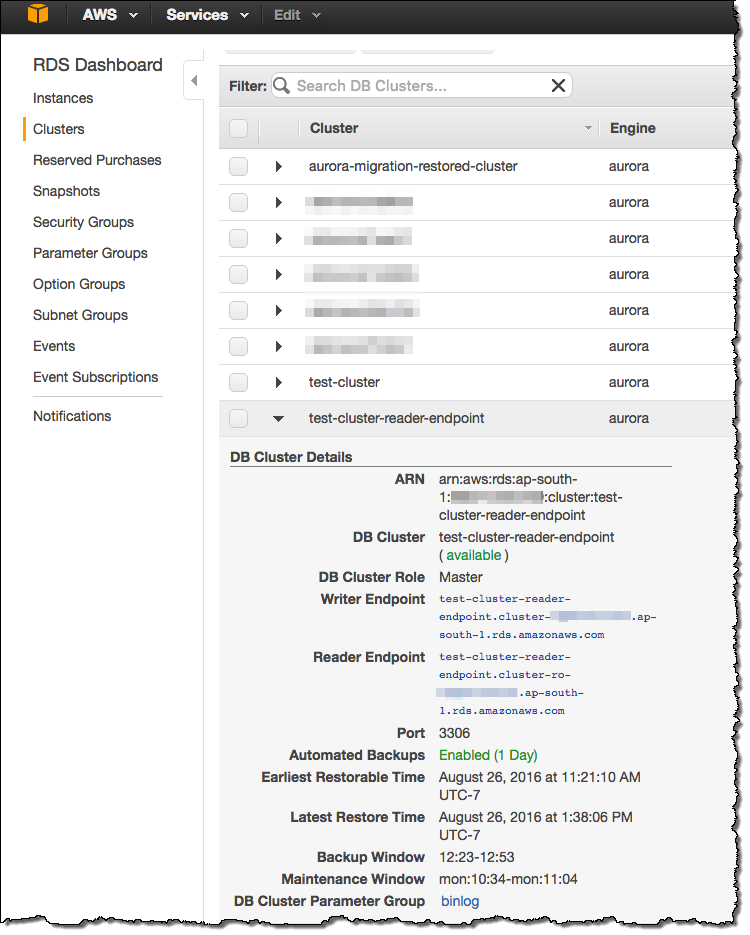
この便利な機能は本日からご利用可能です!
Amazon Auroraアップデート – Parallel Read Ahead, Faster Indexing, NUMA Awareness
Amazon Aurora はAWSサービスの中で最も速く成長するサービスになりました!
リレーショナルデータベースをクラウドに適したデザインにすることで(Amazon Aurora – Amazon RDSに費用対効果の高いMySQL互換のデータベースが登場!! の記事もご覧ください)、Aurora は大きなパフォーマンス改善や、64TBまでシームレスにスケールアップするストレージ、堅牢性・可用性の向上を実現しています。AuroraをMySQL互換にデザインすることによって、お客様は既存のアプリケーションの移行や新しいアプリケーションの構築を簡単に行って頂けています。
MySQL互換を保ちながら、そしてクラウドネイティブなAuroraアーキテクチャを活用することでAuroraには多くのイノベーションを加えられると考えています。
本日、3つのパフォーマンスを改善する新機能をAuroraに追加しました。それぞれの機能は、AWSをご利用の多くのお客様の一般的なワークロードでAuroraのパフォーマンスを改善するように設計されました。
Parallel Read Ahead – レンジ select、 フルテーブルスキャン、テーブル定義の変更やindex作成が最大5倍高速に
Faster Index Build – indexの作成時間が約75%短縮
NUMA-Aware Scheduling – 2つ以上のCPUが搭載されているデータベースインスタンスをご利用の場合、クエリキャッシュからの読み込みやバッファキャッシュからの読み込みが速くなり、全体的なスループットが最大10%向上
詳細をご紹介します
Parallel Read Ahead
MySQLで利用されているInnoDBストレージエンジンは行やindex keyを利用するストレージ(ディスクページ)を管理します。これはテーブルのシーケンシャルスキャンの高速化や新しく作成されたテーブルに効果的です。しかし、行が更新・作成や削除されるにつれて、ストレージがフラグメントされることによって、ページは物理的にシーケンシャルではなくなってきます。そして、スキャン性能が大きく低下します。InnoDBのLinear Read Ahead機能はページが実際に利用されるまでメモリ内で64ページまでまとめることでフラグメントに対処しています。しかし、エンタープライズスケールのワークロードでは、この機能は有効な性能向上にはなりません。
今日のアップデートでは、Auroraは多くの状況で賢くこのような状況を扱う機能をご提供します。Auroraがテーブルをスキャンする際に、論理的に判断し、並列で追加のページをプリフェッチします。この並列プリフェッチはAuroraのレプリケーションが行われているストレージ(3つアベイラビリティゾーンにそれぞれ2つずつのコピー)で優位性を発揮し、データベースキャッシュ中のページがスキャンオペレーションに関連しているかを判断するのに役立ちます。
結果として、レンジselect、フルテーブルスキャン、ALTER TABLE そして、index作成を以前のバージョンと比較して最大5倍高速に行えるようになりました。
Aurora 1.7(詳細はこの後の情報をご覧ください)にアップグレードすることで、すぐにこのパフォーマンス改善をご体験頂けます。
Faster Index Build
プライマリー、セカンダリーインデックスをテーブルに作成する時、ストレージエンジンは新しいキーを含んだ木構造を作成します。この処理は、多くのトップダウンのツリーサーチや、より多くのキーの増加に対応するためにツリーの再構築によりページ分割が伴います。
Auroraはボトムアップ戦略でツリーを構築します。リーフを最初に作成し、必要な親ページを追加していきます。この機能によりストレージ内の移動を軽減し、加えて各ページが一旦全て埋まるためページを分割する必要がなくなります。
この変更により、テーブルのスキーマによりますがindexの追加やテーブルの再構築が最大4倍高速になります。例として、Auroraチームが以下の様なスキーマでテーブルを作成し100億行を追加し5GBののテーブルを作製しました:
create table test01 (id int not null auto_increment primary key, i int, j int, k int);
そして4つのindexを追加しました
alter table test01 add index (i), add index (j), add index (k), add index comp_idx(i, j, k);
db.r3.largeインスタンスで、このクエリの実行時間が67分から25分になりました。db.r3.8xlargeでは、29分から11.5分に短縮されました。
これは新機能でプロダクション環境以外でのテストをお勧めします。利用するには、Aurora 1.7へアップグレードを行ない DB Instance Parameter group(詳細は DB Cluster and DB Instance Parametersをご覧ください)でaurora_lab_modeを1に設定します。
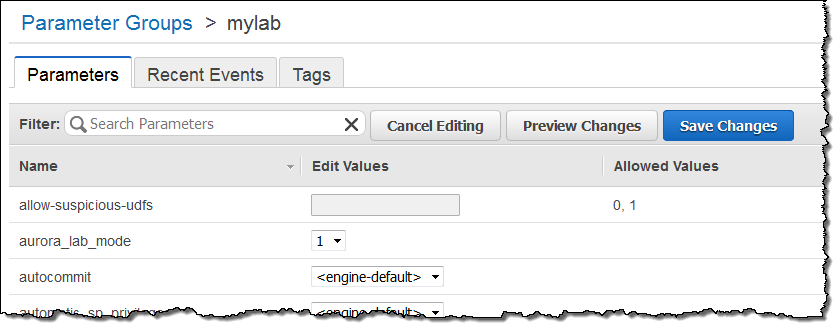
Auroraチームはこのパフォーマンス改善に対するみなさまからのフィードバックを楽しみにしています。お気軽にAmazon RDS Forumへ投稿をお願いします。
NUMA-Aware Scheduling
最も大きいデータベースインスタンス(db.r3.8xlarge) は2つのCPUを搭載しNUMA(Non-Uniform Memory Access)と呼ばれる機能を持っています。このタイプのシステムでは、メインメモリの各区画は各CPUに直接効率的にアクセス出来ます。残りのメモリは少し非効率なCPU間のアクセス経路を介してアクセスします。
Auroraはこの不均等なアクセス時間を活用するためにスケジューリングスレッドのjobを効率的に扱うことが可能になりました。スレッドは他のCPUに接続されている非効率なメモリへのアクセスを気にする必要がありません。結果として、クエリキャッシュやバッファキャッシュを大量に利用する様なCPUバウンドな操作で最大10%性能が向上しました。パフォーマンス向上は同じデータベースインスタンスに数百または数千接続を行っているときに顕著に発揮します。例として、Sysbench oltp.lua ベンチマークで570,000 reads/secondから625,000 reads/secondに向上しました。このテストではdb.r3.8xlarge DBインスタンスで以下のパラメータを利用して行いました。
- oltp_table_count=25
- oltp_table_size=10000
- num-threads=1500
Aurora 1.7にアップグレードすることで、すぐにこのパフォーマンス改善をご体験頂けます。
Upgrading to Aurora 1.7
新しく作成されたDBインスタンスはAurora 1.7で自動的に起動します。既に起動しているDBインスタンスでは、update immediately か during your next maintenance windowを選択することでインストールが可能です。
以下のクエリでAurora 1.7で起動しているか確認出来ます。
mysql> show global variables like “aurora_version”;
+—————-+——-+
| Variable_name | Value |
+—————-+——-+
| aurora_version | 1.7 |
+—————-+——-+
Amazon AuroraでMySQLバックアップからクラスタを作成可能になりました
AWSをご利用になり、クラウドへ移行するメリットを感じられているお客様から、アプリケーションやリレーショナルデータベースに保存されている、大量のデータを移行するより良い方法を良く質問されます。
本日、Amazon Auroraにて重要な新機能をリリースしました。既にオンプレミス環境やAmazon EC2インスタンス上でMySQLをお使いの場合、既存のデータベースのバックアップを取得し、スナップショットバックアップをAmazon S3にアップロード行い、そのスナップショットバックアップを利用して、Amazon Auroraクラスタを作成可能になりました。既存のAmazon AuroraのMySQLデータベースからレプリケーションを行える機能と合わせて利用することで、MySQLからAmazon Auroraへアプリケーションを停止させず簡単にマイグレーション可能です。
この新機能を利用することで大容量のデータ(2TB以上)をMySQLデータベースからAmazon Auroraへ移行元データベースへパフォーマンスインパクトを最小限にして効率的に移行を行うことが可能です。私達の行ったテストではmysqldump utilityを利用した場合と比較して20倍高速に処理が行えました。移行対象データベースにInnoDBとMyISAM形式のテーブルが双方が含まれていても移行は可能ですが、移行前にMyISAMからInnoDBへ変換を行っておくことをお勧めします。
移行方法について簡単にご説明します:
- 移行元データベースの準備 – 移行元データベースでバイナリログを有効化し。移行期間中バイナリログが残っているように設定を行って下さい。
- 移行元データベースのバックアップ – Percona Xtrabackupを利用して移行元データベースから”ホット”バックアップを作成します。このツールはデータベース、テーブルやトランザクションをロックしません。圧縮形式のバックアップを作成可能です。1つのバックアップファイルや複数の小さなバックアップファイルを作成頂けます。Amazon Auroraではどちらの形式でもご利用頂けます。
- S3へアップロード – S3へバックアップファイルをアップロードします。5TB未満のバックアップの場合は、AWS Management ConsoleやAWS Command Line Interface (CLI) を利用してアップロードを行います。さらに大きなバックアップデータの場合は、AWS Import/Export Snowballを利用することをご検討下さい。
- IAM Role – Amazon Relational Database Service (RDS) がアップロードされたバックアップデータとバケットにアクセスするためにIAM roleを作成します。このIAM roleでは必ず、RDSがListBucket と GetBucketLocation の操作をバケットに実行でき、GetObject の操作をバックアップデータに行える必要があります (サンプルポリシーはドキュメントで確認頂けます)。
- クラスタの作成 – 新しいAmazon Auroraクラスタをアップロードしたバックアップデータから作成します。RDSコンソール中のRestore Aurora DB Cluster from S3をクリックし、移行元データベースのバージョン番号を入力します。そして、S3バケットを選択し、IAM roleを選択後、Next Stepをクリックします。その後、クラスタ作成ページ(DB Details と Configure Advanced Settings)の残りの項目を入力します。
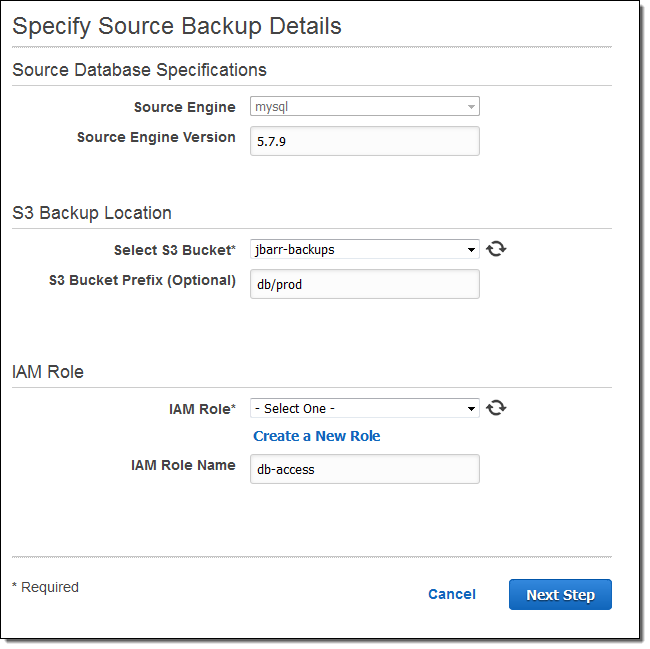
Amazon Auroraはバックアップファイルをアルファベット順に処理します。
- MySQLスキーマの移行 – ユーザ、権限やMySQL INFORMATION_SCHEMAで行っていた設定を移行します。
- 関連するアイテムの移行 – trigger, functionやstored procedureを移行元データベースからAmazon Auroraクラスタに移行します。
- レプリケーションの設定 – 移行元データベースとAmazon Aurora間でレプリケーションを設定し、レプリケーションを追いつかせます。
- データベースの変更 – 全てのクライアントアプリケーションの接続先をAmazon Auroraクラスタに変更します。
- レプリケーションの停止 – Amazon Auroraクラスタへのレプリケーションを停止します。
本番環境でミッションクリティカルなデータベースの移行前には、移行の検証をお勧めします。
本日からご利用いただけます
この新機能は本日からAsia Pacific (Mumbai)リージョンを除く全てのリージョンでご利用いただけます。さらに詳細な情報はAmazon Aurora User Guide中のMigrating Data from an External MySQL Database to an Amazon Aurora DB Clusterをご覧ください。
Amazon AuroraでCross-Region Read Replicaがご利用頂けるようになりました
Amazon Auroraクラスタににリードレプリカを追加することでリードキャパシティの増強を行って頂けます。本日、リードレプリカを他のリージョンに作成頂ける機能をリリースしました。この機能を利用することでリージョン間でディザスタリカバリ構成を利用出来、リードキャパシティを拡張出来ます。その他にも、他のリージョンにデータベースをマイグレーションしたり、新しい環境を構築する際にもご利用頂けます。
リードレプリカを他のリージョンに作成すると、Auroraクラスタがそのリージョンに作成されます。Auroraクラスタには15台までリージョン内であればレプリカラグのとても低いリードレプリカを作成出来ます(多くのケースで20ms以内)。リージョン間の場合、ソースクラスタとターゲットクラスタの間の距離に応じてレイテンシが増加します。この構成は、現在のAuroraクラスタを複製したり、ディザスタリカバリ目的でリードレプリカをリージョン間で構成することに利用頂けます。リージョン障害が万が一発生した場合、クロスリージョンレプリカをマスターとして昇格します。こうすることで、ダウンタイムを最小限にすることが可能です。こちらの機能は、暗号化されていないAuroraクラスタに適用可能です。
リードレプリカを作成する前に、ターゲットとなるリージョンにVPCやDatabase Subnet Groupsが存在しているか、マスターでバイナリログが有効になっているかを確認する必要があります。(訳者注: 設定を有効にする前に最新のパッチを適用して下さい)
VPCの設定
AuroraはVPC内で起動するため、ターゲットとなるリージョンに適切に設定されたDatabase Subnet Groupsが存在するか確認します:
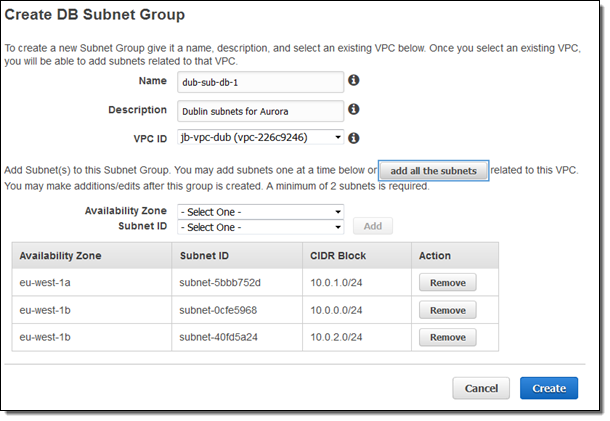
バイナリログを有効にする
クロスリージョンレプリケーションを設定する前にバイナリログを有効にする必要があります。もしdefaultパラメータグループをお使いの場合、新しいDB Cluster Parameter Groupを作成します:
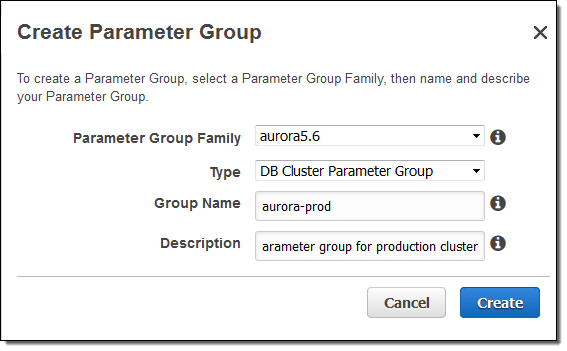
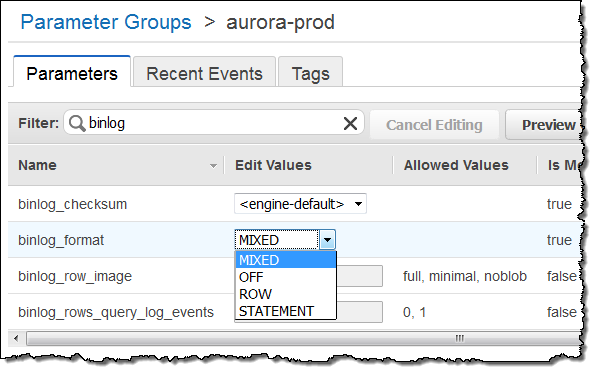
バイナリログを有効にし(binlog_formatをMIXEDに)、Save Changesをクリックします:
次に、設定を変更するDBインスタンスを選択しModifyを選択します。そして、新しいDB Cluster Parameter Groupを選択しApply Immediatelyを選択してContinueをクリックします。変更を確認し、設定を反映させるためにをクリックします: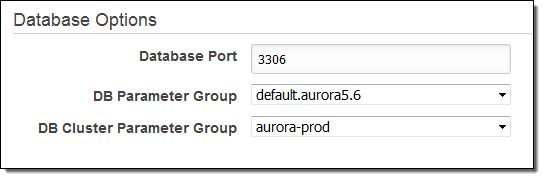
インスタンスを選択し、再起動を実行しreadyになるまで待ちます
リードレプリカの作成
事前準備が完了したら、リードレプリカを作成します!AWS Management Consoleから、ソースクラスタを選択し、 Instance ActionsメニューからCreate Cross Region Read Replicaを選択します:
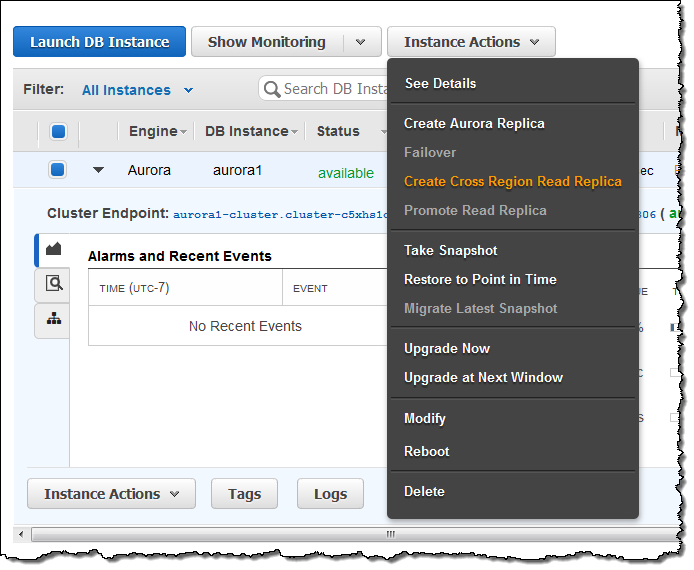
新しインスタンスやクラスタの名前を設定し、ターゲットリージョンを選択します。DB Subnet Groupを選択し、他のオプションも希望の設定にし最後にCreateをクリックします:
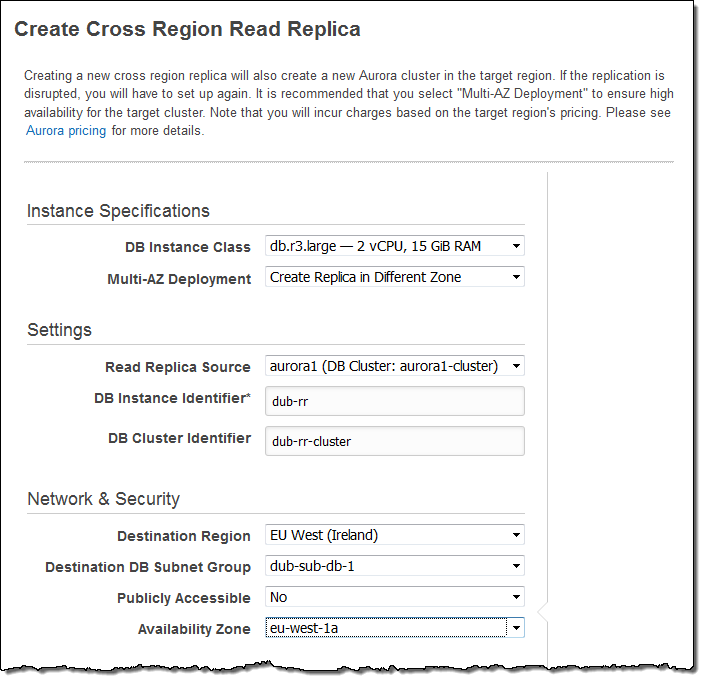
Auroraがクラスタやインスタンスを作成します。インスタンスが作成されデータがレプリケーションされるまでcreatingステータスになります(作成完了までの時間はソースクラスタに保存されているデータサイズに依存します)。
こちらの機能は本日からご利用頂けます!
— Jeff (翻訳は星野が担当しました。原文はこちら)
Amazon Auroraでアカウント間でスナップショットを共有頂けるようになりました
Amazon AuroraはMySQL互換で、ハイパフォーマンスなデータベースエンジンです。Auroraはハイエンドデータベース速度や可用性をオープンソースデータベースのコスト効率やシンプルさでご利用頂けます (更に詳細な情報はAmazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDSをご覧ください)。AuroraはAmazon RDSでご利用頂ける、簡単な管理・数クリックでスケール可能、スピード、セキュリティやコスト効率などの幾つかの重要な機能を持っています。
数クリックでAuroraクラスタのバックアップを行うためにスナップショットを作成出来ます。スナップショットを作成後、同じく数クリックでスナップショットからデータベースをリストア可能です。
スナップショット共有
本日、Auroraスナップショットを共有頂けるようになりました。スナップショットは他のAWSアカウントと共有するだけではなく、パブリックに共有も可能です。同一リージョンの他のAWSアカウントで起動しているAuroraスナップショットからデータベースをリストア可能です。
スナップショット共有の主なユースケースをいくつかご紹介します:
環境の分離 – 多くのAWSのお客様が開発、テスト、ステージング、プロダクション環境に個別のAWSアカウントをご利用しています。必要に応じでこれらのアカウント間でスナップショットを共有頂けます。例えば、初期データベースをステージング環境で構築し、スナップショットを作成します、そしてそのスナップショットを本番環境のアカウントに共有し、そのスナップショットから本番データベースを作成します。他にも、本番環境のコードやクエリで何か問題が発生した場合、プロダクション環境のデータベースのスナップショットを作成しテスト環境にデバッグ目的で共有することも可能です。
Partnering – 必要に応じてスナップショットを特定のパートナーに共有出来ます
データの共同利用 – もしリサーチプロジェクトを行っているなら、スナップショットを作成しパブリックに共有することが可能です。興味をもった人がそのスナップショットから自分のAuroraデータベースを作成し、皆さんのデータをスタートポイントとして利用出来ます。
スナップショットを共有するために、RDSコンソールからShare Snapshotをクリックします。そして、共有先のAWSアカウントを入力します。(もしくは、パブリック共有のためにPublicを選択します)そして、Addを選択します:
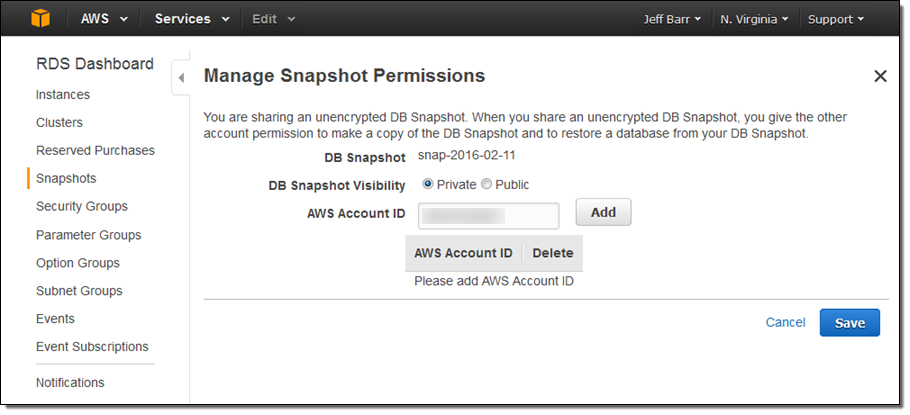
共有出来るスナップショットは、手動作成されたもの、暗号化されていないものを他のAWSアカウントと、パブリックなものを共有可能です。自動取得されたスナップショットと暗号化されたスナップショットは共有出来ません。
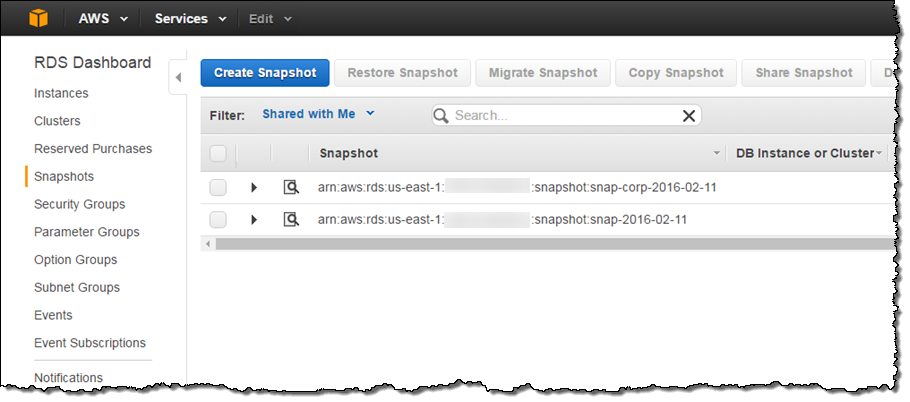
共有されたスナップショットは直ぐに他のアカウントで閲覧出来るようになります:
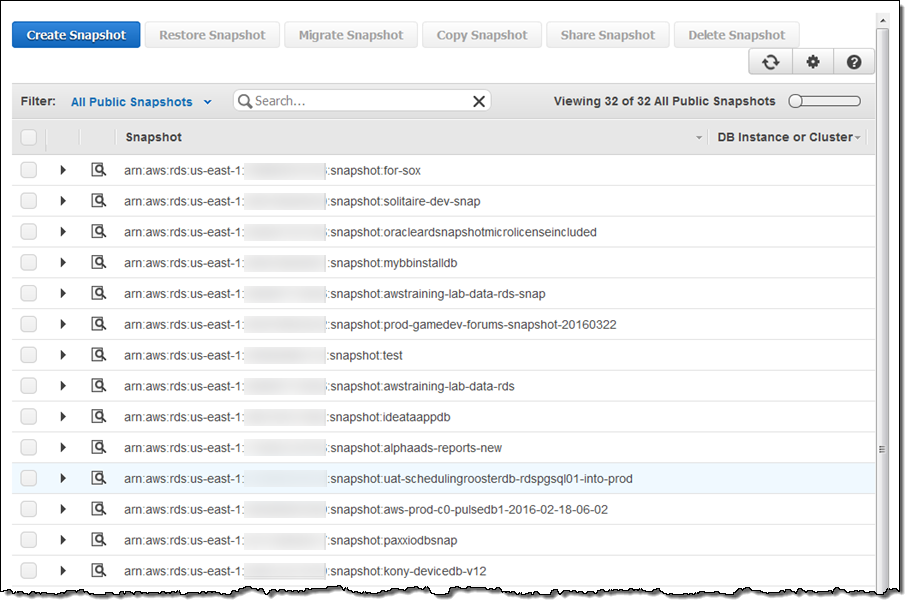
パブリックスナップショットも参照出来ます(FilterでAll Public Snapshotsを選択します):
本日からご利用頂けます
この機能は本日から直ぐにご利用頂けます。
— Jeff (翻訳は星野が担当しました。原文はこちら)