Category: Amazon Aurora
Sign up Today – Amazon Aurora with PostgreSQL Compatibility のプレビュー
昨年、Amazon Aurora に PostgreSQL 互換のエンジンをリリースするとアナウンスしました。その際、プライベートプレビューのサインアップを紹介し、申し込んでいただくようご案内しました。
そのリクエストの反応は非常に大きいものでした!お客様は既に Amazon Aurora が高い可用性、堅牢性を提供することを理解し、ご自身の PostgreSQL 9.6 アプリケーションを AWS クラウドで動かすのを楽しみにされていました。
Opening up the Preview
本日、興味をお持ちのすべてのお客様に Amazon Aurora with PostgreSQL Compatibility の プレビューを開放し、こちらからサインアップ可能となります。プレビューは、米国東部(バージニア北部)リージョンで実施され、従来の環境で運用されていたPostgreSQL に比べて、2-3倍の性能を提供します。このプレビューでは、高速で低レイテンシなリードレプリカをすばやく簡単に作成することも可能です。
Amazon RDS Performance Insights もPreview にてご利用可能です
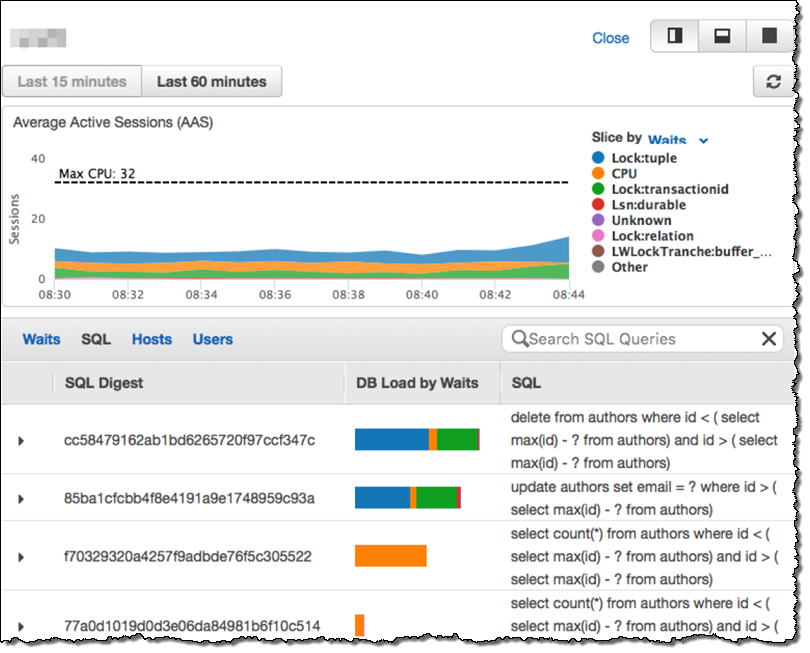
本プレビューには、Amazon RDS Performance Insights も含まれます。このツールを利用することで、各クエリの詳細を含む細かいレベルでデータベース性能を確認することができます。Performance Insight ダッシュボードを通して、データベースの負荷を可視化し、SQL, waits, users, hostsという観点でフィルタリングできます:
— Jeff;
原文: Sign up Today – Preview of Amazon Aurora with PostgreSQL Compatibility(翻訳: SA江川)
Amazon Aurora: Fast DDLの詳細
Anurag GuptaはAmazon Auroraを含む彼がデザインに参加した、いくつかのAWSデータベースサービスに携わっています。 Under the Hoodシリーズでは、Auroraを支える技術や設計について説明します。
Amazon Auroraはオープンソースデータベースのシンプルさとコスト効率とハイエンドなコマーシャルデータベースの可用性と性能を兼ね備えたMySQL互換のデータベースです。この投稿では、Amazon Auroraが一般的な、完了までMySQLでは数時間かかるようなDDL文をほぼ即座に実行出来る仕組みを見ていこうと思います。
Fast DDLとは?なぜ考慮するのか
アプリケーションを変更すると、それに付随するデータベースのスキーマを変更する必要があるケースがあります。クエリのワークロードが変わると、インデックスの追加や削除を行う必要があります。データのフォーマットが変更になると、既存のカラムのデータタイプを変更する必要があります。そして、このような変更は頻繁に起こりえます。Ruby on Railsアプリケーションをサポートする一部のDBAは、週に数十回スキーマを変更すると話しています。
多くのMySQLのDBAはご存知のように、このようなスキーマの変更はプロダクションシステムの中断が発生する可能性があります。変更に時間がかかるからです。場合によっては、完了まで数時間から数日かかることもあります。システムのリソースも奪われるため、アプリケーションのスループットも低下します。また、長時間のオペレーションは長時間のクラッシュリカバリが発生する可能性があります。DDL操作の一部は書き込みロックが必要なため、アプリケーションの一部が使用できなくなります。加えて一時的なスペースを多く必要とする可能性があり、小規模のインスタンスではディスクが不足する可能性もあります。
私たちはこのような点を取り除けるように改善を行っており、良く見る一般的なDDL操作(nullableカラムをテーブルの最後に追加)から改善を始めました。
なぜ既存の方法では問題が起こるのか?
MySQLがどの様にnullableカラムをテーブルの最後に追加する実装になっているか見ていきましょう。
MySQLは以下のような処理を行っています:
- データベースはトランザクションのprepareフェーズでオリジナルテーブルに対して排他ロックを取得します
- 変更後のスキーマで新しい空のテーブルを作成します
- 1行ずつコピーを行ない、インデックスをその後作成する。同時に実行されたデータ操作(DML)文は、一時ファイルに記録されます
- 再度、排他ロックを取得し一時ファイルから新しく作成したテーブルへDML文を適用します。適用すべき操作が多くある場合、この処理に時間を要します
- オリジナルテーブルをdropし、テーブルをリネームします
これらの処理には多くのロックが必要になり、データのコピーやインデックスの作成にオーバヘッドが必要になります。そして、I/Oが多く発生し、一時領域も消費します。
もっと良い方法はないのでしょうか?
これについてはないと思うかもしれません。各行のデータ形式は変更する必要があります。しかし、この変更をテーブル上で実行されている他のDML(および関連するI/O)操作の上にのせることで、多くのことが実行できます。
完全なアプローチは、ブログポストではやや複雑すぎるので、ここでは簡単に説明します。
Auroraでは、DDLをユーザが実行すると
- データベースがINFORMATION_SCHEMAのシステムテーブルを新しいスキーマで更新します。加えて、各操作に対してタイムスタンプを付与し変更をリードレプリカに伝搬します。古いスキーマ情報は新しいシステムテーブル(Schema Version Table)内に格納されます
同期的に行う操作はこれだけで完了です。
そして、その後のDML文は、影響のうけるデータページがスキーマの変更を待っている状態か監視します。この操作は、各ページのlog sequence number (LSN)タイムスタンプとスキーマ変更のLSNタイムスタンプを比べるだけで簡単に行なえます。必要に応じて、DML文を適用する前に新しいスキーマにページを更新します。この操作は、redo-undoレコードページの更新と同じ更新プロセスで実行されます。そして、I/Oはユーザの実行するクエリと同様に扱います。
DML操作では、ページ分割が発生する可能性があるため、ページの変更に注意する必要があります。変更はAuroraのレプリカノードでも同様に扱う必要があります。そして、リードレプリカではどのデータへの変更も許可されていません。SELECT文のために、MySQLに戻されるメモリ上のバッファ内のイメージ変更します。この方法では、ストレージ内で新旧のスキーマが混在していたとしても常に最新のスキーマを参照出来ます。
もし、皆さんがAuroraがどのようにストレージからの読み込みとログの適用を行っているかご存知の場合、このアプローチが似ていると感じると思います。しかし、このアプローチではredo logのセグメントではなく、変更を記録するためにテーブルを使用します。
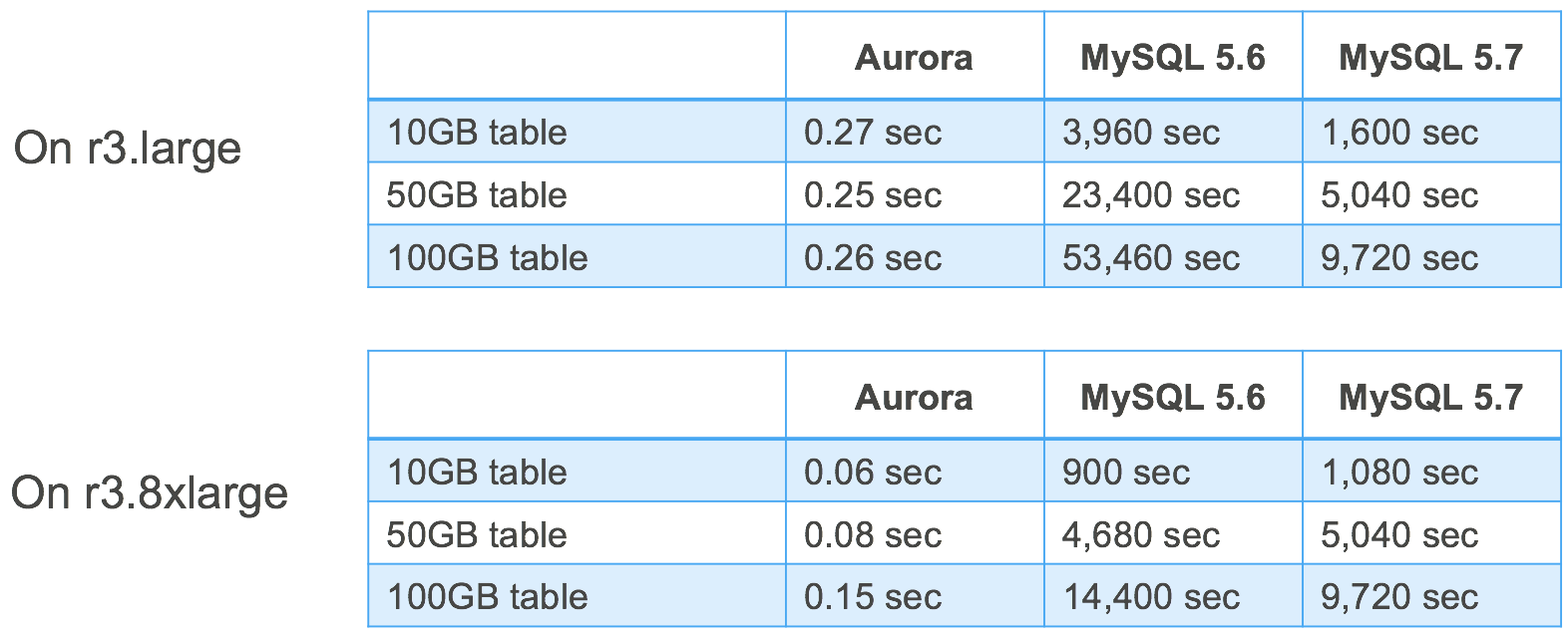
パフォーマンス比較は以下のようになっています。Auroraは Schema Version Tableを変更するために一定の時間で処理が完了しているのがおわかりになると思います。しかし、MySQLではテーブルサイズにほぼ比例して線形に処理時間が増加しています。
明らかに私達が改善すべき多くのDDL文があります。しかし、殆どの物は同様のアプローチで対処可能と考えています。
このことは重要です。たとえデータベースが通常の可用性で稼働していても、これらの長い操作ではアプリケーションへ影響が発生します。それらを並列、バックグラウンド、非同期処理に移すことで違いが出てきます。
質問やフィードバックはありますか?aurora-pm@amazon.comへ是非お寄せ下さい。皆さんの考えや提案を私たちは非常に大切にしています。
注: こちらの機能は2017年4月6日現在Lab modeにてご提供しております。
翻訳は星野が担当しました。原文はこちら。
Amazon Auroraアップデート: クロスリージョン・クロスアカウントサポートの拡張、T2.Small DBインスタンス、リージョンの追加
Amazon Auroraの最近のアップデートを振り返ってみたいと思います。Amazon AuroraはMySQL互換のハイパフォーマンスなデータベースです(間もなくPostgreSQL互換のAuroraもリリース予定です)。Amazon Auroraの紹介は、【AWS発表】Amazon Auroraをご利用頂けるようになりました!や【AWS発表】Amazon Aurora – Amazon RDSに費用対効果の高いMySQL互換のデータベースが登場!!をご覧ください。
最近Auroraへ追加された機能は以下のとおりです
- クロスリージョンスナップショットコピー
- 暗号化されたデータベースのクロスリージョンレプリケーション
- 暗号化されたスナップショットのアカウント間の共有
- US West (Northern California)リージョンのサポート
- T2.smallインスタンスサポート
クロスリージョンスナップショットコピー
Amazon Auroraのスナップショット(自動・手動取得に関わらず)リージョン間でコピー出来るようになりました。スナップショットを選択し、Snapshot ActionsからCopy Snapshotを選択します。その後、リージョンを選択後、新しいスナップショットの名前を入力します。
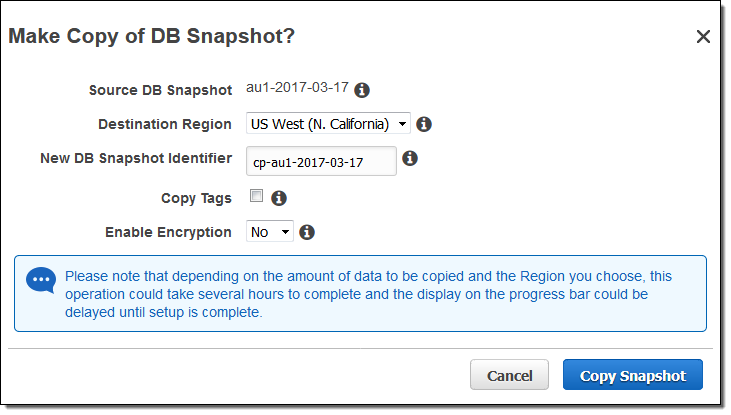
この操作の中で、暗号化済みスナップショットも選択可能です。詳細はドキュメントをご覧ください。
暗号化されたデータベースのクロスリージョンレプリケーション
Amazon Aurora DBを作成する際に暗号化オプションを設定出可能です。
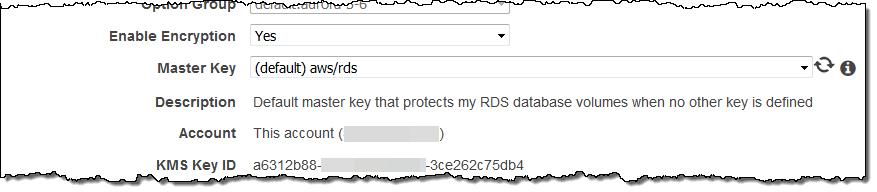
数クリックで他のリージョンにリードレプリカを作成することが出来るようになりました。この機能を利用することで、マルチリージョン、ハイアベイラビリティなシステムが構築可能になりますし、ユーザに近い位置にデータを移動することも可能です。クロスリージョンリードレプリカを作成するには、既存のDBインスタンスを選択し、メニューからCreate Cross Region Read Replicaを選択するだけです。
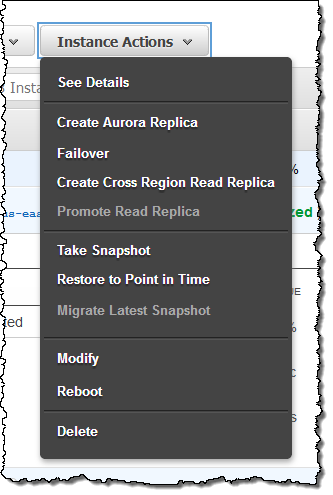
その後、Network & Securityからリージョンを選択し、Createをクリックします。
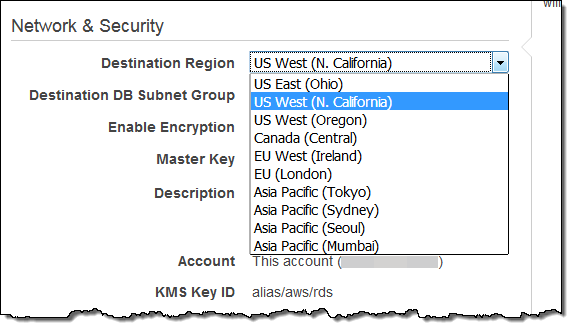
レプリケーション先のリージョンには必ず2つ以上のアベイラビリティゾーンを含んだDB Subnet Groupが必要です。
このパワフルな新機能について詳細は、ドキュメントをご覧ください。
暗号化されたスナップショットのアカウント間の共有
Amazon Aurora DBインスタンスを作成する際に、定期的に自動でスナップショットを行う設定が可能です。この他にも、数クリックで任意のタイミングでスナップショットを作成することも可能です。
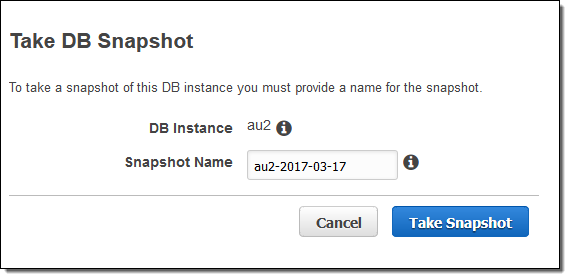
DBインスタンスが暗号化されている場合はスナップショットも暗号化されます。
AWS間で暗号化されたスナップショットを共有出来るようになりました。この機能を使うためには、DBインスタンスはdefault RDS keyではないマスターキーで暗号化されている必要があります。まず、スナップショットを選択し、Snapshot ActionsメニューからShare Snapshotを選択します。
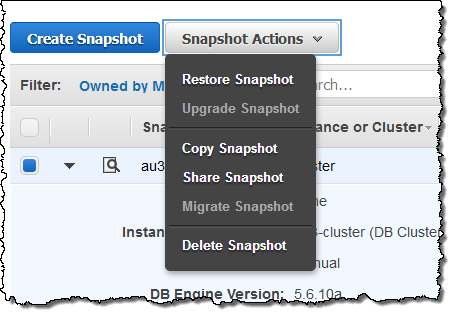
そして、共有先のAWS Account IDを入力し(それぞれのアカウント毎にAddをクリックします)、Saveを選択します。
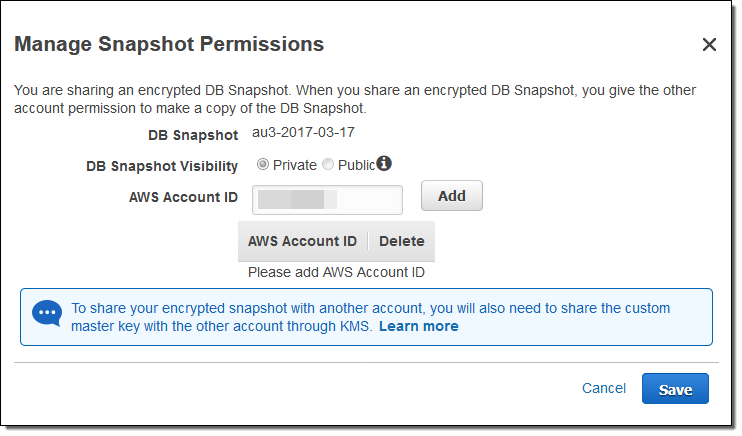
この他にも、スナップショットの暗号化で使用したキーも共有する必要があります。この機能の詳細はドキュメントをご覧ください。
US West (Northern California)リージョンのサポート
Amazon Aurora DBをUS West (Northern California) リージョンでご利用頂けるようになりました。Auroraをご利用頂けるリージョンのリストは以下の通りです。
- US East (Northern Virginia)
- US East (Ohio)
- US West (Oregon)
- US West (Northern California)
- Canada (Central)
- EU (Ireland)
- EU (London)
- Asia Pacific (Tokyo)
- Asia Pacific (Sydney)
- Asia Pacific (Seoul)
- Asia Pacific (Mumbai)
それぞれのリージョンでの価格については、こちらをご覧ください。
T2.smallインスタンスサポート
t2.small DBインスタンスをご利用頂けるようになりました。
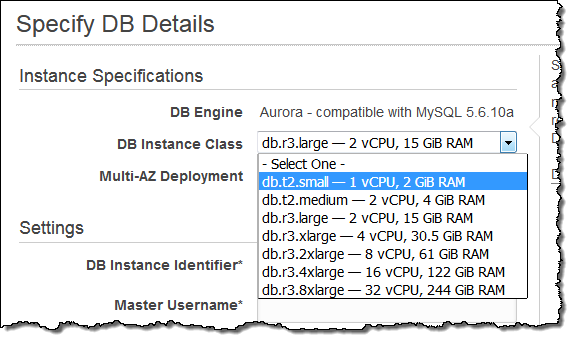
これらの経済的なインスタンスは、開発環境とテスト環境、および負荷の少ないプロダクションワークロードに最適です。また、Amazon Auroraの経験を積むこともできます。これらのインスタンス(昨年11月にリリースしたt2.mediumを含む6つのインスタンスと同様)は、Auroraが利用できるすべてのAWSリージョンで利用可能です。
t2.small DBインスタンスのオンデマンド価格はUS East (Northern Virginia)リージョンでは、1時間あたり$0.041からご利用いただけ、3年のAll Upfrontリザーブドインスタンスをご利用頂くと、1時間あたり$0.018となります。さらに詳細な価格についてはAmazon Auroraの料金ページをご覧ください。
Amazon Aurora: 暗号化されたスナップショット・データベースに対する新機能
本日Amazon Auroraの新機能を2つリリース致しました。
暗号化済みデータベースのクロスリージョンサポート
暗号化済みのデータベースでAWSリージョンをまたいだレプリケーションがサポートされました。クロスリージョンレプリケーションを利用することで、ユーザに近い場所でリードオペレーションを実行することが可能になったり、ディザスターリカバリー環境を簡単に構築出来ます。また、リージョンをまたいだデータベースの移行も容易に行なえます。
また、暗号化されたスナップショットをAWSリージョン間でコピー可能になりました。開発チームとテストチームが様々な地域に分散していたとしても、本番データベースの最新のコピーを安全に共有することによって、グローバルな開発プロセスを構築できます。また、遠隔地にスナップショットを安全に保管することで、ディザスターリカバリー戦略を強化することも可能です。
詳細は、クロスリージョンレプリケーションとクロスリージョンスナップショットコピーのドキュメントをご覧ください。
AWSアカウント間で暗号化済みスナップショット共有をサポート
AWSアカウント間で暗号化済みスナップショットの共有が可能になりました。暗号化キーを共有しているアカウントを分離するためにAuroraのセキュリティモデルを拡張出来ます。他のアカウントの所有者は、スナップショットをコピーしたり、スナップショットからデータベースインスタンスを復元することができます。
詳細なドキュメントはこちらをご覧ください。
Amazon Auroraは、フルマネージド、高可用性、コストパフォーマンスのよいリレーショナルデータベースです。MySQLと互換性があるためアプリケーションコードの変更なしに移行が行なえます。また、こちらのツールを利用することでダウンタイムを最小限に移行を行うことも可能です。
翻訳は星野が担当しました。原文は、Amazon Aurora Announces Encryption Support for Globally Distributed Database Deployments, Amazon Aurora Supports Cross-Account Encrypted Snapshot Sharing
シャーディングされたシステムをAuroraに集約してリソースの消費を削減
リレーショナルデータベースを利用したワークロードで、スケーリングを考えないといけなくなった時に、一般的にスケールアップとスケールアウトと2つの手法が上げられます。一般的にスケールアップの方が簡単に行えます(単純にスペックのいいマシンを購入するなど)。一方スケールアウトは、それぞれ独立したホストで稼働している複数のサーバへ、データベースをシャーディングする必要があり作業が煩雑になります。
難しさにも関わらずスケールアウトとが最近のトレンドとなってきています。コモディティハードウェアとシステムリソースへの要求の増加に伴いワークロードを効率的にシャーディングする必要が出てきました。シャーディングされたシステムの1つの欠点として管理コストがあげられます。もし4つのシャードを持っているとすると、4つのデータベースを管理する必要があります。しかし、たとえそうだとしてもスケールアウトはスケールアップよりコスト効率がいい場面が多かったのです。特にAmazon RDSの様なマネージドデータベースの登場によりリレーショナルデータベースの管理を軽減することが出来るようになったのがその1つの要因です。
しかし、なぜ過去形なのでしょうか? Amazon Auroraの登場によりスケールアップという選択肢が戻ってきたのです。Amazon Auroraは非常にスケールし、MySQL互換のマネージドデータベースサービスです。Auroraは2 vCPU/4 GiBメモリというスペックのインスタンスから、32 vCPU/244 GiBメモリ搭載のインスタンスまでを提供しています。Amazon Auroraは需要に応じてストレージが10 GBから64 TBまで自動的に増加します。また、将来のリードキャパシティの増加に備えて15インスタンスまで低遅延のリードレプリカを3つのアベイラビリティーゾーンに配置することが可能です。この構成の優れている点は、ストレージがリードレプリカ間でシャーディングされている点です。
シャーディングされたシステムを1つのAuroraインスタンスに集約、もしくは少数のシャードに集約しAuroraで稼働させることで多くのコストを節約する事が可能です。これがこのブログポストでお話したいことの全てです。
シャーディングされたシステムをAuroraに集約するために – まずはじめに –
多くのシャーディングされたシステムは標準的な方法で行うことが可能です。データはカスタマーIDなどの特定のキーを元に分割されており、何かしらマッピングを行う機能を用いてシャードに分割されています。この方法には様々な種類があり、1例として参照用のデータを別のシステムか1つのシャードに格納したり、全てのシャードに参照用のデータを配置するなどがあります。どのようにデータを分割しても、シャーディングの複雑さは通常、アプリケーションレイヤーにあり、シャードの統合は比較的容易に行えます。
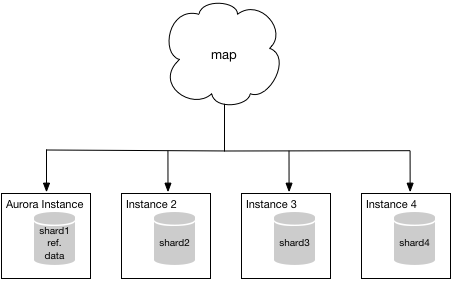
多分皆さんは今、”利点はわかった。ではどうやってAuroraにデータを移行するのか”という疑問をお持ちかと思います。今回の例では、MySQLを利用して4つのシャードを持つシステムを利用していると仮定したいと思います。また、各シャードは他のシャードが持っているデータを持っていないものとします。また1つのシャードが参照用のデータを持っている前提とします。現在の構成は以下の図の様な構成になっていると思います。mapは各シャードへのアプリケーショントラフィックを表しています。
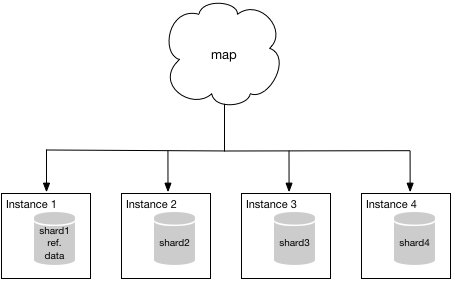
MySQLを運用しているため、Aurora documentationに記載されている方法を利用を利用可能です。簡単に移行を行うために、まずはじめに参照データのみが格納されているインスタンス1を移行します。しかし、どのシャードを最初に移行するかはそれほど重要ではありません。 移行が完了すると、マッピング機能はインスタンス1ではなくAuroraインスタンスを指します。システムは次の図のようになります。
残りのデータを移行する
この時点で、Auroraが特定のワークロードをどれくらいうまく処理しているか評価し、必要な調整を行う必要があります。設定に問題がなくなれば、他のデータを移行する準備は完了です。では、シャード2をAuroraインスタンスに移行しましょう。しかし、どうやって?
AWS Database Migration Service (AWS DMS)を是非ご活用下さい!AWS DMSはこのようなマイグレーションにも対応するように作られました。シャード2からAuroraインスタンスへデータをコピーするためにDMSをご利用になれます。更に、シャード2にとランアクションを実行しながらこれらの作業が可能です。DMSは初期データのロードが完了すると、それらのトランザクションデータをシャード2から収集しAuroraインスタンスに適用します。DMSは継続的にシャード2からAuroraインスタンスへデータを移行し、シャード2の代わりにAuroraインスタンスの利用を開始させるまで同期させます。シャード2からAuroraインスタンスへ切り替える準備が出来たら、シャード2へのトランザクションを停止し、DMSが最後のトランザクションをAuroraインスタンスへ適用するまで待ち、mapの設定を、シャード2に向いていたトラフィックを直接Auroraインスタンスへ向くように変更します。設定が完了すると、システムは以下のような状態になります。
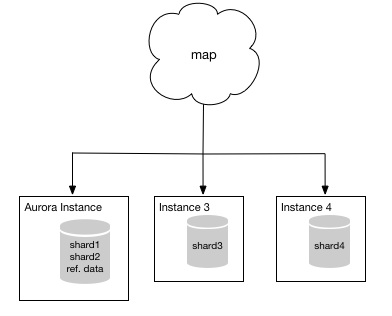
この時点から、Database Migration Serviceを残り2つのシャードをAuroraインスタンスへ移行するために利用出来ます。最終的にシステムは以下の様になります。
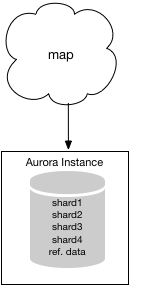
複雑なシャードの扱い方
これでシャーディングされたシステムが1つのAuroraインスタンスへマイグレーションが完了し、コストを削減することが出来ました!しかし、MySQLを利用し、クリーンなシャードを利用しているとう仮定で話をすすめてきました。もしこれらの仮定にそぐわない場合はどうでしょうか?
それでは、シャードがクリーンな状態でない場合を見ていきましょう。例えば、システムが最初に2つのシャードで構成されていたとします。ある時点で、その2つのシャードを4つのシャードに分割したとします。 リシャードィングプロセスの一環として、シャード1と2のコピーを作成してシャード3と4を作成し、マッピング機能を更新しました。 結果は次のようになります。

この図は状況が複雑であるように見えます。 理想的には、このようなリシャードィングの際に、シャードに関係のないデータ、つまりグレーアウトされたデータをパージします。 しかし、必ずしも必要というわけではないし、時には難しいこともあるので、データをそのままにしておく事があります。 この方法では使用されていない冗長なデータを保持する”汚れた”シャードが発生します。 これらのシャードを統合しようとすると、アクティブなデータの行が、削除すべき重複した行と衝突する問題が発生します。
何をすべきか? シャードの統合を行う前に、利用していない行を削除することができます。 しかし、特にマッピング関数がID値のハッシュ(一般的な方法の1つ)で構成されている場合、利用していない行を特定するのは難しいかもしれません。
諦めないで下さい! 別のオプションがあるかもしれません。 各シャード内のデータが1つのデータベースに含まれている場合は、DMSを使用して、システムの各シャードをAuroraインスタンス内の単一のMySQLデータベースに統合できます。 次に、既存のマッピング・スキームを使用して、Auroraインスタンス内の適切なデータベースにトランザクションを転送できます。 この例では、Auroraインスタンスは次のようになります。
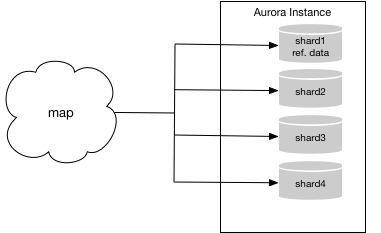
MySQL以外のデータベースを利用している場合
他の仮定として、データベースエンジンとしてMySQLデータベースを利用をしている前提がありました。もしそうでなければ? OracleまたはMicrosoft SQL Serverを使用する場合はどうなるでしょうか? 大丈夫です! AWS Schema Conversion Tool が役立ちます!
ドキュメントの最初で「AWS Schema Conversion Toolは、ソースデータベースのスキーマとカスタムコードの大部分をターゲットデータベースと互換性のあるフォーマットに自動的に変換することで、異種データベースの移行を容易にします」と述べています。シャーディングされたシステムでは、ストアドプロシージャとトリガを使用してデータベース内に組み込まれた多くのビジネスロジックは、通常すでにアプリケーション側に移動されています。 AWS Schema Conversion Toolで、ソースデータベースとしてサポートされているデータベースエンジンでシャーディングされたシステムを利用している場合、Auroraへの変換と統合が可能かどうかを調べる価値があります。 統合の恩恵を受けるだけでなく、オープンソースプラットフォームへの移行のメリットも得られます。
さらに踏み込んで
さらに詳細に興味がありますか? AWS Database Migration Service を使用して、シャーディングされたデータベースを1つ以上のAuroraインスタンスに統合する方法を説明する資料をまとめはじめました。 この例では、DMSチームが提供するMySQLサンプルデータベースのシャーディングバージョンを使用しています。 私たちはこのシャーディングされたバージョンをRDSスナップショットとして利用できるようにしました。 スナップショットは公開されているため、こちらの説明に従って試すことが可能です。それぞれ、説明中でmysql-sampledb-master-shard、mysql-sampledb-shard1、mysql-sampledb-shard2と呼ばれていたものです。
— Ed Murray (manager at Amazon Web Services) (翻訳は星野が担当しました。原文はこちら)
RDS MySQL DBインスタンスからAmazon Aurora Read Replicaを作成可能になりました
24時間365日稼働しているアプリケーションが利用しているデータベースエンジンを他のデータベースエンジンに移行するにはいくつかの方法を使う必要があると思います。データベースをオフラインにせずに移行する良い方法として、レプリケーションを利用する方法があります。
本日、Amazon RDS DB for MySQLインスタンスを Amazon AuroraにAurora Read Replicaを作成して移行する機能をリリースしました。マイグレーションは、まず既存のDBスナップショットを作成し、そこからAurora Read Replicaを作成します。レプリカのセットアップが完了後、ソースデータベースとのレプリケーションの設定を行い最新のデータをキャッチアップします。レプリケーションラグが0になればレプリケーションが完了した状態です。この状態になった後に、 Aurora Read Replicaを独立したAurora DB clusterとして利用可能で、アプリケーションの設定を変更しAurora DB clusterに接続します。
マイグレーションはテラバイトあたり数時間かかります。また、6TBまでのMySQL DBインスタンスに対応しています。InnoDBテーブルのレプリケーションはMyISAMテーブルのレプリケーションよりもやや高速で、圧縮されていないテーブルの利点も受けられます。
RDS DBインスタンスをマイグレーションするためには、 AWS Management ConsoleからRDSのコンソールを選択し、Instance Actionsを選択します。その後、Create Aurora Read Replicaを選択するだけです:
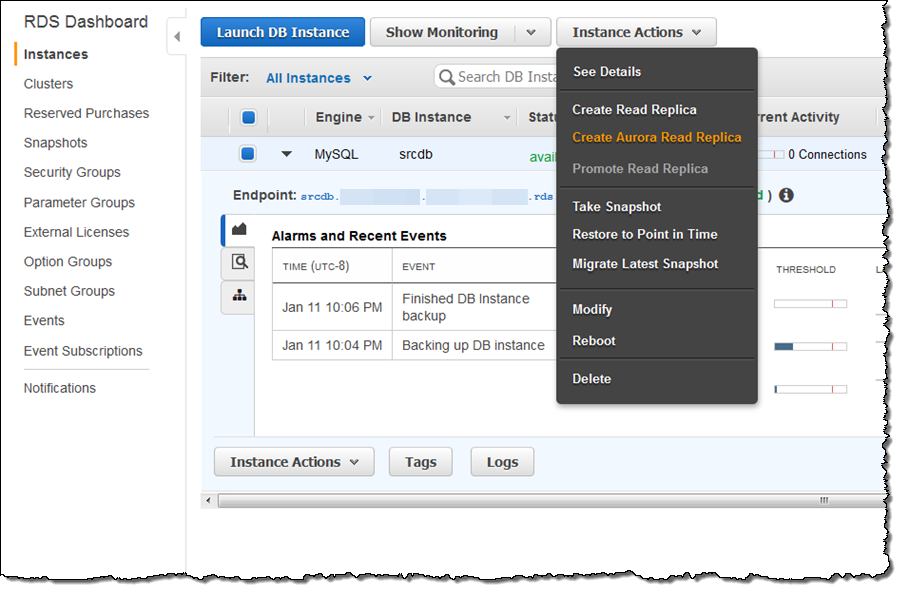
そして、データベースインスタンスの情報やオプションを入力し、Create Read Replicaをクリックします:
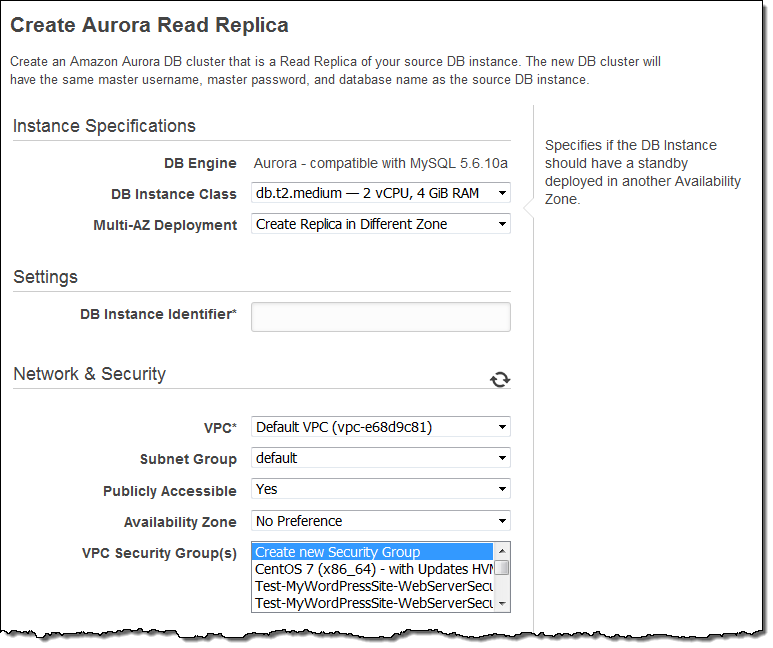
コンソール上でマイグレーションの進捗状況を閲覧出来ます:
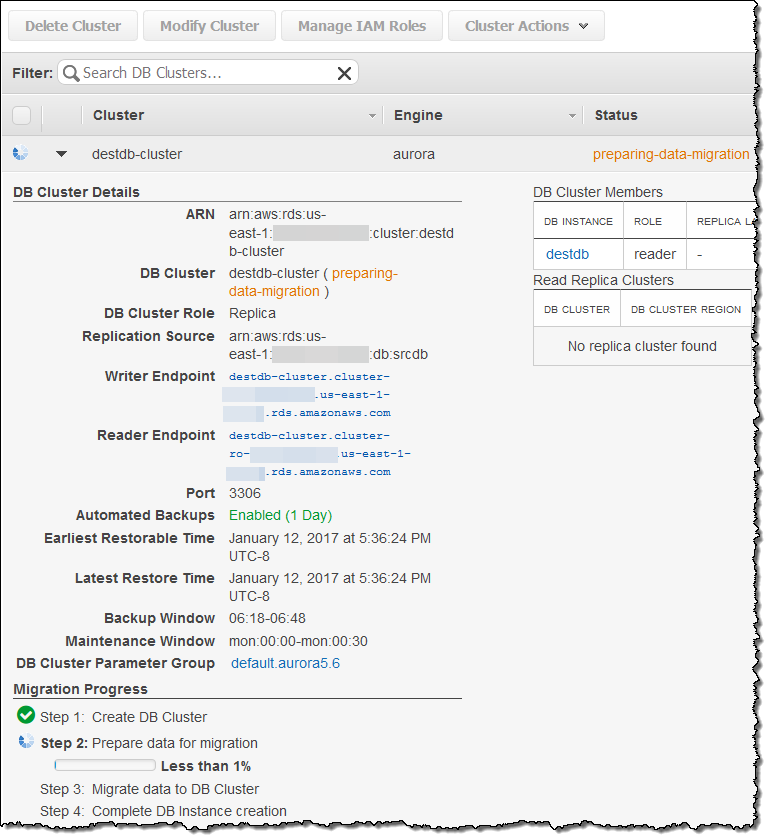
マイグレーション完了後、Aurora Read Replicaでレプリカラグが0になるのを待ちます(SHOW SLAVE STATUSコマンドをレプリカで実行し、“Seconds behind master”を監視します)。その後、ソースのMySQL DBインスタンスへの新しいトランザクションを停止し、Aurora Read ReplicaをDBクラスタに昇格させます:
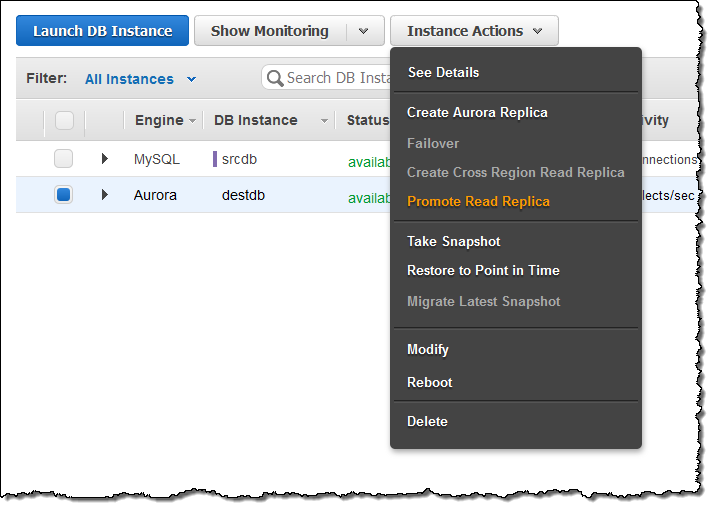
新しいクラスタが利用可能になるまで待機します(通常は1分程度):
最後に、アプリケーションの設定をクラスタのread/writeエンドポイントを利用するように設定し完了です!
Amazon Aurora Clusterに監査機能を追加
re:InventでMySQLデータベースと互換性があり、コマーシャルデータベースの性能と可用性、オープンソースデータベースのコストパーフォーマンスの両面をそなえた、Amazon Auroraの新機能を発表しました。
今日、advanced auditing機能が全てのお客様にご利用頂けるようになったことを発表致します。
advanced auditingとは
Auditingとは特定のイベントを収集して手動もしくは他のアプリケーションで分析出来るように提供する機能を指します。これらのログはコンプライアンス規定やガバナンスのベースになる情報として利用可能です。advanced auditingの例には、ログ分析、ユーザーアクションの監査(過去のイベントおよび、ニアリアルタイムの脅威検出など)、セキュリティ関連のイベントに設定されたアラームのが含まれます。 Auroraのadvanced auditing機能は、データベースのパフォーマンスに与える影響を最小限に抑えながら、これらの機能を提供するように設計されています。
advanced auditingを利用するには
まずはじめに、advanced auditingを有効にし、audit logを参照します。
advanced auditingの有効化
DBクラスタパラメータグループにあるパラメータを設定することでadvanced auditingの有効化や設定を行うことができます。これらのパラメータの変更がDBクラスタの再起動は必要ありません。また、動作は Aurora DB instance parametersと同様です。
機能を有効/無効化するために server_audit_loggingパラメータを利用します。server_audit_eventsパラメータでどのイベントをログに記録するか設定します。
server_audit_excl_usersとserver_audit_incl_usersパラメータでどのユーザを監査対象にするか設定可能です:
- server_audit_excl_usersとserver_audit_incl_usersが未指定の場合(デフォルト値)は全てのユーザが記録されます
- server_audit_incl_usersにユーザを設定し、server_audit_excl_usersを指定しない場合、server_audit_incl_usersに指定したユーザのみ記録されます
- server_audit_excl_usersにユーザを設定し、server_audit_incl_usersを指定しない場合、server_audit_excl_usersに指定したユーザ以外が記録の対象になります
- server_audit_excl_usersとserver_audit_incl_usersに同一のユーザを設定した場合は、server_audit_incl_usersの優先度が高いため記録の対象になります
advanced auditingのパラメータの詳細を以下でご説明します
server_audit_logging 監査ログの有効/無効化を指定します。標準ではOFFになっているので、ONに指定することで有効になります
- Scope: Global
- Dynamic: Yes
- Data type: Boolean
- Default value: OFF (disabled)
server_audit_events イベントのリストをカンマで区切って指定します。リスト中のエレメント間にスペースは入れなように気をつけて下さい
- Scope: Global
- Dynamic: Yes
- Data type: String
- Default value: Empty string
- 有効な値: 以下のイベントの好きな組み合わせを指定可能
- CONNECT – ユーザ情報を含む、接続の成功・失敗・切断を記録
- QUERY – シンタックスや権限不足で失敗したクエリを含む、全てのクエリ文字列とクエリの結果をplane textで記録
- QUERY_DCL – DCLクエリのみを記録 (GRANT, REVOKEなど)
- QUERY_DDL – DDLクエリのみを記録 (CREATE, ALTERなど)
- QUERY_DML – DMLクエリのみを記録 (NSERT, UPDATEなど)
- TABLE – クエリの実行で利用されたテーブルを記録
server_audit_excl_users ログに記録しないユーザをカンマ区切りで指定します。エレメント間にスペースは入れないよう気をつけて下さい。接続・切断のイベントはこの設定に影響を受けないため記録されます。server_audit_excl_usersに指定されていたとしてもserver_audit_incl_usersにも指定されていた場合は、server_audit_incl_usersの優先度が高いため記録の対象になります
- Scope: Global
- Dynamic: Yes
- Data type: String
- Default value: Empty string
server_audit_incl_users ログに記録するユーザをカンマ区切りで指定します。エレメント間にスペースは入れないよう気をつけて下さい。接続・切断のイベントはこの設定に影響を受けません。ユーザがserver_audit_excl_usersに指定されていたとしても、server_audit_incl_usersの優先度が高いため記録の対象になります
- Scope: Global
- Dynamic: Yes
- Data type: String
- Default value: Empty string
audit logを参照する
AWS Management Consoleからaudit logを参照可能です。Instancesページから、DBクラスタを選択し、Logを選択します。

MariaDB Audit Pluginの事をご存知であれば、auditingについてAuroraが取っているアプローチとの幾つかの違いに気づくかと思います。
- Aurora advanced auditingのタイムスタンプはUnix timeフォーマットで記録されます
- イベントは複数のログファイルに記録され、ログはシーケンシャルには並んでいません。必要に応じてファイルの結合やタイムスタンプやquery_idを使用してソートを行えます。Unixをお使いの場合は以下のコマンドで実現出来ます。 cat audit.log.* | sort -t”,” -k1,1 –k6,6
- ファイル数はDBインスタンスサイズに応じて変化します
- ファイルのローテーションは100MB毎に行われ、閾値の変更は行なえません
MySQLからマイグレーションした後のAurora advanced auditingの有効化は方法が異なります。 Audit logの設定はDBクラスタ向けのパラメータグループで行ないます。
Auroraがどのようにadvanced auditingを実装したか
監査機能はコマーシャルデータベスでもオープンソースデータベース一般的に利用出来る機能です。この機能は一般的にパフォーマンスへ大きな影響を与えます。特にデータベースの利用率が高い場合は顕著です。Auroraでの実装の1つのゴールは様々な情報をパフォーマンスの犠牲なくユーザに提供することです。
パフォーマンスを維持するために
パフォーマンスの課題をどの様に解決したか理解するために、私達のadvanced auditingの実装とMariaDB Audit Pluginの実装を比較してみます。MySQL Community Editionではnative audit logを提供していないため、私たちは比較のためにこちらを利用します。そして、 MariaDB Audit Pluginはオープンソースコミュニティの中で、これらの制約を埋める一般的なオプションとしてあげられます。
MariaDB Audit Pluginは、シングルスレッドでシングルミューテックスを処理と各イベントの書き出しに利用します。このデザインは、ログの書き出しのボトルネックに起因するパフォ=マンスの低下を起こしますが、イベントの順序を厳密に保存することが出来ます。もし、このアプローチをAuroraに利用すると、データベースエンジンの期待するスループットや高いスケーラビリティにより、パフォーマンスへのインパクトが更に大きくなってしまいます。
高いパフォーマンスを維持するために、イベント処理とイベントの書き出しロジックを再設計しました。入力面では、ラッチフリーキューを他のスレッドをロックすること無くaudit logを保存するために利用しました。出力面では、ラッチフリーキューから複数のファイルへイベントを書き出すためにマルチスレッドモデルを利用しています。このファイルを処理することで、イベント順に並んだ1つの監査ログとして生成出来ます。

ログフォーマット
audit logは各インスタンスのローカル(エフェメラル)ディスクに保存されます。各Auroraインスタンスは4つのログファイルに書き込みます。
- Encoding: UTF-8
- ファイル名パターン: audit.log.0-3.%Y-%m-%d-%H-%M-rotation
- 保存場所: /rdsdbdata/log/audit/ (各ホスト毎)
- ローテーション: 各ログファイル毎に100MBで、現在は変更不可。4つのログファイルの内、もっとも大きなファイルサイズが100MBになった場合、システムは新しいログファイルのセットへローテーションを行ないます
- クリーンアップ: ディスクスペースを解放するために、ディスク消費量やファイルの世代に応じて古くなったaudit logを削除します
- ログフォーマット: timestamp,serverhost,username,host,connectionid,queryid,operation,database,object,retcode
| パラメータ | 説明 |
| timestamp | 秒精度のログが記録された時点のUnixタイムスタンプ |
| serverhost | ログが記録されたホスト名 |
| username | 接続ユーザ |
| host | ユーザの接続元ホスト |
| connectionid | ログを記録するためのコネクションID |
| queryid | 関連するテーブルやクエリを特定するために利用するクエリID。TABLEイベントでは複数行記録される |
| operation | 記録されたactionタイプ (CONNECT, QUERY, READ, WRITE, CREATE, ALTER, RENAME, DROP) |
| database | USEコマンドで指定されたデータベース名 |
| object | QUERYイベントでは、実行されたクエリ。TABLEイベントではテーブル名 |
| retcode | ログを記録するためのリターンコード |
他の方法と比較を行った場合
前述のように、多くのデータベースでは監査ログ機能が提供されていますが、監査機能が有効になっているとパフォーマンスが低下します。参照のみのワークロードを用いて、8xlargeインスタンス使用し、MariaDB Audit Pluginを有効にしたMySQL 5.7とパフォーマンス比較を行ないました。以下の結果のとおり、MySQLではAudit log機能が有効になっていると性能の大幅な低下が起こっています。Auroraでの性能低下は抑えられています。Auroraでは、15%の低下で抑えられていますが、MySQL5.7では65%の低下となっています。結果として、audit機能が有効になっている場合、AuroraのパフォーマンスはMySQL 5.7と比較して倍以上に向上しました。

Advanced auditingは本日からご利用頂けます!機能の詳細はドキュメントをご覧ください。
注: こちらの機能はAurora version 1.10.1からご利用頂けます (https://forums.aws.amazon.com/ann.jspa?annID=4349)
— Sirish Chandrasekaran (product manager at Amazon Web Services) (翻訳は星野が担当しました。原文はこちら)
Amazon Auroraアップデート – 空間インデックス・ゼロダウンタイムパッチ
AWSの様々なサービスがリリースされてりますが、Amazon Auroraは現在もAWSサービスの中で最も速く成長しているサービスです!お客様には速度、パフォーマンスや可用性を評価頂いています。MySQL互換のAuroraを多く利用いただいていますが、今後リリースされるPostgreSQL互換のAuroraへも期待していただいています(詳細や最近Auroraに追加された機能はAmazon Aurora アップデート – PostgreSQL 互換のエンジンをご覧ください)。
本日、AWS re:Inventでアナウンスをした、空間インデックスとゼロダウンタイムパッチの2つの機能をリリースしました。
空間インデックス
Amazon Auroraは今までも地点やエリアを表すためにGEOMETRY型をご利用頂けました。この型を使ってカラムを作成し、ST_Contains, ST_CrossesやST_Distance(更に他にも)といった機能をspatial queryを実行するためにお使い頂けました。これらのクエリはパワフルですが、大きなデータセットに対してスケールするには不十分な点や制限がありました。
Auroraを利用して、ラージスケールな位置情報を使うアプリケーションを作成していただくために、空間データに対してとても効率的なインデックスをお使い頂けるようになりました。Auroraは dimensionally ordered space-filling curve (次元的に整列した空間充填曲線)を利用して、スケールし、高速かつ正確に情報を取り出すことが出来ます。インデックスはb-treeを使い、MySQL5.7と比較して最大2倍のパフォーマンスです(詳細は、こちらのプレゼンテーションとAmazon Aurora Deep Diveのこちらの箇所をご覧ください)。
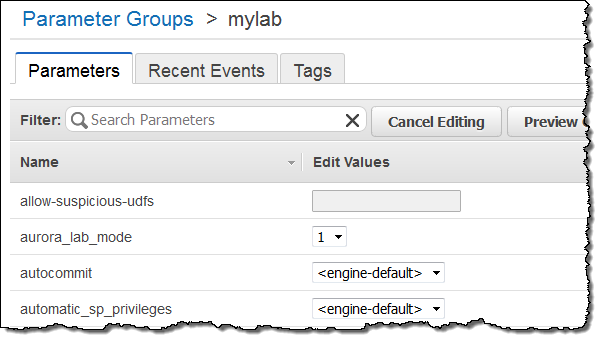
この機能を現在ご利用頂くためには、Aurora Lab Modeを有効にして頂く必要があります。機能を有効にした後は、既存のテーブルや新規に作成するテーブルにspatial indexを設定頂けます(詳細はこちらをご覧ください)。
ゼロダウンタイムパッチ
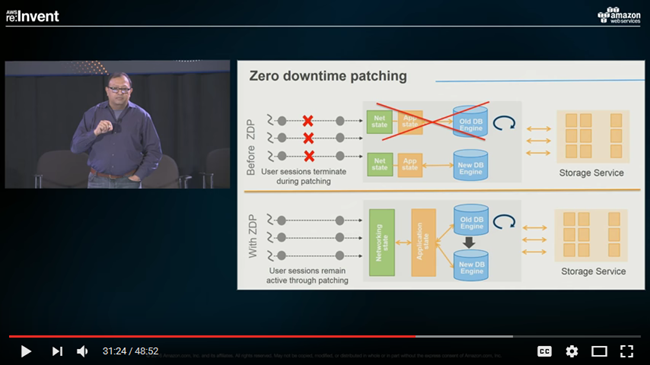
今日のような24×7の世界で、データベースへのパッチ適用やアップデートでデータベースをオフラインにする良い時間はありません。しかし、高可用性を維持するために、read replicaを利用して昇格させる方法が利用されてきました。
私達の、新しいゼロダウンタイムパッチ機能により、Auroraインスタンスへのパッチ適用をダウンタイム無しで、可用性にも影響を及ぼさずオンラインで実行出来るようになりました。この機能は、現在の最新バージョン(1.10)が適用されたAuroraインスタンスで、ベストエフォートで機能します。シングルノードクラスタとマルチノードクラスタのWriterインスタンス双方で機能しますが、バイナリログが有効になっている場合は無効になります。
このパッチは、既に開かれているSSLコネクション、アクティブなロック、トランザクションの完了やテンポラリテーブルの削除を待ちます。パッチ適用可能なウインドウが出来た場合、ゼロダウンタイムパッチとして適用します。アプリケーションセッションは保持されたまま、パッチが適用される間データベースエンジンがリスタートします。この間瞬間的(5秒程度)なスループット低下が発生します。もし、ゼロダウンタイムパッチで適用出来るウインドウがなかった場合、通常のパッチ適用プロセスが実行されます。
さらに詳細にこの機能がどのように動作するかや実装方法については、Amazon Aurora Deep Dive videoのこちらの箇所をご覧ください。
本日からご利用いただけます
これらの新機能が本日からご利用頂けます!
その他の機能改善やBug fixはこちらのforumをご覧ください。
Amazon Aurora アップデート – PostgreSQL 互換のエンジン
(昨日のように思いますが)ちょうど2年前、私は Amazon Aurora を【AWS発表】Amazon Aurora – Amazon RDSに費用対効果の高いMySQL互換のデータベースが登場!! の記事にて紹介しました。この記事では、RDS チームがリレーショナルデータベースモデルを既存の制約にとらわれない新鮮な視点で考え、クラウドに適したリレーショナルデータベースをいかに作ったかを説明しました。
それ以来、私たちがお客様から受けたフィードバックは心温まるものでした。お客様は、MySQL との互換性、高可用性、組み込みの暗号化オプションを愛しています。お客様は、Aurora が、耐障害性、自己修復機能を兼ね備え、10 GB から利用開始でき、事前のプロビジョニングなしに 64 TB までスケール可能なストレージを備えているという事実を頼りにしています。そして、Aurora は 6 つのコピーが 3 つのアベイラビリティーゾーンにわたってレプリケートされ、そのデータを性能や可用性への影響なく、Amazon Simple Storage Service (S3) にバックアップされるということをお客様は把握しています。お客様のシステムがスケールする際には、共通のストレージからデータを読み込む最大 15 個の低レイテンシーリードレプリカを追加できることを把握しています。費用の観点では、Aurora はコンピューティングリソースとストレージのリソースを効率的に使用し、商用データベースと比較して、費用対性能が10倍もよくなることを理解しました。世界規模の商用環境で、どのようにお客様がAurora を使用しているかについては、Amazon Aurora のパートナー紹介とお客様の声 をご覧ください。
もちろん、お客様は常によりよいものを求め、我々もお客様の必要とするものを理解し、それを達成するために最善を尽くします。ここでは、お客様のフィードバックに応えてリリースした最近のいくつかのアップデートを振り返ります。
- 10月 – ストアードプロシジャーからLambda Functionの呼び出し
- 10月 – S3からのデータ読み込み
- 9月 – リーダーエンドポイントが追加されました – 負荷分散と高可用性向上 –
- 9月 – Parallel Read Ahead, Faster Indexing, NUMA Awareness
- 7月 – MySQLバックアップからクラスタを作成可能になりました
- 6月 – Cross-Region Read Replicaがご利用頂けるようになりました
- 5月 – アカウント間でスナップショットを共有頂けるようになりました
- 4月 – Cluster view for Amazon Aurora in RDS console
- 3月 – Amazon Auroraのリードレプリカで、フェイルオーバーの順番を指定可能になりました
- 3月 – Local Time Zone Support
- 3月 – ソウルリージョンでご利用可能に
- 2月- シドニーリージョンでご利用可能に
そして今、 PostgreSQL 互換のエンジンをご利用可能に
これらの機能レベルのフィードバックに加えて、我々はその他のデータベースとの互換性を追加してほしいという多くのリクエストをいただいていました。そのフィードバックリストのトップに上がっていたのは PostgreSQL との互換性です。このオープンソースデータベースは、20 年間にわたり継続して、開発され、多くのエンタープライズ、スタートアップ企業に採用されています。お客様は、PostgreSQL に備わる豊富な機能(SQL Server や Oracle Database でも提供されているものと同様のもの)、性能面の利点、地理情報オブジェクトを好んでいます。お客様は、Aurora が提供するすべての利点を活用しながら、喜んでこれらの機能を利用するでしょう。
本日、Amazon Aurora の PostgreSQL-compatible edition を preview にてリリースします。この preview は、高い堅牢性、高可用性、リードレプリカをすぐに作成できる機能など先にあげたすべての利点を提供します。ここには、お気に召すであろういくつかの特徴をあげます:
Amazon Auroraを開発・テストワークロードでご利用しやすいT2.Medium DBインスタンスクラスをリリース
Amazon Auroraは既にdb.r3.large (2 vCPUs, 15 GiB RAM) から db.r3.8xlarge (32 vCPUs 244 GiB RAM)まで5つのインスタンスクラスをご提供していました。これらのインスタンスは非常に多くのプロダクション環境やアプリケーション向けのユースケースをサポートしています。
今日、 db.t2.medium DB インスタンスクラス (2 vCPUs, 4 GiB RAM)の6つ目の選択肢を追加致しました。通常時、このインスタンスクラスではシングルコアの40%のパフォーマンスを利用することが可能で、CPUを利用するクエリやデータベースタスクを実行する場合コアのフルパフォーマンスまでバーストをします。同名のEC2インスタンスの様に、この新しいインスタンスクラスはCPUクレジットを持っており、CPUが多く使われている場合は消費し、そうでない場合はCPUクレジットを蓄積します。(バースト可能な性能を持つ新しい低コストEC2インスタンスで詳細を説明しています)
db.t2.mediumは多くの開発・テスト環境に最適です。また、負荷の少ないプロダクションワークロードにも利用出来ます。CPUCreditUsageとCPUCreditBalance メトリクスを監視することでCPUクレジットの利用や蓄積を確認することが出来ます。
本日からご利用いただけます
新しいインスタンスクラスを使ったAmazon Auroraデータベースは本日から起動頂けます。Amazon Auroraが利用出来る全リージョンで利用可能です。1時間あたり$0.082(N.Virginiaリージョンの場合)からご利用頂けます。