Category: Amazon CloudWatch
新しい collectd の CloudWatch プラグイン
これまでご自分のビジネス、アプリケーション、システムメトリックスを Amazon CloudWatch で保存されてきたと思います (詳しくは「Amazon CloudWatch の新しいカスタムメトリックス」をご覧ください)。随分前のことになりますが、私が 2011 年に書いたブログで「ユーザーの AWS リソースを CloudWatch で保存しているように、グラフを表示したり、アラームを設定、自動化したアクションをこうしたメトリックスに基づいて設定することができます。」といったように、この機能についてご紹介したことがあります。
そして本日より、新しい CloudWatch プラグイン collectd 対象を使用することで、ユーザーのシステムから統計を収集する方法を簡略化しながら収集した情報を CloudWatch に保存できるようになりました。さまざまなタイプの統計を収集する collectd の機能と、保存、表示、アラート、警告を可能にする CloudWatch の機能を組み合わせることで、EC2 インスタンスの状態とパフォーマンス、そして EC2 で実行しているオンプレミスハードウェアやアプリケーションについてより細かく把握することができます。このプラグインはオープンソースプロジェクトとしてリリースしています。皆様からのプルリクエストをお待ちしております。
パフォーマンスと可搬性を提供するため collectd デーモンは C で記述されています。これは 100 以上のプラグインをサポートし、Apache や Nginx ウェブサーバーパフォーマンス、メモリ使用量、稼働時間の統計を収集できるようにします。
インストールと設定
実際のアクションを見るため、collectd と新しいプラグインを EC2 インスタンスにインストールして設定してみました。
まず、CloudWatch にメトリックスデータを書き込むためのアクセス許可を使用して IAM ポリシーを作成します。
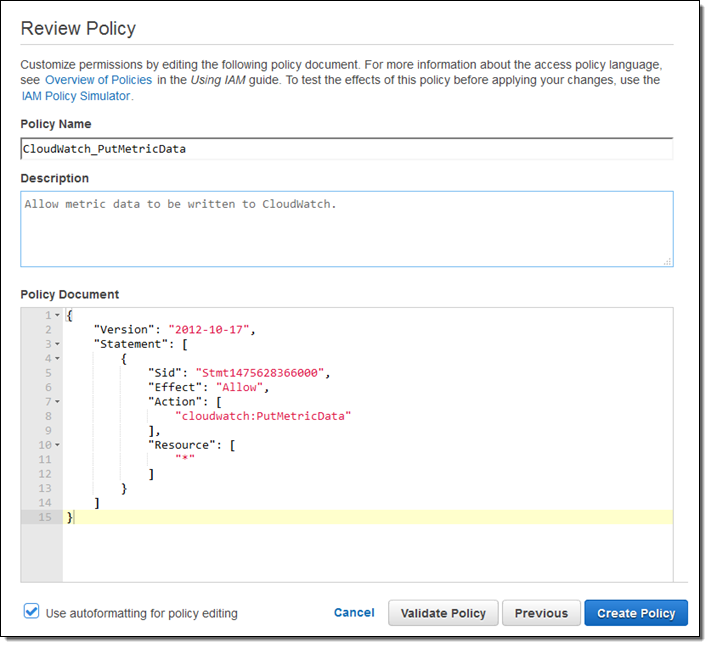
次にポリシーで EC2 を許可する IAM ロール (インスタンスで実行する collectd コード) を作成します。
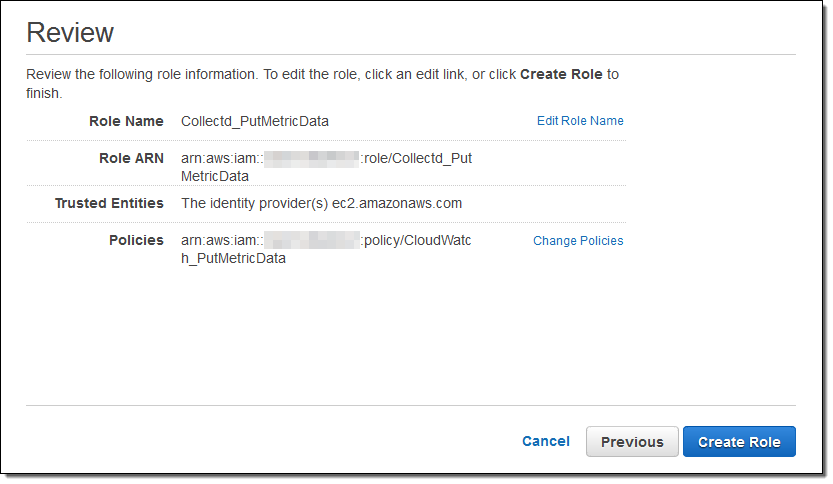
オンプレミスサーバーから統計を収集するためにプラグインを使用する予定の場合や、すでに EC2 インスタンスを実行している場合は、このステップを行わずに適切なアクセス権限を代わりに使用して IAM ユーザーを作成します。私の場合、最初の例ではなくこの方法を実行していたら、ユーザーの認証情報をサーバーまたはインスタンスに追加する必要がありました。
ポリシーとロールの準備ができたら、EC2 インスタンスを起動してロールを選択します。
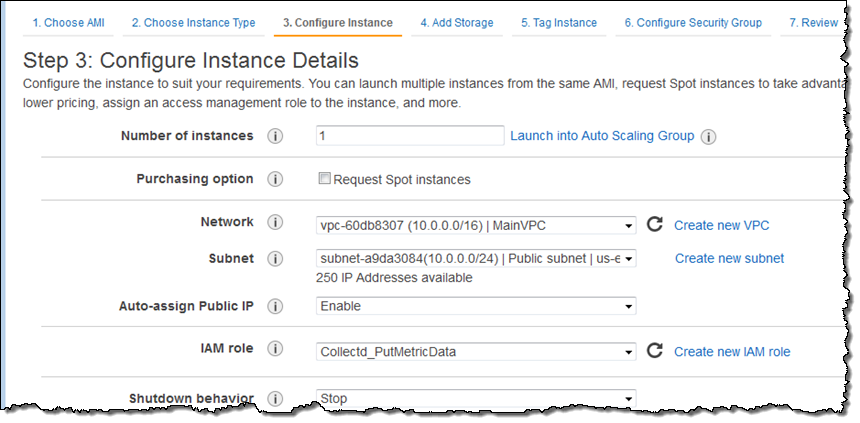
ログインを完了し collectd をインストールします。
$ sudo yum -y install collectd次にプラグインを取得しスクリプトをインストールします。スクリプトを実行可能にしたら、それを実行します。
$ chmod a+x setup.py
$ sudo ./setup.py
いくつかの質問に答えた後、問題なく設定を実行できました。collectd は設定完了後に起動しました。
Installing dependencies ... OK
Installing python dependencies ... OK
Copying plugin tar file ... OK
Extracting plugin ... OK
Moving to collectd plugins directory ... OK
Copying CloudWatch plugin include file ... OK
Choose AWS region for published metrics:
1. Automatic [us-east-1]
2. Custom
Enter choice [1]: 1
Choose hostname for published metrics:
1. EC2 instance id [i-057d2ed2260c3e251]
2. Custom
Enter choice [1]: 1
Choose authentication method:
1. IAM Role [Collectd_PutMetricData]
2. IAM User
Enter choice [1]: 1
Choose how to install CloudWatch plugin in collectd:
1. Do not modify existing collectd configuration
2. Add plugin to the existing configuration
Enter choice [2]: 2
Plugin configuration written successfully.
Stopping collectd process ... NOT OK
Starting collectd process ... OK
$
collectd を実行することができ、プラグインのインストールと設定が完了したら、次のステップは目的の統計を決定し、CloudWatch に発行するプラグインを設定することです (メトリックスごとに料金が発生するので、これは大切なステップです)。
ファイル /opt/collectd-plugins/cloudwatch/config/blocked_metrics には、収集したメトリックスのリストが含まれていますが、これは CloudWatch に発行されていません。
$ cat /opt/collectd-plugins/cloudwatch/config/blocked_metrics
# This file is automatically generated - do not modify this file.
# Use this file to find metrics to be added to the whitelist file instead.
cpu-0-cpu-user
cpu-0-cpu-nice
cpu-0-cpu-system
cpu-0-cpu-idle
cpu-0-cpu-wait
cpu-0-cpu-interrupt
cpu-0-cpu-softirq
cpu-0-cpu-steal
interface-lo-if_octets-
interface-lo-if_packets-
interface-lo-if_errors-
interface-eth0-if_octets-
interface-eth0-if_packets-
interface-eth0-if_errors-
memory--memory-used
load--load-
memory--memory-buffered
memory--memory-cached
メモリの消費量が気になっていたので、次のラインを追加しました。 /opt/collectd-plugins/cloudwatch/config/whitelist.conf:
memory--memory-.*collectd の設定ファイル (/etc/collectd.conf) には collectd とプラグインの設定も含まれています。私の場合、変更の必要はありませんでした。
変更を反映させるため、collectd を再起動させました。
$ sudo service collectd restart
多少のメモリを消費させるためにインスタンスを少し使用してから、CloudWatch コンソールを開きメトリックスを探し表示しました。
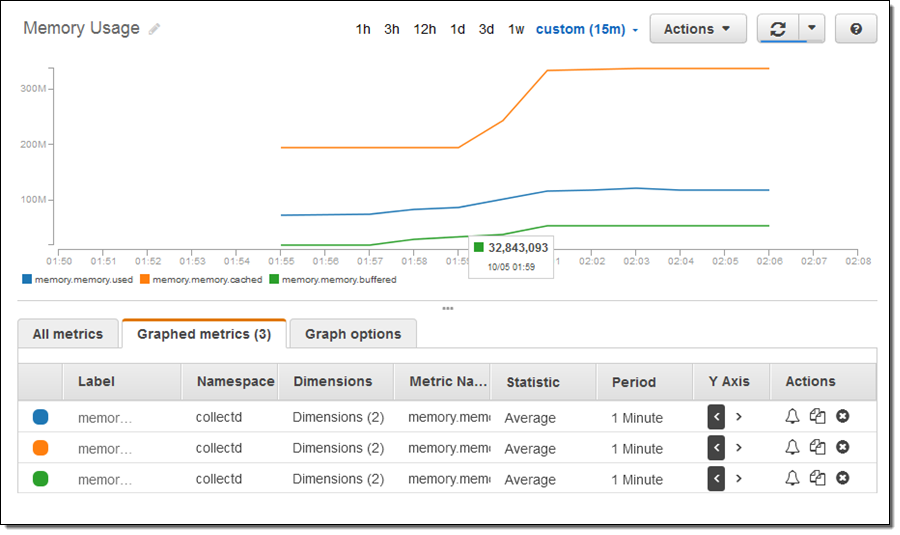
このスクリーンショットには、今後 CloudWatch コンソールに施される強化点のプレビューが含まれていますので、ご自分の画面に同じものが表示されなくてもご安心ください (詳しくは今後お知らせします)。
プロダクションインスタンスをモニタリングしていたのであれば、collected プラグインを 1 つ 2 つインストールすることもできました。Amazon Linux AMI で利用可能なリストは次をご覧ください。
$ sudo yum list | grep collectd
collectd.x86_64 5.4.1-1.11.amzn1 @amzn-main
collectd-amqp.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-apache.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-bind.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-curl.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-curl_xml.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-dbi.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-dns.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-email.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-generic-jmx.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-gmond.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-ipmi.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-iptables.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-ipvs.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-java.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-lvm.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-memcachec.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-mysql.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-netlink.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-nginx.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-notify_email.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-postgresql.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-rrdcached.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-rrdtool.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-snmp.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-varnish.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-web.x86_64 5.4.1-1.11.amzn1 amzn-main
主要事項
バージョン 5.5 以降の collectd を使用している場合は、4 つのメトリックスがデフォルトで発行されるようなりました。
- df-root-percent_bytes-used – ディスク速度
- memory–percent-used – メモリ使用量
- swap–percent-used – スワップ使用率
- cpu–percent-active – cpu 使用率
これらを発行したくない場合は whitelist.conf ファイルから削除することができます。
現在、Amazon Linux AMI、Ubuntu、RHEL、CentOS のプライマリリポジトリは古いバージョンの collectd を提供しています。カスタムリポジトリからインストールした場合またはソースから構築した場合はデフォルト設定による動作が異なる点にご注意ください。
その他
ご紹介できるものは他にもあるのですが、残念ながら時間切れです。その他のプラグインもインストールし whitelist.conf を設定してさらに多くのメトリックスを CloudWatch に発行することができます。CloudWatch アラームを作成してカスタムダッシュボードやその他を設定することもできます。
始めるには GitHub の AWS ラボにアクセスし collectd の CloudWatch プラグインをダウンロードしてください。
— Jeff;
CloudWatch Logs とダッシュボードを改善
Amazon CloudWatch では AWS インフラストラクチャで発生する問題の確認、診断、対応、解決を AWS で実行しているアプリケーション内で行うことができます。今回は CloudWatch Logs (Store and Monitor OS & Application Log Files with Amazon CloudWatch) そして CloudWatch ダッシュボード (CloudWatch Dashboards – Create & Use Customized Metrics Views) に追加された複数のユーザビリティと機能の改善点についてご説明します。
CloudWatch Logs のユーザビリティを改善
CloudWatch Logs はオペレーティングシステムやアプリケーションログファイルを管理する、可用性と拡張性そして耐久性が高く安全なサービスです。ログのデータ取り込み、保管、フィルター、検索、アーカイブを可能にするため、操作の負荷を軽減しアプリケーションとビジネスに集中できるようにします。ログの件数やサイズが増えても効率性と生産性を維持できるようにするため、AWS では CloudWatch Logs コンソールにユーザビリティの改善点をいくつか加えました。
- ログデータのフォーマット処理を改善
- 長いログファイルへのアクセスを簡略化
- ロググループ内の検索が簡単に
- ログファイルの共同作業を簡易化
- 特定の期間内の検索を改善
今回のリリース前に CloudWatch ダッシュボードにも改善点を加えました。
- フルスクリーンモード
- ダークテーマ
- グラフ内にある Y 軸の範囲を指定
- グラフ名の変更を簡易化
- グラフ設定の永続的なストレージ
CloudWatch Logs コンソールの動作
では、次にそれぞれの改善点について詳しくご説明します。CloudWatch Logs コンソールを開き、ロググループをクリックしてからグループ内のログストリームにアクセスします。右側のオプションを表示メニューを見つけます。
次のように、複数行で拡大した状態でログメッセージを表示するにはすべて開くをクリックします。
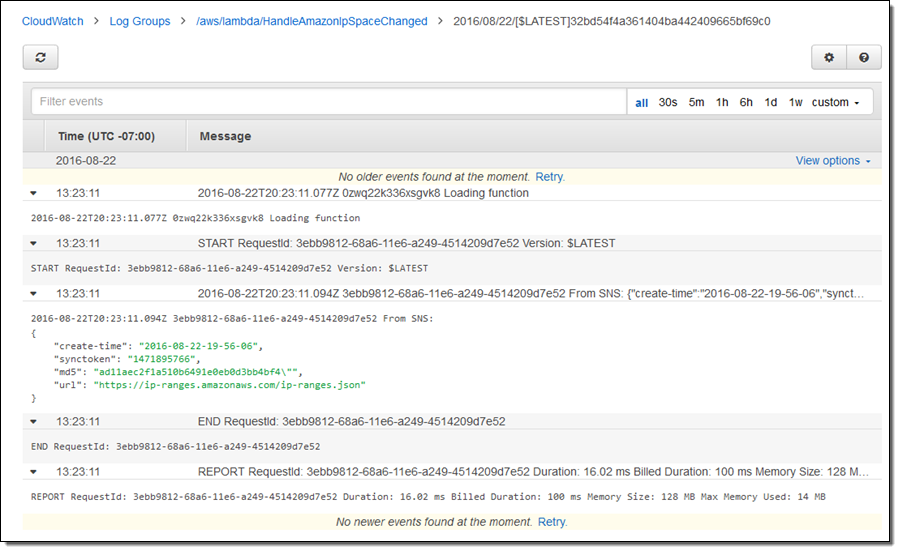
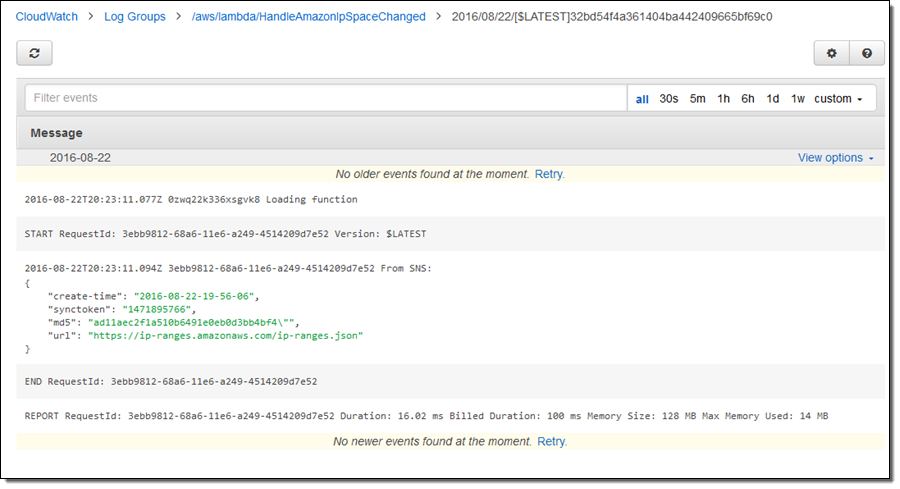
飾りのないプレーンテキストでログを表示したい場合は、テキスト表示を切り替えることもできます。
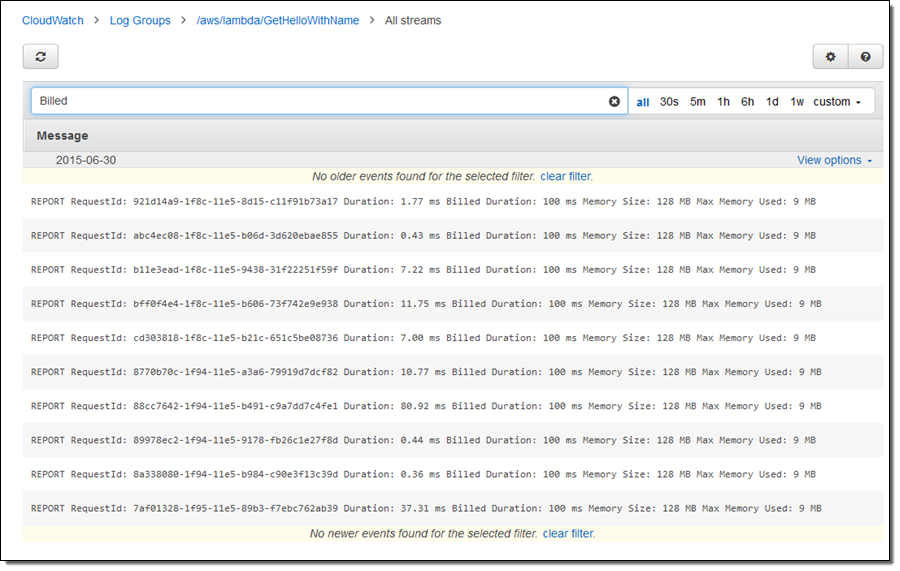
この他にもロググループ内のストリームすべてに渡り、ログデータの表示を改善しました。ロググループを選びイベントを検索をクリックすると、そのロググループ内のストリームすべてからのログデータを見ることができます。例えば、1 つの Lambda 関数における複数の呼び出しに対する課金対象期間を見つけやすくなりました。
さらに、従来の割り付け表示に代わり、制限のないスクロールバーが導入されました。これでお好きなだけログファイルをスクロールできるようになりました。
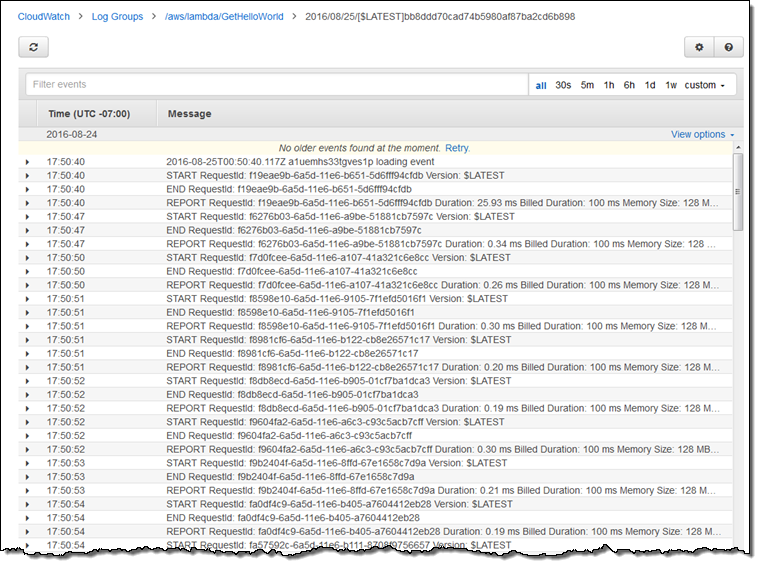
次のように、特定の期間を指定したり、ワンクリックで日付を指定するなどして検索条件を絞り込むことが可能になりました。
チームの一員として作業をしている場合は、ご自分のログ分析セッションの URL を共有できるようになりました。
URL には検索パラメータとフィルターが含まれ、次のようなフラグメントもその一部になっています。
group=<log_group_name>_log;stream=<log_stream_name>;filter=<filter_parameter>;start=PT<time_frame>
この CloudWatch Logs コンソールの改善点は、今すぐご利用いただけます。詳しくは Getting Started with CloudWatch Logs をご覧ください。
CloudWatch ダッシュボードに追加した改善点
CloudWatch ダッシュボードに最近追加された改善点については、すでにお気づきの方もいらっしゃるかもしれません。まず、ダッシュボードに新しいフルスクリーンモードを追加しました。Actions メニューで全画面表示に切り替えるをクリックします。
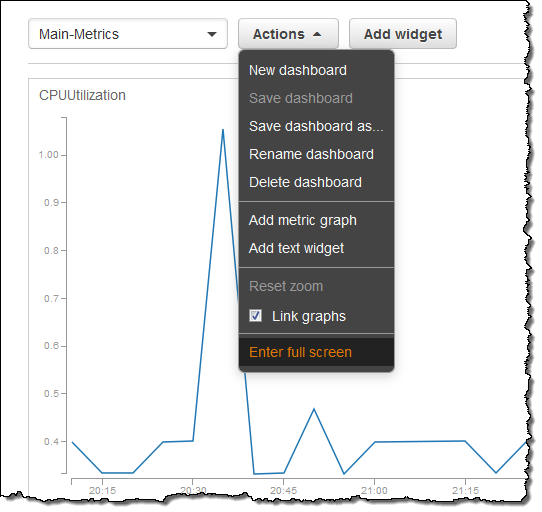
フルスクリーンモード状態になったら、ダークをクリックして夜用の新しいダークテーマに切り替えることができます。
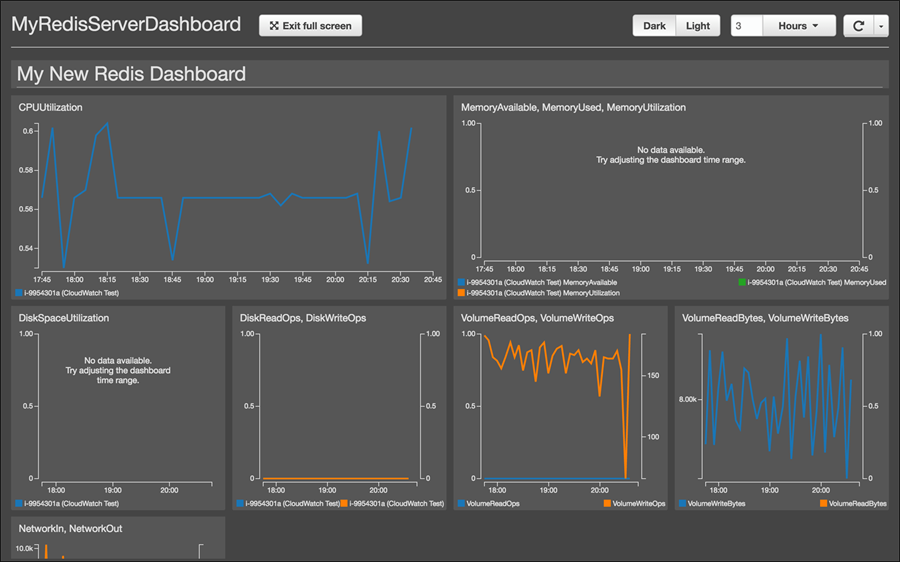
フルスクリーンモードでダークテーマを使用した Redis ダッシュボードの例がこちらです。
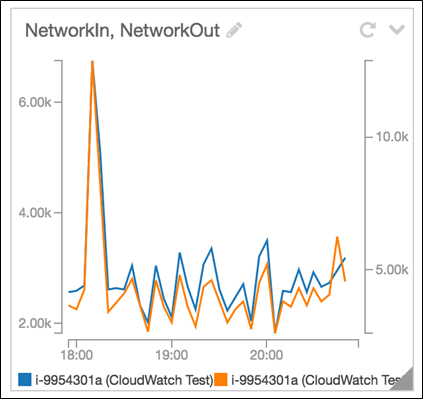
場合によってはダッシュボードにグラフをどのように表示するか、より細かに管理したいと思うこともあるのではないでしょうか。例えば、データの異常値がグラフを読みにくくしていて、ダッシュボードで Y 軸の特定範囲に集中したい場合などが考えられます。次の例はその場合のグラフです。異常値が急増した後に起きる傾向をマスクしています。
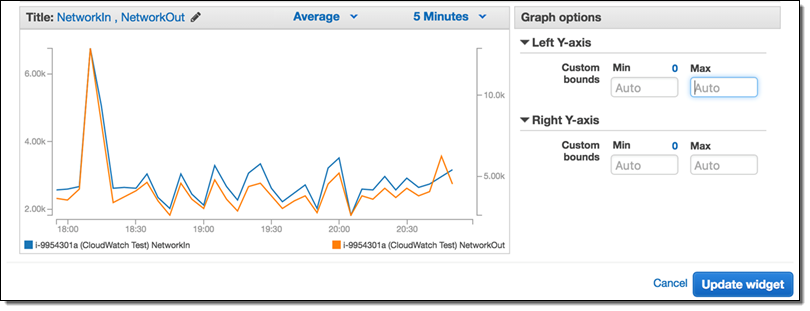
Y 軸を編集するには、ツールセレクターをクリックして Edit をクリックします。

Graph Options を選択し、お好きな具合にグラフが表示されるまで Y 軸の値を編集します。その後、ウィジェットの更新をクリックしてください。
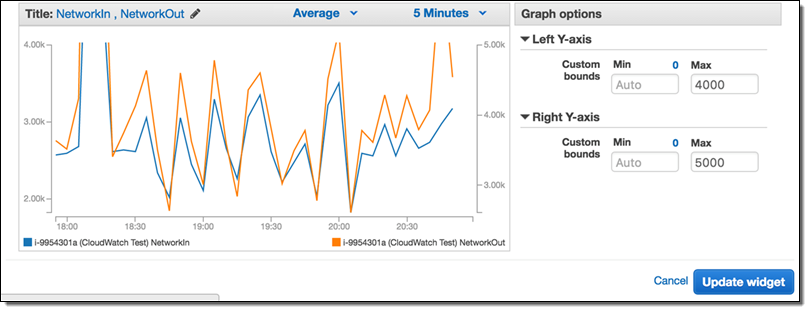
編集後のグラフは次のようになります。
AWS の多くのお客様はダッシュボード内でグラフ名の変更ができるようにしたいとリクエストしていました。そして今回より、ワンクリックでその操作が可能になりました (グラフ名の近くにマウスを移動させ、鉛筆のアイコンをクリックするだけです)。
今後は CloudWatch が時間範囲、タイムゾーン設定、更新間隔、自動更新の設定を各グラフごとに記憶できるようになりました。
Amazon CloudWatch パートナーエコシステム
では最後に AWS パートナーによる優れたソリューションについてご紹介します。次のパートナーは CloudWatch に加え、付加価値のあるソリューションも構築しています。
- DataDog はインフラストラクチャ内の主要項目との統合を提供し、問題対応の際に直接チームと協力することを可能にしています。
- Librato はインフラストラクチャの要素に渡り統合を提供し、複合メトリックスや算術演算の時列系データへの変換をサポートしています。
- SignalFx はメトリックスへの瞬時な可視性の提供、データ分析に集中そしてサービス規模で通知を送信しています。
- Splunk はマシンデータの収集やインサイト検知を可能にするオペレーショナルインテリジェンスのプラットフォームを提供しています。
- Sumo Logic はログ管理や時系列メトリックスのマシンデータ分析サービスで、アプリケーションの構築、実行、安全性の確保に役立っています。
ご自分が AWS パートナーでこちらのリストに属すものを提供していらっしゃる場合は、すぐに更新しますのでお知らせください。
— Jeff;
Amazon ECSでAuto Scaling
Amazon EC2 Container Service (Amazon ECS)のClusterを自動的にスケールさせる方法はありましたが、本日Auto ScalingとAmazon CloudWatchのAlarmに追加された新機能により、ECSのServiceにScaling Policyを利用することができます。ServiceのAuto Scalingにより、需要が高まった時にスケールアウトさせて高い可用性を実現したり、需要が下がったらServiceとClusterをスケールインさせることでコストを最適化するのを、全て自動でリアルタイムに行うことができます。
この記事では、Clusterを需要に合わせて自動的にリサイズさせつつ、この新しい機能がどうやって利用できるかをお見せします。
Service Auto Scalingの概要
すぐに利用できるECS Serviceのスケーリング機能はずっと一番要望を受けていて、ついに今日この機能をアナウンスでき嬉しいです。自動でスケールするServiceの作成手順はとても簡単で、ECSコンソールやCLI、SDKでもサポートされています。希望するTaskの数とその最小・最大数を選択し、1つ以上のScaling Policyを作成すると、後はService Auto Scalingが面倒を見てくれます。Service SchedulerはAvailability Zoneを意識してくれるので、ECSのTaskを複数のZoneに渡って分散するように心配する必要もありません。
それに加えて、ECS Taskを複数AZ Cluster上で実行することも非常に簡単です。ECS ClusterのAuto Scaling Groupが、複数Zoneに渡る可用性を管理してくれるので、必要とされる回復力や信頼性を持つことができ、ECSがTaskのZone間の分散を管理してくれるので、皆さんはビジネスロジックに集中することができます。
利点:
- 来ているアプリケーションの負荷にキャパシティを対応させる: ECS ServiceとECS ClusterのAuto Scaling Groupを両方にScaling Policyを使います。必要に応じて、Cluster InstanceとService Taskをスケールアウトさせ、需要が落ち着いたら安全にスケールインさせることで、キャパシティの推測ゲームから抜け出せます。これによって、ロングランな環境で低コストな高可用性を実現できます。
- 複数AZのClusterでECSの基盤に高い可用性を持たせる: Zone障害という可能性から守ることができます。Availability Zoneを考慮しているECS SchedulerはCluster上のTaskを管理し、スケールし、分散してくれるので、アーキテクチャは高い可用性を持ちます。
Service Auto Scalingのデモ
この記事では、これらの機能を使い真にスケーラブルで高い可用性を持ったMicroservicesアーキテクチャを作成する手順を辿りたいと思います。このゴールに到達するために、以下の様な手順をお見せします:
- Auto Scaling Groupで2つ以上のZoneにECS Clusterを作成する。
- そのCluster上にECS Serviceを設定し、希望するTaskの数を定義する。
- ECS Serviceの前段にElastic Load Balancingのロードバランサを設定する。これが負荷の入り口になります。
- ECS Service用のスケールインとスケールアウトのCloudWatch Alarmを設定する。
- ECS Cluster用のスケールインとスケールアウトのCloudWatch Alarmを設定する 。(注: 前のステップで作成したものとは別のAlarmになります)
- ECS Service用のScaling Policyを作成し、スケールアウトとスケールインする時のScaling Actionを定義する。
- ECS Clusterが動いているAuto Scaling Group用のScaling Policyを作成する。これらのPolicyはECS Clusterのスケールイン・アウトで利用されます。
- 負荷を徐々に増やしたり減らしたりすることで、スケーラブルなECS ServiceとClusterの高可用性をテストする。
この記事では、Cluster上に1つのECS Serviceを設定する手順をお見せしますが、このパターンは同じCluster上で複数のECS Serviceを実行する時にも適応できます。
注意: この例を実行した結果、発生した如何なるAWSのコストも支払う必要があります。
概念図

ECS ServiceのAuto Scalingを設定する
Auto Scalingを設定する前に、複数AZ (2 Zone)のCluster上で実行されていて、ロードバランサを前段に持つECS Serviceを作っておく必要があります。
- ECS ClusterとServiceをロードバランサも一緒に構築します。このデモではClusterの名前は”anyscale”とします。
CloudWatch Alarmを設定する
- Amazon CloudWatchのコンソール上で、ECS Serviceのスケールインとスケールアウト時に使われるCloudWatch Alarmを設定します。このデモではCPUUtilization (ECS, ClusterName, ServiceNameのカテゴリから選びます)を使いますが、他のMetricsを使うこともできます。(注: 他のやり方として、Service用のScaling Policyを設定する時にはECSのコンソール上でこれらのAlarmを設定することもできます。)

- AlarmにECSServiceScaleOutAlarmという名前をつけ、CPUUtilizationの閾値を75に設定します。
- Actionの所でNotificationを削除します。このデモではECSとAuto Scalingのコンソールを使ってActionを設定します。
- 上記の2ステップを繰り返してスケールインのAlarmを作成し、CPUUtilizationの閾値を25にして、演算子を”<=”に設定します。
- Alarmsの所で、スケールインのAlarmがALARM状態にあるはずです。今のところECS Serviceに負荷がかかっていないので、これは期待した状態です。

- ECS Cluster用のCloudWatch Alarmを設定するために、前のステップと同じことをします。今度は、CPUReservation (ECS, ClusterNameから選びます)をMetricとして利用します。前のステップの様に2つのAlarmを作成し、1つがECS Clusterのスケールアウト用、他方がスケールイン用とします。それらにECSClusterScaleOutAlarmとECSClusterScaleInAlarm という名前(または自由な名前)を設定します。
注: これはCluster固有のMetricですが(Cluster-Service固有のMetricと対照的)、このパターンでも有効的ですし、複数ECS Serviceのシナリオでも有効です。ECS Clusterはどれが起因であってもClusterの負荷に応じて常にスケールします。
ECS ServiceのスケールはECS Clusterのスケールに比べてとても速いので、ECS ClusterのスケーリングのAlarmをECS ServiceのAlarmよりも敏感にしておくことをお勧めします。こうすることで、スケーリングの間Clusterに余分なキャパシティが常にあることを保証でき、一瞬の負荷のピークに対応することができます。もちろん気をつけるべきは、この余分なEC2のキャパシティでコストは増えるので、Clusterのキャパシティを確保するのとコストの間で良いバランスを見つける必要がありますが、それはアプリケーション毎に異なるでしょう。
ECS ServiceにScaling Policyを追加する
Add a scale out and a scale in policy on the ECS service created earlier.
先ほど作成したECS ServiceにスケールアウトとスケールインのPolicyを追加します。
- ECSコンソールにサインインし、Serviceが動いているClusterを選択、Servicesを開いてServiceを選択します
- Serviceのページでは、Updateを選択します。
- Taskの数が2になっていることを確認します。これはそのServiceが実行する時のデフォルトのTask数です。
- Update ServiceのページのOptional configurationsの下にある、Configure Service Auto Scalingを選択します。

- Service Auto Scaling (optional)のページのScalingの下にある、Configure Service Auto Scaling to adjust your service’s desired countを選択します。Minimum number of tasksとDesired number of tasksの両方に2と入力します。Maximum number of tasksには10を入力します。ECS Serviceの作成時にホスト(EC2インスタンス)上の80番ポートをECS Containerの80番ポートにマッピングしているので、Auto Scaling GroupとECS Taskが両方共同じ数値になっていることを確認しておいて下さい。
- Automatic task scaling policiesセクションの下の、Add Scaling Policyを選択します。
- Add Policyのページでは、Policy Nameに値を入力します。Execute policy whenには、前に作成したCloudWatch Alarm (ECSServiceScaleOutAlarm)を入力します。ActionではAdd 100 percentを設定し、Saveを選択します。
- 上の2つのステップの繰り返しで、前に作成したスケールインのCloudWatch Alarm (ECSServiceScaleInAlarm)を使ってスケールインのPolicyを作成します。ActionではRemove 50 percentを設定し、Saveを選択します。
- Service Auto Scaling (optional)ページで、Saveを選択します。
ECS ClusterにScaling Policyを追加する
ECS Cluster (Auto Scaling Group)にスケールアウトとスケールインのPolicyを追加します。
- Auto Scalingのコンソールにサインインしてこのデモ用に作成したAuto Scaling Groupを選択します。
- DetailsからEditを選択します。
- DesiredとMinが2に、Maxが10に設定されていることを確認して、Saveを選択します。
- Scaling PoliciesからAdd Policyを選択します。
- まず、スケールアウトのPolicyを作成します。Nameに値を入力し、Execute policy whenは前に作成したスケールアウトのAlarm (ECSClusterScaleOutAlarm)を選択します。ActionではAdd 100 percent of groupを設定し、Createを選択します。

- 上のステップを繰り返して、スケールインのPolicyをスケールインのAlarm (ECSClusterScaleInAlarm)を使って、ActionにはRemove 50 percent of groupを設定します。
Auto Scaling Group用のスケールインとスケールアウトのPolicyを見ることができるはずです。これらのPolicyを使って、Auto Scaling GroupはECS Serviceが動いているClusterのサイズを大きくしたり小さくしたりできます。
注: ClusterのScaling Policyをこの様に設定することで、Clusterに幾つかの余分なキャパシティを確保することになります。これによってECS Serviceのスケールアウトはより高速になりますが、同時に、需要に依ってはいくつかのEC2インスタンスが利用されない状態になることがあります。
以上でECS ServiceとAuto Scaling Groupに対して、今回はそれぞれ異なるCloudWatch Alarmによって発動するようにAuto Scalingの設定が完了しました。異なるCloudWatch Alarmsの異なる組み合わせを使ってそれぞれのPolicyをもっと凝ったScaling Policyとすることもできます。
これでスケールアウトできるキャパシティを持ったCluster上で動作するServiceができあがったので、Alarmが発動するようにロードバランサにトラフィックを流してみましょう。
ECS Serviceスケーリングの負荷試験
それでは、Apache abツールを使いECS Serviceに負荷試験をして、スケーリングの設定が動作するかを確認してみます(負荷試験インスタンスの作成の章をご覧ください)。CloudWatchのコンソールで、Serviceがスケールアウト・インする様子が見られます。Auto Scaling Groupが2つのAvailability Zoneを使う用に設定されているので、各Zoneに5つのEC2インスタンスを見ることができるはずです。また、ECS Service SchedulerもAvailability Zoneを意識するので、Taskも2つのZoneに渡って分散しているでしょう。
EC2コンソールから、手動でEC2インスタンスを終了させることで高可用性の試験もできます。Auto Scaling GroupとECS Service Schedulerが、追加のEC2インスタンスを起動しTaskも起動してくれるはずです。
追加で考慮すべきこと
- キャパシティの確保: 既に書いた様に、ECS Clusterに余分なキャパシティを確保しておくことで、Clusterが新しいインスタンスを準備するのを待たなくて良いので、ECS Serviceのスケールアウトがとても高速になります。こちらはCloudWatch Alarmが発動する値を変更するか、Scaling Policyの値を変更することで簡単に実現できます。
- インスタンスの終了保護: いくつかのスケールインのケースでは、利用できるECS Clusterのキャパシティが減少することで、強制的にTaskが終了したり他のホストに移動してしまいます。こちらはECS ClusterのスケールインのPolicyを需要に対して敏感に反応しないように調整するか、EC2のホストが終了する前にうまくTaskが終了できるようにすることで軽減できます。そのためには、別の記事で解説されているAuto Scaling Lyfecycle Eventやインスタンスの終了保護をご覧頂くと良いと思います。
今回のデモではAWSコーンソールを使いましたが、もちろん同じことをAWS SDKやCLIを使って実現することも可能です。
まとめ
ミッションクリティカルなMicroservicesアーキテクチャを動かす時には、トータルでかかるコストを下げることは非常に重要ですし、加えて負荷を複数のZoneに分散できることや、ECS ServiceとClusterのキャパシティを負荷の変化に合わせて調整できることが必要になります。この記事でご紹介した手順では、2軸でのスケーリングを活用することでこれを実現することができます。
補足
2016年7月21日に全てのリージョンで利用可能となりました。 https://aws.amazon.com/about-aws/whats-new/2016/07/amazon-ec2-container-service-automatic-service-scaling-region-expansion/
原文: https://aws.amazon.com/blogs/compute/automatic-scaling-with-amazon-ecs/ (翻訳: SA岩永)
Amazon Kinesis アップデート – Amazon Elasticsearch Service との統合、シャード単位のメトリクス、時刻ベースのイテレーター
Amazon Kinesis はストリーミングデータをクラウド上で簡単に扱えるようにします。
Amazon Kinesis プラットフォームは3つのサービスから構成されています:Kinesis Streams によって、開発者は独自のストリーム処理アプリケーションを実装することができます;Kinesis Firehose によって、ストリーミングデータを保存・分析するための AWS へのロード処理がシンプルになります;Kinesis Analytics によって、ストリーミングデータを標準的な SQL で分析できます。
多くの AWS のお客様が、ストリーミングデータをリアルタイムに収集・処理するためのシステムの一部として Kinesis Streams と Kinesis Firehose を利用しています。お客様はこれらが完全なマネージドサービスであるがゆえの使い勝手の良さを高く評価しており、ストリーミングデータのためのインフラストラクチャーを独自に管理するかわりにアプリケーションを開発するための時間へと投資をしています。
本日、私たちは Amazon Kinesis Streams と Amazon Kinesis Firehose に関する3つの新機能を発表します。
- Elasticsearch との統合 – Amazon Kinesis Firehose は Amazon Elasticsearch Service へストリーミングデータを配信できるようになりました。
- 強化されたメトリクス – Amazon Kinesis はシャード単位のメトリクスを CloudWatch へ毎分送信できるようになりました。
- 柔軟性 – Amazon Kinesis から時間ベースのイテレーターを利用してレコードを受信できるようになりました。
Amazon Elasticsearch Service との統合
Elasticsearch はポピュラーなオープンソースの検索・分析エンジンです。Amazon Elasticsearch Service は AWS クラウド上で Elasticsearch を簡単にデプロイ・実行・スケールさせるためのマネージドサービスです。皆さんは、Kinesis Firehose のデータストリームを Amazon Elasticsearch Service のクラスターへ配信することができるようになりました。この新機能によって、サーバーのログやクリックストリーム、ソーシャルメディアのトラフィック等にインデックスを作成し、分析することが可能になります。
受信したレコード(Elasticsearch ドキュメント)は指定した設定に従って Kinesis Firehose 内でバッファリングされたのち、複数のドキュメントに同時にインデックスを作成するバルクリクエストを使用して自動的にクラスターへと追加されます。なお、データは Firehose へ送信する前に UTF-8 でエンコーディングされた単一の JSON オブジェクトにしておかなければなりません(どのようにこれを行うかを知りたい方は、私の最近のブログ投稿 Amazon Kinesis Agent Update – New Data Preprocessing Feature を参照して下さい)。
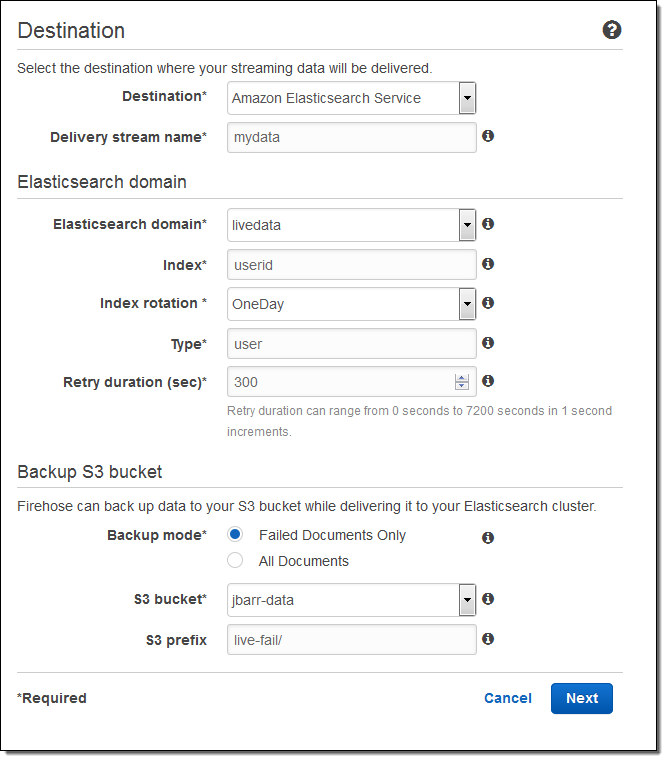
こちらが、AWS マネージメントコンソールを使用したセットアップの方法です。出力先(Amazon Elasticsearch Service)を選択し、配信ストリームの名を入力します。次に、Elasticsearch のドメイン(この例では livedata)を選択、インデックスを指定し、インデックスのローテーション(なし、毎時、日次、週次、月次)を選択します。また、全てのドキュメントもしくは失敗したドキュメントのバックアップを受け取る S3 バケットも指定します:
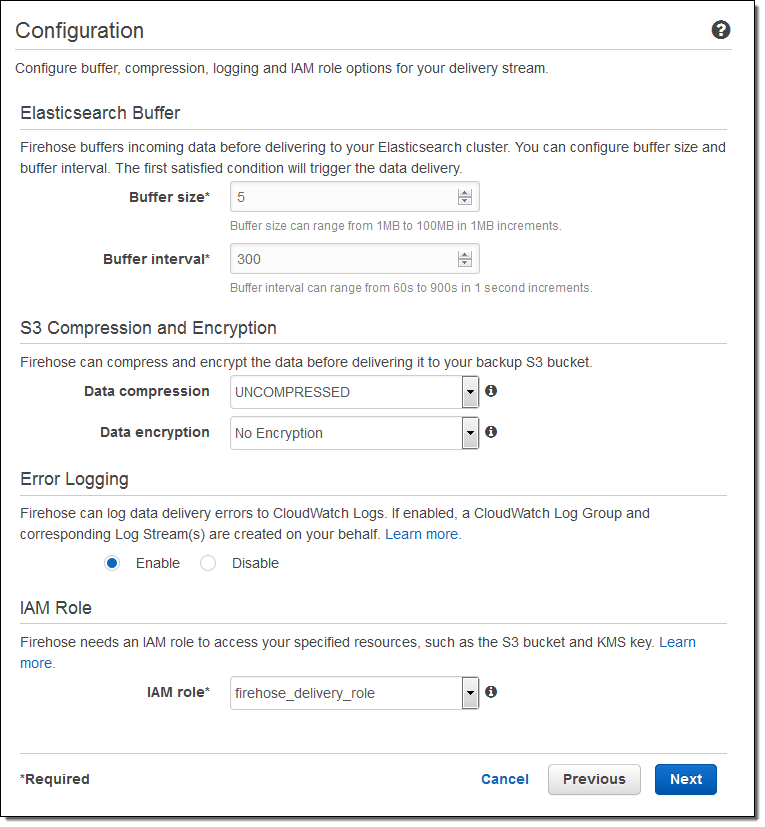
そして、バッファーのサイズを指定し、S3 バケットに送信されるデータの圧縮と暗号化のオプションを選択します。必要に応じてログ出力を有効にし、IAM ロールを選択します:
一分程度でストリームの準備が整います:
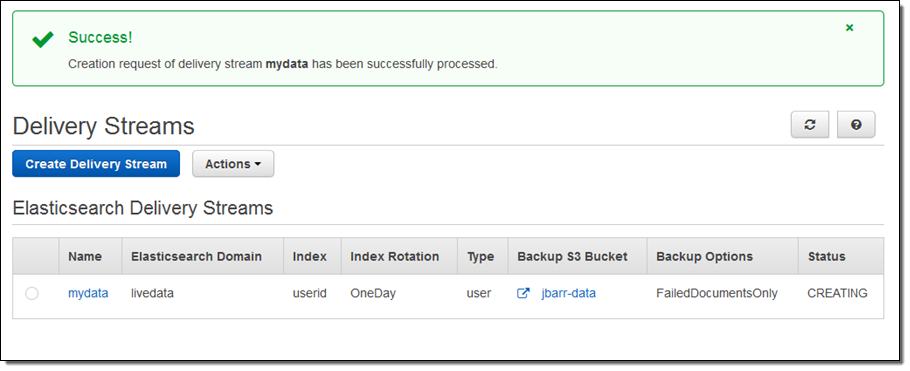
コンソールで配信のメトリクスを見ることもできます:
データが Elasticsearch へ到達した後は、Kibana や Elasticsearch のクエリー言語による視覚的な検索ができます。
総括すると、この統合によって、皆さんのストリーミングデータを収集し、Elasticsearch に配信するための処理は実にシンプルになります。もはや、コードを書いたり、独自のデータ収集ツールを作成したりする必要はありません。
シャード単位のメトリクス
全ての Kinesis ストリームは、一つ以上のシャードによって構成されており、全てのシャードは一定量の読み取り・書き込みのキャパシティを持っています。ストリームにシャードを追加することで、ストリームのキャパシティは増加します。
皆さんは、それぞれのシャードのパフォーマンスを把握する目的で、シャード単位のメトリクスを有効にすることができるようになりました。シャードあたり6つのメトリクスがあります。それぞれのメトリクスは一分間に一回レポートされ、通常のメトリクス単位の CloudWatch 料金で課金されます。この新機能によって、ある特定のシャードに負荷が偏っていないかを他のシャードと比較して確認したり、ストリーミングデータの配信パイプライン全体で非効率な部分を発見・一掃したりすることが可能になります。例えば、処理量に対して受信頻度が高すぎるシャードを特定したり、アプリケーションから予想よりも低いスループットでデータが読まれているシャードを特定したりできます。
こちらが、新しいメトリクスです:
IncomingBytes – シャードへの PUT が成功したバイト数。
IncomingRecords – シャードへの PUT が成功したレコード数。
IteratorAgeMilliseconds – シャードに対する GetRecords 呼び出しが戻した最後のレコードの滞留時間(ミリ秒)。値が0の場合、読み取られたレコードが完全にストリームに追いついていることを意味します。
OutgoingBytes – シャードから受信したバイト数。
OutgoingRecords – シャードから受信したレコード数。
ReadProvisionedThroughputExceeded – 秒間5回もしくは2MBの上限を超えてスロットリングされた GetRecords 呼び出しの数。
WriteProvisionedThroughputExceeded – 秒間1000レコードもしくは1MBの上限を超えてスロットリングされたレコードの数。
EnableEnhancedMetrics を呼び出すことでこれらのメトリクスを有効にすることができます。いつもどおり、任意の期間で集計を行うために CloudWatch の API を利用することもできます。
時刻ベースのイテレーター
任意のシャードに対して GetShardIterator を呼び出し、開始点を指定してイテレーターを作成することで、アプリケーションは Kinesis ストリームからデータを読み取ることができます。皆さんは、既存の開始点の選択肢(あるシーケンス番号、あるシーケンス番号の後、最も古いレコード、最も新しいレコード)に加え、タイムスタンプを指定できるようになりました。指定した値(UNIX 時間形式)は読み取って処理しようとする最も古いレコードのタイムスタンプを表します。
— Jeff;
翻訳は SA 内海(@eiichirouchiumi)が担当しました。原文はこちらです。
CloudWatch Metrics for Spot Fleets
スポットフリートは、ほんの数クリックでご利用頂けます。利用を始めるとフリートのサイズに関係なく(1台のインスタンスから何千台のインスタンスまで)費用対効果の高いキャパシティを複数プールからリソース提供します。この強力なEC2機能の詳細については、こちらのブログを参照下さい。【AWS発表】Amazon EC2 スポットフリート API – 一度のリクエストで数千台のスポットインスタンスを制御、【AWS発表】Spotフリート – コンソール、フリートスケーリング、CoudFormationに対応。
私は各スポットフリートを一つの集合体として考えます。フリートが起動すると、それぞれが独立したグループのEC2インスタンスとして起動します。スポット価格の変化や、フリートキャパシティの変更に伴いインスタンスの状態は変化しますが(可能な限り費用対効果を高めるよう変化)、フリート自体はその属性を保持します。
新しいスポットフリート メトリックス
スポットフリートの管理、監視、拡張性をより簡単にするために、CloudWatchに新しいスポットフリート用メトリックが追加されました。メトリックスは、複数のディメンションからアクセスできます:スポットフリート毎、スポットフリートが構成されているアベイラビリティゾーン毎、フリート内のEC2インスタンスタイプ、アベイラビリティゾーン、インスタンスタイプ等。
下記メトリックスは各スポットフリート毎に取得されます。(これらメトリックスを取得するためには、EC2詳細モニタリングを有効にする必要があります)
- AvailableInstancePoolsCount
- BidsSubmittedForCapacity
- CPUUtilization
- DiskReadBytes
- DiskReadOps
- DiskWriteBytes
- DiskWriteOps
- EligibleInstancePoolCount
- FulfilledCapacity
- MaxPercentCapacityAllocation
- NetworkIn
- NetworkOut
- PendingCapacity
- StatusCheckFailed
- StatusCheckFailed_Instance
- StatusCheckFailed_System
- TargetCapacity
- TerminatingCapacity
メトリックのいくつかは、スポットフリートの入札プロセスのヒントとなるかもしれません。例えば、
- AvailableInstancePoolsCount – スポットフリートのリクエストに含まれるインスタンス・プールの数を示します。
- BidsSubmittedForCapacity – スポットフリート キャパシティの入札数を示します。
- EligibleInstancePoolsCount – スポットインスタンスリクエストの対象となるインスタンスプールの数を示します。いずれか(1)スポット価格がオンデマンド価格より高い場合、または(2)入札価格がスポット価格よりも低い場合にはプールが不適用となります。
- FulfilledCapacity – フリートキャパシティを満たす容量の合計を示します。
- PercentCapacityAllocation – 特定ディメンションに割り当てられた容量の割合を示します。特定のインスタンスタイプに割り当てられた容量のパーセントを決定するために、インスタンスタイプと共に使用することができます。
- PendingCapacity – ターゲットキャパシティと利用済みキャパシティの差異を示します。
- TargetCapacity – スポットフリート内の現在要求されたターゲットキャパシティを示します。
- TerminatingCapacity – スポットインスタンスの終了通知を受けたインスタンスのインスタンスキャパシティを示します。
これらのメトリックスは、スポットフリートの全体的なステータスとパフォーマンスを決定する手助けになります。メトリック名からも分かりますが、スポットフリート毎に消費されるディスク、CPU、およびネットワークリソースを確認することができます。また、スポットキャパシティ確保のために入札の前にどのような傾向があるかを確認することができます。それに加え、アベイラビリティゾーン、インスタンスタイプをまたいだ下記メトリックスも取得できます。
- CPUUtilization
- DiskReadBytes
- DiskReadOps
- DiskWriteBytes
- FulfilledCapacity
- NetworkIn
- NetworkOut
- StatusCheckFailed
- StatusCheckFailed_Instance
- StatusCheckFailed_System
これらのメトリックスを利用することでアベイラビリティゾーン、インスタンスタイプをまたいだの負荷の許容可能な分布確認をすることができます。
フリート全体の使用率を把握するためにMax、Min、またはAvgを使用しメトリックを集計することができます。一方で、2種類以上のインスタンスからなるフリートでは、Avgを使用すること自体意味がないことにもご注意ください!
利用可能
この機能はすでにご利用頂けます。
— Jeff (翻訳は酒徳が担当しました。本文はこちら:https://aws.amazon.com/jp/blogs/aws/new-cloudwatch-metrics-for-spot-fleets/)