Category: AWS Lambda
DynamoDB Update – Triggers (Streams + Lambda) + Cross-Region Replication App
I’ve got some really good news for Amazon DynamoDB users! First, the DynamoDB Streams feature is now available and you can start using it today. As you will see from this blog post, it is now very easy to use AWS Lambda to process the change records from a stream. Second, we are making it really easy for you to replicate content from one DynamoDB table to another, either across regions or within a region.
Let’s dig in!
DynamoDB Streams
We launched a sneak preview of DynamoDB Streams last fall, just a couple of days before AWS re:Invent. As I wrote at the time, we built this feature because many AWS customers expressed a desire to be able to track the changes made to their DynamoDB tables.

“Interactive Intelligence is excited to be an early adopter of the new Amazon DynamoDB Cross Region Replicas feature. Incorporating this feature into the PureCloud platform has enabled us to quickly and easily replicate data across AWS regions, thus reducing our operational and support costs.”
Mike Szilagyi, Vice President of PureCloud Service Technology
DynamoDB Streams are now ready for production use. Once you enable it for a table, all changes (puts, updates, and deletes) are tracked on a rolling 24-hour basis and made available in near real-time as a stream record. Multiple stream records are grouped in to shards and returned as a unit for faster and more efficient processing.
The relative ordering of a sequence of changes made to a single primary key will be preserved within a shard. Further, a given key will be present in at most one of a set of sibling shards that are active at a given point in time. As a result, your code can simply process the stream records within a shard in order to accurately track changes to an item.
Your code can retrieve the shards, iterate through the records, and process them in any desired way. The records can be retrieved at approximately twice the rate of the table’s provisioned write capacity.
You can enable streams for a table at creation time by supplying a stream specification parameter when you call CreateTable. You can also enable streams for an existing table by supplying a similar specification to UpdateTable. In either case, the specification must include a flag (enable or disable streams), and a view type (store and return item keys only, new image only, old image only, or both new and old images).
Read the new DynamoDB Streams Developer Guide to learn more about this new feature.
You can create DynamoDB Streams on your DynamoDB tables at no charge. You pay only for reading data from your Streams. Reads are measured as read request units; each call to GetRecords is billed as a single request unit and can return up to 1 MB of data. See the DynamoDB Pricing page for more info.
DynamoDB Streams + Lambda = Database Triggers
AWS Lambda makes it easy for you to write, host, and run code (currently Node.js and Java) in the cloud without having to worry about fault tolerance or scaling, all on a very economical basis (you pay only for the compute time used to run your code, in 100 millisecond increments).
As the centerpiece of today’s launch of DynamoDB Streams in production status, we are also making it easy for you to use Lambda to process stream records without writing a lot of code or worrying about scalability as your tables grow larger and busier.
You can think of the combination of Streams and Lambda as a clean and lightweight way to implement database triggers, NoSQL style! Historically, relational database triggers were implemented within the database engine itself. As such, the repertoire of possible responses to an operation is limited to the operations defined by the engine. Using Lambda to implement the actions associated with the triggers (inserting, deleting, and changing table items) is far more powerful and significantly more expressive. You can write simple code to analyze changes (by comparing the new and the old item images), initiate updates to other forms of data, enforce business rules, or activate synchronous or asynchronous business logic. You can allow Lambda to manage the hosting and the scaling so that you can focus on the unique and valuable parts of your application.
Getting set up to run your own code to handle changes is really easy. Let’s take a quick walk-through using a new table. After I create an invocation role for Lambda (so that it can access DynamoDB on my behalf), I open up the Lambda Console and click on Create a Lambda function. Then I choose the blueprint labeled dynamodb-process-stream:
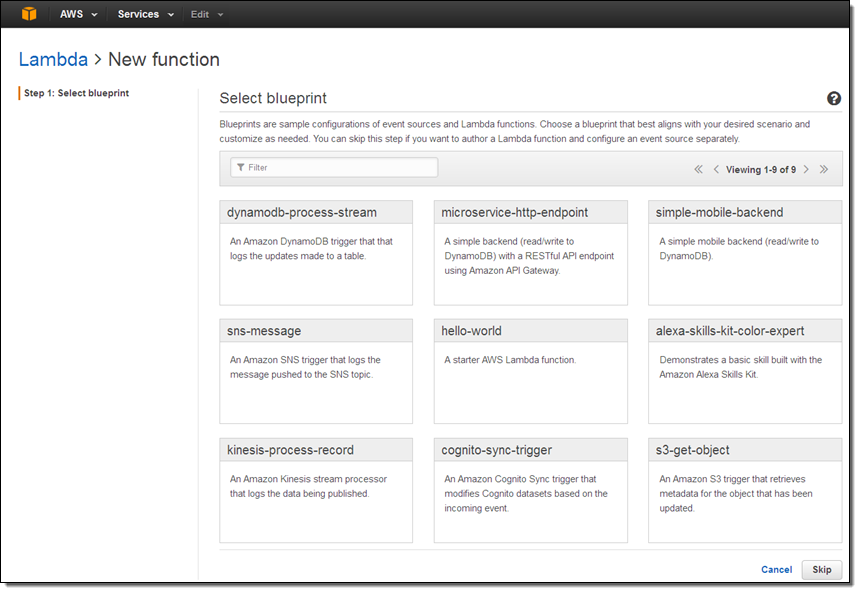 Each blueprint configures an event source and a skeletal Lambda function to get you started. The Console prompts me to configure the event source. I connect it to one of my DynamoDB tables (user_table), indicate that my code can handle batches of up to 100 stream records, and that I want to process new records (I could also choose to process existing records dating back to the stream’s trim horizon):
Each blueprint configures an event source and a skeletal Lambda function to get you started. The Console prompts me to configure the event source. I connect it to one of my DynamoDB tables (user_table), indicate that my code can handle batches of up to 100 stream records, and that I want to process new records (I could also choose to process existing records dating back to the stream’s trim horizon):
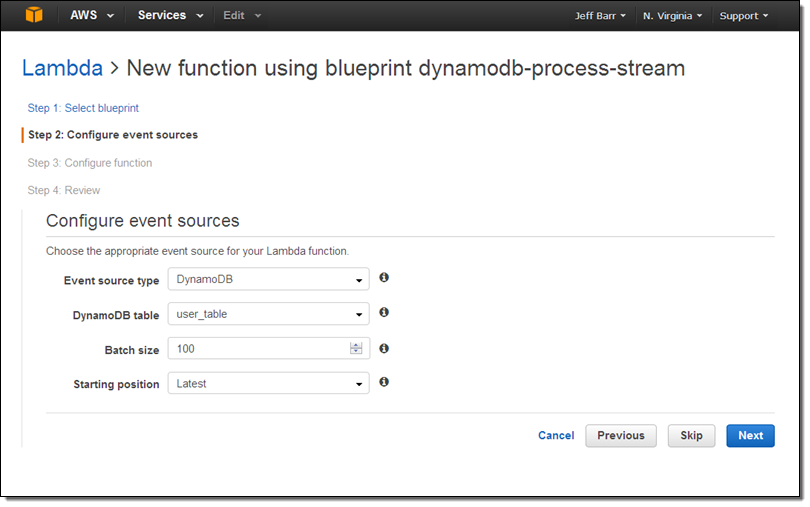
The blueprint includes a function that I can use as-is for testing purposes; I simply give it a name (ProcessUserTableRecords) and choose an IAM role so that the function can access DynamoDB:
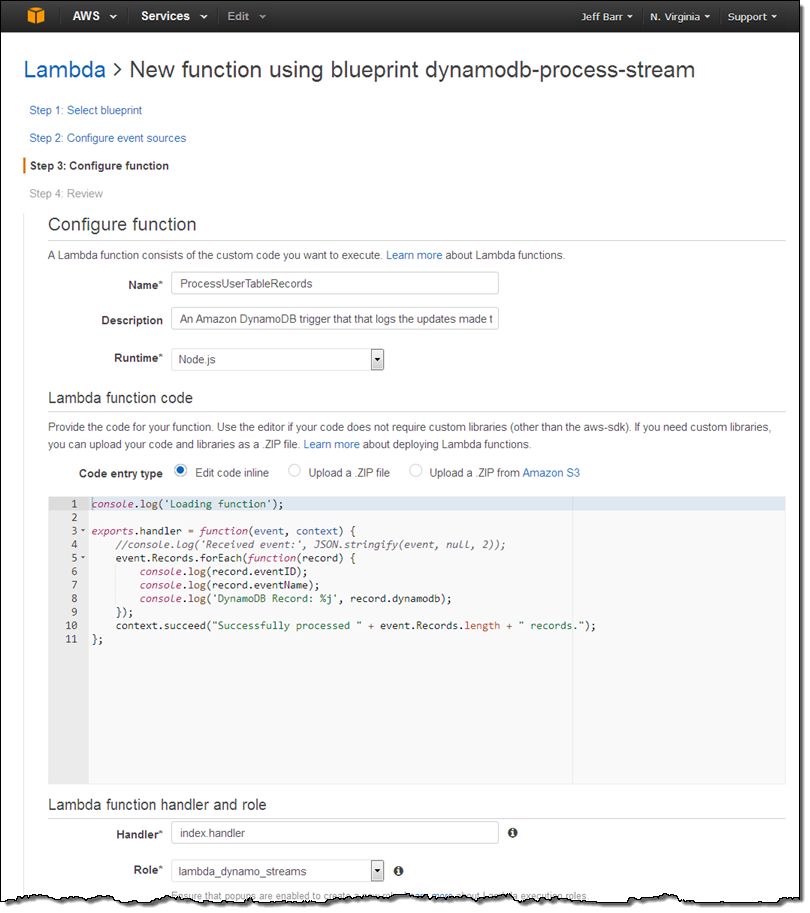
Now I confirm my intent. I will enable the event source (for real development you might want to defer this until after you have written and tested your code):
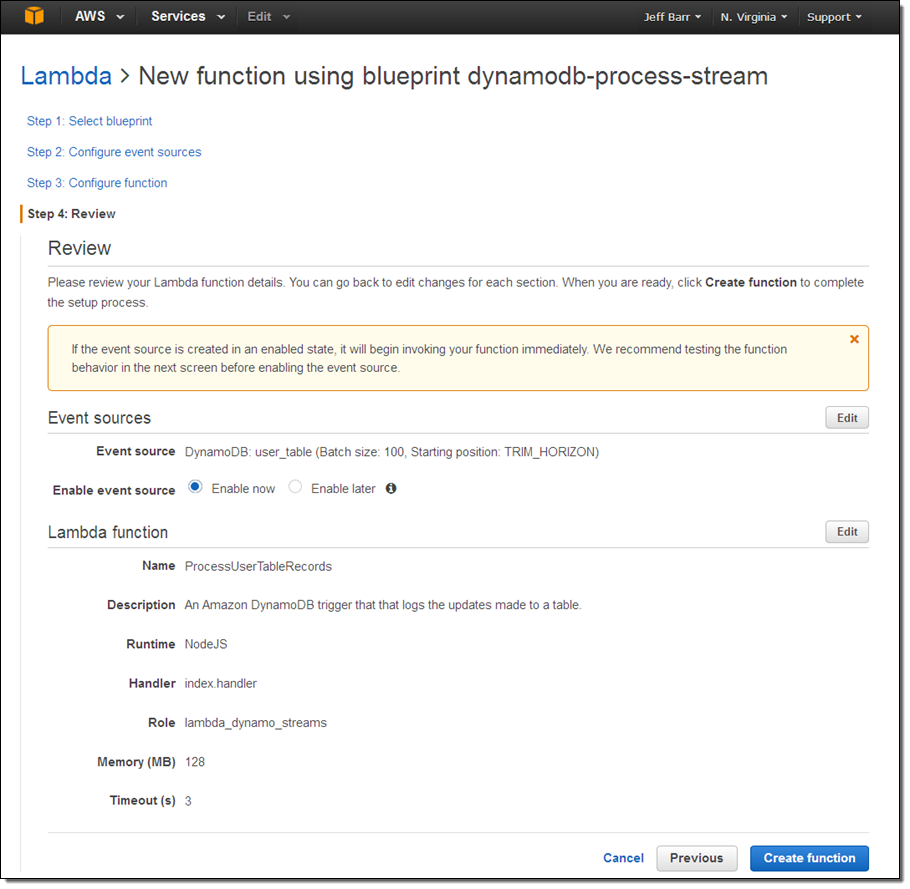
Clicking Create function will create the function and use my table’s update stream as an event source. I can see the status of this and the other event sources on the Event sources tab in the Lambda Console:
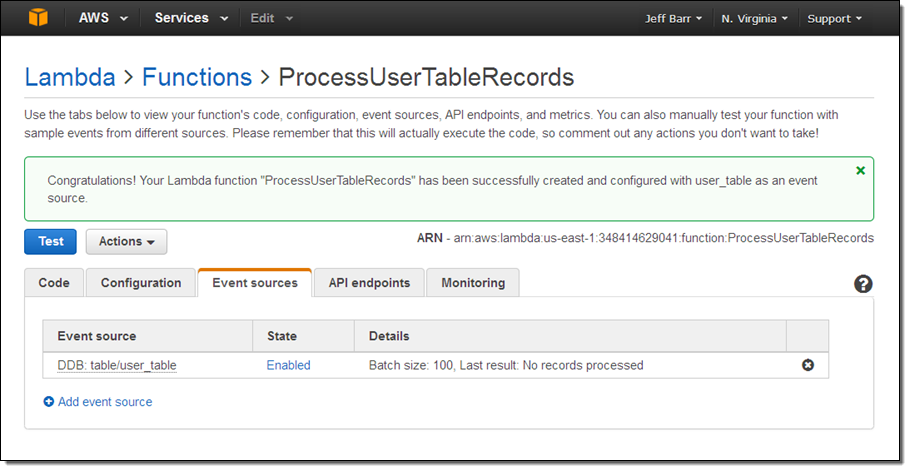
Ok, I am all set. At this point I have a function, it is connected to my table’s update stream, and it is ready to process records! To test this out I switch to the DynamoDB Console and insert a couple of items into my table in order to generate some activity on the stream:
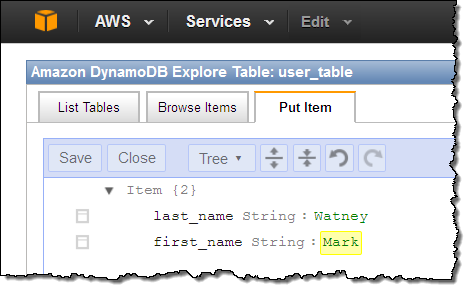
Then I go back to the Lambda Console (browser tabs make all of this really easy, of course) and verify that everything worked as expected. A quick glance at the Monitoring tab confirms that my function ran twice, with no apparent errors:
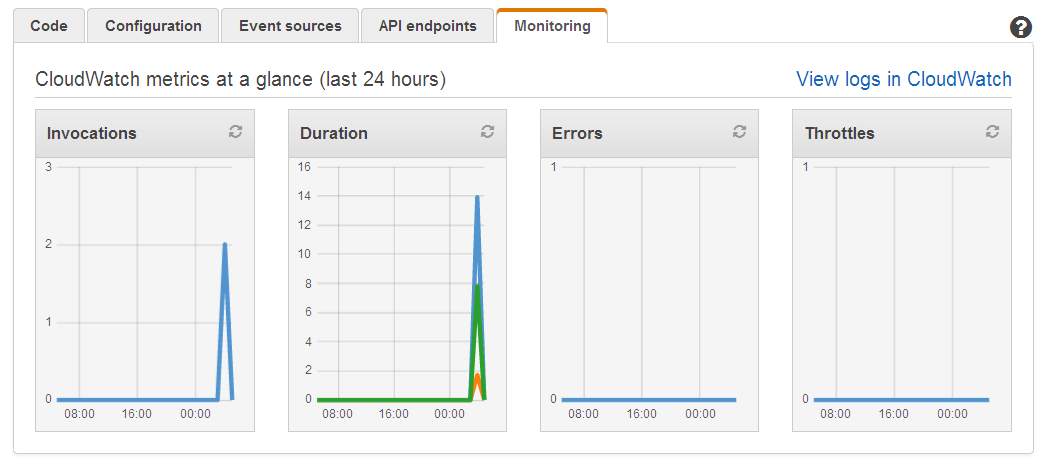
That looks good, so I inspect the CloudWatch Logs for the function to learn more:
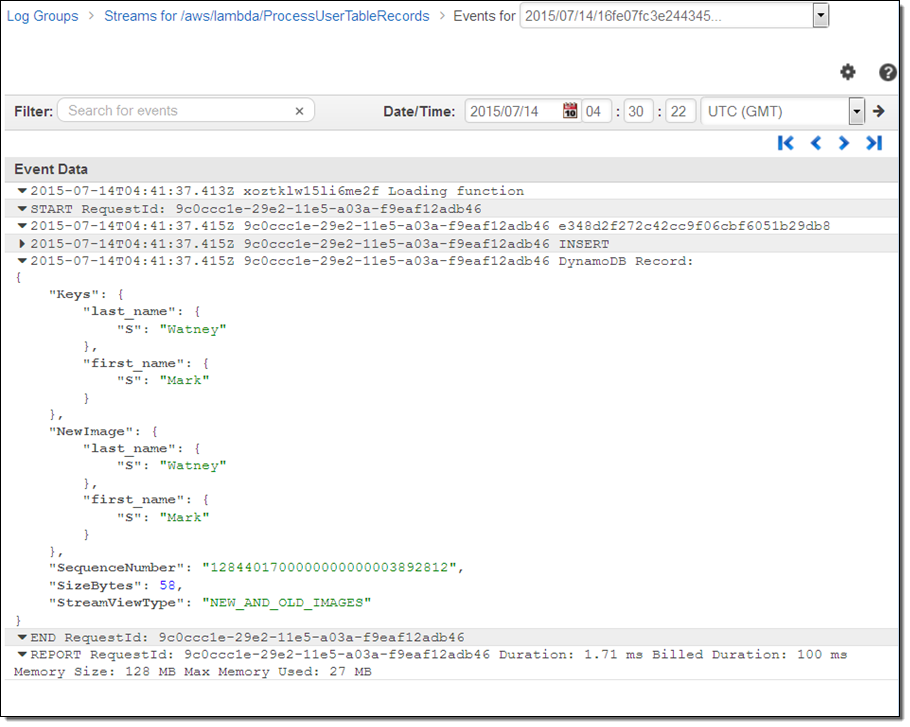
If I was building a real application, I could start with the code provided by the blueprint and add more functionality from there.
AWS customer Mapbox is already making use of DynamoDB Streams and Lambda, take a look at their new blog post, Scaling the Mapbox Infrastructure with DynamoDB Streams.
To learn more about how to use DynamoDB and Lambda together, read the documentation on Using DynamoDB Streams and AWS Lambda. There is no charge for DynamoDB Triggers; you pay the usual rates for the execution of your Lambda functions (see the Lambda Pricing page for more information).
I believe that this new feature will allow you to make your applications simpler, more powerful, and more responsive. Let me know what you build!
Cross-Region DynamoDB Replication
As an example of what can be done with the new DynamoDB Streams feature, we are also releasing a new cross-region replication app for DynamoDB. This application makes use of the DynamoDB Cross Region Replication library that we published last year (you can also use this library as part of your own applications, of course).
You can use replication to duplicate your DynamoDB data across regions for several different reasons including disaster recovery and low-latency access from multiple locations. As you’ll see, the app makes it easy for you to set up and maintain replicas.
This app runs on AWS Elastic Beanstalk and makes use of the Amazon EC2 Container Service, all launched via a AWS CloudFormation template.
You can initiate the launch process from within the DynamoDB Console. CloudFormation will prompt you for the information that it needs to have in order to create the stack and the containers:
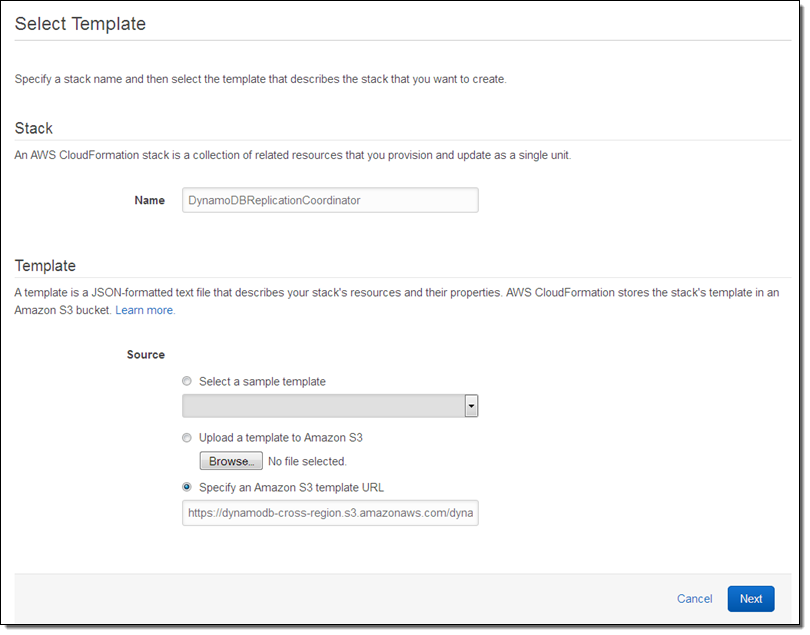
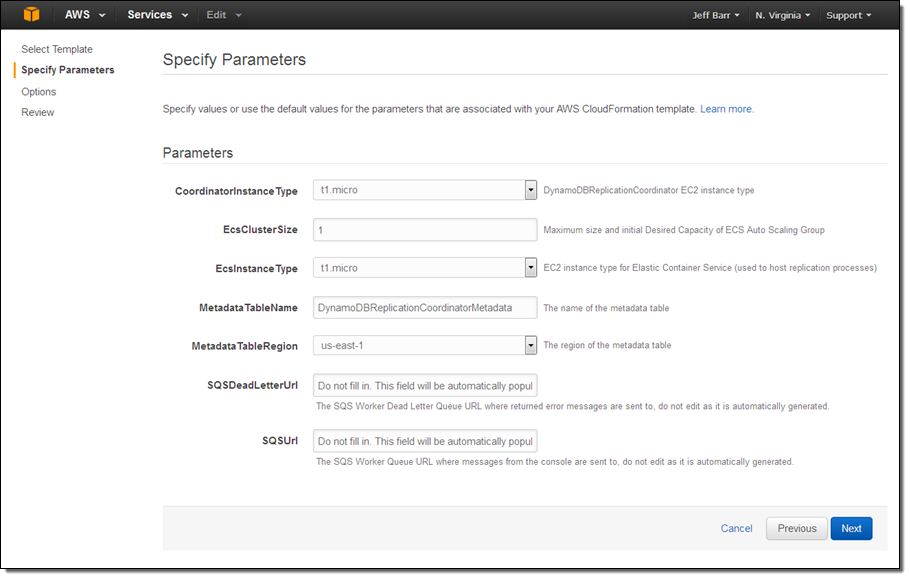
Give the stack (a collective name for the set of AWS resources launched by the template) a name and then click on Next. Then fill in the parameters (you can leave most of these at their default values):
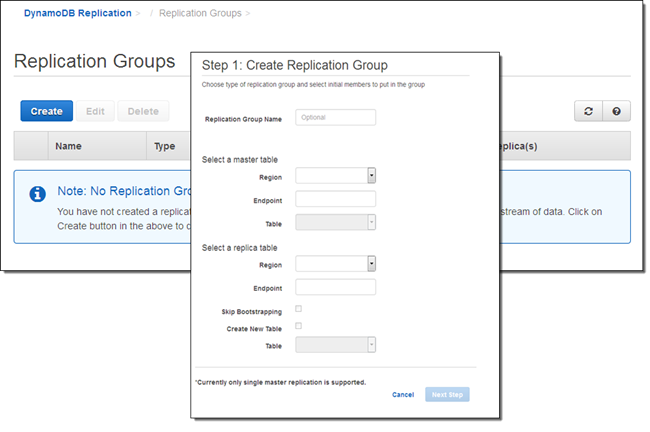
The Metadata table contains the information that the replicator needs to have in order to know which tables to replicate and where the replicas are to be stored. After you launch the replication app you can access its online configuration page (the CloudFormation template will produce a URL) and set things up:
This feature is available to you at no charge. You will be charged for the resources (provisioned throughput and storage for the replica tables, data transfer between regions, reading data from the Streams, the EC2 instances, and the SQS queue that is used to control the application). See the DynamoDB Pricing page for more information.
Read about Cross Region Replication to learn how to set everything up!
— Jeff;
New – Alexa Skills Kit, Alexa Voice Service, Alexa Fund
Amazon Echo is a new type of device designed around your voice. Echo connects to Alexa, a cloud-based voice service powered (of course) by AWS. You can ask Alexa to provide information, answer questions, play music, read the news, and get results or answers instantly.
When you are in the same room as an Amazon Echo, you simply say the wake word (either “Alexa” or “Amazon”) and then make your request. For example, you might say “Alexa, when do the Seattle Mariners play next?” or “Alexa, will it ever rain in Seattle?” Behind the scenes, code running in the cloud hears, understands, and processes your spoken requests.
Today we are giving you the ability to create new voice-driven capabilities (also known as skills) for Alexa using the new Alexa Skills Kit (ASK). You can connect existing services to Alexa in minutes with just a few lines of code. You can also build entirely new voice-powered experiences in a matter of hours, even if you know nothing about speech recognition or natural language processing.
We will also be opening up the underlying Alexa Voice Service (AVS) to developers in preview form. Hardware manufacturers and other participants in the new and exciting Internet of Things (IoT) world can sign up today for notification when the preview is available. Any device that has a speaker, a microphone, and an Internet connection can integrate Alexa with a few lines of code.
In order to help to inspire creativity and to fuel innovation in and around voice technology, we are also announcing the Alexa Fund. The Alexa Fund will provide up to $100 million in investments to support developers, manufacturers, and start-ups of all sizes who are creating new designed around the human voice to improve customers’ lives.
ASK and AWS Lambda
You can build new skills for Alexa using AWS Lambda. You simply write the code using Node.js and upload it to Lambda through the AWS Management Console, where it becomes known as a Lambda function. After you upload and test your function using the sample events built in to the Console, you can sign in to the Alexa Developer Portal, register your code in the portal (by creating an Alexa App), and then use the ARN (Amazon Resource Name) of the function to connect it to the App. After you complete your testing, you can publish your App in order to make it available to Echo owners. Lambda will take care of hosting and running your code in a scalable, fault-tolerant environment. In many cases, the function that supports an Alexa skill will remain comfortably within the Lambda Free Tier. Read Developing Your Alexa Skill as a Lambda Function to get started.
ASK as a Web Service
You can also build your app as a web service and take on more of the hosting duties yourself using Amazon Elastic Compute Cloud (EC2), AWS Elastic Beanstalk, or an on-premises server fleet. If you choose any of these options, the service must be Internet-accessible and it must adhere to the Alexa app interface specification. It must support HTTPS over SSL/TLS on port 443 and it must provide a certificate that matches the domain name of the service endpoint. Your code is responsible for verifying that the request actually came from Alexa and for checking the time-based message signature. To learn more about this option, read Developing Your Alexa App as a Web Service.
Learn More
We are publishing a lot of information about ASK, AVS, and the Alexa Fund today. Here are some good links to get you started:
— Jeff;
AWS Lambda Update – Run Java Code in Response to Events
Many AWS customers are using AWS Lambda to build clean, straightforward applications that handle image and document uploads, process log files from AWS CloudTrail, handle data streamed from Amazon Kinesis, and so forth. With the recently launched synchronous invocation capability, Lambda is fast becoming a favorite choice for building mobile, web and IoT backends.
Our internal mailing list is awash with discussions about interesting ways to use Lambda, many of which would fall squarely into the traditional data processing realm. These customers love Lambda because they can focus on their application and leave the hosting and scaling duties to us. To date, developers have written their Lambda functions in Node.js, a derivative of JavaScript designed specifically for use in server-side applications.
Lambda Functions in Java
Today we are making Lambda even more useful by giving you the ability to write your Lambda functions in Java. We have had many requests for this and the team is thrilled to be able to respond. This is the first in a series of additional language options that we plan to make available to Lambda developers.
Your code can make use of Java 8 features (read What’s New in JDK 8) to learn more) along with any desired Java libraries. You can also use the AWS SDK for Java to make calls to the AWS APIs.
We provide you with two libraries specific to Lambda: aws-lambda-java-core with interfaces for Lambda function handlers and the context object, and aws-lambda-java-events containing type definitions for AWS event sources (Amazon Simple Storage Service (S3), Amazon Simple Notification Service (SNS), Amazon DynamoDB, Amazon Kinesis, and Amazon Cognito). You may also want to spend some time learning more about the Lambda programming model for Java.
You can author your Lambda functions in one of two ways. First, you can use a high-level model that uses input and output objects (the input and output types can be any Java POJO or primitive):
public lambdaHandler( input, Context context) throws IOException;
public lambdaHandler( input) throws IOException;
If you do not want to use POJOs or if Lambda’s serialization model does not meet your needs, you can use the Stream model. This is a bit lower-level:
public void lambdaHandler(InputStream input, OutputStream output, Context context)
throws IOException;
The class in which your Lambda function is defined should include a public zero-argument constructor, or define the handler method as static. Alternatively, you can implement one of the handler interfaces (RequestHandler::handleRequest or RequestStreamHandler::handleRequest) available within the Lambda core Java library.
Packaging, Deploying, and Uploading
You can continue to use your existing development tools. In order to prepare your compiled code for use with Lambda, you must create a ZIP or JAR file that contains your compiled code (CLASS files) and any desired JAR files (Note that deployment packages uploaded to Lambda are limited to 50 MB). Your handler functions should be stored in the usual Java directory structure (e.g. com/mypackage/MyHandler.class); the JAR files must be directly inside of a lib subdirectory. In order to make this process easy, we have published build approaches using popular Java deployment tools such as Maven and Gradle.
Specify a runtime of “java8” when you upload your ZIP file. If you implemented one of the handler interfaces, provide the class name. Otherwise, provide the fully qualified method reference (e.g. com.mypackage.LambdaHandler::functionHandler).
Using the AWS Toolkit for Eclipse
The AWS Toolkit for Eclipse plugin will automatically generate and upload the ZIP file for you. You can create a Lambda project from the AWS menu:
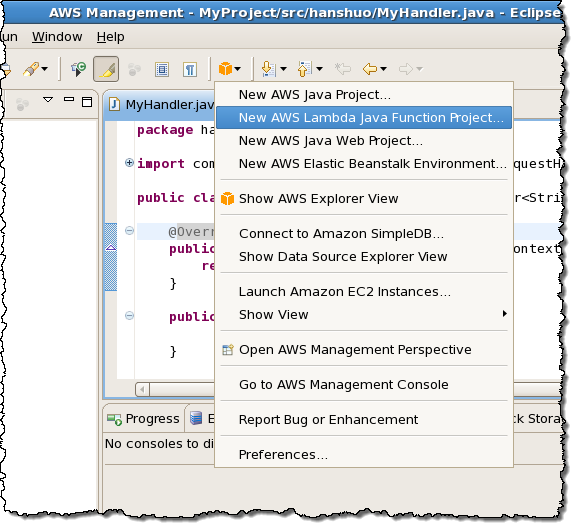
After filling in the particulars of your project you can start with template generated by the toolkit:
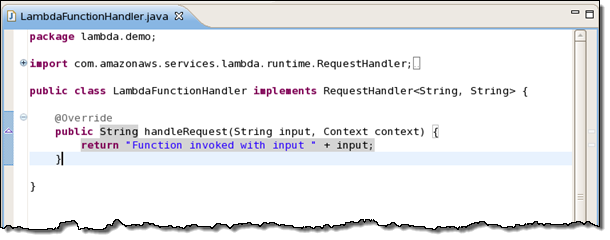
Then you can write your function and deploy it to Lambda with a click:

And then you can invoke it:
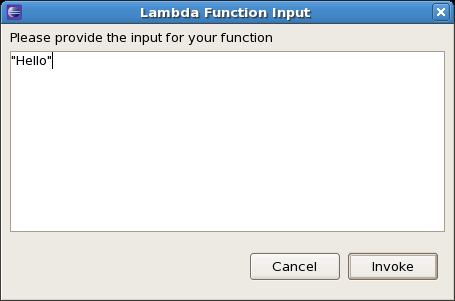
Available Now
You can start writing your Lambda functions in Java today!
To learn more, read about Authoring Lambda Functions in Java in the Lambda documentation.
— Jeff;
AWS Lambda – In Full Production with New Features for Mobile Devs
We launched AWS Lambda in preview form at last year’s AWS re:Invent conference (see my post, AWS Lambda – Run Code in the Cloud for more information). As I said at the time, Lambda is a zero-admin compute platform; you don’t have to configure, launch, or, monitor Amazon Elastic Compute Cloud (EC2) instances, think about scale, or worry about fault tolerance. You simply create a Lambda function (using JavaScript / Node.js), set the appropriate permissions, and connect the function to your AWS resources.
We received a lot of great feedback during the preview period. We have used your feedback to update and prioritize our development roadmap and I would like to share the results with you in this blog post. It was great to hear that you (and many other developers) plan to use Lambda to host mobile, website, and device backends. We have added several features to Lambda in order to provide you with even more power and flexibility for this important set of use cases. I’ll get to that part in a minute.
Now in Production
First and foremost, Lambda is now ready for production workloads. You can now run up to 100 concurrent requests per account (up from 50 during the preview). If your application is taking off like a rocket and you need to be able to run more requests concurrently, get in touch and we’ll do our best to help out in an expeditious fashion.
Lambda will start to execute your code within milliseconds, provided that the function exists, that it has the proper permissions, and that you are within your account-level limit for concurrent requests.
Taken together, these two factors give Lambda the scale and the responsiveness necessary to host high-volume production applications. Lambda’s fine-grained pricing means that your applications, even at scale, will be cost-effective to run.
New Lambda Features
Let’s take a look at the features that we have added as part of our move to general availability:
- Synchronous Invoke -Your application can now invoke a Lambda function synchronously and receive a response as soon as it finishes executing. The arguments and the response can be expressed in JSON notation. You can try out the new invocation model using this simple walk through: Handling Events from User Applications.
- New Triggers – You can now invoke Lambda functions using Amazon Simple Notification Service (SNS) notifications as triggers. You can also invoke them in response to a request made via the AWS Mobile SDK (Android and iOS). To learn more about invoking Lambda functions using Amazon SNS, visit the Amazon SNS Developers Guide.
- Simplified Access Model – You can now use a single IAM role (instead of the pair that were previously required) to grant execution permission to your Lambda functions. The console includes one-click role creation and will also help you to bring your existing execution roles into conformance with the new, simpler model. Read Introduction to Permissions Model to learn more.
- Cross-Account Access to Resources – Lambda has also added support for resource based policies and cross account access, allowing to now grant permissions to invoke Lambda functions from another AWS account.
- Enhanced Console – You can now use the AWS Management Console to add, edit, and remove Amazon Kinesis streams as event sources. You can also now view all event sources for a Lambda function in one place, making it much easier to see what’s triggering your function. Take the new console for a spin for Kinesis and read Getting Started with Kinesis Events to learn more.
- Multiple Functions – You can now attach more than one Lambda function to a single Kinesis or DynamoDB stream. If you plan to do this with a Kinesis stream, we recommend that you have sufficient shards to handle the expected number of concurrent requests.
- Enhanced Metrics & API – We added metrics for throttling, improved the event source management APIs, and streamlined Lambda’s programming model.
- Cognito Events – You can now invoke a Lambda function as part of the synchronization process for a Cognito Dataset. Read about Cognito Events to learn more.
Great Mobile Support

“Amazon Cognito makes it really easy for us to store game states in the cloud and synchronize them across devices. We are excited about Amazon Cognito’s integration with AWS Lambda because we can now efficiently intercept, verify and resolve all the changes made to the game data across multiple devices by running the analysis on the AWS Lambda backend. As a result, we can deliver a better gaming experience for our customers.”
Todd Shallbetter, Chief Operating Officer
Atari
Mobile applications often attract a large user base very quickly. Whether you are just prototyping a mobile app or already have a large user base, you can count on Lambda to instantly add a backend that can scale automatically.
As I mentioned earlier, developers are already using Lambda as an integral part of sophisticated mobile apps. They are able to create scalable server-side components (the mobile backend) without having to think about compute, storage, load balancing, and the like. However, the asynchronous processing model means they cannot use it in latency sensitive tasks, such as responding to in-app activity.
The new Synchronous Invoke feature that I described above is a great fit for this use case. Lambda functions that have been invoked in synchronous fashion via the Mobile SDK receive detailed context information as part of the request. They have access to application data (name, build, version, and package), device data (manufacturer, model, platform), and user data (the client id). Because function are invoked within milliseconds, the mobile backend can respond to requests with great rapidity. You can improve your overall app experience without having to worry about hosting or scaling backend code.
The AWS Mobile SDKs for Android and iOS now include support for the new Synchronous Invoke feature. You can also use the AWS Mobile SDK as an event source in order to run your Lambda code in response to events that occur on the mobile device.
Amazon Cognito is a service that makes it easy to save user data, such as app preferences or game state, in the AWS Cloud without writing any backend code or managing any infrastructure. You can now trigger execution of your Lambda functions when Cognito syncs a Dataset. Your Lambda function can participate in the sync operation by validating, filtering, or modifying the incoming data.
On the Roadmap
That roadmap I mentioned above? We are just getting started and we have all sorts of cool stuff in the works. For example, you will soon be able to write your Lambda functions in Java! You will also be able to use Lambda functions to intercept and process merge and conflict resolution events on your Cognito Datasets.
From our Customers
We also have great partners starting to participate in the Lambda ecosystem! For example, Codeship announced AWS Lambda support for deploying Lambda functions, which makes it easy to make updates to Lambda functions without having to do manual updates or build your own deployment system.
Get Started Today
Read Getting Started with AWS Lambda to learn how to create your first function. Check out the What’s New Page to learn more about the features that I described above.
Take Lambda for a spin and let me know what you come up with!
— Jeff;
AWS Lambda – Run Code in the Cloud
We want to make it even easier for you to build applications that run in the Cloud. We want you to be able to focus on your code, and to work within a cloud-centric environment where scalability, reliability, and runtime efficiency are all high enough to be simply taken for granted!
 Today we are launching a preview of AWS Lambda, a brand-new way to build and run applications in the cloud, one that lets you take advantage of your existing programming skills and your knowledge of AWS. With Lambda, you simply create a Lambda function, give it permission to access specific AWS resources, and then connect the function to your AWS resources. Lambda will automatically run code in response to modifications to objects uploaded to Amazon Simple Storage Service (S3) buckets, messages arriving in Amazon Kinesis streams, or table updates in Amazon DynamoDB.
Today we are launching a preview of AWS Lambda, a brand-new way to build and run applications in the cloud, one that lets you take advantage of your existing programming skills and your knowledge of AWS. With Lambda, you simply create a Lambda function, give it permission to access specific AWS resources, and then connect the function to your AWS resources. Lambda will automatically run code in response to modifications to objects uploaded to Amazon Simple Storage Service (S3) buckets, messages arriving in Amazon Kinesis streams, or table updates in Amazon DynamoDB.
Lambda is a zero-administration compute platform. You don’t have to configure, launch, or monitor EC2 instances. You don’t have to install any operating systems or language environments. You don’t need to think about scale or fault tolerance and you don’t need to request or reserve capacity. A freshly created function is ready and able to handle tens of thousands of requests per hour with absolutely no incremental effort on your part, and on a very cost-effective basis.
Let’s dig in! We’ll take a more in-depth look at Lambda, sneak a peek at the programming model and runtime environment, and then walk through a programming example. As you read through this post, keep in mind that we have plenty of items on the Lambda roadmap and that what I am able to share today is just the first step on what we expect to be an enduring and feature-filled journey.
Lambda Concepts
 The most important Lambda concept is the Lambda function, or function for short. You write your functions in Node.js (an event-driven, server side implementation of JavaScript).
The most important Lambda concept is the Lambda function, or function for short. You write your functions in Node.js (an event-driven, server side implementation of JavaScript).
You upload your code and then specify context information to AWS Lambda to create a function. The context information specifies the execution environment (language, memory requirements, a timeout period, and IAM role) and also points to the function you’d like to invoke within your code. The code and the metadata are durably stored in AWS and can later be referred to by name or by ARN (Amazon Resource Name). You an also include any necessary third-party libraries in the upload (which takes the form of a single ZIP file per function).
After uploading, you associate your function with specific AWS resources (a particular S3 bucket, DynamoDB table, or Kinesis stream). Lambda will then arrange to route events (generally signifying that the resource has changed) to your function.
When a resource changes, Lambda will execute any functions that are associated with it. It will launch and manage compute resources as needed in order to keep up with incoming requests. You don’t need to worry about this; Lambda will manage the resources for you and will shut them down if they are no longer needed.
Lambda is accessible from the AWS Management Console, the AWS SDKs and the AWS Command Line Interface (CLI). The Lambda APIs are fully documented and can be used to connect existing code editors and other development tools to Lambda.
Lambda Programming Model
Functions are activated after the associated resource has been changed. Execution starts at the designated Node.js function and proceeds from there. The function has access (via a parameter supplied along with the POST) to a JSON data structure. This structure contains detailed information about the change (or other event) that caused the function to be activated.
Lambda will activate additional copies of function as needed in order to keep pace with changes. The functions cannot store durable state on the compute instance and should use S3 or DynamoDB instead.
Your code can make use of just about any functionality that is intrinsic to Node.js and to the underlying Linux environment. It can also use the AWS SDK for JavaScript in Node.js to make calls to other AWS services.
Lambda Runtime Environment
The context information that you supply for each function specifies a maximum execution time for the function. This is typically set fairly low (you can do a lot of work in a couple of seconds) but can be set to up 60 seconds as your needs dictate.
Lambda uses multiple IAM roles to manage access to your functions and your AWS resources. The invocation role gives Lambda permission to run a particular function. The execution role gives a function permission to access specific AWS resources. You can use distinct roles for each function in order to implement a fine-grained set of permissions.
Lambda monitors the execution of each function and stores request count, latency, availability, and error rate metrics in Amazon CloudWatch. The metrics are retained for 30 days and can be viewed in the Console.
Here are a few things to keep in mind when as you start to think about how you will put Lambda to use:
- The context information for a function specifies the amount of memory needed to run it. You can set this to any desired value between 128 MB and 1 GB. The memory setting also determines the amount of CPU power, network bandwidth, and I/O bandwidth that are made available to the function.
- Each invocation of a function can make use of up to 256 processes or threads. It can consume up to 512 MB of local storage and up to 1,024 file descriptors.
- Lambda imposes a set of administrative limits on each AWS account. During the preview, you can have up to 25 invocation requests underway simultaneously.
Lambda in Action
Let’s step through the process of creating a simple function using the AWS Management Console. As I mentioned earlier, you can also do this from the SDKs and the CLI. The console displays all of my functions:
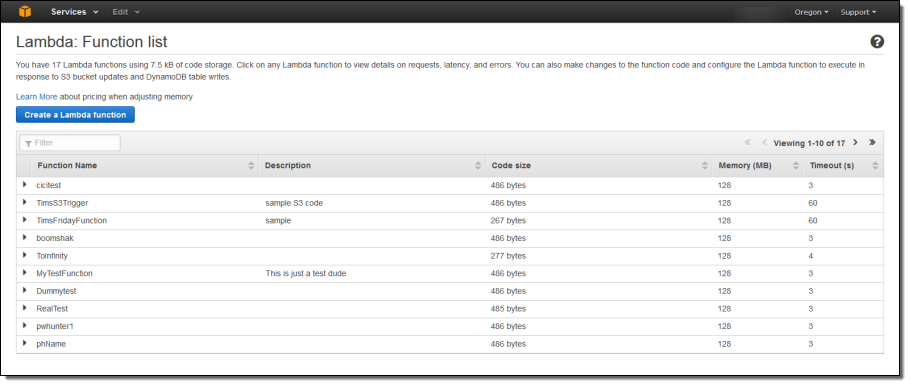
I simply click on Create Function to get started. Then I fill in all of the details:
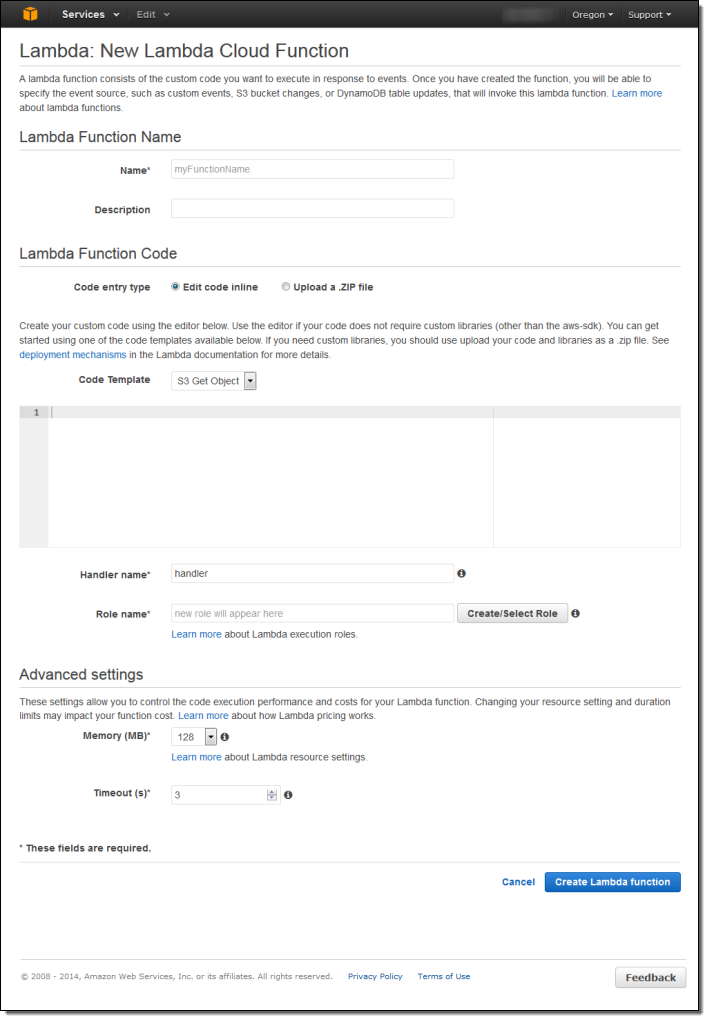
I name and describe my function:

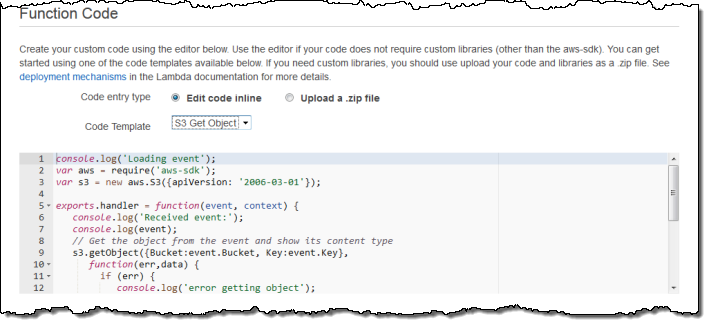
Then I enter the code or upload a ZIP file. The console also offers a choice of sample code snippets to help me to get started:
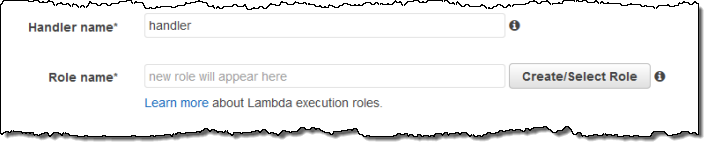
Now I tell Lambda which function to run and which IAM role to use when the code runs:
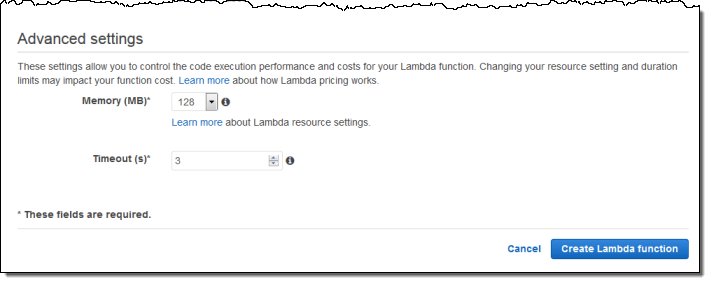
I can also fine-tune the memory requirements and set a limit on execution time:
After I create my function, I can iteratively edit and test it from within the Console. As you can see, the pane on the left shows a sample of the JSON data that will be passed to my function:
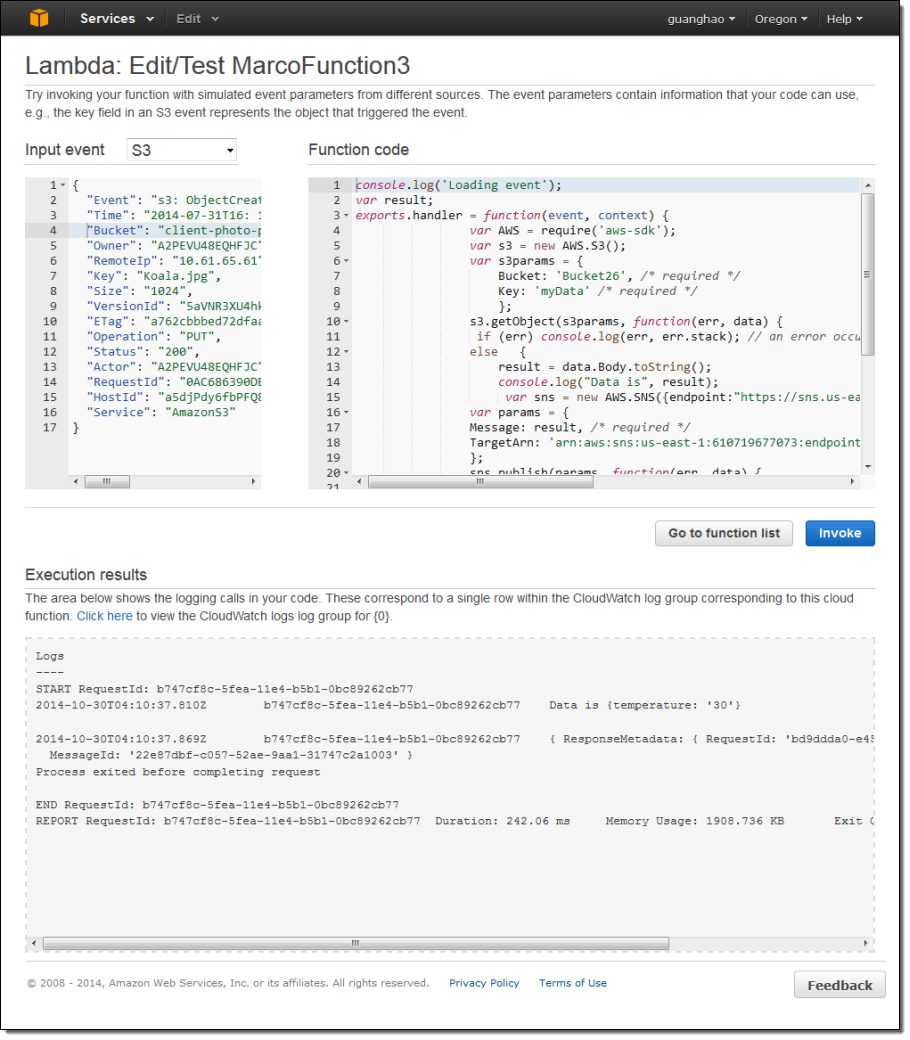
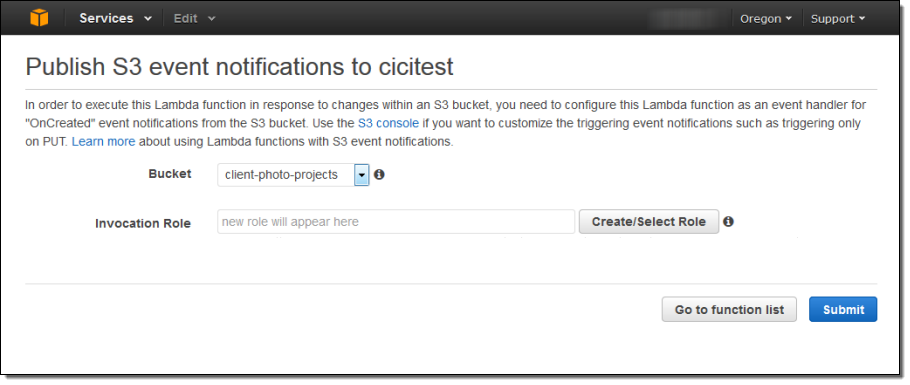
When the function is working as expected, I can attach it to an event source such as Amazon S3 event notification. I will to provide an invocation role in order to give S3 the permission that it needs to have in order to invoke the function:
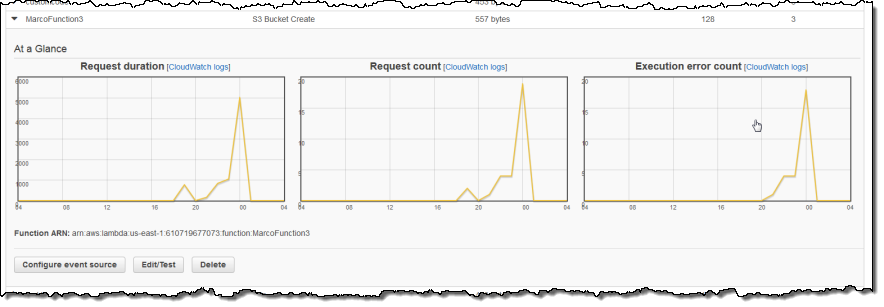
Lambda collects a set of metrics for each of my functions and sends them to Amazon CloudWatch. I can view the metrics from the Console:
On the Roadmap
We have a great roadmap for Lambda! While I won’t spill all of the beans today, I will tell you that we expect to add support for additional AWS services and other languages. As always, we love your feedback; please leave a note in the Lambda Forum.
Pricing & Availability
Let’s talk about pricing a bit before wrapping up! Lambda uses a fine-grained pricing model. You pay for compute time in units of 100 milliseconds and you pay for each request. The Lambda free tier includes 1 million free requests per month and up to 3.2 million seconds of compute time per month depending on the amount of memory allocated per function.
Lambda is available today in preview form in the US East (Northern Virginia), US West (Oregon), and EU (Ireland) Regions. If you would like to get started, register now.
— Jeff;