Category: Amazon Elasticsearch Service
Kinesis Firehoseを使用してApache WebログをAmazon Elasticsearch Serviceに送信する
Elasticsearch、Logstash、および、Kibana(ELK)スタックを所有して運用する多くのお客様が、他の種類のログの中でもApache Webログを読み込んで可視化しています。 Amazon Elasticsearch Serviceは、AWSクラウドにElasticsearchとKibanaを提供しており、セットアップと運用が簡単です。 Amazon Kinesis Firehoseは、Amazon Elasticsearch ServiceにApache Webログ(またはその他のログデータ)をサーバーレスで確実に配信します。
Firehoseを使用すると、Firehose内のレコードを変換するAWS Lambda関数への自動呼び出しを追加できます。これらの2つのテクノロジーを使用すると、既存のELKスタックを効果的かつ簡単に管理することができます。
この記事では、最初にAmazon Elasticsearch Serviceドメインを設定する方法を説明します。次に、事前ビルドされたLambda関数を使用してApache Webログを解析するFirehoseストリームを作成して接続する方法を示します。最後に、Amazon Kinesis Agentでデータをロードし、Kibanaで可視化する方法を示します。
AWS上でApache Flinkを使用してリアルタイムストリーム処理パイプラインを構築する
今日のビジネス環境では、多様なデータソースが着実に増加していく中で、データが継続的に生成されています。したがって、このデータを継続的にキャプチャ、格納、および処理して、大量の生データストリームを実用的な洞察に素早く繋げることは、組織にとって大きな競争上のメリットになっています。
Apache Flinkは、このようなストリーム処理パイプラインの基礎を形成するのに適したオープンソースプロジェクトです。ストリーミングデータの継続的な分析に合わせたユニークな機能を提供しています。しかし、Flinkを基にしたパイプラインの構築と維持には、物理的なリソースと運用上の努力に加え、かなりの専門知識が必要になることがよくあります。
この記事では、Amazon EMR、Amazon Kinesis、Amazon Elasticsearch Serviceを使用してApache Flinkを基にした、一貫性のあるスケーラブルで信頼性の高いストリーム処理パイプラインの参照アーキテクチャの概要を説明します。 AWSLabs GitHubリポジトリは、実際に参照アーキテクチャを深く理解するために必要なアーティファクトを提供します。リソースには、サンプルデータをAmazon Kinesisストリームに取り込むプロデューサアプリケーションと、リアルタイムでデータを分析し、その結果をAmazon ESに可視化するためのFlinkプログラムが含まれています。
Amazon EC2インスタンスにホストベースの侵入検知システムアラートの監視方法
AWSリソースを安全に保護するためのアプローチとして、予防のための仕組み、検知のため仕組みといったそれぞれのレイヤーでのアプローチを検討頂くことを推奨しています。たとえば、Amazon EC2インスタンスにホストベースのコントロールを組み込むことで、アクセスを制限し、システムの動作やアクセスパターンに伴う適切なレベルの可視性を準備できます。これらのコントロールには、ホスト上のネットワークトラフィック、ログファイル、およびファイルアクセスを監視・分析するホストベースの侵入検知システム(HIDS)を含むことが一般的です。 HIDSは、通常、警告、自動修復ソリューションと統合され、攻撃、許可されていない活動、疑わしい活動、環境内の一般的なエラーを検出し対処します。
このブログ記事では、Amazon CloudWatch Logsを使用してオープンソースセキュリティ(OSSEC)HIDSからのアラートを収集、集約する方法を示します。 また、CloudWatch Logs サブスクリプションを組み合わせることで、Amazon Elasticsearch Service(Amazon ES)に分析データと可視化のアラートを配信し、一般的なオープンソースであるKibanaを使用し可視化まで行います。また皆さんが、すぐに試せるようにCloudFormationテンプレートを用意しましたので、ほとんどのデプロイメント作業を自動化させています。このソリューションを使用して、EC2 全体の可視性と洞察を向上させ、セキュリティ修復活動を促進することができます。たとえば、特定ホストがEC2インスタンスのスキャンを検知したらOSSECアラートをトリガーし、VPCネットワークACL(Access Control List)またはAWS WAFルールを実装して、送信元IPアドレスまたはCIDRをブロックすることができます。
ソリューションの概要
次の図は、この記事のソリューションの概要を示しています。

ソリューションの仕組みは次のとおりです。
1. ターゲットEC2インスタンスでは、OSSEC HIDSは、CloudWatch Logs エージェントがキャプチャするログに基づきアラートを生成します。 HIDSは、ログ分析、整合性チェック、Windowsレジストリ監視、ルートキット検出、リアルタイムアラート、およびアクティブな応答を実行します。詳細については、「OSSEC入門」を参照してください。
2. CloudWatch Logs グループはにアラートがイベントとして送信されます。
3. AWS Lambdaを介してイベントをAmazon ESに転送するために、CloudWatch Logs サブスクリプションがターゲットロググループに適用されます。
4. Amazon ESにはログに記録されたアラートデータがロードされます。
5. Kibanaはアラートをほぼリアルタイムで視覚化します。 Amazon ESはすべてのAmazon ESドメインにKibanaを標準でインストールした形で提供されます。
デプロイ時の考慮事項
この記事では、主なOSSEC HIDSのデプロイは、Linuxベースのインストールで構成されています。インストールでは、アラートが各システム内でローカルに生成されます。このソリューションは、デプロイの対象リージョンはAmazon ESとLambdaに依存します。 AWSサービスの可用性に関する最新情報は、Regionテーブルで確認できます。また、EC2インスタンスが必要なコンポーネントを適切にプロビジョニングするために、インターネットアクセスとDNS解決を持つAmazon VPC(Virtual Private Cloud)サブネットを識別する必要があります。
デプロイのプロセスを簡素化するために、テスト環境向けにAWS CloudFormationテンプレートを作成しました。このテンプレートを使用して、テスト環境スタックを既存のAmazon VPCサブネットに自動的にプロビジョニングできます。 CloudFormationを使用してこのソリューションのコアコンポーネントをプロビジョニングし、警告分析用にKibanaを設定します。このソリューションのソースコードはGitHubで入手できます。
Cloud Formation テンプレートは選択したリージョンで、下記の流れで展開されます。
1. CloudWatch LogsにアクセスするためのAWS Identity and Access Management(IAM)ロールが作成され、Amazon Linuxを実行する2つのEC2インスタンスにアタッチされます。注:サンプルHIDSアラートデータを提供するために、2つのEC2インスタンスが自動的に構成され、シミュレートされたHIDSアラートをローカルに生成します。
2. OSSEC、CloudWatch Logsエージェント、およびテスト環境で使用される追加パッケージをインストールして設定します。
3. ターゲットのHIDS Amazon ESドメインを作成します。
4. ターゲットのHIDS CloudWatch Logsグループを作成します。
5. Amazon ESにHIDSアラートを送信するために、Lambda関数とCloudWatch Logsサブスクリプションを作成します。
CloudFormationスタックがデプロイされた後、Amazon ESドメインのKibanaインスタンスにアクセスして、テスト環境のセットアップの最終ステップを完了することができます。これについては後で説明します。
このブログの投稿の範囲外にはなりますが、既存のEC2環境にOSSECを導入する場合は、監視対象のログファイル、完全性チェック用のディレクトリ、アクティブな応答など、必要な構成を決定する必要があります。通常、環境の最適化のためにシステムのテストとチューニングに時間を要すことがほとんどです。 OSSECのドキュメントは、このプロセスに慣れ始めるのに適しています。エージェントのインストールと別のOSSECマネージャを使用してイベントを一元的に処理してからCloudWatch Logsにエクスポートするという、OSSECの展開には別のアプローチをとることもできます。この展開では、エージェントとマネージャの間に追加のサーバーコンポーネントとネットワーク通信が必要です。 Windows ServerはOSSECでサポートされていますが、エージェントベースのインストールが必要なため、OSSECマネージャが必要です。 OSSECのアーキテクチャと展開オプションの詳細については、「OSSECアーキテクチャ」を参照してください。
ソリューションのデプロイ
手順の概要は次のとおりです。
1. CloudFormationスタックを起動します。
2. Kibanaのインデックスパターンを設定し、アラートの探索を開始します。
3. Kibana HIDSダッシュボードを設定し、アラートを視覚化します。
1. CloudFormationスタックの起動
CloudFormationテンプレートを使用して、プロビジョニングプロセスを自動化しテスト環境を起動します。次の入力パラメータでは、展開のためにターゲットVPCとサブネット(インターネットアクセスが必要)を識別する必要があります。ターゲットサブネットがインターネットゲートウェイを使用する場合は、AssignPublicIPパラメーターをtrueに設定します。ターゲットサブネットがNATゲートウェイを使用する場合は、AssignPublicIPのデフォルト設定をfalseのままにしておきます。
まず、デプロイしたリージョンにあるS3バケットにLambda Function 展開パッケージを配置する必要があります。これを行うには、圧縮された展開パッケージをダウンロードし、同じリージョンバケットにアップロードします。 S3へのオブジェクトのアップロードの詳細については、「Amazon S3へのオブジェクトのアップロード」を参照してください。
また、スタックの作成後に環境にアクセスするための信頼できる送信元IPアドレスまたはCIDRブロックと、インスタンスに関連付けるEC2キーペアを提供する必要があります。 EC2キーペアの作成については、「Amazon EC2を使用したキーペアの作成」を参照してください。また、信頼できるIPアドレスまたはCIDRブロックは、Kibanaアクセス用にAmazon ESアクセスポリシーの自動作成のために使用されます。すべてのIPv4アドレスがインスタンスにアクセスできるようにする0.0.0.0/0を使用するのではなく、特定のIPアドレスまたはCIDR範囲を使用することをお勧めします。インスタンスへのインバウンドトラフィックの認可の詳細については、「Linuxインスタンスのインバウンドトラフィックの認可」を参照してください。
入力パラメータを確認したら(詳細は次のスクリーンショットと表を参照)、CloudFormationスタックを作成します。

| Input parameter | インプット パラメータの説明 |
| 1. HIDSInstanceSize | テストサーバーのEC2インスタンスサイズ |
| 2. ESInstanceSize | Amazon ESインスタンスのサイズ |
| 3. MyKeyPair | デプロイ後にインスタンスに安全に接続できる公開鍵/秘密鍵のペア |
| 4. MyS3Bucket | ZIP展開パッケージを使用したS3バケット |
| 5. MyS3Key | ZIP展開パッケージ用の領域内のS3キー |
| 6. VPCId | ソリューションを展開するAmazon VPC |
| 7. SubnetId | 選択したVPC内のアウトバウンド接続を持つサブネットID(インターネットアクセスが必要) |
| 8. AssignPublicIP | サブネットがインターネットゲートウェイ経由で接続するように設定されている場合はtrueに設定します。サブネットがNATゲートウェイ経由で接続するように設定されている場合はfalseに設定されます |
| 9. MyTrustedNetwork | EC2インスタンスおよびAmazon ESエンドポイントへのアクセスをホワイトリストに登録するために使用される信頼できるソースIPまたはCIDRブロック |
CloudFormationスタックの作成を継続するには:
1. 入力パラメータを入力して、次へを選択します。
2. 「オプション」ページで、デフォルトを受け入れて「次へ」を選択します。
3. レビューページで詳細を確認し、AWS CloudFormationがIAMリソースを作成する可能性があることを確認します。チェックボックスをオンにし、作成を選択します。 (スタックは約10分で作成されます)。
スタックを作成したら、CloudFormation OutputsタブのHIDSESKibanaURLをメモしてください。そして次のKibanaの設定手順に進みます。
2.Kibanaのインデックスパターンを設定し、アラートの調査を開始
このセクションでは、Kibanaの初期セットアップを実行します。 Kibanaにアクセスするには、CloudFormationスタック出力(前のセクションを参照)でHIDSESKibanaURLを見つけて選択します。これにより、Amazon ESインスタンスに自動的にプロビジョニングされるKibanaインスタンスが表示されます。 CloudFormation入力パラメータで指定したソースIPを使用して、Amazon ESアクセスポリシーが自動的に設定されます。次のようなエラーが表示された場合は、Amazon ESのアクセスポリシーが正しいことを確認する必要があります。
Amazon ESドメインへのアクセスを保護する方法の詳細については、「Amazon Elasticsearchサービスドメインへのアクセスを制御する方法」を参照してください。
OSSEC HIDSアラートは現在Amazon ESに処理されています。 Kibanaを使用してアラートデータをインタラクティブに分析するには、Amazon ESで分析するデータを識別するインデックスパターンを設定する必要があります。索引パターンに関する追加情報は、Kibanaのドキュメントを参照してください。
インデックス名またはパターン ボックスに「cwl-2017.*」と入力します。インデックスパターンは、ラムダ関数内でcwl-YYYY.MM.DDとして生成されるため、月と日のワイルドカード文字を使用して2017のデータと一致させることができます。Time-field nameドロップダウンリストから@timestamp を選択し作成します。

Kibanaでは、ディスカバーペインを選択して、作成されているアラートを表示できるようになりました。リアルタイムに近いアラートの表示のリフレッシュレートを設定するには、右上の時間範囲(Last 15 minutesなど)を選択します。

自動更新を選択し、5秒などの間隔を選択します。

Kibanaでは、設定した時間枠内で5秒間隔で自動更新するように設定する必要があります。次のスクリーンショットに示すように、アラートがカウントグラフとともに更新されるはずです。

EC2インスタンスはCloudFormationによって自動的に設定され、アクティビティをシミュレートして次のようないくつかのタイプのアラートを表示します。
- 成功したsudoからROOT実行 :Linuxのsudoコマンドが正常に実行されました。
- Webサーバー400のエラー・コード : サーバーは、クライアント エラー(形式が不適切な要求構文、サイズが大きすぎる、無効なリクエスト・メッセージ・フレーミング、不正なリクエスト・ルーティングなど)によりリクエストを処理できません。
- SSHのセキュアでない接続試行(スキャン) : SSHリスナーへの無効な接続試行。
- ログインセッションが開かれました : システムでログインセッションが開かれました。
- ログインセッションが閉じられました : システムのログインセッションが閉じられました。
- 新しいYumパッケージがインストールされています : パッケージがシステムにインストールされています。
- Yumパッケージが削除されました : パッケージがシステムから削除されました。
次のスクリーンショットに示すように、いくつかのアラートフィールドを詳しく見ていきましょう。

上記番号付きアラートフィールド(スクリーンショット)は、次のように定義されています
1. @log_group – ソースとなるCloudWatch Logグループ
2. @log_stream – CloudWatchログのストリーム名(InstanceID)
3. @message – ソースalerts.jsonからのJSONペイロードOSSECログ
4. @owner – アラートが発生したAWSアカウントID
5. @timestamp – Lambda関数によって適用されるタイムスタンプ
6. full_log – ソースファイルからのログイベント
7. location – ソースログファイルのパスとファイル名
8. rule.comment – 一致したOSSECルールの簡単な説明
9. rule.level – 0から16までのOSSECルール分類(詳細は、ルール分類を参照)
10. rule.sidid – 一致したOSSECルールのルールID
11. srcip – アラートをトリガした送信元IPアドレス。この場合、シミュレートされたアラートにはサーバのローカルIPが含まれています
また、Kibanaクエリーバーに検索条件を入力して、HIDSアラートデータをインタラクティブに調べることができます。たとえば、次のクエリを実行すると、ソースIPが10.10.10.10であるEC2 InstanceID i-0e427a8594852eca2のすべてのrule.level 6アラートを表示できます。
シンプルテキスト、Luceneクエリ構文、またはJSONベースのElasticsearch Query DSLを使用して検索を実行できます。データの検索に関する追加情報は、Elasticsearchのドキュメントを参照してください。
3. Kibana HIDSダッシュボードの設定、アラートを視覚化
アラートの傾向とパターンを時間の経過とともに分析するには、グラフとグラフを使用してアラートデータを表現すると便利です。私はKibanaインスタンスにインポートできる基本ダッシュボードテンプレートを設定しました。
KibanaインスタンスにサンプルのHIDSダッシュボードのテンプレートを追加するには:
1. テンプレートを ローカルに保存し、Kibanaナビゲーションペインで[管理]を選択します。
2. 保存オブジェクト、インポート、およびHIDSダッシュボードテンプレートを選択します。
3. HIDSアラートダッシュボードエントリの右側にある目のアイコンを選択します。インポートされたダッシュボードに移動します。

Kibanaダッシュボードテンプレートをインポートして選択すると、次のスクリーンショットに示すように、HIDSダッシュボードが表示されます。このサンプルHIDSダッシュボードには、アラートの時間、アラートの種類、ルールレベルの内訳、上位10のルールソースID、および上位10のソースIPが含まれています。

アラートデータを詳細に調べるには、次の2つのスクリーンショットに示すように、フィルタするアラートタイプを選択します。


ソースIPアドレスや時間範囲などの基準に基づいてアラートの詳細を表示できます。 Kibanaを使用してアラートデータを視覚化する方法の詳細については、「Kibanaユーザーガイド」を参照してください。
まとめ
このブログ記事では、CloudWatch Logs を使用してOSSEC HIDSからほぼリアルタイムでアラートを収集し、CloudWatch Logsサブスクリプションを使用して、Kibanaとの分析と可視化のためにアラートをAmazon ESに渡す方法を示しました。このソリューションによってデプロイされたダッシュボードは、AWS環境における防御の深いセキュリティ戦略の一環として、EC2のセキュリティ監視を改善するのに役立ちます。
このソリューションを使用して、EC2への攻撃、異常な活動、およびエラーの傾向を検出することができます。また、システムの修復作業の優先順位付けや、VPCセキュリティグループルール、VPCネットワークACL、AWS WAFルールなど、追加のセキュリティコントロールを導入する場所を決定するのに役立ちます。
この投稿に関するコメントがある場合は、下の「コメント」セクションに追加してください。このソリューションの実装に関する問題や問題がある場合は、CloudWatchまたはAmazon ESフォーラムで新しいスレッドでお知らせ下さい。このソリューションのソースコードはGitHubで入手できます。 OSSEC固有のサポートが必要な場合は、「OSSECサポートオプション」を参照してください。
– Cameron (翻訳はSA酒徳が担当しました。原文はこちら:How to Monitor Host-Based Intrusion Detection System Alerts on Amazon EC2 Instances)
Amazon Elasticsearch Service が Elasticsearch 5.1 をサポート
Amazon Elasticsearch Service は、オープンソース検索および分析エンジンである Elasticsearch を容易にデプロイ、運用、拡張できるようにするマネージド型サービスです。このたび Amazon Elasticsearch Service で Elasticsearch 5.1 および Kibana 5.1 がサポートされるようになったことを、ここにお知らせいたします。Elasticsearch 5 は非常に多くの新機能と機能拡張を備えており、Amazon Elasticsearch Service をご利用のお客様はそれらを活用いただけるようになりました。今回の Elasticsearch 5 のリリースには、次のような内容が含まれています。
- インデックス作成のパフォーマンス: ロックの実装の更新および非同期のトランザクションログ FSYNC による、インデックス作成のスループットの向上
- 取り込みパイプライン: 受信データは一連の取り込みプロセッサを適用するパイプラインに送信できます。これにより検索インデックスに必要なデータに正確に変換できます。単純な付加アプリケーションから複雑な正規表現アプリケーションまで、20 個のプロセッサが含まれています
- Painless スクリプティング: Amazon Elasticsearch Service は Elasticsearch 5 のための新しい安全でパフォーマンスに優れたスクリプト言語である、Painless をサポートします。スクリプト言語を使用すると、検索結果の優先順位を変更したり、クエリでインデックスフィールドを削除したり、検索結果を修正して特定のフィールドを戻したりすることができます。
- 新しいデータ構造: 新しいデータ型である Lucene 6 データ構造をサポートし、半精度浮動小数点、テキスト、キーワード、さらにピリオドが含まれるフィールド名を完全にサポートします
- 検索と集計: リファクタリング検索 API、BM25 関連性計算、Instant Aggregations、ヒストグラム集計と用語集計の機能強化、再設計されたパーコレーターと完了サジェスタ
- ユーザーエクスペリエンス: 厳密な設定、本文とクエリ文字列パラメーターの検証、インデックス管理の向上、デフォルトで廃止予定のログを記録、新しい共有割り当て API、ロールオーバーと圧縮 API のための新しいインデックス効率パターン
- Java REST クライアント: Java 7 で稼働してノード障害時に再試行 (またはラウンドロビン、スニッフィング、要求のログ記録) を処理するシンプルな HTTP/REST Java クライアント
- その他の向上: 遅延ユニキャストのホスト DNS ルックアップ、再インデックス作成の自動並列タスク、update-by-query、delete-by-query、タスク管理 API による検索のキャンセル
Elasticsearch 5 による強力な新機能や機能強化により、サービスをより迅速に、より容易に提供することができ、さらにセキュリティの強化を図ることができます。マネージド型サービスである Amazon Elasticsearch Service を使うと、お客様は Elasticsearch による次のような機能を活用して、ソリューションを構築、開発、デプロイすることができます。
- 複数のインスタンスタイプを設定
- データストレージに Amazon EBS ボリュームを使用
- 専用マスターノードによるクラスターの安定性の向上
- ゾーン対応 – 同じリージョン内の 2 つのアベイラビリティーゾーンにまたがるクラスターノード割り当て
- AWS Identity and Access Management (IAM) によるアクセスコントロールとセキュリティ
- リソース用にさまざまな地理的場所やリージョンを活用
- Amazon Elasticsearch ドメインのスナップショットによるレプリケーション、バックアップ、リストア
- Amazon CloudWatch との統合による Amazon Elasticsearch ドメインメトリクスのモニタリング
- AWS CloudTrail との統合による設定の監査
- Kinesis Firehose および DynamoDB などの他の AWS のサービスとの統合による、リアルタイムストリーミングデータの Amazon Elasticsearch Service への読み込み
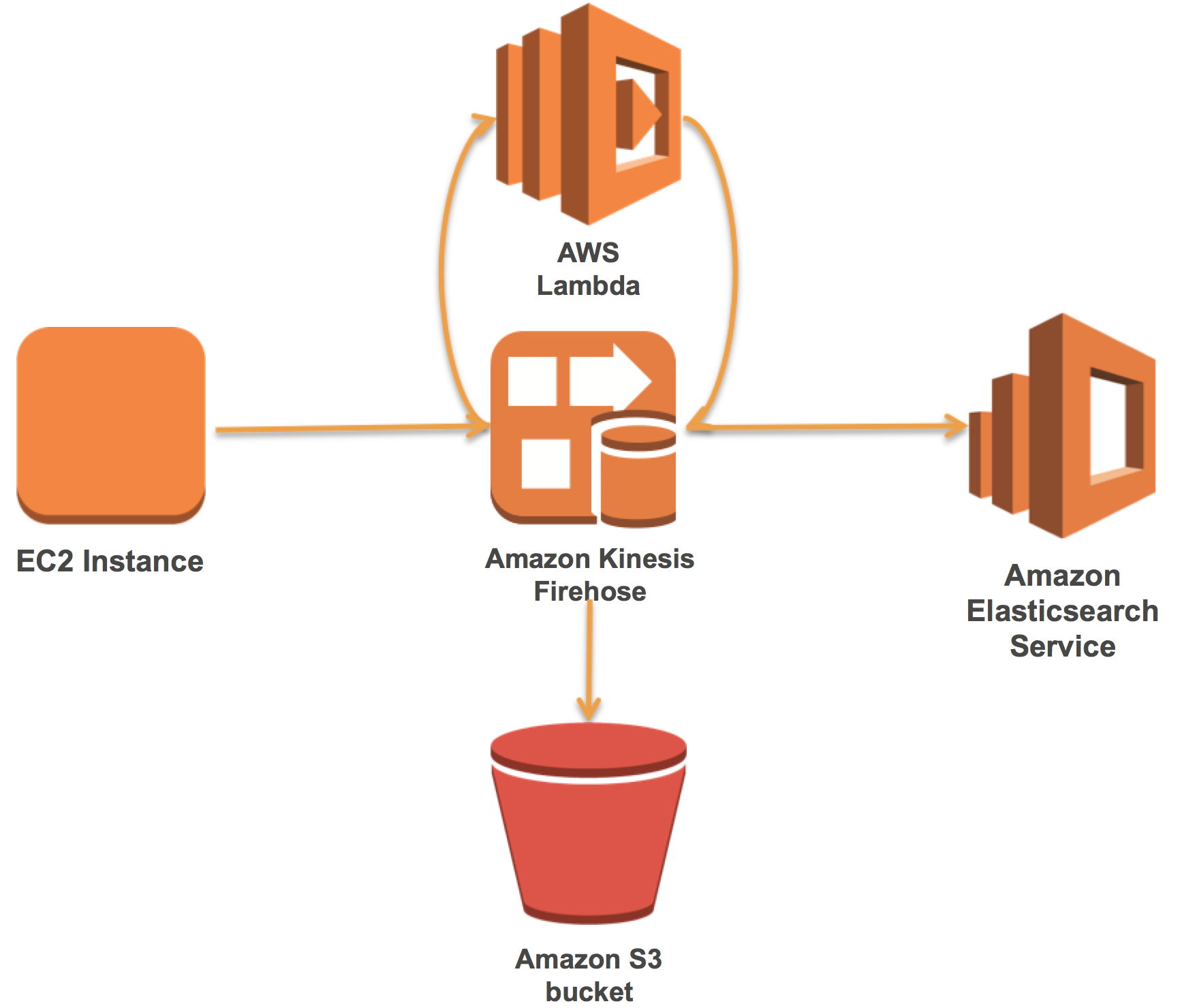
Amazon Elasticsearch Service では、ダウンタイムなしで動的な変更を行うことができます。インスタンスの追加、インスタンスの削除、インスタンスのサイズの変更、ストレージ設定の変更、その他の変更を動的に行うことができますい。上記の機能のいくつかについて、その機能を具体例でご紹介します。先日の IT/Dev カンファレンスでは、Express.js、AWS Lambda、Amazon DynamoDB、および Amazon S3 を使用して、サーバレスで従業員オンボーディングシステムを構築する方法の説明を、プレゼンテーションさせていただきました。このデモでは、架空のオンボーディングプロセス用の従業員に関する人事データを収集して、DynamoDB に保存しました。収集された従業員データを、会社の人事部門が必要に応じて検索、照会、分析するシナリオを考えてみます。オンボーディングシステムを容易に拡張して、従業員テーブルが DynamoDB Streams を使用して Lambda を起動するようにし、必要な従業員の属性を Amazon Elasticsearch Service に保存することができます。この結果、次のようなソリューションアーキテクチャとなります。
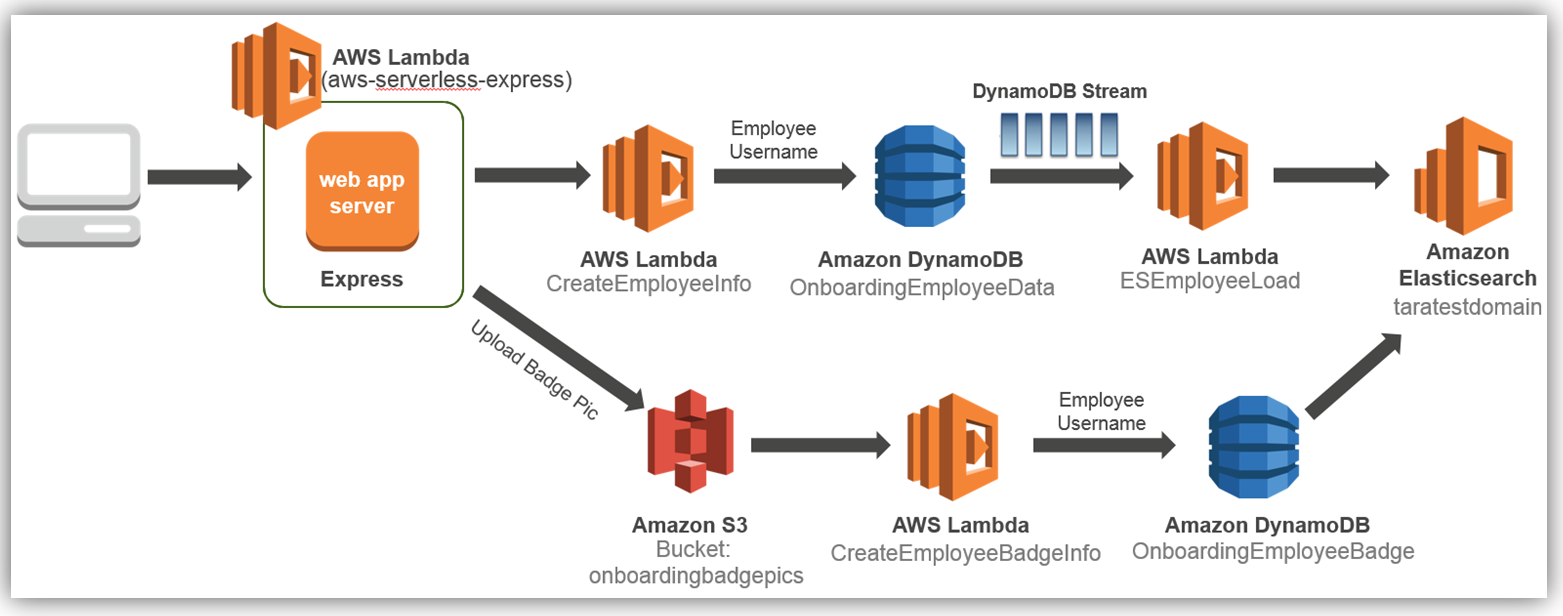
従業員レコードが入力されてデータベースに保存されるたびに、従業員データを Amazon Elasticseach Service に動的に保存してインデックスを作成する方法のみに焦点を当てます。前述の既存のオンボーディングソリューションにこの拡張機能を追加するには、以下の詳細なクラウドアーキテクチャ図に示すように、ソリューションを実装します。
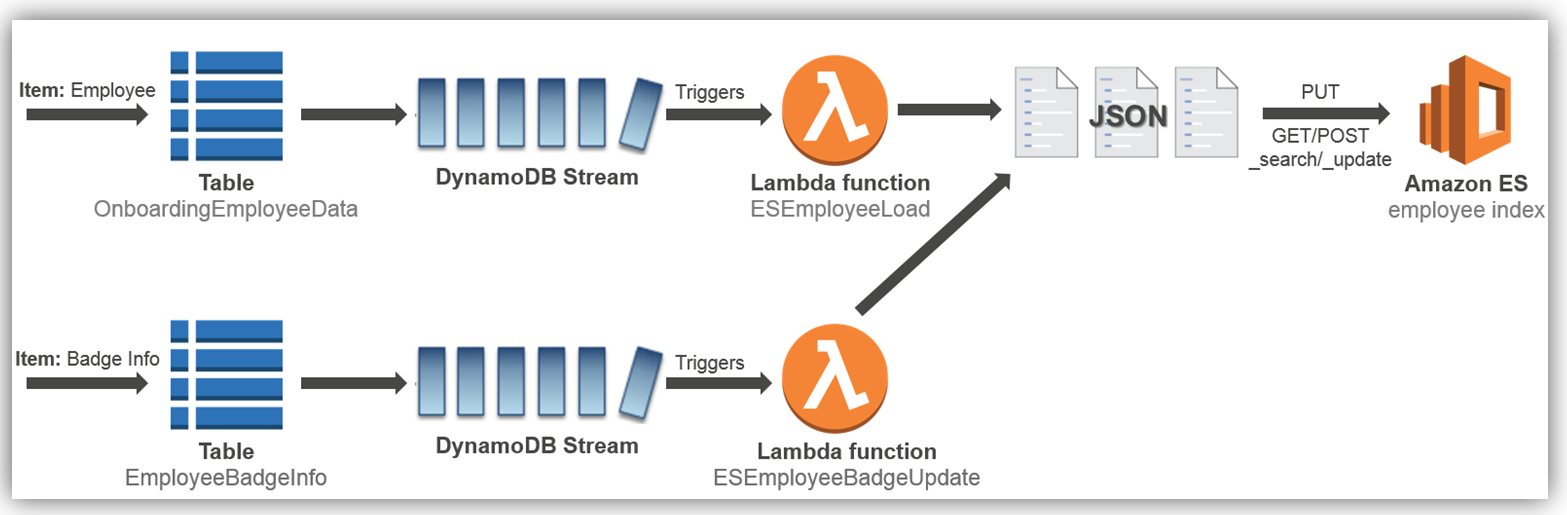
従業員の Amazon Elasticsearch Service へのロードプロセスを実装する方法を見てみましょう。これは上の図に示されている最初のプロセスフローです。Amazon Elasticsearch Service: ドメイン作成 AWS コンソールにアクセスして、Elasticsearch 5 が実行されている Amazon Elasticsearch Service を確認しましょう。ご想像どおり、AWS コンソールのホームから [分析] グループの [Elasticsearch Service] を選択します。
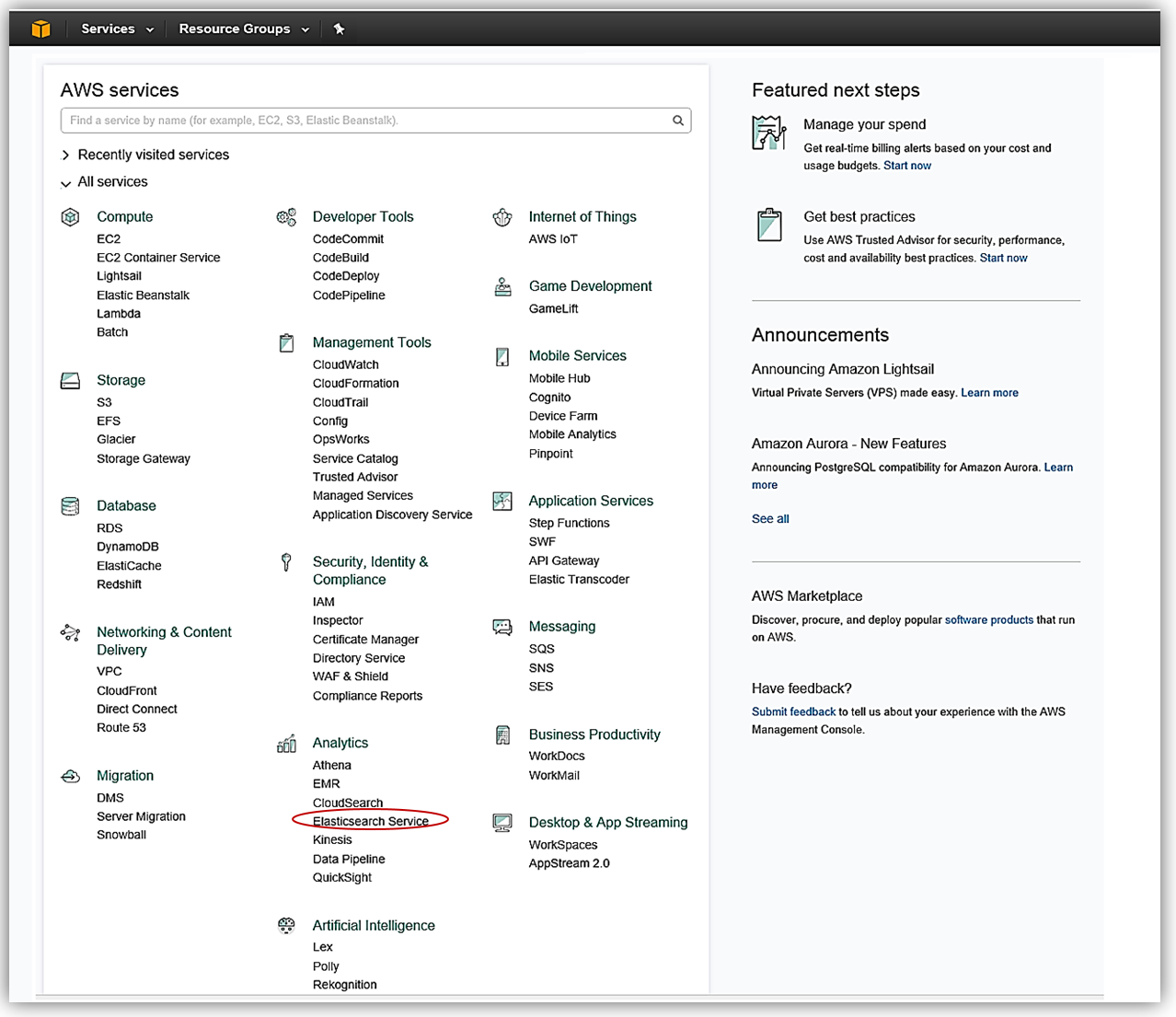
Elasticsearch ソリューションを作成するための最初のステップは、ドメインの作成です。お気付きのとおり、Amazon Elasticsearch Service ドメインの作成時に Elasticsearch 5.1 バージョンを選択できるようになりました。今日の本題は Elasticsearch 5 のサポート開始ですので、Amazon Elasticsearch Service でのドメイン作成にあたり、もちろん 5.1 Elasticsearch エンジンのバージョンを選択します。
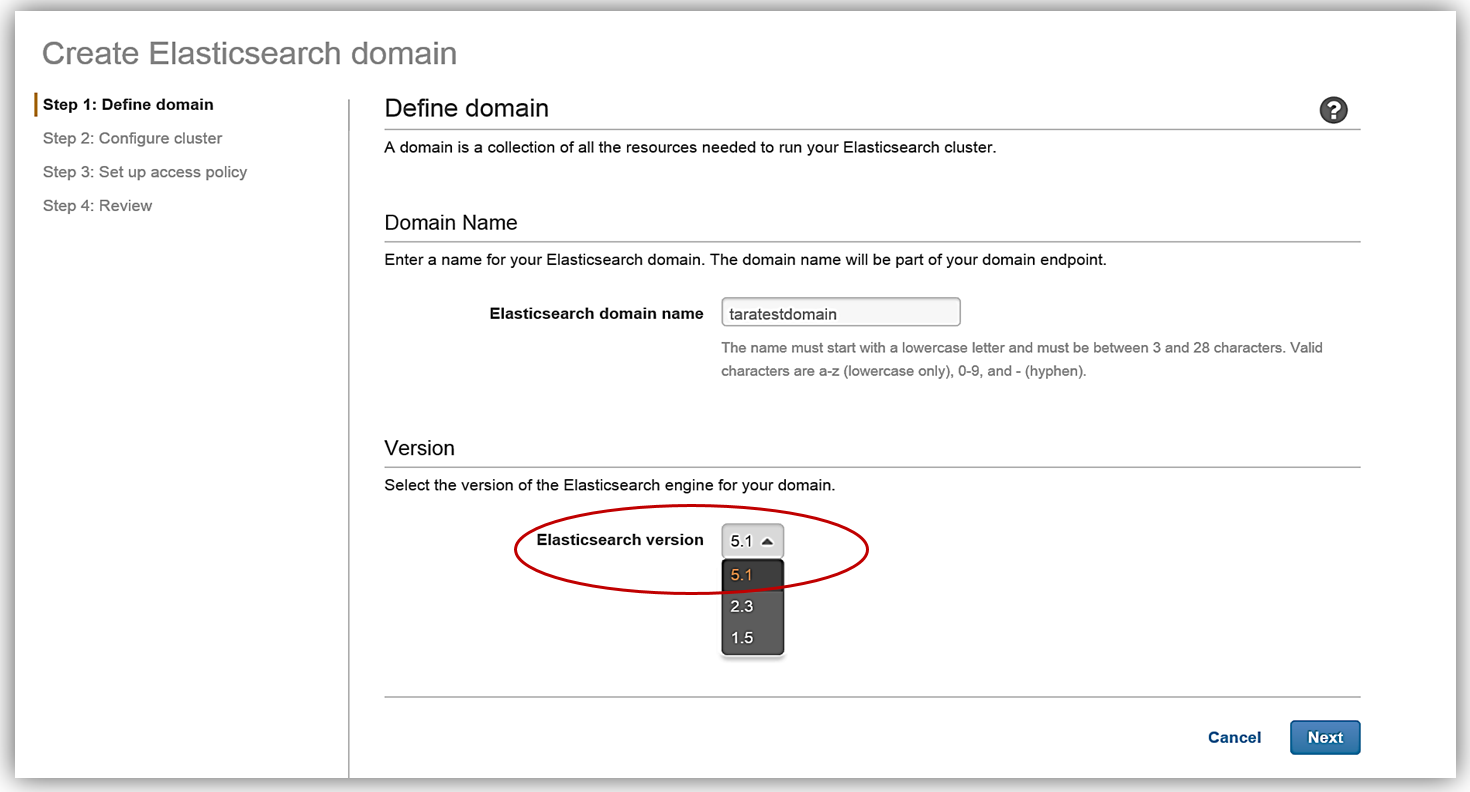
[Next] をクリックし、インスタンスとストレージの設定を構成して、Elasticsearch ドメインを設定します。クラスターのインスタンスタイプとインスタンス数は、アプリケーションの可用性、ネットワークボリューム、およびデータのニーズに基づいて決定する必要があります。データの不整合や Elasticsearch のスプリットブレインの問題を回避するために、複数のインスタンスを選択することが推奨されるベストプラクティスです。そこで、今回はクラスター用に 2 つのインスタンス/データノードを選択し、EBS をストレージデバイスとして設定します。
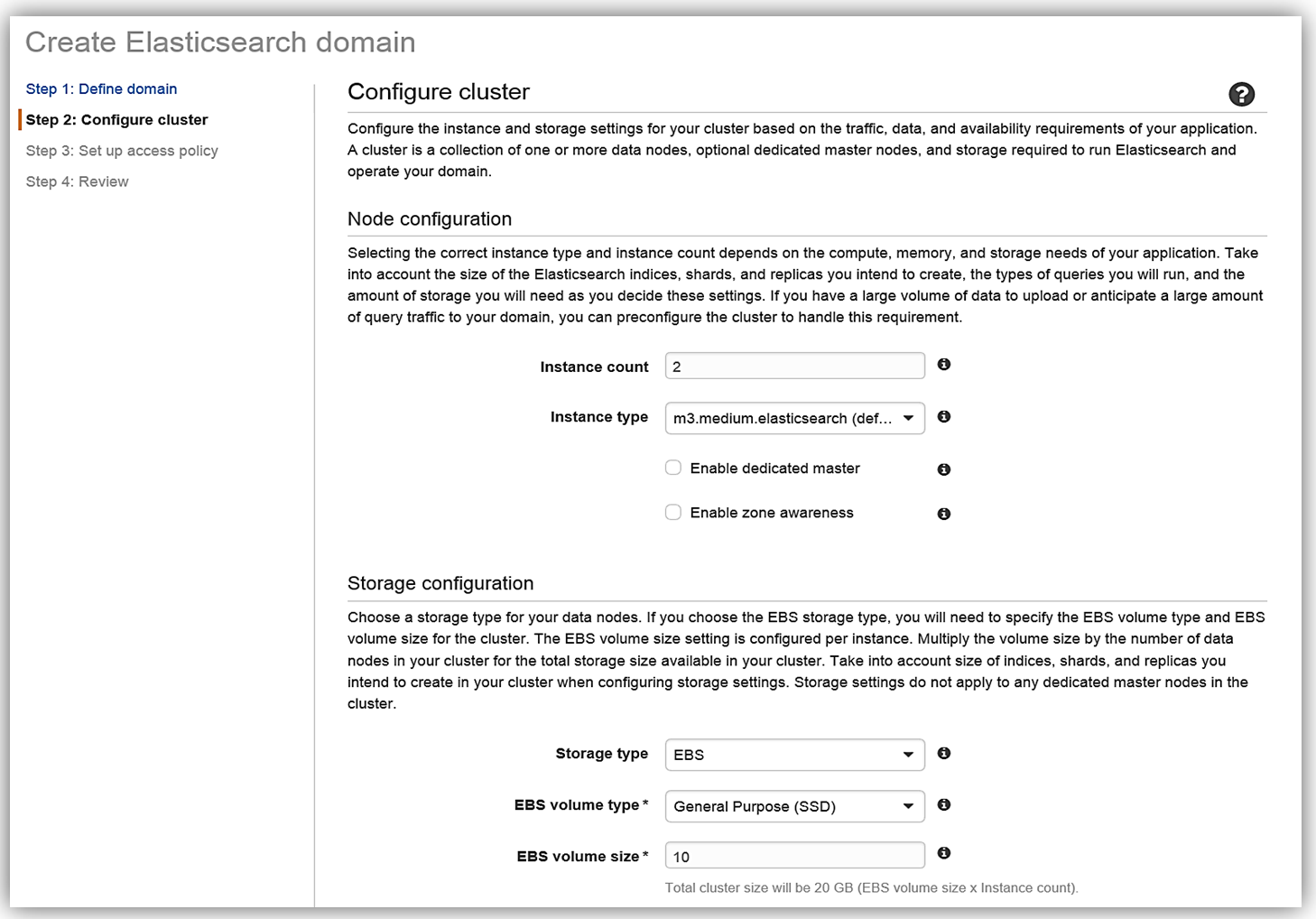
具体的なアプリケーションに必要なインスタンスの数を理解するには、AWS データベースブログの「Get Started with Amazon Elasticsearch Service: How Many Data Instances Do I Need (Amazon Elasticsearch Service をはじめよう: 必要なインスタンス数の算出方法)」の記事を参照してください。あと必要なのは、アクセスポリシーを設定してサービスをデプロイするだけです。サービスを作成すると、ドメインが初期化され、デプロイされます。
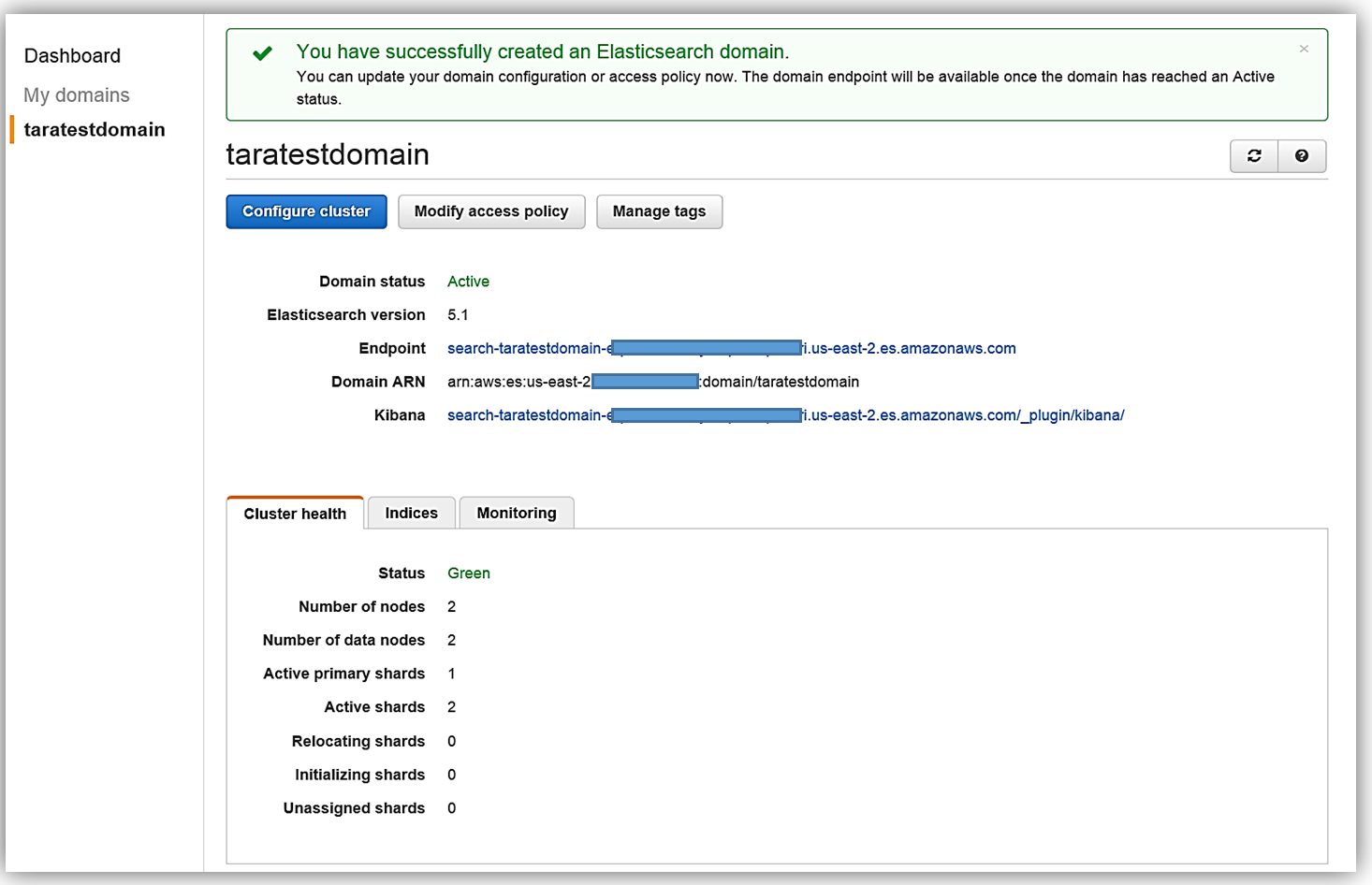
これで Elasticsearch Service を実行することができました。次は、データを入力するメカニズムが必要です。DynamoDB Streams を使用して、Amazon Elasticsearch Service への従業員データの動的なデータロードプロセスを実装します。Amazon DynamoDB: テーブルとストリーム DynamoDB コンソールに着手する前に、まずは基本を簡単に確認しましょう。 Amazon DynamoDB はスケーラブルな分散 NoSQL データベースサービスです。DynamoDB Streams は、すべての CRUD オペレーションの順序付けられた時間ベースのシーケンスを DynamoDB テーブル内の項目に提供します。各ストリームレコードには、テーブル内の個々の項目のプライマリ属性の変更に関する情報が含まれています。ストリームは非同期で実行され、実質的にリアルタイムでストリームレコードを書き込むことができます。さらに、ストリームはテーブルの作成時に有効にでき、また既存のテーブルで有効にして変更することができます。DynamoDB Streams の詳細については、「DynamoDB 開発者ガイド」を参照してください。それでは DynamoDB コンソールから、OnboardingEmployeeData デーブルを確認しましょう。
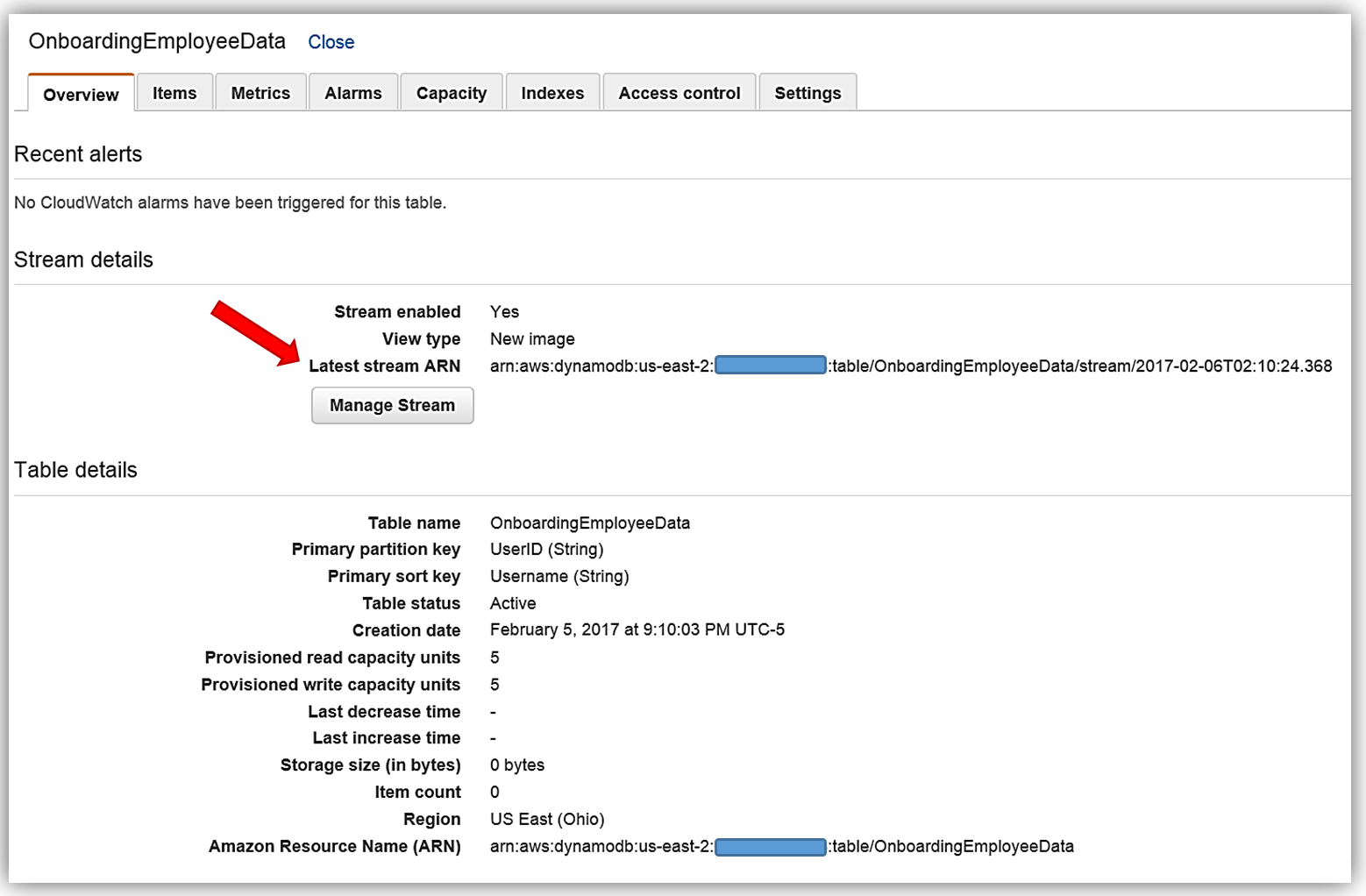
このテーブルには、プライマリパーティションキー UserID があり、これは文字列データ型です。さらにプライマリソートキー Username があり、これも文字列データ型です。ここでは UserID を Elasticsearch のドキュメント ID として使用します。さらにこのテーブルではストリームが有効で、ストリームの表示タイプは New image です。表示タイプが New image に設定されたストリームには、更新された後に項目レコード全体を表示するストリームレコードがあります。ストリームが、変更前のデータ項目を提供するレコードを表示するようにすることもできます。また項目のキー属性のみを提供したり、古い項目と新しい項目の情報を提供したりすることもできます。AWS CLI を使用して DynamoDB テーブルを作成する場合、取得するキー情報は [Stream Details] セクションの下に表示される 最新のストリーム ARN です。DynamoDB ストリームには一意の ARN 識別子があります。これは DynamoDB テーブルの ARN の外にあります。ストリーム ARN は、ストリームと Lambda 関数の間のアクセス権限の IAM ポリシーを作成するために必要です。

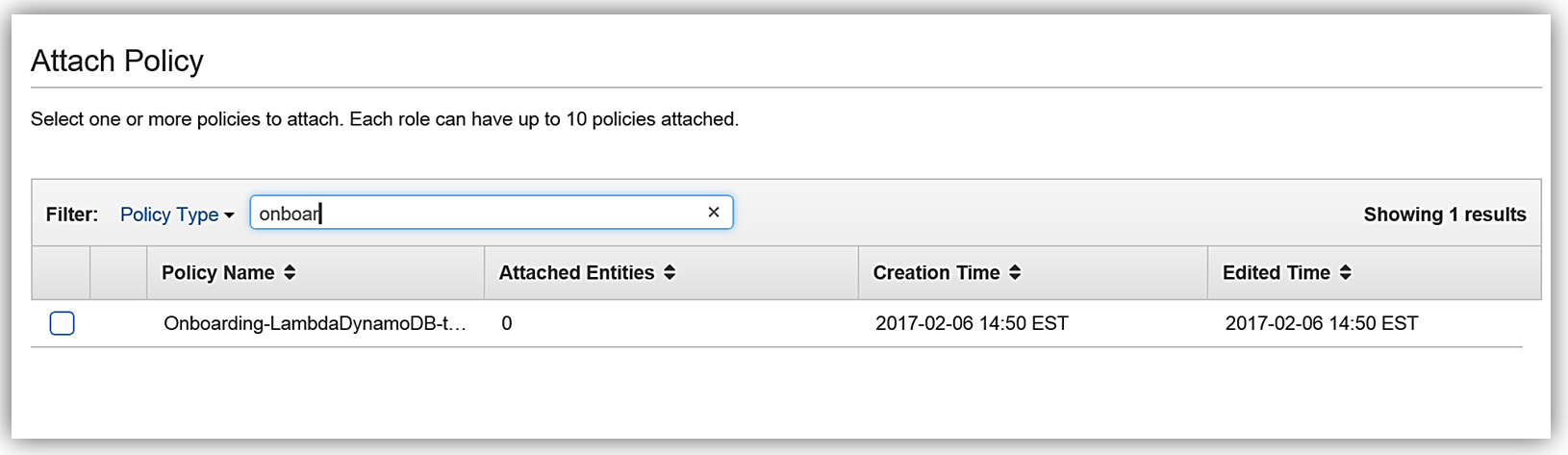
IAM ポリシー あらゆるサービスの実装で第一に重要なことは、適切なアクセス権限を設定することです。このため、まずは IAM コンソールを使って、DynamoDB と Elasticsearch にアクセス権限を設定する、Lambda 関数のロールとポリシーを作成します。まず、DynamoDB ストリームを使用した Lambda の実行のための既存の管理ポリシーに基づくポリシーを作成します。
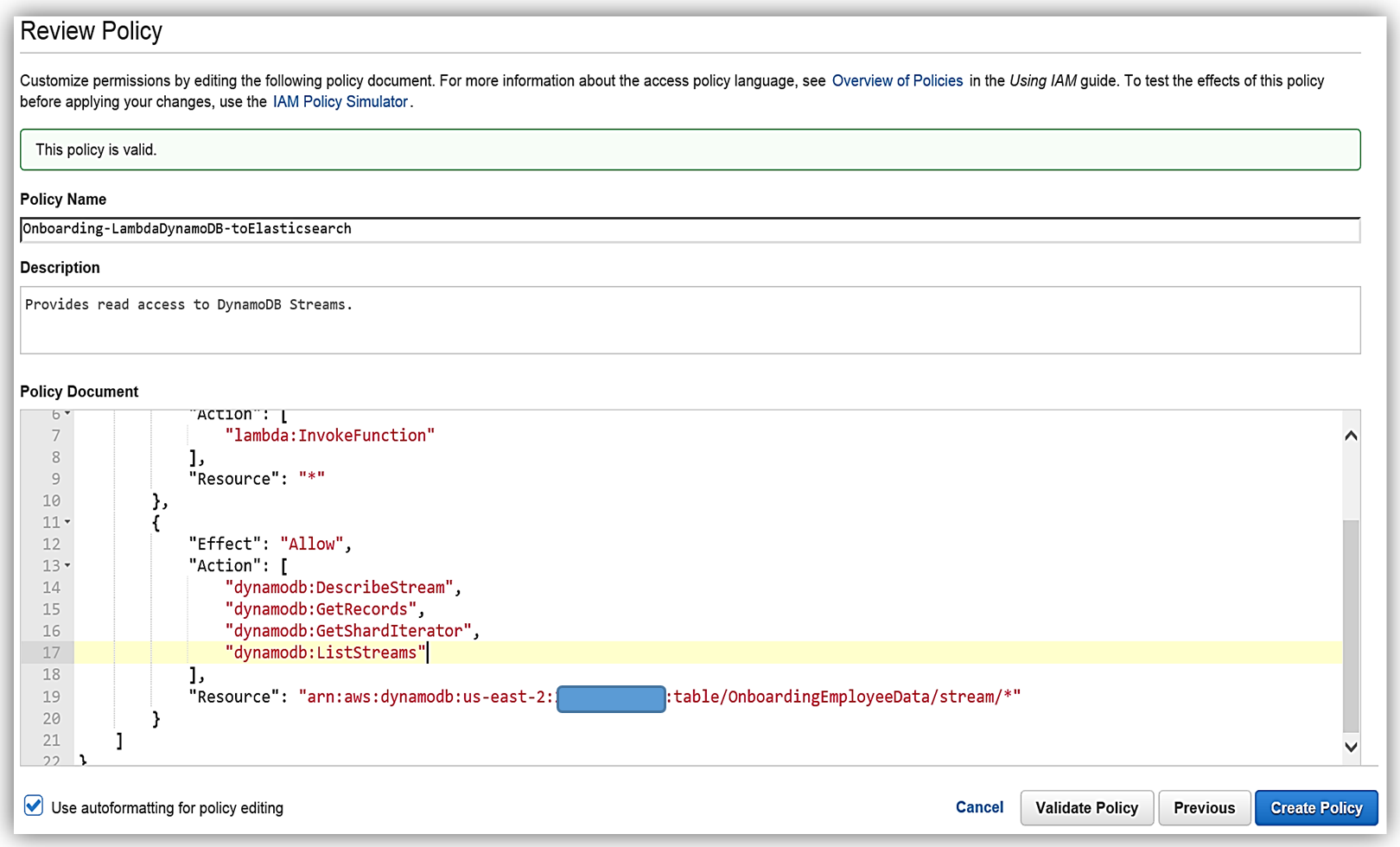
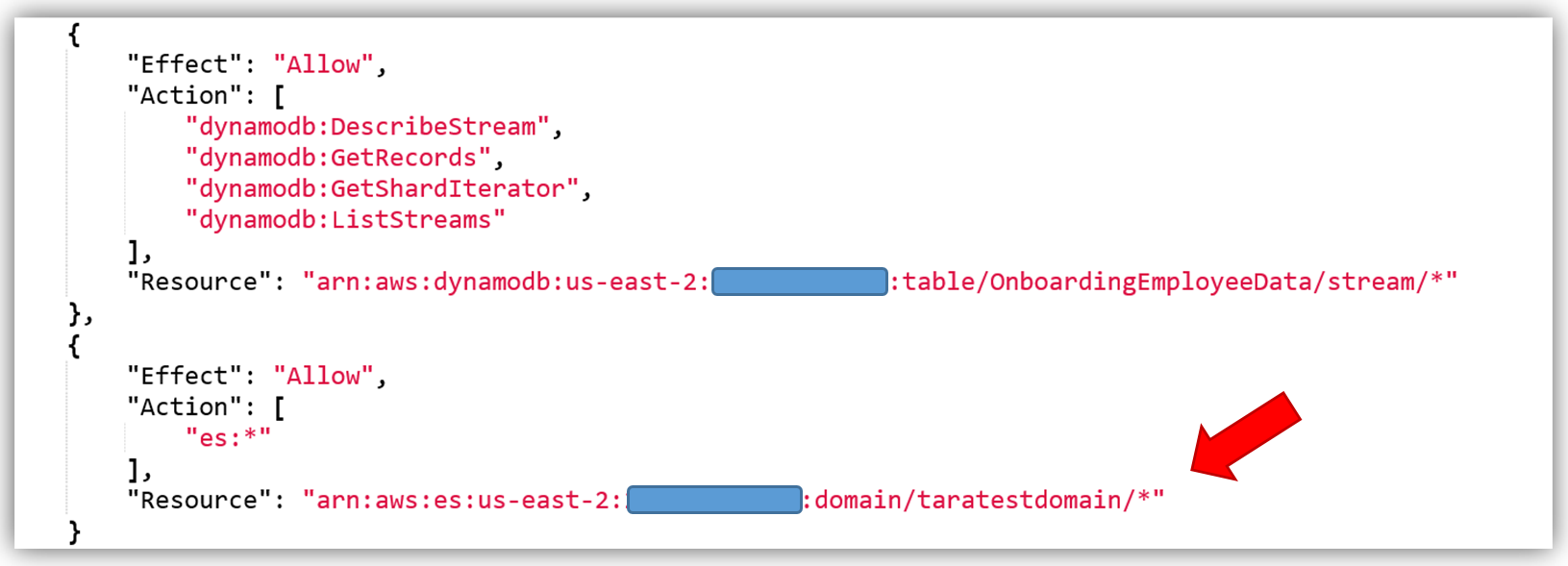
すると次にポリシーの確認画面に移ります。ここでは選択された管理ポリシーの詳細が表示されます。ここでは、このポリシーの名前を Onboarding-LambdaDynamoDB-toElasticsearch として、ソリューション用にポリシーのカスタマイズを行います。現在のポリシーでは、すべてのストリームがアクセス可能であることに注意します。推奨されるベストプラクティスは、最新のストリーム ARN を追加して、このポリシーで特定の DynamoDB ストリームのみがアクセスできるようにすることです。ポリシーを変更して、DynamoDB テーブル OnboardingEmployeeData に ARN を追加し、ポリシーを検証します。変更されたポリシーは次のようになります。
あとは、Amazon Elasticsearch Service のアクセス権限をポリシーに追加するだけです。Amazon Elasticsearch Service のアクセス権限のコアポリシーは次のとおりです。

このポリシーを使って、特定の Elasticsearch ドメインの ARN を、ポリシーのリソースとして追加します。これにより、ポリシーのセキュリティのベストプラクティスである、最小権限の原則を適用したポリシーを活用することができます。次のように Amazon Elasticsearch Service ドメインを追加して、ポリシーを検証して保存します。
カスタムポリシーを作成する最も望ましい方法は、IAM Policy Simulator を使用するか、またはサービスドキュメントの AWS のサービスのアクセス権限の例を参照することです。AWS のサービスのサブセットのポリシーの例については、こちらを参照することもできます。最小権限の原則によるセキュリティのベストプラクティスを適用して、必要な ES のアクセス権限のみを追加してください。上記は単なる一例です。アクセスを許可するために Lambda 関数が使用するロールを作成し、そのロールに前述のポリシーをアタッチします。
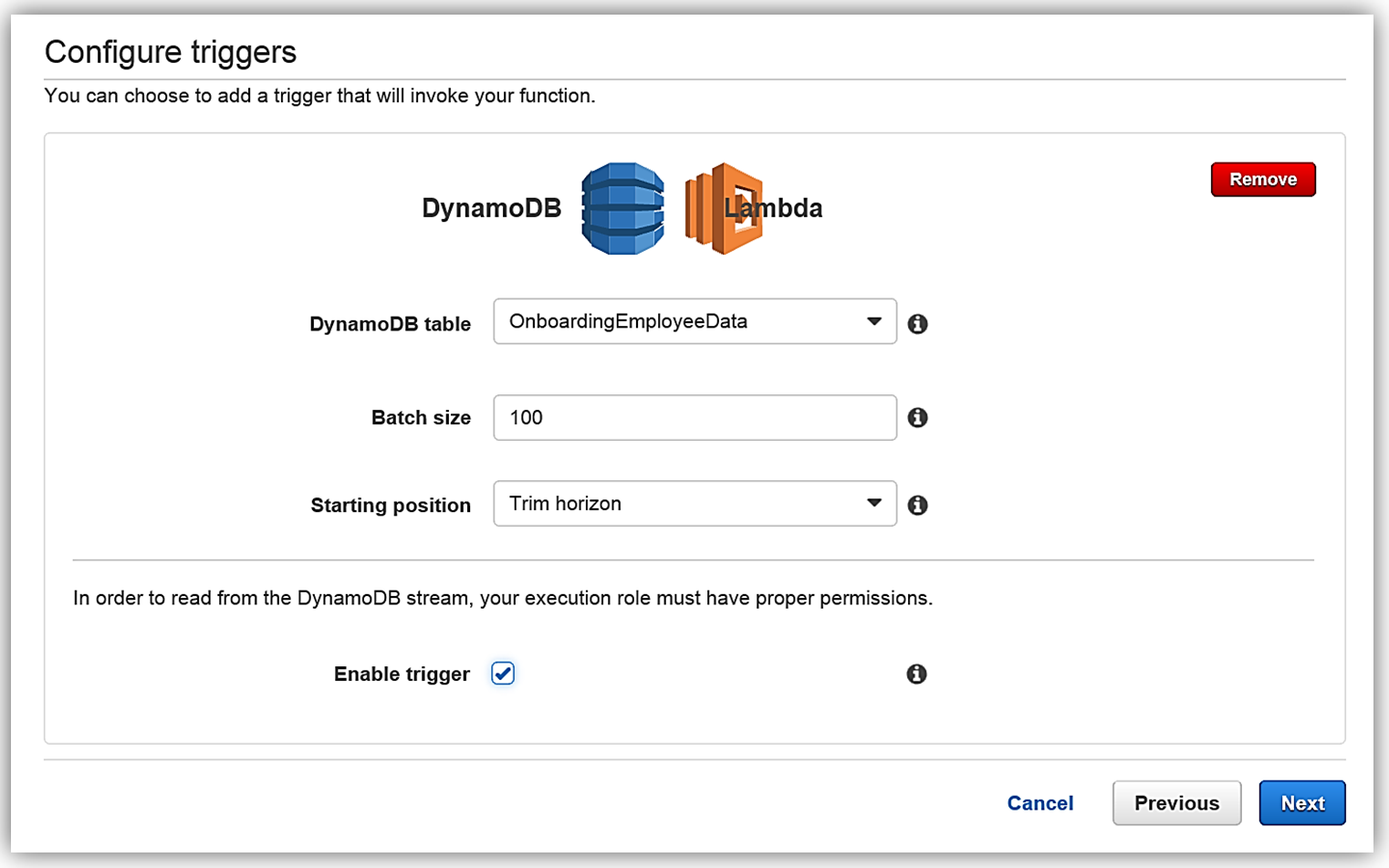
AWS Lambda: DynamoDB がトリガーする Lambda 関数 AWS Lambda は、アマゾン ウェブ サービスのサーバーレスコンピューティングサービスの中心となるものです。Lambda を使うと、サポートされた言語を使って、事実上あらゆる種類のアプリケーションやバックエンドサービスのコードを作成して実行できます。Lambda は、AWS のサービスまたは HTTP リクエストからのイベントに対応して、コードをトリガーします。Lambda はワークロードに基づいて動的にスケールします。コードの実行に対してのみ料金を支払います。DynamoDB ストリームが Lambda 関数をトリガーし、それによりインデックスが作成され、データが Elasticsearch に送信されます。もう 1 つの方法は、DynamoDB の Logstash プラグインを使用することです。ただし、Logstash プロセッサのいくつかは Elasticsearch 5.1 コアに組み込まれ、さらにパフォーマンスの最適化が向上されているため、今回は Lambda を使用して DynamoDB ストリームを処理し、Amazon Elasticsearch Service にデータをロードすることにします。では AWS Lambda コンソールを使って、Amazon Elasticsearch Service に従業員データをロードするための Lambda 関数を作成しましょう。コンソールでブランク関数設計図を選択して、新しい Lambda 関数を作成します。次に [Configure Trigger] ページに移ります。トリガーページで、Lambda をトリガーする AWS のサービスとして DynamoDB を選択し、トリガー関連オプションとして次のように入力します。
- テーブル: OnboardingEmployeeData
- バッチサイズ: 100 (デフォルト)
- 開始位置: 水平トリム
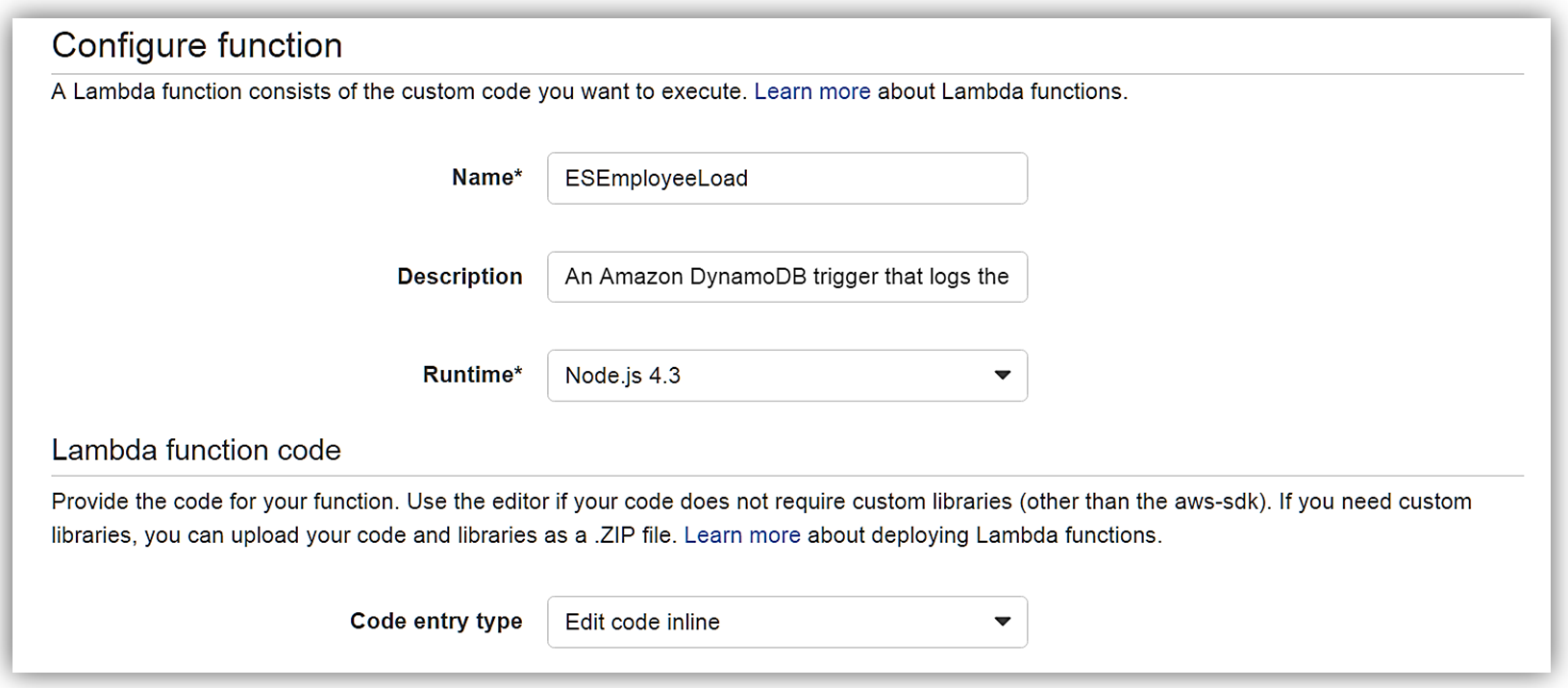
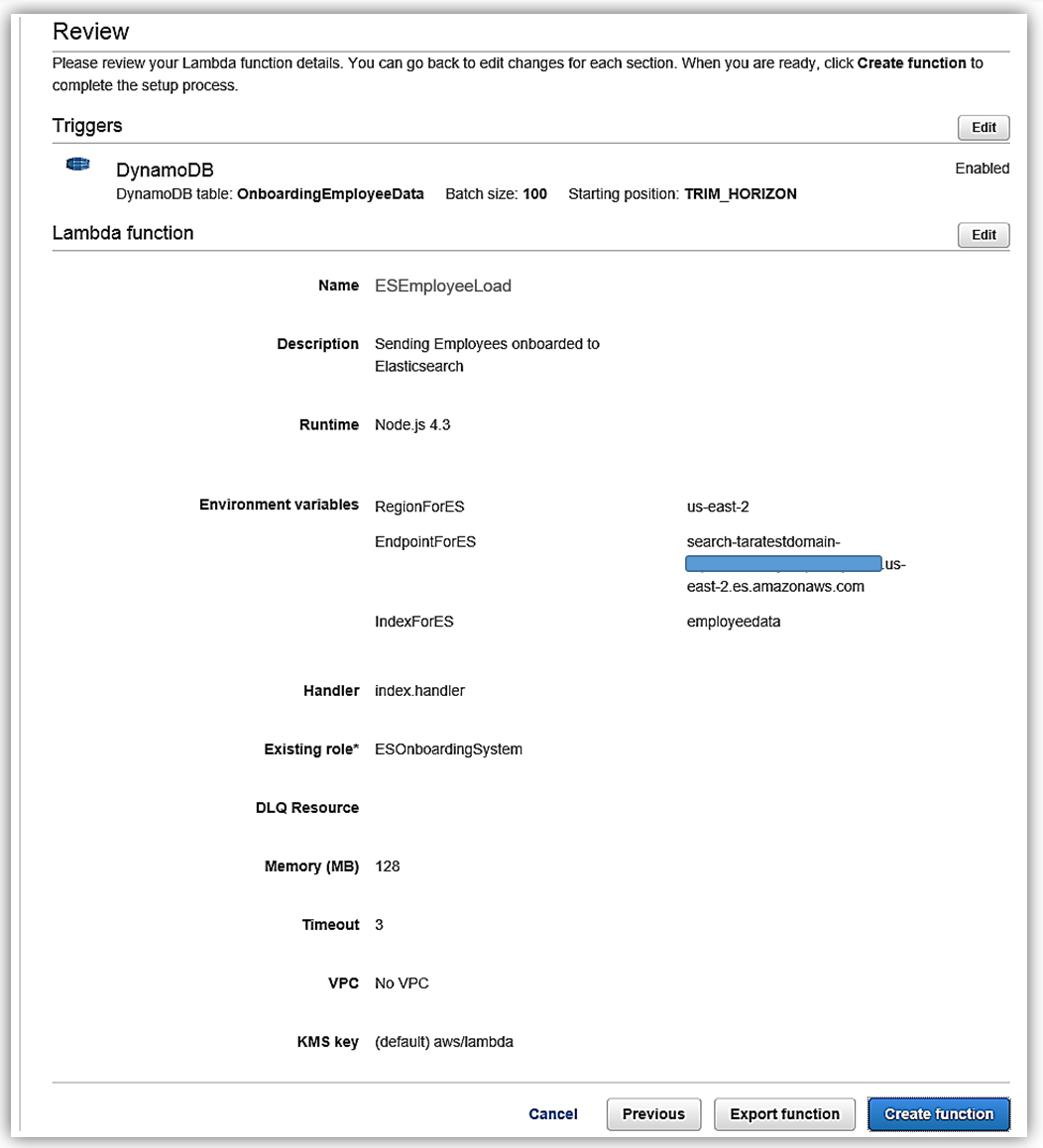
[Next] をクリックすると、関数の設定画面に移動します。関数の名前を ESEmployeeLoad とし、この関数を Node.4.3 で作成します。
Lambda 関数のコードは次のとおりです。
var AWS = require('aws-sdk');
var path = require('path');
//すべての ElasticSearch ドメイン情報のオブジェクト
var esDomain = {
region: process.env.RegionForES,
endpoint: process.env.EndpointForES,
index: process.env.IndexForES,
doctype: 'onboardingrecords'
};
//作成された ES ドメインエンドポイントからの AWS エンドポイント
var endpoint = new AWS.Endpoint(esDomain.endpoint);
//AWS 認証情報は環境から取得される
var creds = new AWS.EnvironmentCredentials('AWS');
console.log('Loading function');
exports.handler = (event, context, callback) => {
//console.log('Received event:', JSON.stringify(event, null, 2));
console.log(JSON.stringify(esDomain));
event.Records.forEach((record) => {
console.log(record.eventID);
console.log(record.eventName);
console.log('DynamoDB Record: %j', record.dynamodb);
var dbRecord = JSON.stringify(record.dynamodb);
postToES(dbRecord, context, callback);
});
};
function postToES(doc, context, lambdaCallback) {
var req = new AWS.HttpRequest(endpoint);
req.method = 'POST';
req.path = path.join('/', esDomain.index, esDomain.doctype);
req.region = esDomain.region;
req.headers['presigned-expires'] = false;
req.headers['Host'] = endpoint.host;
req.body = doc;
var signer = new AWS.Signers.V4(req , 'es'); // es: サービスコード
signer.addAuthorization(creds, new Date());
var send = new AWS.NodeHttpClient();
send.handleRequest(req, null, function(httpResp) {
var respBody = '';
httpResp.on('data', function (chunk) {
respBody += chunk;
});
httpResp.on('end', function (chunk) {
console.log('Response: ' + respBody);
lambdaCallback(null,'Lambda added document ' + doc);
});
}, function(err) {
console.log('Error: ' + err);
lambdaCallback('Lambda failed with error ' + err);
});
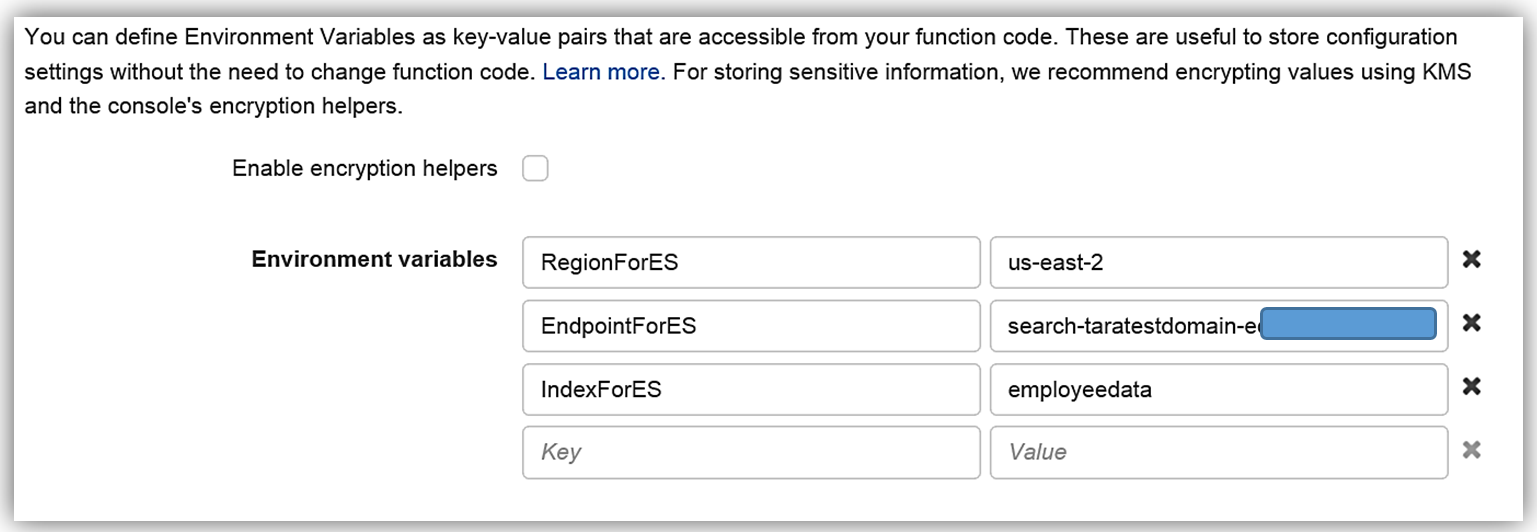
}Lambda 関数の環境変数は次のとおりです。
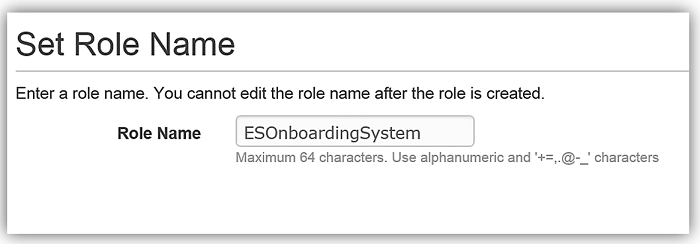
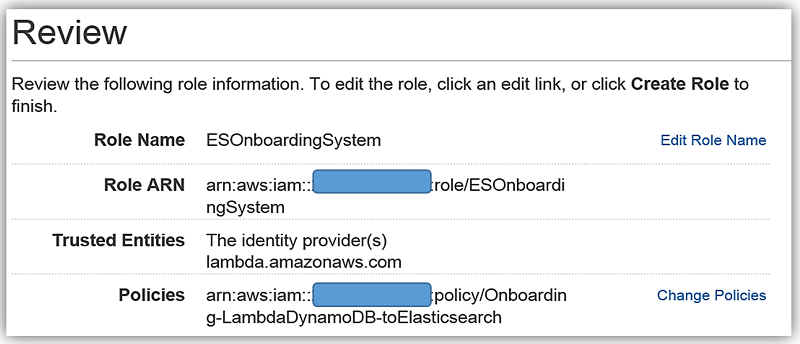
既存のロールのオプションで ESOnboardingSystem を選択します。これは先に作成した IAM ロールです。
Lambda 関数のための IAM ロールのアクセス権限を完成したら、Lambda 関数の詳細を確認し、ESEmployeeLoad 関数の作成を完了します。
Elasticsearch との通信を行う Lambda 関数の構築プロセスは、これで完了です。では、データベースへのデータ変更のシミュレーションを行って、関数のテストを行いましょう。
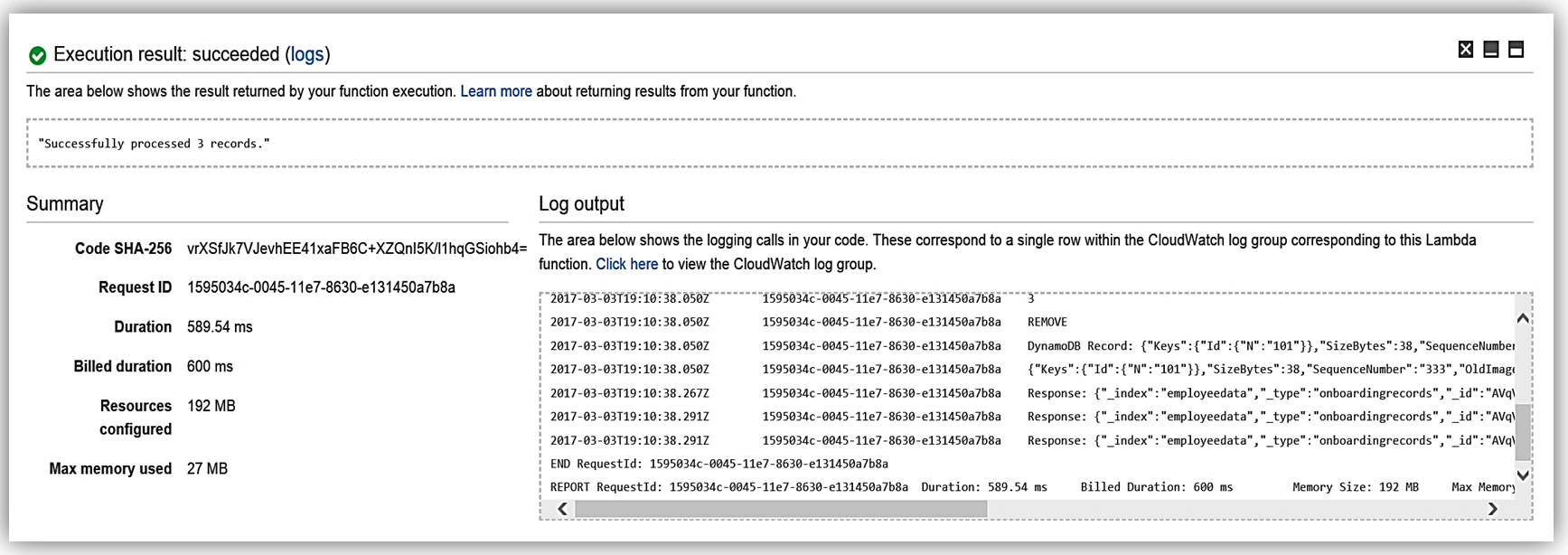
関数 ESEmployeeLoad は、オンボーディングシステムのデータベースでのデータの変更により実行されます。また、CloudWatch ログを確認することにより、Lambda 関数の Elasticsearch への処理を確認できます。さらに Lambda 関数を変更して新機能を利用したり、直接 Elasticsearch を使って新しい取り込みモードを利用することもできます。たとえば、従業員レコードドキュメントのパイプラインを実装することができます。

この関数を複製して、従業員レコードに合わせてバッジを更新する処理や、従業員データに対するその他のプリプロセッサを活用したりすることができます。たとえば、Elasticsearch ドキュメントのデータパラメーターに基づいてデータを検索する場合、検索 API を使用してデータセットからレコードを取得できます。


可能性は無限です。データのニーズに応じて創造性を発揮しながら、優れたパフォーマンスを確保できます。Amazon Elasticsearch Service: Kibana 5.1 Elasticsearch 5.1 を使用しているすべての Amazon Elasticsearch Service ドメインでは、オープンソースの可視化ツールの最新バージョンである Kibana 5.1 が備えられています。可視化と分析のための補完プラットフォームである Kibana も、Kibana 5.1 リリースで機能強化されました。Kibana を活用すると、さまざまなグラフ、テーブル、マップを使用して、Elasticsearch データの表示、検索、操作を行うことができます。さらに、Kibana は大量データの高度なデータ分析を実行できます。Kibana リリースの主な機能強化は次のとおりです。
- 可視化ツールの新しいデザイン: カラースキームの更新と表示画面活用の最大化
- Timelion: 時間ベースのクエリ DSL による可視化ツール
- コンソール: 従来 Sense と呼ばれていた機能がコア機能の一部となりました。以前と同様の設定を使って、Elasticsearch へのフリーフォームのリクエストを行うことができます
- フィールドスクリプト言語: Elasticsearch クラスターで新しいスクリプト言語 Painless を使うことが可能
- タグクラウドの可視化: 5.1 では、データの重要度による単語ベースのグラフィカルビューが追加されました
- グラフの拡張: 前回削除されたグラフが復活し、さらに X-Pack の高度なビューが追加されました
- Profiler の UI: ツリービューによる Profile API の拡張を提供
- レンダリングパフォーマンスの向上: パフォーマンスを向上させ、CPU 負荷を低減
まとめ ご覧いただいたように、このリリースでは Elasticsearch ソリューションの構築に役立つ、広範な機能強化や新機能を備えています。Amazon Elasticsearch Service では新たに、15 個の Elasticsearch API と 6 つのプラグインをサポートします。Amazon Elasticsearch Service は Elasticsearch 5.1 の次のオペレーションをサポートします。

Elasticsearch でサポートされるオペレーションの詳細については、「Amazon Elasticsearch 開発者ガイド」を参照してください。また Amazon Elasticsearch Service のウェブサイトを活用したり、AWS マネジメントコンソールにサインインして開始することもできます。- Tara
Amazon Elasticsearch Service をはじめよう: シャード数の算出方法
Dr. Jon Handler (@_searchgeek) は検索技術にスペシャライズした Amazon Web Services のプリンシパルソリューションアーキテクトです。
Elasticsearch および Amazon Elasticsearch Service(Amazon ES) のブログポストシリーズへようこそ。ここでは今後もAWS上でElasticsearchをはじめるにあたって必要な情報を提供していく予定です。
いくつのシャードが必要?
Elasticsearchは、大量のデータを、シャードと呼ばれる細かいユニットに分割し、それらのシャードを複数のインスタンスに分散して保持します。Elasticsearchではインデックス作成の際にシャード数を設定します。既存のインデックスのシャード数を変更することは出来ないため、最初のドキュメントをインデックスに投入する前にシャード数を決定しなければなりません。最初はインデックスのサイズからシャード数を算出するにあたって、それぞれのシャードのサイズの目安を30GBにします。
シャード数 = インデックスのサイズ / 30GB
インデックスのサイズ算出に関しては、AWS Solutions Architect ブログ: 【AWS Database Blog】Amazon Elasticsearch Service をはじめよう: インスタンス数の見積もり方法をご覧ください。
データの送信やクエリをクラスタに対して行っていく中で、クラスタのパフォーマンスを元に、継続的にリソースのユーセージを評価しながら、シャード数を調整していきます。
シャードとは?
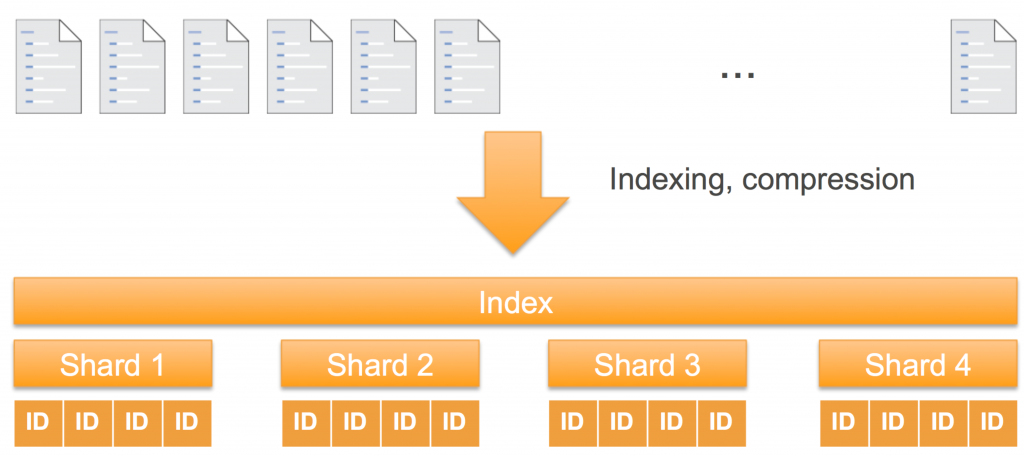
サーチエンジンには2つの役割があります: ドキュメントを元にしたインデックスの作成と、インデックスの中からマッチしたドキュメントを引き当てる検索です。インデックスが小さければ一つのデータ構造で一台のマシンで事足りるでしょう。しかし、大量のドキュメントにおいては、インデックスを保存するのに一台のマシンでは足りませんし、ピースに分割されたインデックスから検索結果を求めるためのコンピュート能力も足りません。Elasticsearchではこれらのピースのことをシャードと呼びます。それぞれのドキュメントは計算結果に基いてシャードにルーティングされます。デフォルトではドキュメントのIDのハッシュ値に基づいたルーティングになります。
シャードは ストレージ(storage) の単位であり、また 処理(computation) の単位でもあります。Elasticsearchはシャードを独立した形でクラスタ内のインスタンスにデプロイし、インデックスの処理をそれぞれで並列に行います。Elasticsearchという名前の通り”elastic”なものであると言えるでしょう。クラスタにインスタンスを追加する場合、Amazon Elasticsearch Serviceは自動的にシャードのリバランスを行い、クラスタ内のインスタンスにシャードを再配置します。
ストレージ(storage)においては、シャードはそれぞれ別のもの(distinct)です。シャード内のドキュメントは、他のシャードに重複して保持されることはありません。このアプローチによってシャード毎の独立性を保っています。
処理(computation)においても、シャードはそれぞれ別のもの(distinct)です。それぞれのシャードはドキュメントが処理されて生成されたApache Lucene indexのインスタンスです。インデックスには全てのシャードが含まれるため、クエリや更新リクエストのプロセスにおいて、それぞれのシャードはお互いに協調して機能する必要があります。クエリのプロセスにおいては、Elasticsearchはインデックス内の全てのシャードにクエリをルーティングします。それぞれのシャードはローカルで個別に処理を行い、それぞれの結果をアグリゲートして最終的にレスポンスします。書き込みリクエストにおいては(ドキュメントの追加、もしくは、既存のドキュメントの更新)、Elasticsearchはリクエストを適切なシャードにルーティングします。
Elasticsearchには2つの種類のシャードがある
Elasticsearchには2つの種類のシャードがあります – プライマリシャードとレプリカシャードです。プライマリシャードは全ての書き込みリクエストを受け付けます。プライマリシャードは新しく追加されたドキュメントをレプリカにパスします。デフォルトでは、書き込みがレプリカに確認(acknowledge)されるのを待ってから呼び出し元に書き込み成功のレスポンスを行います。プライマリとレプリカシャードはデータの保存に冗長性をもたらし、データのロスを起こりにくくします。

この図の例では、Elasticsearchクラスタは3つのデータインスタンスを保持しています。緑と青の2つのインデックスがあり、それぞれ3つのシャードがあります。それぞれのシャードのプライマリは赤枠で囲われています。それぞれのシャードにはレプリカがあり、それらに枠はありません。Elasticsearchはいくつかのルールを元にシャードをインスタンスに配置します。最も基本的なルールとして、プライマリとレプリカのシャードを同じインスタンスに配置しない、というものが挙げられます。
最初にストレージにフォーカスする
お客様のワークロードには2つの種類があります: シングルインデックスとローリングインデックス。シングルインデックスのワークロードは、全てのコンテンツを保持する”source of truth”な外部のリポジトリを使い、データは一つのインデックスに保持されます。ローリングインデックスのワークロードは、データを継続的に受け取り、データはタイムスタンプによって(通常は1日24時間)異なるインデックスに保持されます。
それぞれのワークロードにおけるシャーディングの計算のスタート地点は、インデックスに必要なストレージサイズです。それぞれのシャードをストレージの単位として扱うと、いくつのシャードが必要になるかのベースラインを見出すことが出来ます。シングルインデックスのワークロードであれば、トータルのストレージ容量を30GBで割って最初に必要なシャード数を算出します。ローリングインデックスのワークロードの場合は一期間のインデックスのサイズを30GBで割ることで最初のシャード数を算出します。
シングルシャードを恐れるな!
もし、あなたのインデックスのサイズが30GB以下であるのであれば、一つのシャードのみを使うべきです。”more is better”というガッツフィーリングをお持ちの方もいらっしゃいますが、誘惑を断ち切りましょう! シャードは処理とストレージのエンティティであり、あなたが追加するシャードによってインデックスに対するリクエストはアディショナルなCPUに分散されて処理されます。必要以上のプロセッサーを使うことで、その管理や処理結果の結合などに追加で処理が必要になり、パフォーマンスが下がることにつながります。scatter-gatherなクエリおよびレスポンスにおけるネットワークのオーバーヘッドもかかるでしょう。
シャード数の設定
Elasticsearchのインデックス作成APIを叩いく際にシャード数を設定します。Amazon Elasticsearch ServiceでのAPIコールは以下のようになります:
>>> curl –XPUT https://search-tweets-EXAMPLE.us-west-2.es.amazonaws.com/tweet -d '{
"settings": {
"index" : {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
}'
シングルインデックスのワークロードの場合、この設定を行うのはインデックスを最初に作成する際の1回のみですが、ローリングインデックスのワークロードの場合、インデックスを定期的に作成することになります。その場合は _template APIを使って、テンプレートにマッチする新しいインデックスには自動的に設定が適用されるようにします。
>>> curl –XPUT https://search-tweets-EXAMPLE.us-west-2.es.amazonaws.com/_template/template1 -d '{
"template": "logs*",
"settings": {
"index" : {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
}'
この例では、”log”というプレフィックスで作られたインデックスは、2つのシャードと1つのレプリカを保持します。
ワークロードに合わせた調整
今回カバーした内容は最もシンプルなシャーディングに関することでしたが、今後のポストではユーセージを元にしたシャード数の調整といったネクストレベルなところまで踏み込む予定です。もし、はじめたばかりであれば、30GBでインデックスのサイズを割り算することでシャード数を算出しましょう。データをインデックスに投入する前にシャード数を設定するのをお忘れなく。
あなたのシャーディングアドベンチャーのエピソードを是非お聞かせください!
Amazon Elasticsearch Serviceのより詳細な情報に関しては、https://aws.amazon.com/jp/elasticsearch-service/ をご覧ください。
原文:Get Started with Amazon Elasticsearch Service: How Many Shards Do I Need?(翻訳:篠原 英治)
AWSでの疎結合データセットの適合、検索、分析
あなたは刺激的な仮説を思いつきました。そして今、あなたは、それを証明する(あるいは反論する)ためにできるだけ多くのデータを見つけて分析したいと思っています。適用可能な多くのデータセットがありますが、それらは異なる人によって異なる時間に作成され、共通の標準形式に準拠していません。異なるものを意味する変数に対して同じ名前を、同じものを意味する変数に対して異なる名前を使用しています。異なる測定単位と異なるカテゴリを使用しています。あるものは他のものより多くの変数を持っています。そして、それらはすべてデータ品質の問題を抱えています(例えば、日時が間違っている、地理座標が間違っているなど)。
最初に、これらのデータセットを適合させ、同じことを意味する変数を識別し、これらの変数が同じ名前と単位を持つことを確認する方法が必要です。無効なデータでレコードをクリーンアップまたは削除する必要もあります。
データセットが適合したら、データを検索して、興味のあるデータセットを見つける必要があります。それらのすべてにあなたの仮説に関連するレコードがあるわけではありませんので、いくつかの重要な変数に絞り込んでデータセットを絞り込み、十分に一致するレコードが含まれていることを確認する必要があります。
関心のあるデータセットを特定したら、そのデータにカスタム分析を実行して仮説を証明し、美しいビジュアライゼーションを作成して世界と共有することができます。
このブログ記事では、これらの問題を解決する方法を示すサンプルアプリケーションについて説明します。サンプルアプリケーションをインストールすると、次のようになります。
- 異なる3つのデータセットを適合させて索引付けし、検索可能にします。
- 事前分析を行い、関連するデータセットを見つけるために、データセットを検索するための、データ駆動のカスタマイズ可能なUIを提示します。
- Amazon AthenaやAmazon QuickSightとの統合により、カスタム解析やビジュアライゼーションが可能です
Amazon Kinesis アップデート – Amazon Elasticsearch Service との統合、シャード単位のメトリクス、時刻ベースのイテレーター
Amazon Kinesis はストリーミングデータをクラウド上で簡単に扱えるようにします。
Amazon Kinesis プラットフォームは3つのサービスから構成されています:Kinesis Streams によって、開発者は独自のストリーム処理アプリケーションを実装することができます;Kinesis Firehose によって、ストリーミングデータを保存・分析するための AWS へのロード処理がシンプルになります;Kinesis Analytics によって、ストリーミングデータを標準的な SQL で分析できます。
多くの AWS のお客様が、ストリーミングデータをリアルタイムに収集・処理するためのシステムの一部として Kinesis Streams と Kinesis Firehose を利用しています。お客様はこれらが完全なマネージドサービスであるがゆえの使い勝手の良さを高く評価しており、ストリーミングデータのためのインフラストラクチャーを独自に管理するかわりにアプリケーションを開発するための時間へと投資をしています。
本日、私たちは Amazon Kinesis Streams と Amazon Kinesis Firehose に関する3つの新機能を発表します。
- Elasticsearch との統合 – Amazon Kinesis Firehose は Amazon Elasticsearch Service へストリーミングデータを配信できるようになりました。
- 強化されたメトリクス – Amazon Kinesis はシャード単位のメトリクスを CloudWatch へ毎分送信できるようになりました。
- 柔軟性 – Amazon Kinesis から時間ベースのイテレーターを利用してレコードを受信できるようになりました。
Amazon Elasticsearch Service との統合
Elasticsearch はポピュラーなオープンソースの検索・分析エンジンです。Amazon Elasticsearch Service は AWS クラウド上で Elasticsearch を簡単にデプロイ・実行・スケールさせるためのマネージドサービスです。皆さんは、Kinesis Firehose のデータストリームを Amazon Elasticsearch Service のクラスターへ配信することができるようになりました。この新機能によって、サーバーのログやクリックストリーム、ソーシャルメディアのトラフィック等にインデックスを作成し、分析することが可能になります。
受信したレコード(Elasticsearch ドキュメント)は指定した設定に従って Kinesis Firehose 内でバッファリングされたのち、複数のドキュメントに同時にインデックスを作成するバルクリクエストを使用して自動的にクラスターへと追加されます。なお、データは Firehose へ送信する前に UTF-8 でエンコーディングされた単一の JSON オブジェクトにしておかなければなりません(どのようにこれを行うかを知りたい方は、私の最近のブログ投稿 Amazon Kinesis Agent Update – New Data Preprocessing Feature を参照して下さい)。
こちらが、AWS マネージメントコンソールを使用したセットアップの方法です。出力先(Amazon Elasticsearch Service)を選択し、配信ストリームの名を入力します。次に、Elasticsearch のドメイン(この例では livedata)を選択、インデックスを指定し、インデックスのローテーション(なし、毎時、日次、週次、月次)を選択します。また、全てのドキュメントもしくは失敗したドキュメントのバックアップを受け取る S3 バケットも指定します:
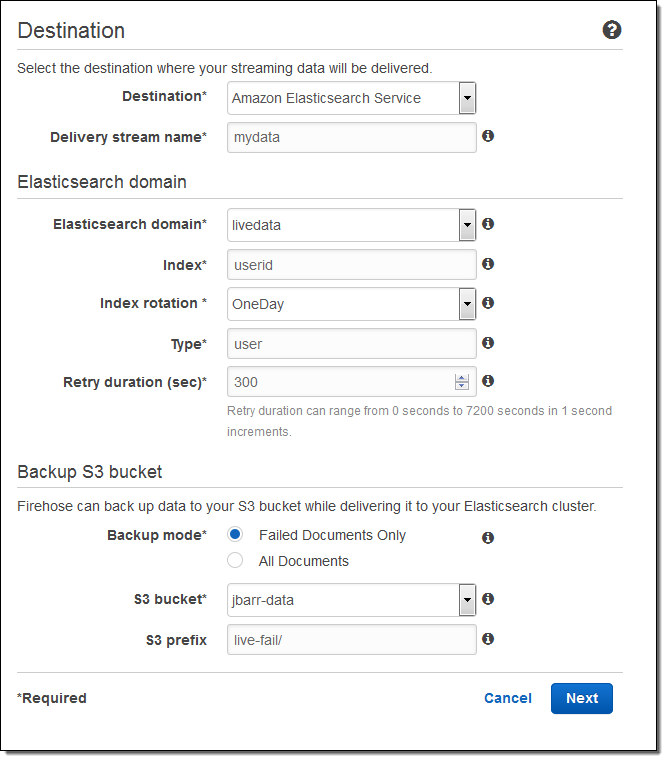
そして、バッファーのサイズを指定し、S3 バケットに送信されるデータの圧縮と暗号化のオプションを選択します。必要に応じてログ出力を有効にし、IAM ロールを選択します:
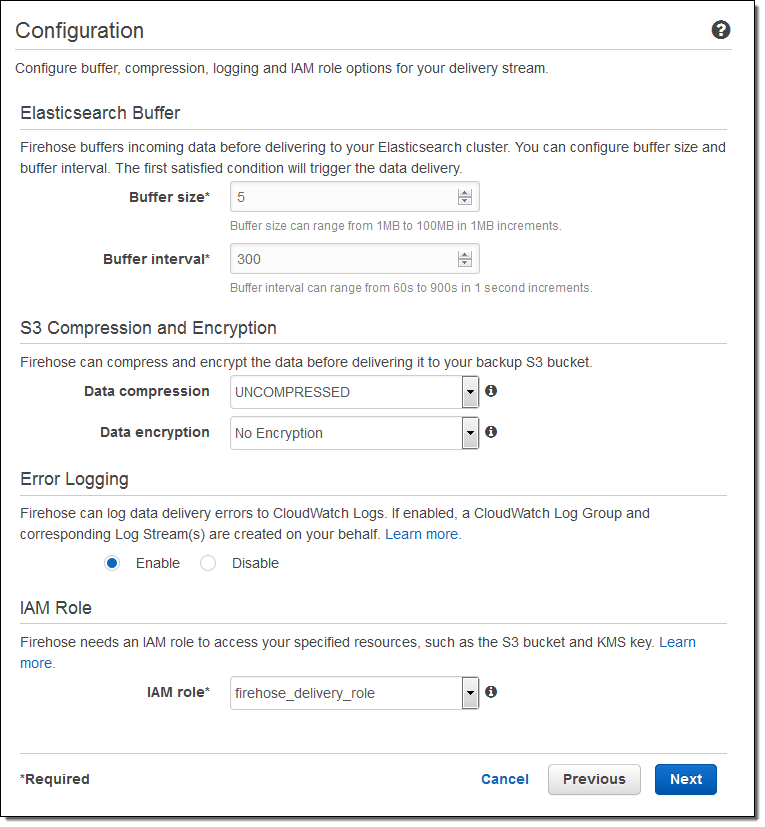
一分程度でストリームの準備が整います:
コンソールで配信のメトリクスを見ることもできます:
データが Elasticsearch へ到達した後は、Kibana や Elasticsearch のクエリー言語による視覚的な検索ができます。
総括すると、この統合によって、皆さんのストリーミングデータを収集し、Elasticsearch に配信するための処理は実にシンプルになります。もはや、コードを書いたり、独自のデータ収集ツールを作成したりする必要はありません。
シャード単位のメトリクス
全ての Kinesis ストリームは、一つ以上のシャードによって構成されており、全てのシャードは一定量の読み取り・書き込みのキャパシティを持っています。ストリームにシャードを追加することで、ストリームのキャパシティは増加します。
皆さんは、それぞれのシャードのパフォーマンスを把握する目的で、シャード単位のメトリクスを有効にすることができるようになりました。シャードあたり6つのメトリクスがあります。それぞれのメトリクスは一分間に一回レポートされ、通常のメトリクス単位の CloudWatch 料金で課金されます。この新機能によって、ある特定のシャードに負荷が偏っていないかを他のシャードと比較して確認したり、ストリーミングデータの配信パイプライン全体で非効率な部分を発見・一掃したりすることが可能になります。例えば、処理量に対して受信頻度が高すぎるシャードを特定したり、アプリケーションから予想よりも低いスループットでデータが読まれているシャードを特定したりできます。
こちらが、新しいメトリクスです:
IncomingBytes – シャードへの PUT が成功したバイト数。
IncomingRecords – シャードへの PUT が成功したレコード数。
IteratorAgeMilliseconds – シャードに対する GetRecords 呼び出しが戻した最後のレコードの滞留時間(ミリ秒)。値が0の場合、読み取られたレコードが完全にストリームに追いついていることを意味します。
OutgoingBytes – シャードから受信したバイト数。
OutgoingRecords – シャードから受信したレコード数。
ReadProvisionedThroughputExceeded – 秒間5回もしくは2MBの上限を超えてスロットリングされた GetRecords 呼び出しの数。
WriteProvisionedThroughputExceeded – 秒間1000レコードもしくは1MBの上限を超えてスロットリングされたレコードの数。
EnableEnhancedMetrics を呼び出すことでこれらのメトリクスを有効にすることができます。いつもどおり、任意の期間で集計を行うために CloudWatch の API を利用することもできます。
時刻ベースのイテレーター
任意のシャードに対して GetShardIterator を呼び出し、開始点を指定してイテレーターを作成することで、アプリケーションは Kinesis ストリームからデータを読み取ることができます。皆さんは、既存の開始点の選択肢(あるシーケンス番号、あるシーケンス番号の後、最も古いレコード、最も新しいレコード)に加え、タイムスタンプを指定できるようになりました。指定した値(UNIX 時間形式)は読み取って処理しようとする最も古いレコードのタイムスタンプを表します。
— Jeff;
翻訳は SA 内海(@eiichirouchiumi)が担当しました。原文はこちらです。