Category: Amazon EMR
New – Amazon EMR Instance Fleets
Today we’re excited to introduce a new feature for Amazon EMR clusters called instance fleets. Instance fleets gives you a wider variety of options and intelligence around instance provisioning. You can now provide a list of up to 5 instance types with corresponding weighted capacities and spot bid prices (including spot blocks)! EMR will automatically provision On-Demand and Spot capacity across these instance types when creating your cluster. This can make it easier and more cost effective to quickly obtain and maintain your desired capacity for your clusters.
You can also specify a list of Availability Zones and EMR will optimally launch your cluster in one of the AZs. EMR will also continue to rebalance your cluster in the case of Spot instance interruptions by replacing instances with any of the available types in your fleet. This will make it easier to maintain your cluster’s overall capacity. Instance fleets can be used instead of instance groups. Just like groups your cluster will have master, core, and task fleets.
Let’s take a look at the console updates to get an idea of how these fleets work.
We’ll start by navigating to the EMR console and clicking the Create Cluster button. That should bring us to our familiar EMR provisioning console where we can navigate to the advanced options near the top left.
We’ll select the latest EMR version (instance fleets are available for EMR versions 4.8.0 and greater, with the exception of 5.0.x) and click next.
Now we get to the good stuff! We’ll select the new instance fleet option in the hardware options.
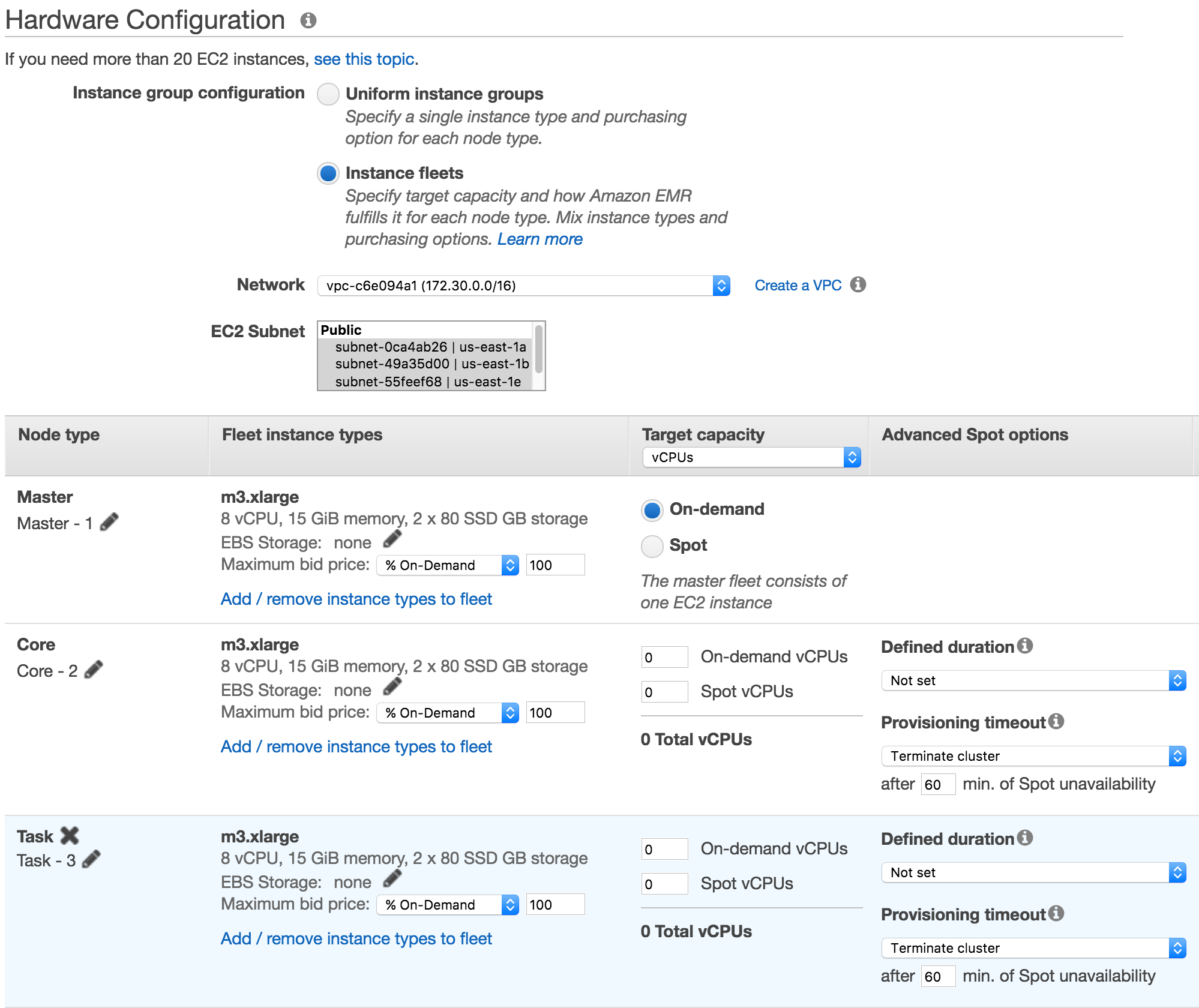
Now what I want to do is modify our core group to have a couple of instance types that will satisfy the needs of my cluster.

EMR will provision capacity in each instance fleet and availability zone to meet my requirements in the most cost effective way possible. The EMR console provides an easy mapping of vCPU to weighted capacity for each instance type, making it easy to use vCPU as the capacity unit (I want 16 total vCPUs in my core fleet). If the vCPU units don’t match my criteria for weighting instance types I can change the “Target capacity” selector to include arbitrary units and define my own weights (this is how the API/CLI consume capacity units as well).
When the cluster is being provisioned if it’s unable to obtain the desired spot capacity within a user defined timeout you can have it terminate or fall back onto On-Demand instances to provision the rest of the capacity.
All this functionality for instance fleets is also available from the AWS SDKs and the CLI. Let’s take a look at how we would provision our own instance fleet.
First we’ll create our configuration json in my-fleet-config.json:
[
{
"Name": "MasterFleet",
"InstanceFleetType": "MASTER",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [{"InstanceType": "m3.xlarge"}]
},
{
"Name": "CoreFleet",
"InstanceFleetType": "CORE",
"TargetSpotCapacity": 11,
"TargetOnDemandCapacity": 11,
"LaunchSpecifications": {
"SpotSpecification": {
"TimeoutDurationMinutes": 20,
"TimeoutAction": "SWITCH_TO_ON_DEMAND"
}
},
"InstanceTypeConfigs": [
{
"InstanceType": "r4.xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 50,
"WeightedCapacity": 1
},
{
"InstanceType": "r4.2xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 50,
"WeightedCapacity": 2
},
{
"InstanceType": "r4.4xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 50,
"WeightedCapacity": 4
}
]
}
]Now that we have our configuration we can use the AWS CLI’s ’emr’ subcommand to create a new cluster with that configuration:
aws emr create-cluster --release-label emr-5.4.0 \
--applications Name=Spark,Name=Hive,Name=Zeppelin \
--service-role EMR_DefaultRole \
--ec2-attributes InstanceProfile="EMR_EC2_DefaultRole,SubnetIds=[subnet-1143da3c,subnet-2e27c012]" \
--instance-fleets file://my-fleet-config.json
If you’re eager to get started the feature is available now at no additional cost and you can find detailed documentation to help you get started here.
Thanks to the EMR service team for their help writing this post!
Human Longevity, Inc. – Changing Medicine Through Genomics Research
Human Longevity, Inc. (HLI) is at the forefront of genomics research and wants to build the world’s largest database of human genomes along with related phenotype and clinical data, all in support of preventive healthcare. In today’s guest post, Yaron Turpaz, Bryan Coon, and Ashley Van Zeeland talk about how they are using AWS to store the massive amount of data that is being generated as part of this effort to revolutionize medicine.
— Jeff;
When Human Longevity, Inc. launched in 2013, our founders recognized the challenges ahead. A genome contains all the information needed to build and maintain an organism; in humans, a copy of the entire genome, which contains more than three billion DNA base pairs, is contained in all cells that have a nucleus. Our goal is to sequence one million genomes and deliver that information—along with integrated health records and disease-risk models—to researchers and physicians. They, in turn, can interpret the data to provide targeted, personalized health plans and identify the optimal treatment for cancer and other serious health risks far earlier than has been possible in the past. The intent is to transform medicine by fostering preventive healthcare and risk prevention in place of the traditional “sick care” model, when people wind up seeing their doctors only after symptoms manifest.
Our work in developing and applying large-scale computing and machine learning to genomics research entails the collection, analysis, and storage of immense amounts of data from DNA-sequencing technology provided by companies like Illumina. Raw data from a single genome consumes about 100 gigabytes; that number increases as we align the genomic information with annotation and phenotype sources and analyze it for health insights.
From the beginning, we knew our choice of compute and storage technology would have a direct impact on the success of the company. Using the cloud was clearly the best option. We’re experts in genomics, and don’t want to spend resources building and maintaining an IT infrastructure. We chose to go all in on AWS for the breadth of the platform, the critical scalability we need, and the expertise AWS has developed in big data. We also saw that the pace of innovation at AWS—and its deliberate strategy of keeping costs as low as possible for customers—would be critical in enabling our vision.
Leveraging the Range of AWS Services
Spectral karyotype analysis / Image courtesy of Human Longevity, Inc.
Today, we’re using a broad range of AWS services for all kinds of compute and storage tasks. For example, the HLI Knowledgebase leverages a distributed system infrastructure comprised of Amazon S3 storage and a large number of Amazon EC2 nodes. This helps us achieve resource isolation, scalability, speed of provisioning, and near real-time response time for our petabyte-scale database queries and dynamic cohort builder. The flexibility of AWS services makes it possible for our customized Amazon Machine Images and pre-built, BTRFS-partitioned Amazon EBS volumes to achieve turn-up time in seconds instead of minutes. We use Amazon EMR for executing Spark queries against our data lake at the scale we need. AWS Lambda is a fantastic tool for hooking into Amazon S3 events and communicating with apps, allowing us to simply drop in code with the business logic already taken care of. We use Auto Scaling based on demand, and AWS OpsWorks for managing a Docker pipeline.
We also leverage the cost controls provided by Amazon EC2 Spot and Reserved Instance types. When we first started, we used on-demand instances, but the costs started to grow significantly. With Spot and Reserved Instances, we can allocate compute resources based on specific needs and workflows. The flexibility of AWS services enables us to make extensive use of dockerized containers through the resource-management services provided by Apache Mesos. Hundreds of dynamic Amazon EC2 nodes in both our persistent and spot abstraction layers are dynamically adjusted to scale up or down based on usage demand and the latest AWS pricing information. We achieve substantial savings by sharing this dynamically scaled compute cluster with our Knowledgebase service and the internal genomic and oncology computation pipelines. This flexibility gives us the compute power we need while keeping costs down. We estimate these choices have helped us reduce our compute costs by up to 50 percent from the on-demand model.
We’ve also worked with AWS Professional Services to address a particularly hard data-storage challenge. We have genomics data in hundreds of Amazon S3 buckets, many of them in the petabyte range and containing billions of objects. Within these collections are millions of objects that are unused, or used once or twice and never to be used again. It can be overwhelming to sift through these billions of objects in search of one in particular. It presents an additional challenge when trying to identify what files or file types are candidates for the Amazon S3-Infrequent Access storage class. Professional Services helped us with a solution for indexing Amazon S3 objects that saves us time and money.
Moving Faster at Lower Cost
Our decision to use AWS came at the right time, occurring at the inflection point of two significant technologies: gene sequencing and cloud computing. Not long ago, it took a full year and cost about $100 million to sequence a single genome. Today we can sequence a genome in about three days for a few thousand dollars. This dramatic improvement in speed and lower cost, along with rapidly advancing visualization and analytics tools, allows us to collect and analyze vast amounts of data in close to real time. Users can take that data and test a hypothesis on a disease in a matter of days or hours, compared to months or years. That ultimately benefits patients.
Our business includes HLI Health Nucleus, a genomics-powered clinical research program that uses whole-genome sequence analysis, advanced clinical imaging, machine learning, and curated personal health information to deliver the most complete picture of individual health. We believe this will dramatically enhance the practice of medicine as physicians identify, treat, and prevent diseases, allowing their patients to live longer, healthier lives.
— Yaron Turpaz (Chief Information Officer), Bryan Coon (Head of Enterprise Services), and Ashley Van Zeeland (Chief Technology Officer).
Learn More
Learn more about how AWS supports genomics in the cloud, and see how genomics innovator Illumina uses AWS for accelerated, cost-effective gene sequencing.
Additional At-Rest and In-Transit Encryption Options for Amazon EMR
Our customers use Amazon EMR (including Apache Hadoop and the full range of tools that make up the Apache Spark ecosystem) to handle many types of mission-critical big data use cases. For example:
- Yelp processes over a terabyte of log files and photos every day.
- Expedia processes streams of clickstream, user interaction, and supply data.
- FINRA analyzes billions of brokerage transaction records daily.
- DataXu evaluates 30 trillion ad opportunities monthly.
Because customers like these (see our big data use cases for many others) are processing data that is mission-critical and often sensitive, they need to keep it safe and sound.
We already offer several data encryption options for EMR including server and client side encryption for Amazon S3 with EMRFS and Transparent Data Encryption for HDFS. While these solutions do a good job of protecting data at rest, they do not address data stored in temporary files or data that is in flight, moving between job steps. Each of these encryption options must be individually enabled and configured, making the process of implementing encryption more tedious that it need be.
It is time to change this!
New Encryption Support
Today we are launch a new, comprehensive encryption solution for EMR. You can now easily enable at-rest and in-transit encryption for Apache Spark, Apache Tez, and Hadoop MapReduce on EMR.
The at-rest encryption addresses the following types of storage:
- Data stored in S3 via EMRFS.
- Data stored in the local file system of each node.
- Data stored on the cluster using HDFS.
The in-transit encryption makes use of the open-source encryption features native to the following frameworks:
- Apache Spark
- Apache Tez
- Apache Hadoop MapReduce
This new feature can be configured using an Amazon EMR security configuration. You can create a configuration from the EMR Console, the EMR CLI, or via the EMR API.
The EMR Console now includes a list of security configurations:
Click on Create to make a new one:
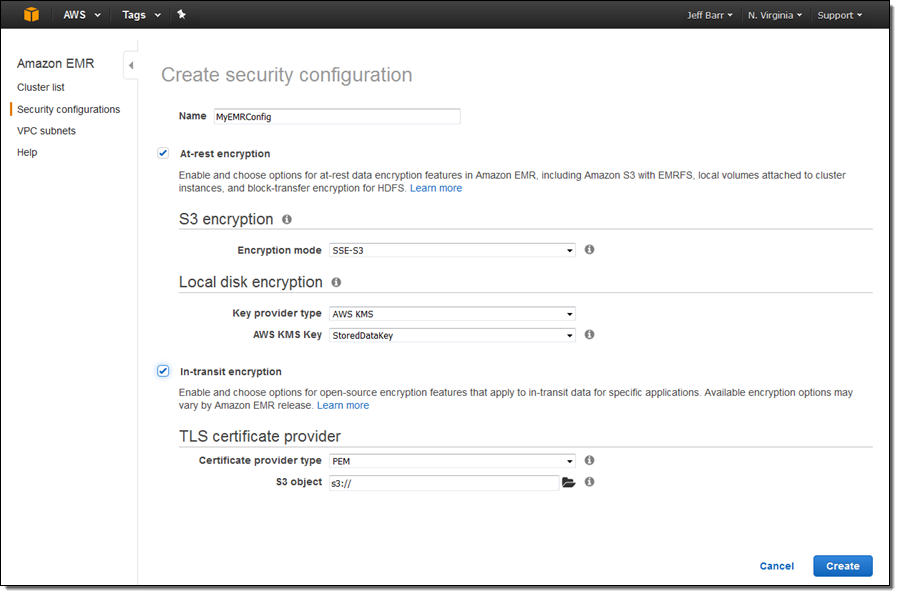
Enter a name, and then choose the desired mode and type for each aspect of this new feature. Based on the mode or the type, the console will prompt you for additional information.
S3 Encryption:
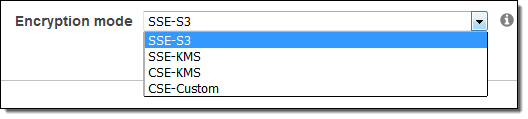
Local disk encryption:

In-transit encryption:
![]()
If you choose PEM as the certificate provider type, you will need to enter the S3 location of a ZIP file that contains the PEM file(s) that you want to use for encryption. If you choose Custom, you will need to enter the S3 location of a JAR file and the class name of the custom certificate provider.
After you make all of your choices and click on Create, your security configuration will appear in the console:
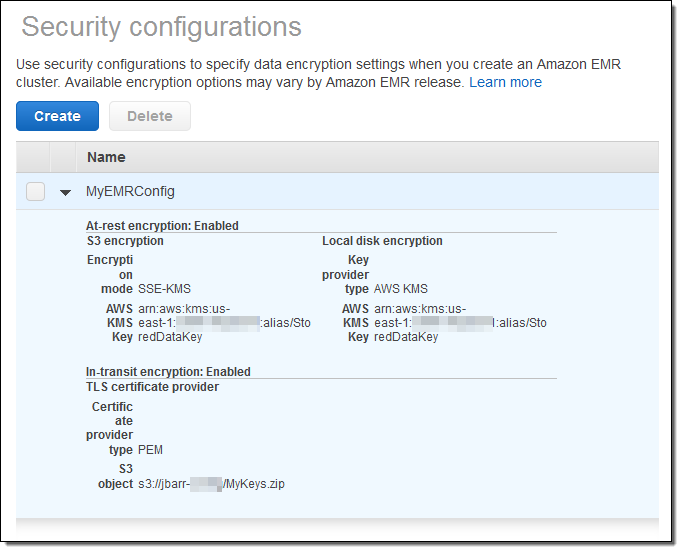
You can then specify the configuration when you create a new EMR Cluster. This feature is available for clusters that are running Amazon EMR release 4.8.0 or 5.0.0. To learn more, read about Amazon EMR Encryption with Security Configurations.
— Jeff;
Amazon EMR 5.0.0 – Major App Updates, UI Improvements, Better Debugging, and More
The Amazon EMR team has been cranking out new releases at a fast and furious pace! Here’s a quick recap of this year’s launches:
- EMR 4.7.0 – Updates to Apache Tez, Apache Phoenix, Presto, HBase, and Mahout (June).
- EMR 4.6.0 – HBase for realtime access to massive datasets (April).
- EMR 4.5.0 – Updates to Hadoop, Presto; addition of Spark and EMRFS (April).
- EMR 4.4.0 – Sqoop, HCatalog, Java 8, and more (March).
- EMR 4.3.0 – Updates to Spark, Presto, and Ganglia (January).
Today the team is announcing and releasing EMR 5.0.0. This is a major release that includes support for 16 open source Hadoop ecosystem projects, major version upgrades for Spark and Hive, use of Tez by default for Hive and Pig, user interface improvements to Hue and Zeppelin, and enhanced debugging functionality.
Here’s a map that shows how EMR has progressed over the course of the past couple of releases:

Let’s check out the new features in EMR 5.0.0!
Support for 16 Open Source Hadoop Ecosystem Projects
We started using Apache Bigtop to manage the EMR build and packaging process during the development of EMR 4.0.0. The use of Bigtop helped us to accelerate the release cycle while we continued to add additional packages from the Hadoop ecosystem, with a goal of making the newest GA (generally available) open source versions accessible to you as quickly as possible.
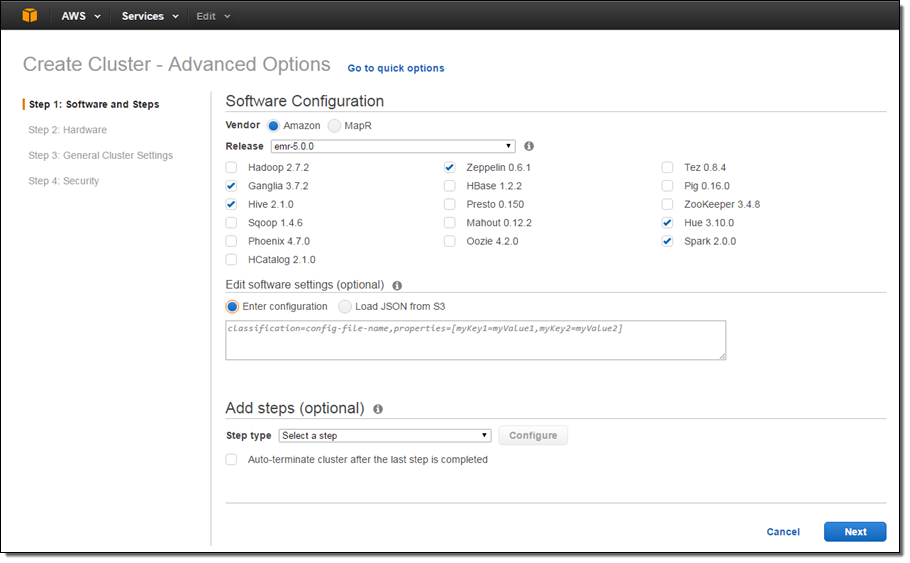
In accord with our goal, EMR 5.0 includes support for 16 Hadoop ecosystem projects including Apache Hadoop, Apache Spark, Presto, Apache Hive, Apache HBase, and Apache Tez. You can choose the desired set of apps when you create a new EMR cluster:
Major Version Upgrade for Spark and Hive
This release of EMR updates Hive (a SQL-like interface for Tez and Hadoop MapReduce) from 1.0 to 2.1, accompanied by a move to Java 8. It also updates Spark (an engine for large-scale data processing) from 1.6.2 to 2.0, with a similar move to Scala 2.11. The Spark and Hive updates are both major releases and include new features, performance enhancements, and bug fixes. For example, Spark now includes a Structured Streaming API, better SQL support, and more. Be aware that the new versions of Spark and Hive are not 100% backward compatible with the old ones; check your code and upgrade to EMR 5.0.0 with care.
With this release, Tez is now the default execution engine for Hive 2.1 and Pig 0.16, replacing Hadoop MapReduce and resulting in better performance, including reduced query latency. With this update, EMR uses MapReduce only when running a Hadoop MapReduce job directly (Hive and Pig now use Tez; Spark has its own framework).
User Interface Improvements
EMR 5.0.0 also updates Apache Zeppelin (a notebook for interactive data analytics) from 0.5.6 to 0.6.1, and Hue (an interface for analyzing data with Hadoop) from 3.7.1 to 3.10. The new versions of both of these web-based tools include new features and lots of smaller improvements.
Zeppelin is often used with Spark; Hue works well with Hive, Pig, and HBase. The new version of Hue includes a notebooks feature that allows you to have multiple queries on the same page:
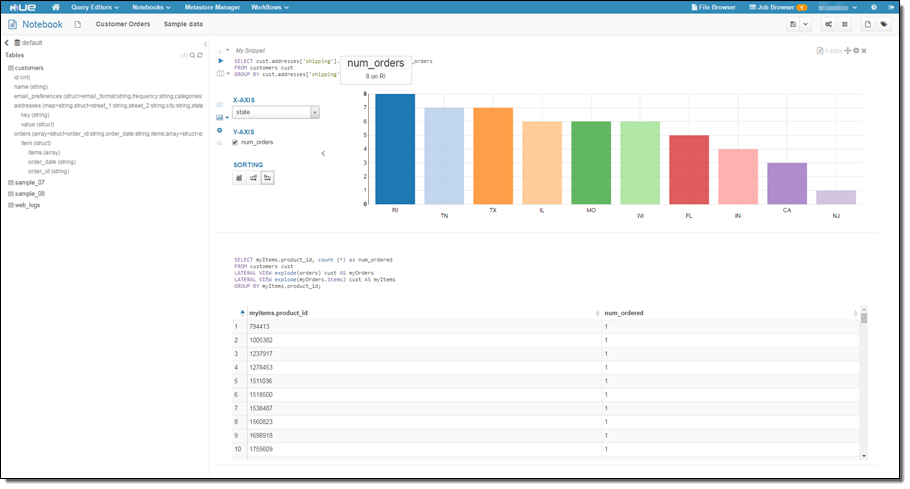
Hue can also help you to design Oozie workflows:
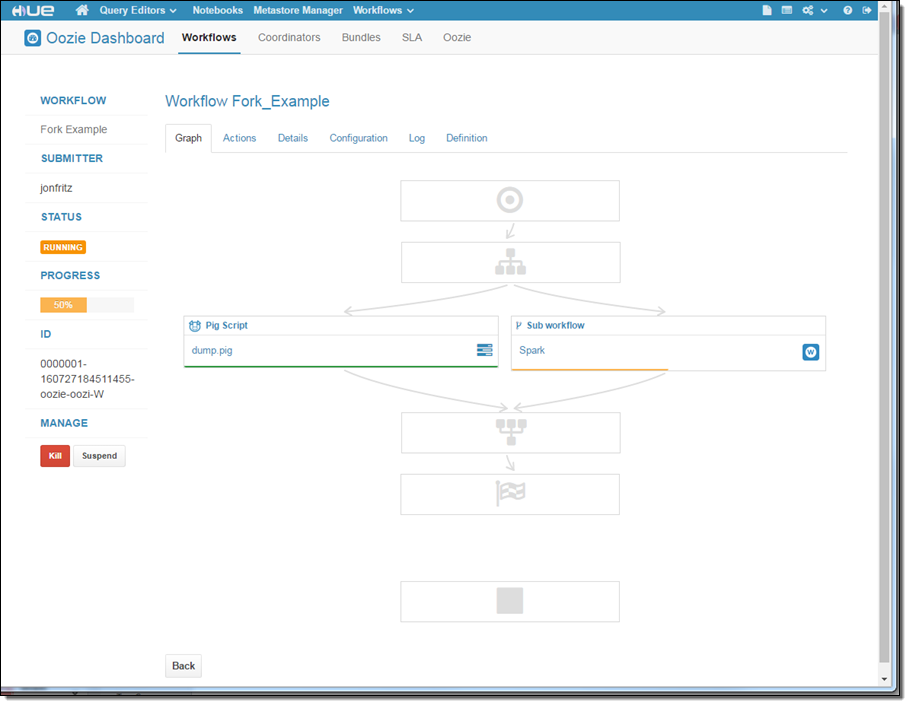
Enhanced Debugging Functionality
Finally, EMR 5.0.0 includes some better debugging functionality, making it easier for you to figure out why a particular step of your EMR job failed. The console now displays a partial stack track and links to the log file (stored in Amazon S3) in order to help you to find, troubleshoot, and fix errors:
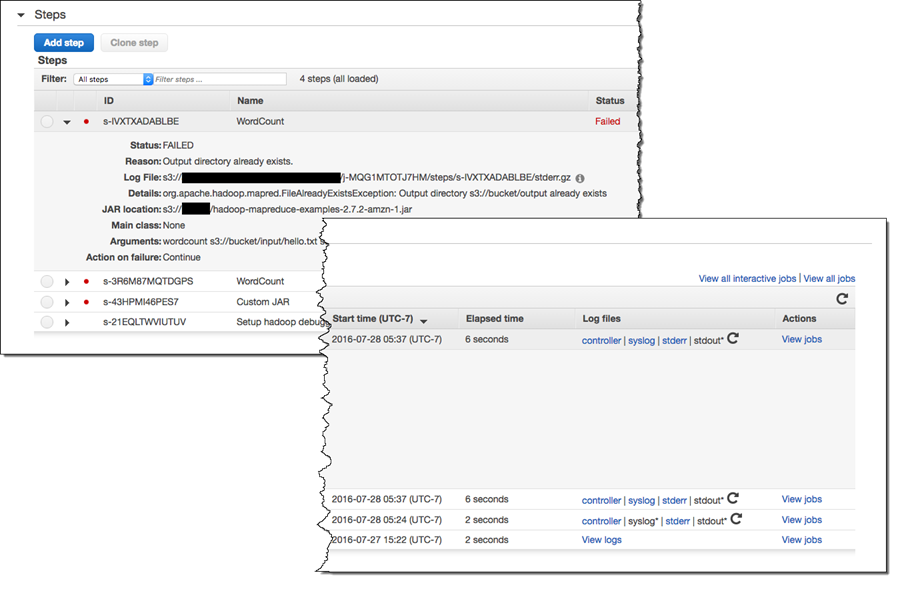 Launch a Cluster Today
Launch a Cluster Today
You can launch an EMR 5.0.0 cluster today in any AWS Region! Open up the EMR Console, click on Create cluster, and choose emr-5.0.0 from the Release menu:
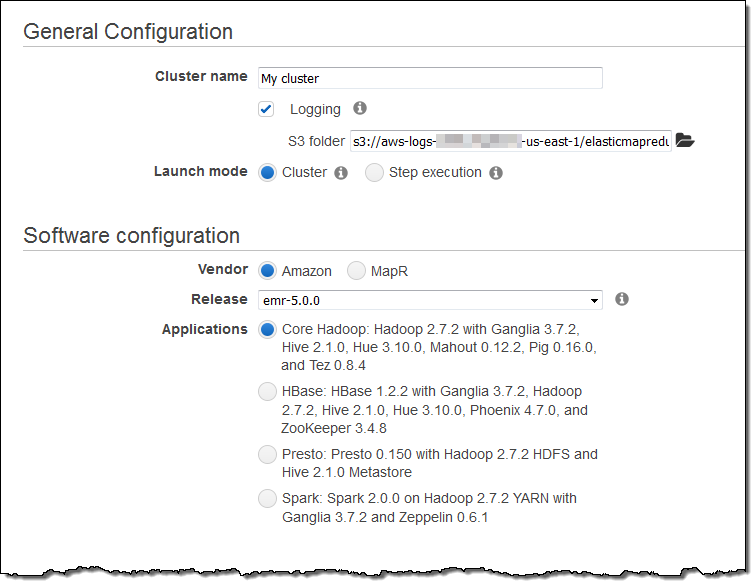
Learn More
To learn more about this powerful new release of EMR, plan to attend our webinar or August 23rd, Introducing Amazon EMR Release 5.0: Faster, Easier, Hadoop, Spark, and Presto.
— Jeff;
Amazon EMR 4.7.0 – Apache Tez & Phoenix, Updates to Existing Apps
Amazon EMR allows you to quickly and cost-effectively process vast amounts of data. Since the 2009 launch, we have added many new features and support for an ever-increasing roster of applications from the Hadoop ecosystem. Here are a few of the additions that we have made this year:
- April – Support for Apache HBase 1.2 (EMR 4.6).
- March – Support for Sqoop, HCatalog, Java 8, and more (EMR 4.4).
- February – Support for EBS volumes, M4 instances, and C4 instances.
- January – Support for Apache Spark, with updates to other applications.
Today we are pushing forward once again, with new support for Apache Tez (dataflow-driven data processing task orchestration) and Apache Phoenix (fast SQL for OLTP and operational analytics), along with updates to several of the existing apps. In order to make use of these new and/or updated applications, you will need to launch a cluster that runs release 4.7.0 of Amazon EMR.
New – Apache Tez (0.8.3)
Tez runs on top of Apache Hadoop YARN. Tez provides you with a set of dataflow definition APIs that allow you to define a DAG (Directed Acyclic Graph) of data processing tasks. Tez can be faster than Hadoop MapReduce, and can be used with both Hive and Pig. To learn more, read the EMR Release Guide. The Tez UI includes a graphical view of the DAG:
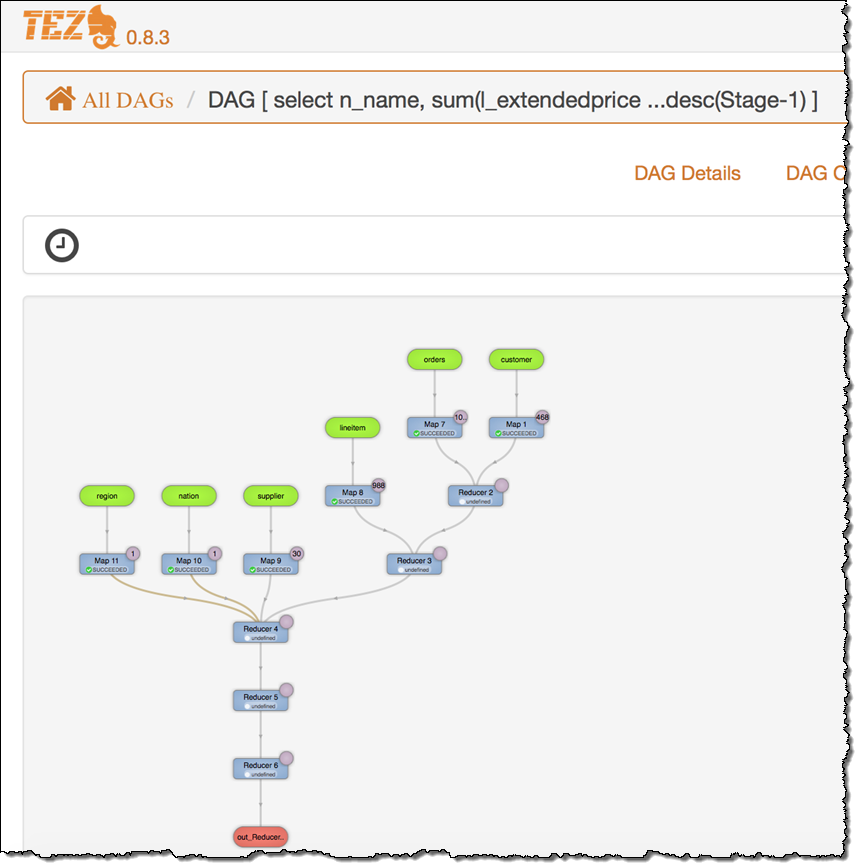
The UI also displays detailed information about each DAG:
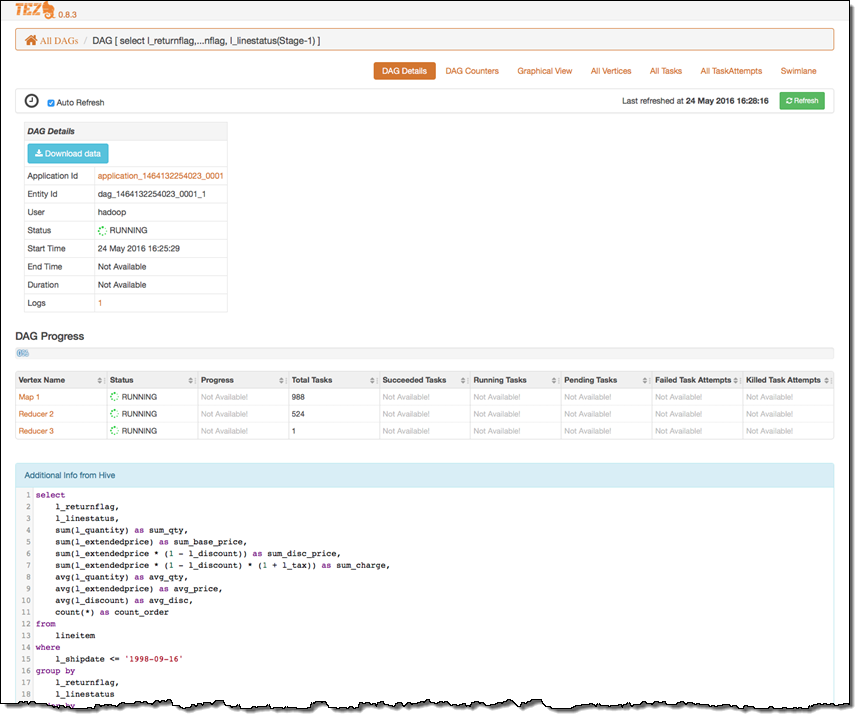
New – Apache Phoenix (4.7.0)
Phoenix uses HBase (another member of the Hadoop ecosystem) as its datastore. You can connect to Phoenix using a JDBC driver included on the cluster or from other applications that are running on or off of the cluster. Either way, you get access to fast, low-latency SQL with full ACID transaction capabilities. Your SQL queries are compiled into a series of HBase scans, the scans are run in parallel, and the results are aggregated to produce the result set. To learn more, read the Phoenix Quick Start Guide or review the Apache Phoenix Overview Presentation.
Updated Applications
We have also updated the following applications:
- HBase 1.2.1 – HBase provides low-latency, random access to massive datasets. The new version includes some bug fixes.
- Mahout 0.12.0 – Mahout provides scalable machine learning and data mining. The new version includes a large set of math and statistics features.
- Presto 0.147 – Presto is a distributed SQL query engine designed for large data sets. The new version adds features and fixes bugs.
Amazon Redshift JDBC Driver
You can use the new Redshift JDBC driver to allow applications running on your EMR clusters to access and update data stored in your Redshift clusters. Two versions of the driver are included on your cluster:
- JDBC 4.0-compatible –
/usr/share/aws/redshift/jdbc/RedshiftJDBC4.jar. - JDBC 4.1-compatible –
/usr/share/aws/redshift/jdbc/RedshiftJDBC41.jar.
To start using the new and applications, simply launch a new EMR cluster, and select release 4.7.0 along with the desired set of applications.
— Jeff;
Amazon EMR Update – Apache HBase 1.2 Is Now Available
Apache HBase is a distributed, scalable big data store designed to support tables with billions of rows and millions of columns. HBase runs on top of Hadoop and HDFS and can also be queried using MapReduce, Hive, and Pig jobs.
AWS customers use HBase for their ad tech, web analytics, and financial services workloads. They appreciate its scalability and the ease with which it handles time-series data.
HBase 1.2 on Amazon EMR
Today we are making version 1.2 of HBase available for use with Amazon EMR. Here are some of the most important and powerful features and benefits that you get when you run HBase:
Strongly Consistent Reads and Writes – When a writer returns, all of the readers will see the same value.
Scalability – Individual HBase tables can be comprised of billions of rows and millions of columns. HBase stores data in a sparse form in order to conserve space. You can use column families and column prefixes to organize your schemas and to indicate to HBase that the members of the family have a similar access pattern. You can also use timestamps and versioning to retain old versions of cells.
Backup to S3 – You can use the HBase Export Snapshot tool to backup your tables to Amazon S3. The backup operation is actually a MapReduce job and uses parallel processing to adeptly handle large tables.
Graphs And Timeseries – You can use HBase as the foundation for a more specialized data store. For example, you can use Titan for graph databases and OpenTSDB for time series.
Coprocessors – You can write custom business logic (similar to a trigger or a stored procedure) that runs within HBase and participates in query and update processing (read The How To of HBase Coprocessors to learn more).
You also get easy provisioning and scaling, access to a pre-configured installation of HDFS, and automatic node replacement for increased durability.
Getting Started with HBase
HBase 1.2 is available as part of Amazon EMR release 4.6. You can, as usual, launch it from the Amazon EMR Console, the Amazon EMR CLI, or through the Amazon EMR API. Here’s the command that I used:
$ aws --region us-east-1 emr create-cluster \
--name "MyCluster" --release-label "emr-4.6.0" \
--instance-type m3.xlarge --instance-count 3 --use-default-roles \
--ec2-attributes KeyName=keys-jbarr-us-east \
--applications Name=Hadoop Name=Hue Name=HBase Name=HiveThis command assumes that the EMR_DefaultRole and EMR_EC2_DefaultRole IAM roles already exist. They are created automatically when you launch an EMR cluster from the Console (read about Create and Use Roles for Amazon EMR and Create and Use Roles with the AWS CLI to learn more).
I found the master node’s DNS on the Cluster Details page and SSH’ed in as user hadoop. Then I ran a couple of HBase shell commands:
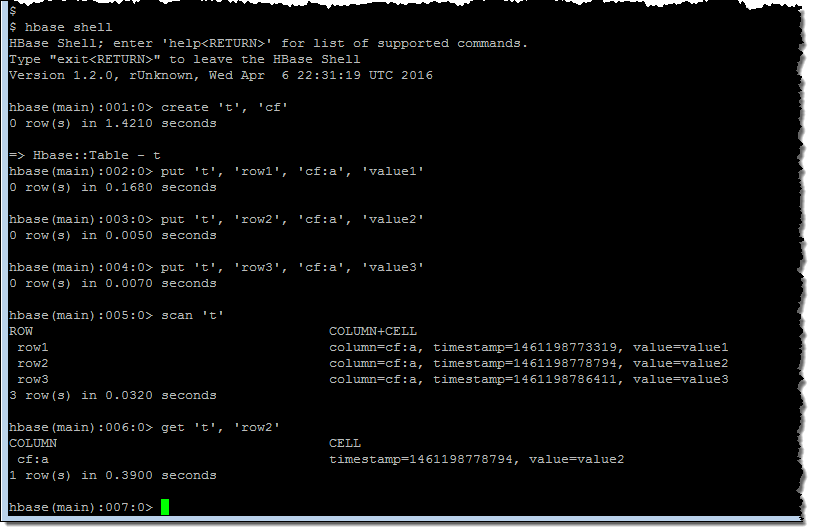
Following the directions in our new HBase Tutorial, I created a table called customer, restored a multi-million record snapshot from S3 into the table, and ran some simple queries:
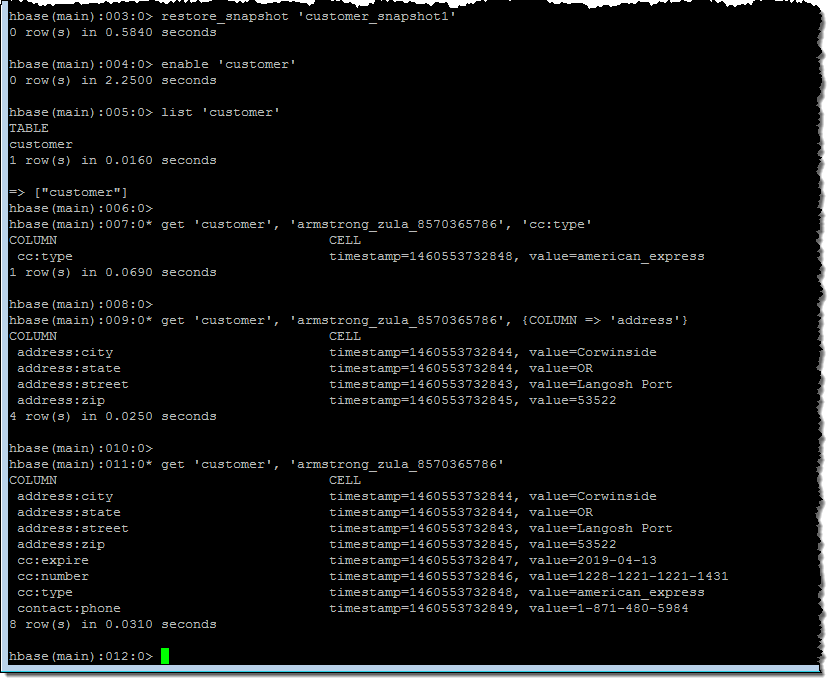
Available Now
You can start using HBase 1.2 on Amazon EMR today. To learn more, read the Amazon EMR Documentation.
— Jeff;
Amazon EMR 4.4.0 – Sqoop, HCatalog, Java 8, and More
Rob Leidle, Development Manager for Amazon EMR, wrote the guest post below to introduce you to the latest and greatest version!
— Jeff;
Today we are announcing Amazon EMR release 4.4.0, which adds support for Apache Sqoop (1.4.6) and Apache HCatalog 1.0.0, an upgraded release of Apache Mahout (0.11.1), and upgraded sandbox releases for Presto (0.136) and Apache Zeppelin (0.5.6). We have also enhanced our default Apache Spark settings and added support for Java 8.
New Applications in Release 4.4.0
Amazon EMR provides an easy way to install and configure distributed big data applications in the Hadoop and Spark ecosystems on managed clusters of Amazon EC2 instances. You can create Amazon EMR clusters from the Amazon EMR Create Cluster Page in the AWS Management Console, AWS Command Line Interface (CLI), or using a SDK with an EMR API. In the latest release, we added support for several new versions of the following applications:
 Zeppelin 0.5.6 – Zeppelin is an open-source interactive and collaborative notebook for data exploration using Spark. Zeppelin 0.5.6 adds the ability to import or export a notebook, notebook storage in GitHub, auto-save on navigation, and better Pyspark support. View the Zeppelin release notes or learn more about Zeppelin on Amazon EMR.
Zeppelin 0.5.6 – Zeppelin is an open-source interactive and collaborative notebook for data exploration using Spark. Zeppelin 0.5.6 adds the ability to import or export a notebook, notebook storage in GitHub, auto-save on navigation, and better Pyspark support. View the Zeppelin release notes or learn more about Zeppelin on Amazon EMR. Presto 0.136 – Presto is an open-source, distributed SQL query engine designed for low-latency queries on large datasets in Amazon S3 and HDFS. This is a minor version release, with support for larger arrays, SQL binary literals, the ability to call connector-defined procedures, and improvements to the web interface. View the Presto release notes or learn more about Presto on Amazon EMR.
Presto 0.136 – Presto is an open-source, distributed SQL query engine designed for low-latency queries on large datasets in Amazon S3 and HDFS. This is a minor version release, with support for larger arrays, SQL binary literals, the ability to call connector-defined procedures, and improvements to the web interface. View the Presto release notes or learn more about Presto on Amazon EMR. Sqoop 1.4.6 – Sqoop is a tool for transferring bulk data between HDFS, S3 (using EMRFS), and structured datastores such as relational databases. You can use Sqoop to transfer structured data from RDS and Aurora to EMR for processing, and write out results back to S3, HDFS, or another database. Learn more about Sqoop on Amazon EMR.
Sqoop 1.4.6 – Sqoop is a tool for transferring bulk data between HDFS, S3 (using EMRFS), and structured datastores such as relational databases. You can use Sqoop to transfer structured data from RDS and Aurora to EMR for processing, and write out results back to S3, HDFS, or another database. Learn more about Sqoop on Amazon EMR. Mahout 0.11.1 – Mahout is a collection of tools and libraries for building distributed machine learning applications. This release includes support for Spark as well as a new math environment based on Spark named Samsara. Learn more about Mahout on Amazon EMR.
Mahout 0.11.1 – Mahout is a collection of tools and libraries for building distributed machine learning applications. This release includes support for Spark as well as a new math environment based on Spark named Samsara. Learn more about Mahout on Amazon EMR.
 HCatalog 1.0.0 – HCatalog is a sub-project within the Apache Hive project. It is a table and storage management layer for Hadoop which utilizes the Hive Metastore. It enables tools to execute SQL on Hadoop through an easy to use REST interface.
HCatalog 1.0.0 – HCatalog is a sub-project within the Apache Hive project. It is a table and storage management layer for Hadoop which utilizes the Hive Metastore. It enables tools to execute SQL on Hadoop through an easy to use REST interface.
Enhancements to the default settings for Spark
We have improved our default configuration for Spark executors from the Apache defaults to better utilize resources on your cluster. Starting with release 4.4.0, EMR has enabled dynamic allocation of executors by default, which lets YARN determine how many executors to utilize when running a Spark application. Additionally, the amount of memory used for each executor is now automatically determined by the instance family used for your cluster’s core instance group.
Enabling dynamic allocation and customizing the executor memory allows Spark to utilize all resources on your cluster, place additional executors on nodes added to your cluster, and better allow for multitenancy for Spark applications. The previous maximizeResourceAllocation parameter is still available. However, this doesn’t use dynamic allocation, and specifies a static number of executors for your Spark application. You can also still override the new defaults by using the configuration API or passing additional parameters when submitting your Spark application using spark-submit. Learn more about Spark configuration on Amazon EMR.
Using Java 8 with your applications on Amazon EMR
By default, applications on your Amazon EMR cluster use the Java Development Kit 7 (JDK 7) for their runtime environment. However, on release 4.4.0, you can use JDK 8 by setting JAVA_HOME to point to JDK 8 for the relevant environment variables using a configuration object (though please note that JDK 8 is not compatible with Apache Hive). Learn more about using Java 8 on Amazon EMR.
Launch an Amazon EMR Cluster with Release 4.4.0 Today
To create an Amazon EMR cluster with 4.4.0, select release 4.4.0 on the Create Cluster page in the AWS Management Console, or use the release label emr-4.4.0 when creating your cluster from the AWS CLI or using a SDK with the EMR API.
— Rob Leidle – Development Manager, Amazon EMR
Amazon EMR Update – Support for EBS Volumes, and M4 & C4 Instance Types
My colleague Abhishek Sinha wrote the guest post below to tell you about the latest additions to Amazon EMR.
— Jeff;
Amazon EMR is a service that allows you to use distributed data processing frameworks such as Apache Hadoop, Apache Spark and Presto to process data on a managed cluster of EC2 instances.
Newer versions of EMR (3.10 and 4.x), allow you to use Amazon EBS volumes to increase the local storage of each instance. This works well with the existing set of supported instance types, and also gives you the ability to use the M4 and C4 instance types with EMR. Today I would like to tell you more about both of these features.
Increasing Instance Storage Using Amazon EBS
EMR uses the local storage of each instance for HDFS (Hadoop Distributed File System) and to store intermediate files when processing data from S3 using EMRFS. You can now use EBS volumes to extend this storage. The EBS volumes are tied to the lifecycle of the associated instances and augment any existing storage on the instance. If you terminate a cluster, any associated EBS volumes are also deleted along with it.
You will benefit from the ability to customize the storage of your EMR instances if…
- Your processing requirements demand a larger amount of HDFS (or local) storage than what is available by default on an instance. With support for EBS volumes, you will be able to customize the storage capacity on an instance relative to the compute capacity that the instance provides. Optimizing the storage on an instance will allow you to save costs.
- You want to take advantage of the latest generation EC2 instance types such as the M4, C4, and R3 and need more storage than is available on these instance types. You can now add EBS volumes to customize the storage in order to better meet your needs. If you’re using the older M1 and M2 instances, you should be able to reduce costs and improve performance by moving to newer M4, C4 and R3 instances. We recommend that you benchmark your application to measure the impact on your specific workloads.
It’s important to note that the EBS volumes added to an Amazon EMR cluster do not persist data after the cluster is shutdown. EMR will automatically clean up the volumes when you terminate your cluster.
Adding EBS Volumes to a Cluster
EMR currently groups the nodes in your cluster into 3 logical instance groups: a Master Group, which runs the YARN Resource Manager and the HDFS Name Node Service; a Core Group, which runs the HDFS DataNode Daemon and the YARN Node Manager Service; and Task Groups, which run the YARN Node Manager Service. EMR supports up to 50 instance groups per cluster and allows you to select an instance type for each group. You can now specify the amount of EBS storage you want to add to each instance in a given instance group. You can specify multiple EBS volumes, add EBS volumes to instances with instance storage, or even combine different volumes of different types. Here is how you specify your storage configuration in the EMR Console:
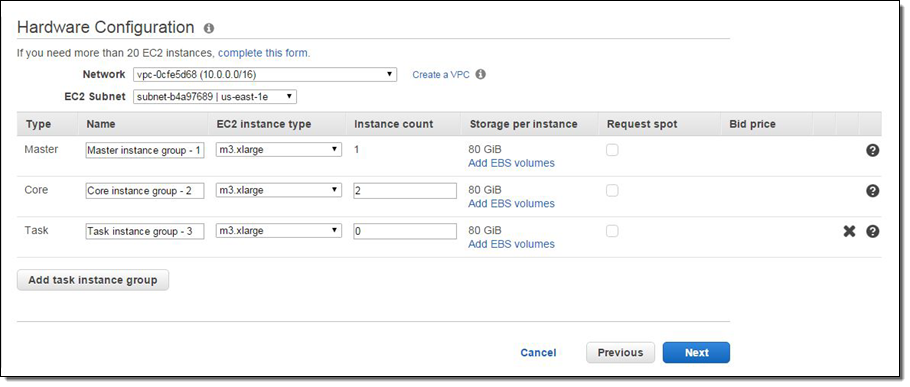
For example, if you configured a Core Group to use the m4.2xlarge instance, attached a pair of 1 TB gp2 (General Purpose SSD) volumes and want 10 instances in the group, the Core group would have 10 instances with a total of 20 volumes. Here’s how you would set that up:
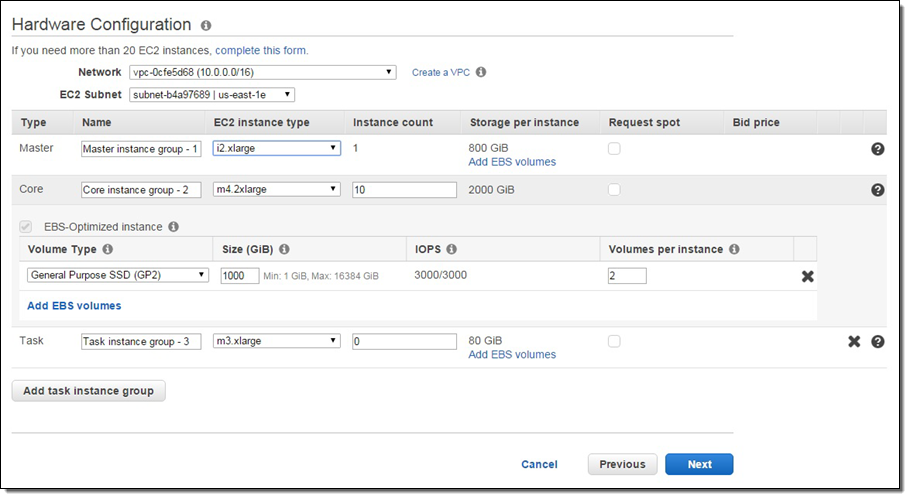
To learn more, read the EBS FAQ. Support for EBS is available starting with AMI 3.10 and EMR Release 4.0.
EBS Volume Performance Characteristics
Amazon EMR allows you to use several different EBS volume types: General Purpose SSD (GP2), Magnetic, and Provisioned IOPS (SSD). You can choose different types of volumes depending upon the nature of your job. Our internal testing suggests that the General Purpose SSD volumes should suffice for most of the workloads, however we recommend that you test against your own workload. One thing to note is that the General Purpose SSD volumes provide a baseline performance of 3 IOPS/GiB (up to 10,000 IOPS) with the ability to burst to 3,000 IOPS for volumes under 1,000 GiB. Please see I/O Credits and Burst Performance for more details. Here is a comparison of the volumes types:
| General Purpose (SSD) | Provisioned IOPS | Magnetic | |
| Storage Media | SSD-backed | SSD-backed | Magnetic-backed |
| Max Volume Size | 16 TB | 16 TB | 1 TB |
| Max IOPS per Volume | 10,000 IOPS | 20,000 IOPS | ~100 IOPS |
| Max IOPS Burst Performance | 3000 IOPS for volumes <= 1TB | n/a | Hundreds |
| Max Throughput per Volume | 160 MB/second | 320 MB/second | 40-90 MB/second |
| Max IOPS per Node (16K) | 48,000 | 48,000 | 48,000 |
| Max Throughput per Instance | 800 MB/second | 800 MB/second | 800 MB/second |
| Latency (Random Read) | 1-2 ms | 1-2 ms | 20-40 ms |
| API Name | gp2 | io1 | standard |
Support for M4 and C4 Instances
You can now launch EMR clusters that use M4 and C4 instances in regions where they are available. The M4 instances feature a custom Intel Xeon E5-2676 v3 (Haswell) processor and the C4 instances are based on the Intel Xeon E5-2666 v3 processor. These instances are designed to deliver the highest level of processor performance on EC2. Both types of instances offer Enhanced Networking which delivers up to 4 times the packet rate of instances without Enhanced Networking, while ensuring consistent latency, even when under high network I/O. Both the M4 and C4 instances are EBS-Optimized by default, with additional, dedicated network capacity for I/O operations. The instances support 64-bit HVM AMIs and can be launched only within a VPC.
Please see the Amazon EMR Pricing page for more details on the prices for these instances.
Productivity Tip
You can generate a create-cluster command that represents the configuration of an existing EMR 4.x cluster, including the EBS volumes. This will allow you to recreate the cluster using the AWS Command Line Interface (CLI).
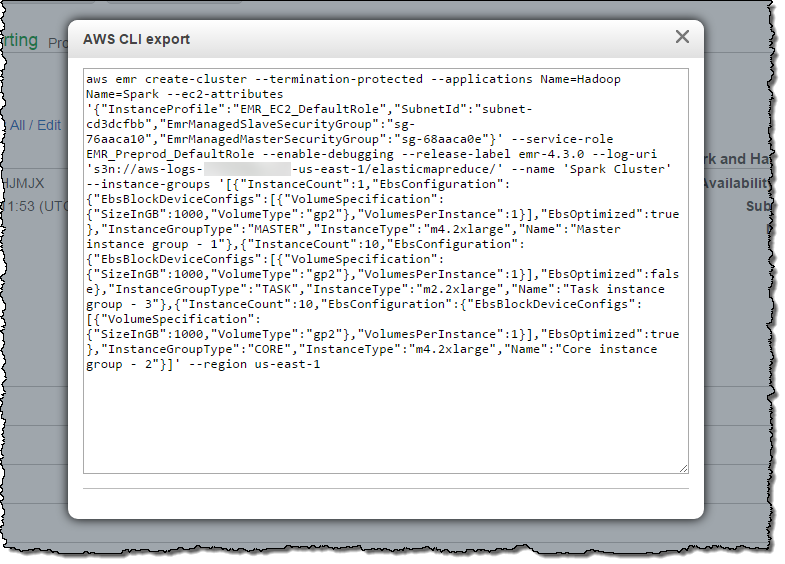
Available Now
These new features are available now and you can start using them today!
— Abhishek Sinha, Senior Product Manager
EMR 4.3.0 – New & Updated Applications + Command Line Export
My colleague Jon Fritz wrote the blog post below to introduce you to some new features of Amazon EMR.
— Jeff;
Today we are announcing Amazon EMR release 4.3.0, which adds support for Apache Hadoop 2.7.1, Apache Spark 1.6.0, Ganglia 3.7.2, and a new sandbox release for Presto (0.130). We have also enhanced our maximizeResourceAllocation setting for Spark and added an AWS CLI Export feature to generate a create-cluster command from the Cluster Details page in the AWS Management Console.
New Applications in Release 4.3.0
Amazon EMR provides an easy way to install and configure distributed big data applications in the Hadoop and Spark ecosystems on managed clusters of Amazon EC2 instances. You can create Amazon EMR clusters from the Amazon EMR Create Cluster Page in the AWS Management Console, AWS Command Line Interface (CLI), or using a SDK with an EMR API. In the latest release, we added support for several new versions of the following applications:
- Spark 1.6.0 – Spark 1.6.0 was released on January 4th by the Apache Foundation, and we’re excited to include it in Amazon EMR within four weeks of open source GA. This release includes several new features like compile-time type safety using the Dataset API (SPARK-9999), machine learning pipeline persistence using the Spark ML Pipeline API (SPARK-6725), a variety of new machine learning algorithms in Spark ML, and automatic memory management between execution and cache memory in executors (SPARK-10000). View the release notes or learn more about Spark on Amazon EMR.
- Presto 0.130 – Presto is an open-source, distributed SQL query engine designed for low-latency queries on large datasets in Amazon S3 and HDFS. This is a minor version release, with optimizations to SQL operations and support for S3 server-side and client-side encryption in the PrestoS3Filesystem. View the release notes or learn more about Presto on Amazon EMR.
- Hadoop 2.7.1 – This release includes improvements to and bug fixes in YARN, HDFS, and MapReduce. Highlights include enhancements to FileOutputCommitter to increase performance of MapReduce jobs with many output files (MAPREDUCE-4814) and adding support in HDFS for truncate (HDFS-3107) and files with variable-length blocks (HDFS-3689). View the release notes or learn more about Amazon EMR.
- Ganglia 3.7.2 – This release includes new features such as building custom dashboards using Ganglia Views, setting events, and creating new aggregate graphs of metrics. Learn more about Ganglia on Amazon EMR.
Enhancements to the maximizeResourceAllocation Setting for Spark
Currently, Spark on your Amazon EMR cluster uses the Apache defaults for Spark executor settings, which are 2 executors with 1 core and 1GB of RAM each. Amazon EMR provides two easy ways to instruct Spark to utilize more resources across your cluster. First, you can enable dynamic allocation of executors, which allows YARN to programmatically scale the number of executors used by each Spark application, and adjust the number of cores and RAM per executor in your Spark configuration. Second, you can specify maximizeResourceAllocation, which automatically sets the executor size to consume all of the resources YARN allocates on a node and the number of executors to the number of nodes in your cluster (at creation time). These settings create a way for a single Spark application to consume all of the available resources on a cluster. In release 4.3.0, we have enhanced this setting by automatically increasing the Apache defaults for driver program memory based on the number of nodes and node types in your cluster (more information about configuring Spark).
AWS CLI Export in the EMR Console
You can now generate an EMR create-cluster command representative of an existing cluster with a 4.x release using the AWS CLI Export option on the Cluster Details page in the AWS Management Console. This allows you to quickly create a cluster using the Create Cluster experience in the console, and easily generate the AWS CLI script to recreate that cluster from the AWS CLI.
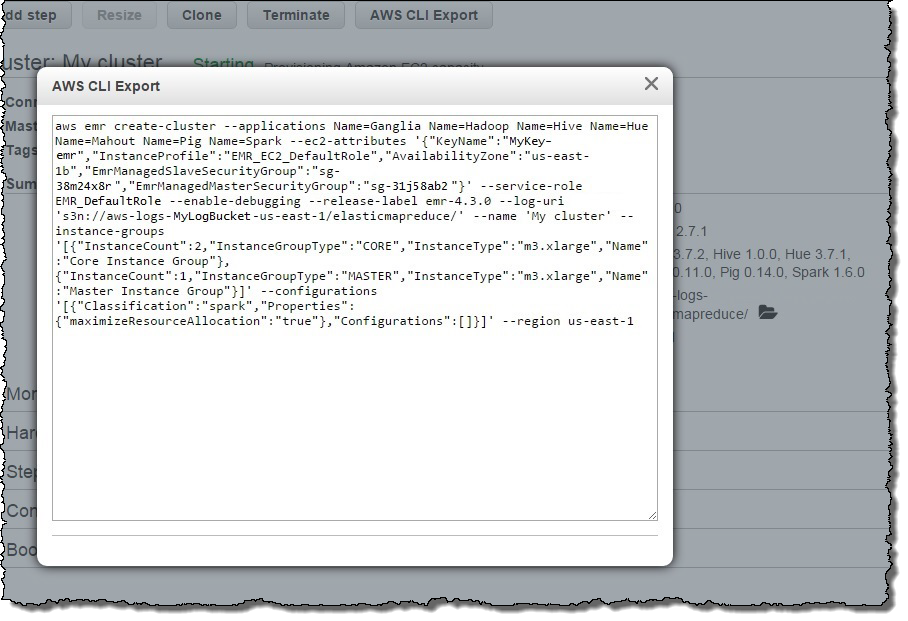
Launch an Amazon EMR Cluster with Release 4.3.0 Today
To create an Amazon EMR cluster with 4.3.0, select release 4.3.0 on the Create Cluster page in the AWS Management Console, or use the release label emr-4.3.0 when creating your cluster from the AWS CLI or using a SDK with the EMR API.
— Jon Fritz, Senior Product Manager, Amazon EMR
New – Launch Amazon EMR Clusters in Private Subnets
My colleague Jon Fritz wrote the guest post below to introduce you to an important new feature for Amazon EMR.
— Jeff;
Today we are announcing that Amazon EMR now supports launching clusters in Amazon Virtual Private Cloud (VPC) private subnets, allowing you to quickly, cost-effectively, and securely create fully configured clusters with Hadoop ecosystem applications, Spark, and Presto in the subnet of your choice. With Amazon EMR release 4.2.0 and later, you can launch your clusters in a private subnet with no public IP addresses or attached Internet gateway. You can create a private endpoint for Amazon S3 in your subnet to give your Amazon EMR cluster direct access to data in S3, and optionally create a Network Address Translation (NAT) instance for your cluster to interact with other AWS services, like Amazon DynamoDB and AWS Key Management Service (KMS). For more information on Amazon EMR in VPC, visit the Amazon EMR documentation.
Network Topology for Amazon EMR in a VPC Private Subnet
Before launching an Amazon EMR cluster in a VPC private subnet, please make sure you have the required permissions in your EMR service role and EC2 instance profile, and that you have a route (either through a route from your subnet to an S3 endpoint in your VPC or a NAT/Proxy instance) to the required S3 buckets for your cluster’s initialization. Click here for more information about configuring your subnet.
You can use the new VPC Subnets page in the EMR Console to view the VPC subnets available for your clusters, and configure them by adding S3 endpoints and NAT instances:
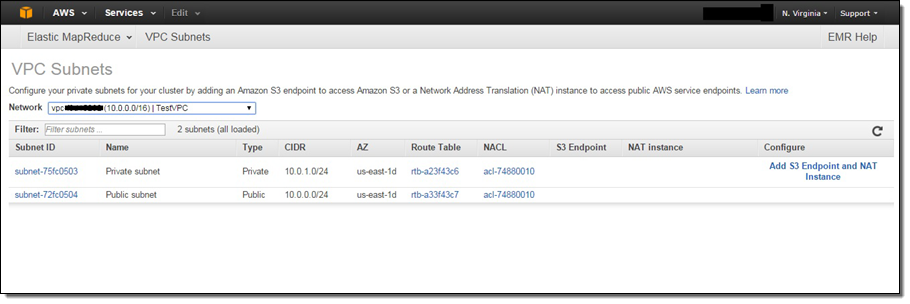
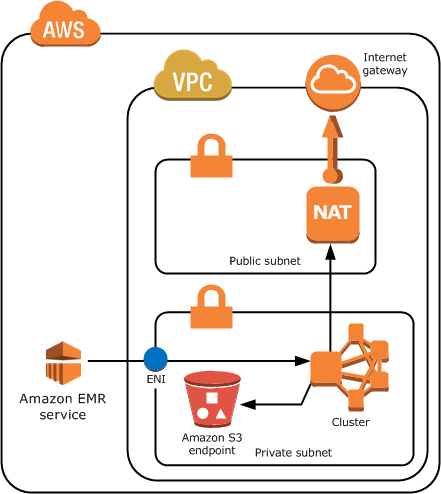
Also, here is a sample network topology for an Amazon EMR cluster in a VPC private subnet with a S3 endpoint and NAT instance. However, if you do not need to use your cluster with AWS services besides S3, you do not need a NAT instance to provide a route to those public endpoints:
Encryption at Rest for Amazon S3 (with EMRFS), HDFS, and Local Filesystem
A typical Hadoop or Spark workload on Amazon EMR utilizes Amazon S3 (using the EMR Filesystem – EMRFS) for input datasets/output results and two filesystems located on your cluster: the Hadoop Distributed Filesystem (HDFS) distributed across your cluster and the Local Filesystem on each instance. Amazon EMR makes it easy to enable encryption for each filesystem, and there are a variety of options depending on your requirements:
- Amazon S3 Using the EMR Filesystem (EMRFS) – EMRFS supports several Amazon S3 encryption options (using AES-256 encryption), allowing Hadoop and Spark on your cluster to performantly and transparently process encrypted data in S3. EMRFS seamlessly works with objects encrypted by S3 Server-Side Encryption or S3 client-side encryption. When using S3 client-side encryption, you can use encryption keys stored in the AWS Key Management Service or in a custom key management system in AWS or on-premises.
- HDFS Transparent Encryption with Hadoop KMS – The Hadoop Key Management Server (KMS) can supply keys for HDFS Transparent Encryption, and it is installed on the master node of your EMR cluster with HDFS. Because encryption and decryption activities are carried out in the client, data is also encrypted in-transit in HDFS. Click here for more information.
- Local Filesystem on Each Node – The Hadoop MapReduce and Spark frameworks utilize the Local Filesystem on each slave instance for intermediate data throughout a workload. You can use a bootstrap action to encrypt the directories used for these intermediates on each node using LUKS.
Encryption in Transit for Hadoop MapReduce and Spark
Hadoop ecosystem applications installed on your Amazon EMR cluster typically have different mechanisms to encrypt data in transit:
- Hadoop MapReduce Shuffle – In a Hadoop MapReduce job, Hadoop will send data between nodes in your cluster in the shuffle phase, which occurs before the reduce phase of the job. You can use SSL to encrypt this process by enabling the Hadoop settings for Encrypted Shuffle and providing the required SSL certificates to each node.
- HDFS Rebalancing – HDFS rebalances by sending blocks between DataNode processes. However, if you use HDFS Transparent Encryption (see above), HDFS never holds unencrypted blocks and the blocks remain encrypted when moved between nodes.
- Spark Shuffle – Spark, like Hadoop MapReduce, also shuffles data between nodes at certain points during a job. Starting with Spark 1.4.0, you can encrypt data in this stage using SASL encryption.
IAM Users and Roles, and Auditing with AWS CloudTrail
You can use Identity and Access Management (IAM) users or federated users to call the Amazon EMR APIs, and limit the API calls that each user can make. Additionally, Amazon EMR requires clusters to be created with two IAM roles, an EMR service role and EC2 instance profile, to limit the permissions of the EMR service and EC2 instances in your cluster, respectively. EMR provides default roles using EMR Named Policies for automatic updates, however, you can also provide custom IAM roles for your cluster. Finally, you can audit the calls your account has made to the Amazon EMR API using AWS CloudTrail.
EC2 Security Groups and Optional SSH Access
Amazon EMR uses two security groups, one for the Master Instance Group and one for slave instance groups (Core and Task Instance Groups), to limit ingress and egress to the instances in your cluster. EMR provides two default security groups, but you can provide your own (assuming they have the necessary ports open for communication between the EMR service and the cluster) or add additional security groups to your cluster. In a private subnet, you can also specify the security group added to the ENI used by the EMR service to communicate with your cluster.
Also, you can optionally add an EC2 key pair to the Master Node of your cluster if you would like to SSH to that node. This allows you to directly interact with the Hadoop applications installed on your cluster, or access web-UIs for applications using a proxy without opening up ports in your Master Security Group.
Hadoop and Spark Authentication and Authorization
Because Amazon EMR installs open source Hadoop ecosystem applications on your cluster, you can also leverage existing security features in these products. You can enable Kerberos authentication for YARN, which will give user-level authentication for applications running on YARN (like Hadoop MapReduce and Spark). Also, you can enable table and SQL-level authorization for Hive using HiveServer2 features, and use LDAP integration to create and authenticate users in Hue.
Run your workloads securely on Amazon EMR
Earlier this year, Amazon EMR was added to the AWS Business Associates Agreement (BAA) for running workloads which process PII data (including eligibility for HIPAA workloads). Amazon EMR also has certification for PCI DSS Level 1, ISO 9001, ISO 27001, and ISO 27018.
Security is a top priority for us and our customers. We are continuously adding new security-related functionality and third-party compliance certifications to Amazon EMR in order to make it even easier to run secure workloads and configure security features in Hadoop, Spark, and Presto.
— Jon Fritz, Senior Product Manager, Amazon EMR
PS – To learn more, read Securely Access Web Interfaces on Amazon EMR Launched in a Private Subnet on the AWS Big Data Blog.