Category: AWS Lambda
AWS Snowball Edge – More Storage, Local Endpoints, Lambda Functions
A I was preparing to write this blog post I went back and read the post I wrote when we launched AWS Snowball last year (AWS Import/Export Snowball – Transfer 1 Petabyte Per Week Using Amazon-Owned Storage Appliances) and then cataloged all of the updates that we have made since then. To recap, Snowball started out as a 50 TB data transfer appliance, designed with physical integrity and data security at top of mind. In a little over a year we have made many incremental improvements including increased capacity (80 TB), a job management API, HIPAA-eligibility, HDFS import, an S3 adapter, and availability in additional AWS Regions.
While all of these improvements were important they did not change the basic character of the appliance. Over the past year or so, with many AWS customers putting the original Snowball to work in many different types of physical environments and on a very wide variety of migration, big data, genomics, and data collection workloads, we have seen that there’s room to make this appliance even more functional.
Many customers are generating large amounts of data (often hundreds of terabytes) in situations where network connectivity is limited or non-existent and the physical environment is extreme. Customers want to collect data that they generate in farms, factories, hospitals, aircraft, and oil wells. From shop floor metrics to video surveillance, to information collected by IoT devices, customers are interested in a model that goes beyond straightforward store-and-forward data to collection, and would like to be able to do some local processing as the data arrives. They want to filter, clean, analyze, organize, track, summarize, and monitor the data as it arrives. They want to scan incoming data for patterns or problems, and raise alerts quickly if something interesting is detected.
New Snowball Edge
 Today we are adding Snowball Edge to the lineup. This appliance expands the scope of the Snowball, adding more connectivity, more storage, horizontal scalability via clustering, new storage endpoints that can be accessed from existing S3 and NFS clients, and Lambda-powered local processing.
Today we are adding Snowball Edge to the lineup. This appliance expands the scope of the Snowball, adding more connectivity, more storage, horizontal scalability via clustering, new storage endpoints that can be accessed from existing S3 and NFS clients, and Lambda-powered local processing.
Physically, Snowball Edge is designed to be at home in rough-and-tumble industrial, aerospace, agricultural, and military environments. The new form factor is also suitable for rack mounting in situations where you are taking advantage of the new clustering feature.
Let’s take a quick look at all of the new features!
More Connectivity
This appliance is well-connected, and gives you plenty of high-speed options.
On the network side you can use 10GBase-T, 10 or 25 Gb SFP28, or 40 Gb QSFP+. Your IoT devices can upload data using 3G cellular or Wi-Fi. If that’s not enough, there’s also a PCIe expansion port.
You have access to enough connectivity to copy data to Snowball Edge at up to 14 Gb per second; you can copy 100 TB in 19 hours or so. Beginning-to-end (initiate data transfer to data available in S3) the entire process takes a week, including shipping and handling along the way.
More Storage
Snowball Edge includes 100 TB of storage.
Horizontal Scaling via Clustering
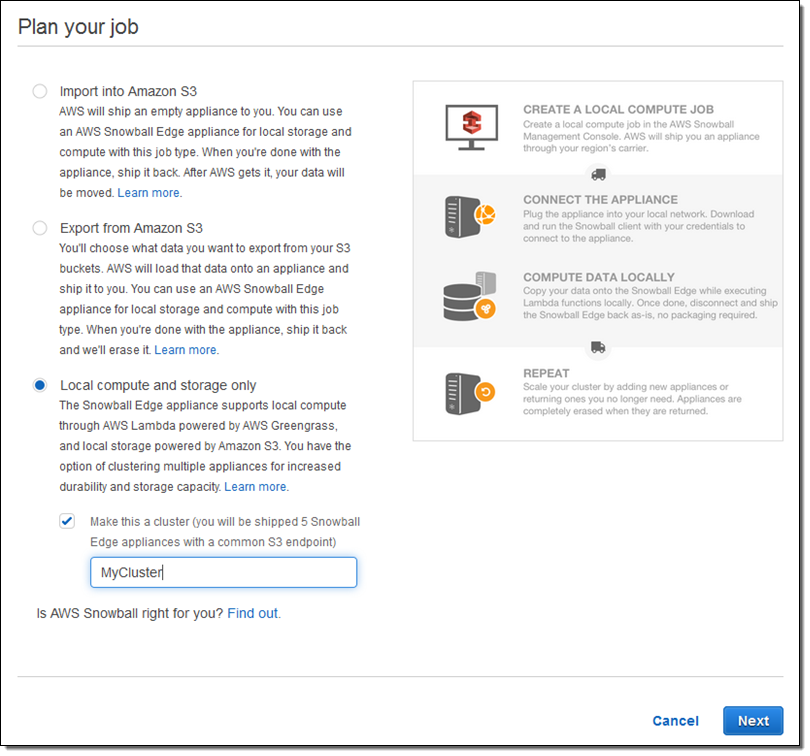
You can easily configure 2 or more Snowball Edge appliances into a cluster to add capacity and to increase durability, while keeping all of the storage accessible through a single endpoint. For example, clustering 6 appliances will create a highly available cluster with 400 TB of storage and 99.999% durability. This allows you to remove 2 of the appliances and still keep your data protected.
You can grow clusters up to petabyte scale, and you can shrink them by simply removing and returning appliances. The clusters are self-managing and you don’t need to worry about software updates or other tedium.
Order a cluster by simply checking Local compute and storage only and Make this a cluster when you set up your job:
New Storage Endpoints (S3 and NFS)
If you have existing backup, archiving, or data transfer tools that “speak” S3 or NFS, you can now use them to store and access data stored on Snowball Edge. If you create a cluster of 2 or more appliances, the same endpoint applies to all of them; this allows you to think of your cluster as local, network-attached storage.
Snowball Edge supports a powerful subset of the S3 API, including LIST, GET, PUT, DELETE, HEAD, and Multipart Upload. It also supports NFS v3 and NFS 4.1.
When you use Snowball Edge as a file storage gateway and access it via NFS, file and directory metadata (permissions, ownership, and timestamps) is mapped to S3 metadata, and preserved when the data is ingested to S3. You can use this feature to migrate data, bootstrap your usage of AWS Storage Gateway, or to store on-premises files for sharing between on-premises apps.
Lambda-Powered Local Processing
You can now write AWS Lambda functions in Python and use them to process data as it is uploaded to an S3 bucket associated with a Snowball Edge.
The functions can (as I hinted at earlier) filter, clean, analyze, organize, track, summarize the data as it arrives. Snowball Edge gives you the ability to add intelligence and sophistication to your data collection and data processing systems.
We are starting out with support for the S3 PUT operation, and you can use one function per bucket. The functions must be written in Python, and are run in a Lambda environment that is configured for 128 MB of memory.
You configure your functions when you order your Snowball Edge:
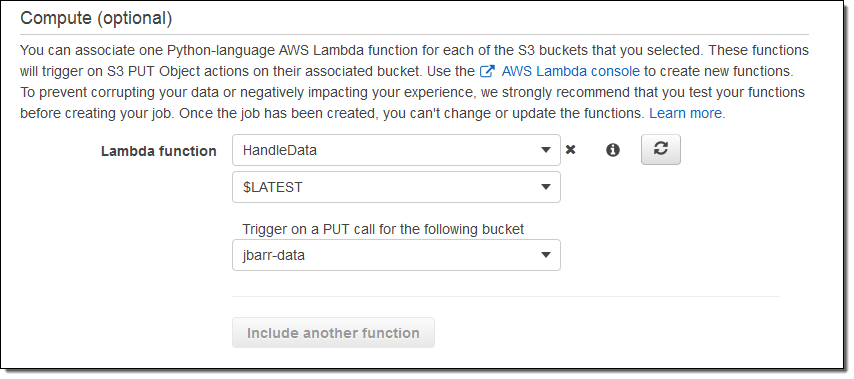
We do recommend that you test your functions in the cloud before placing your order.
Pricing and Availability
Snowball Edge is designed to be deployed in plug-and-play fashion. Your colleagues in the field don’t have to configure or administer it. The on-board LCD panel displays status information and plays setup videos. The on-board code is self-updating; there’s no routine software maintenance. You can check the status and make late-breaking configuration changes to deployed appliances through the AWS Management Console (API and CLI access is also available).
Each Snowball Edge job costs $300 plus shipping. You can keep each appliance for up to 10 days; after that you’ll be charged $30 per appliance per day. You can run Lambda functions locally at no charge.
You can learn more by attending our webinar December 15th. Register here.
— Jeff;
CloudTrail Update – Capture and Process Amazon S3 Object-Level API Activity
I would like to show you how several different AWS services can be used together to address a challenge faced by many of our customers. Along the way I will introduce you to a new AWS CloudTrail feature that launches today and show you how you can use it in conjunction with CloudWatch Events.
The Challenge
Our customers store many different types of mission-critical data in Amazon Simple Storage Service (S3) and want to be able to track object-level activity on their data. While some of this activity is captured and stored in the S3 access logs, the level of detail is limited and log delivery can take several hours. Customers, particularly in financial services and other regulated industries, are asking for additional detail, delivered on a more timely basis. For example, they would like to be able to know when a particular IAM user accesses sensitive information stored in a specific part of an S3 bucket.
In order to meet the needs of these customers, we are now giving CloudTrail the power to capture object-level API activity on S3 objects, which we call Data events (the original CloudTrail events are now called Management events). Data events include “read” operations such as GET, HEAD, and Get Object ACL as well as “write” operations such as PUT and POST. The level of detail captured for these operations is intended to provide support for many types of security, auditing, governance, and compliance use cases. For example, it can be used to scan newly uploaded data for Personally Identifiable Information (PII), audit attempts to access data in a protected bucket, or to verify that the desired access policies are in effect.
Processing Object-Level API Activity
Putting this all together, we can easily set up a Lambda function that will take a custom action whenever an S3 operation takes place on any object within a selected bucket or a selected folder within a bucket.
Before starting on this post, I created a new CloudTrail trail called jbarr-s3-trail:
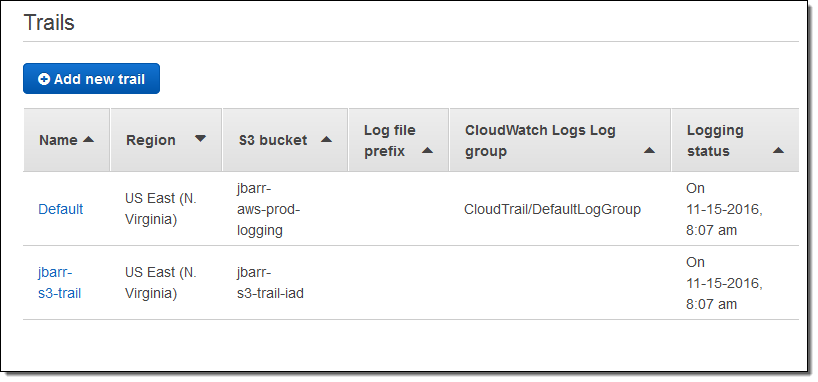
I want to use this trail to log object-level activity on one of my S3 buckets (jbarr-s3-trail-demo). In order to do this I need to add an event selector to the trail. The selector is specific to S3, and allows me to focus on logging the events that are of interest to me. Event selectors are a new CloudTrail feature and are being introduced as part of today’s launch, in case you were wondering.
I indicate that I want to log both read and write events, and specify the bucket of interest. I can limit the events to part of the bucket by specifying a prefix, and I can also specify multiple buckets. I can also control the logging of Management events:
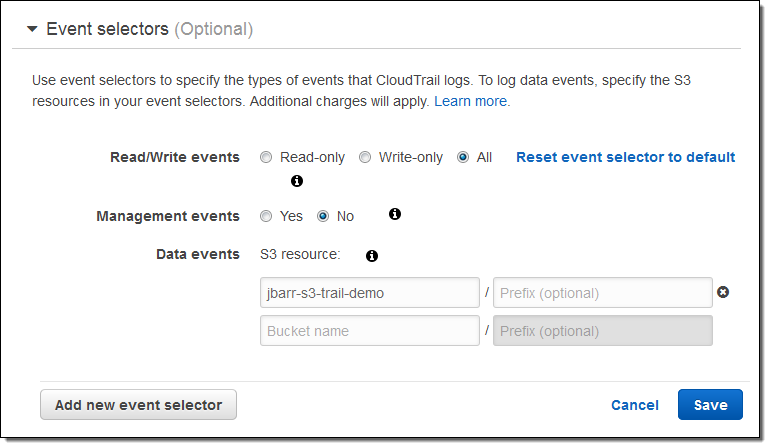
CloudTrail supports up to 5 event selectors per trail. Each event selector can specify up to 50 S3 buckets and optional bucket prefixes.
I set this up, opened my bucket in the S3 Console, uploaded a file, and took a look at one of the entries in the trail. Here’s what it looked like:
{
"eventVersion": "1.05",
"userIdentity": {
"type": "Root",
"principalId": "99999999999",
"arn": "arn:aws:iam::99999999999:root",
"accountId": "99999999999",
"username": "jbarr",
"sessionContext": {
"attributes": {
"creationDate": "2016-11-15T17:55:17Z",
"mfaAuthenticated": "false"
}
}
},
"eventTime": "2016-11-15T23:02:12Z",
"eventSource": "s3.amazonaws.com",
"eventName": "PutObject",
"awsRegion": "us-east-1",
"sourceIPAddress": "72.21.196.67",
"userAgent": "[S3Console/0.4]",
"requestParameters": {
"X-Amz-Date": "20161115T230211Z",
"bucketName": "jbarr-s3-trail-demo",
"X-Amz-Algorithm": "AWS4-HMAC-SHA256",
"storageClass": "STANDARD",
"cannedAcl": "private",
"X-Amz-SignedHeaders": "Content-Type;Host;x-amz-acl;x-amz-storage-class",
"X-Amz-Expires": "300",
"key": "ie_sb_device_4.png"
}
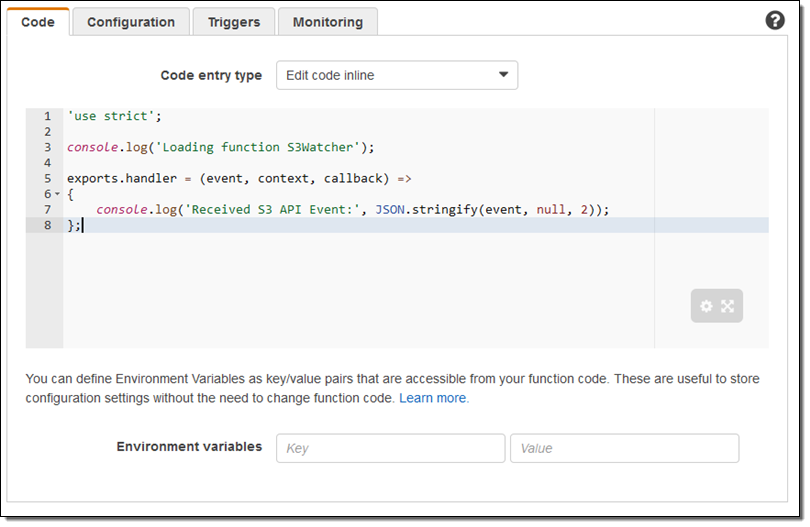
Then I create a simple Lambda function:
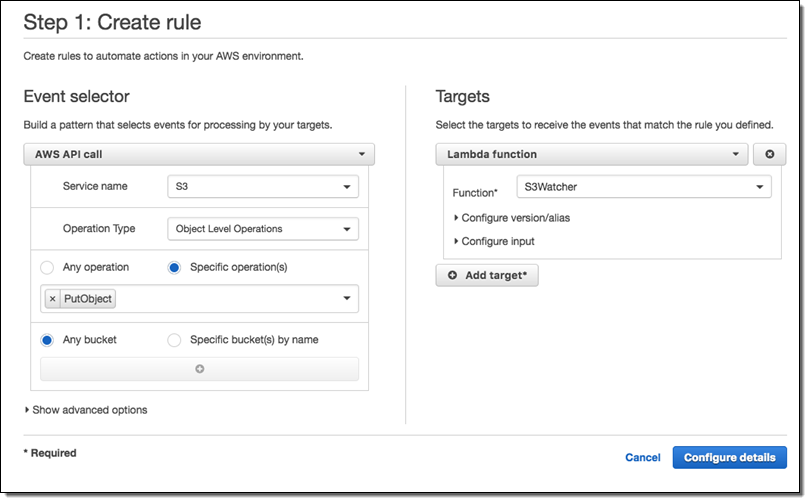
Next, I create a CloudWatch Events rule that matches the function name of interest (PutObject) and invokes my Lambda function (S3Watcher):
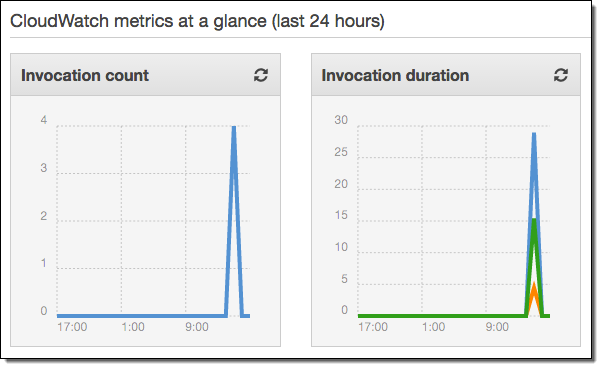
Now I upload some files to my bucket and check to see that my Lambda function has been invoked as expected:
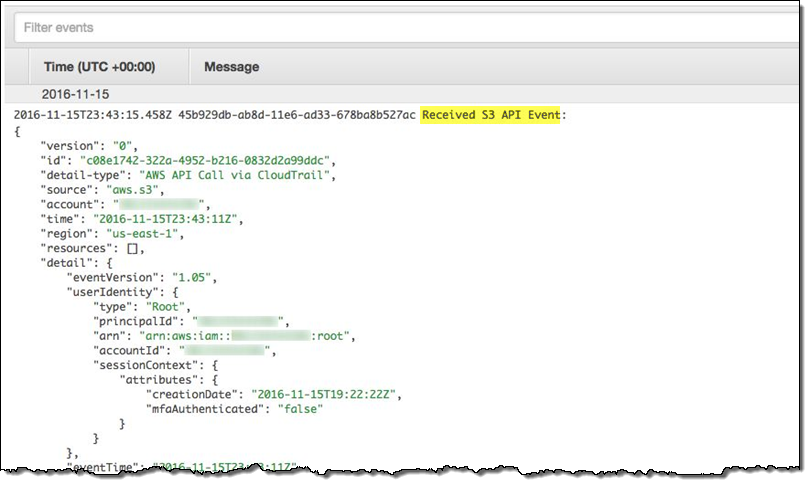
I can also find the CloudWatch entry that contains the output from my Lambda function:
Pricing and Availability
Data events are recorded only for the S3 buckets that you specify, and are charged at the rate of $0.10 per 100,000 events. This feature is available in all commercial AWS Regions.
— Jeff;
New for AWS Lambda – Environment Variables and Serverless Application Model (SAM)
I am thrilled by all of the excitement that I see around AWS Lambda and serverless application development. I have shared many serverless success stories, tools, and open source projects in the AWS Week in Review over the last year or two.
Today I would like to tell you about two important additions to Lambda: environment variables and the new Serverless Application Model.
Environment Variables
Every developer likes to build code that can be used in more than one environment. In order to do this in a clean and reusable fashion, the code should be able to accept configuration values at run time. The configuration values customize the environment for the code: table names, device names, file paths, and so forth. For example, many projects have distinct configurations for their development, test, and production environments.
You can now supply environment variables to your Lambda functions. This allows you to effect configuration changes without modifying or redeploying your code, and should make your serverless application development even more efficient. Each environment variable is a key/value pair. The keys and the values are encrypted using AWS Key Management Service (KMS) and decrypted on an as-needed basis. There’s no per-function limit on the number of environment variables, but the total size can be no more than 4 kb.
When you create a new version of a Lambda function, you also set the environment variables for that version of the function. You can modify the values for the latest version of the function, but not for older versions. Here’s how I would create a simple Python function, set some environment variables, and then reference them from my code (note that I had to import the os library):
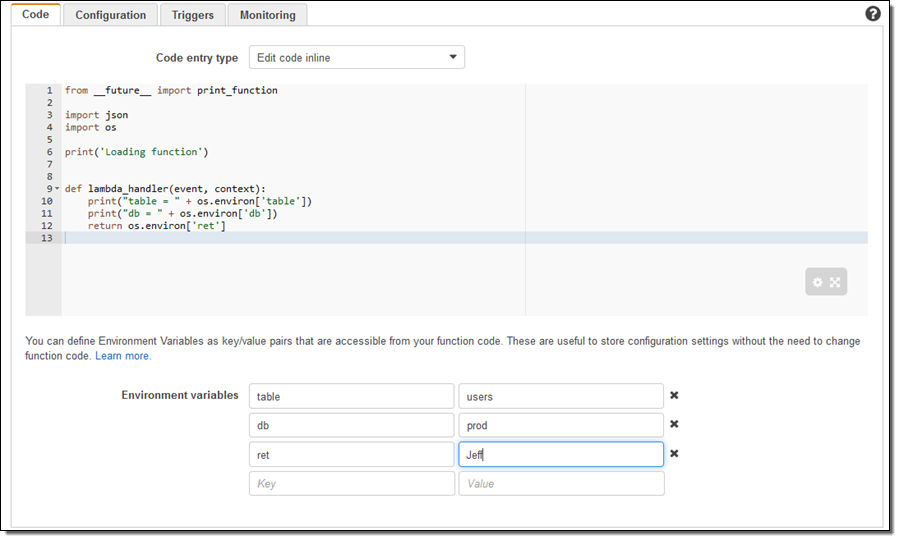
There’s no charge for this feature if you use the default service key provided by Lambda (the usual per-request KMS charges apply if you choose to use your own key).
To learn more and to get some ideas for other ways to make use of this new feature, read Simplify Serverless Applications With Lambda Environment Variables on the AWS Compute Blog.
AWS Serverless Application Model
Lambda functions, Amazon API Gateway resources, and Amazon DynamoDB tables are often used together to build serverless applications. The new AWS Serverless Application Model (AWS SAM) allows you describe all of these components using a simplified syntax that is natively supported by AWS CloudFormation. In order to use this syntax, your CloudFormation template must include a Transform section (this is a new aspect of CloudFormation) that looks like this:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
The remainder of the template is used to specify the Lambda functions, API Gateway endpoints & resources, and DynamoDB tables. Each function declaration specifies a handler, a runtime, and a URI to a ZIP file that contains the code for the function.
APIs can be declared implicitly by defining events, or explicitly, by providing a Swagger file.
DynamoDB tables are declared using a simplified syntax that requires just a table name, a primary key (name and type), and the provisioned throughput. The full range of options is also available for you to use if necessary.
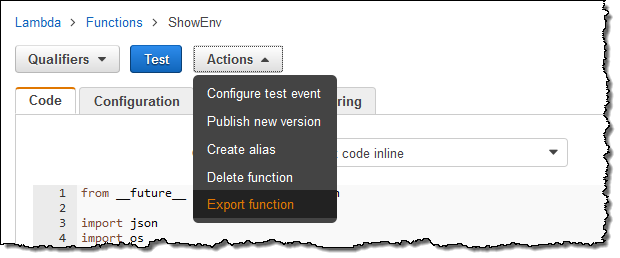
You can now generate AWS SAM files and deployment packages for your Lamba functions using a new Export operation in the Lambda Console. Simply click on the Actions menu and select Export function:
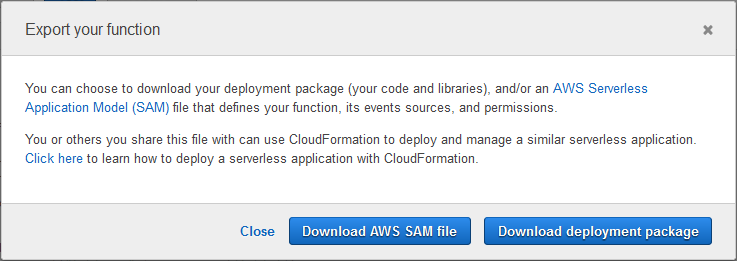
Then click on Download AWS SAM file or Download deployment package:
Here is the AWS SAM file for my function:
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Description: A starter AWS Lambda function.
Resources:
ShowEnv:
Type: 'AWS::Serverless::Function'
Properties:
Handler: lambda_function.lambda_handler
Runtime: python2.7
CodeUri: .
Description: A starter AWS Lambda function.
MemorySize: 128
Timeout: 3
Role: 'arn:aws:iam::99999999999:role/LambdaGeneralRole'The deployment package is a ZIP file with the code for my function inside. I would simply upload the file to S3 and update the CodeUri in the SAM file in order to use it as part of my serverless application. You can do this manually or you can use a pair of new CLI commands (aws cloudformation package and aws cloudformation deploy) to automate it. To learn more about this option, read the section on Deploying a Serverless app in the new Introducing Simplified Serverless Application Management and Deployment post.
You can also export Lambda function blueprints. Simply click on the download link in the corner:
And click on Download blueprint:
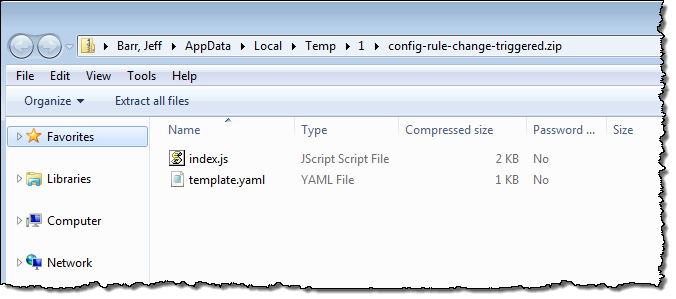
The ZIP file contains the AWS SAM file and the code:
To learn more and to see this new specification in action, read Introducing Simplified Serverless Application Management and Deployment on the AWS Compute Blog.
— Jeff;
New – CloudWatch Events for EBS Snapshots
Cloud computing can improve upon traditional IT operations by giving you the power to automate complex high-level operations that were formerly kept in a runbook or passed along as tribal knowledge. Far too many of these operations involve backup and recovery operations, especially in smaller and less mature organizations.
Many AWS customers make great use of Amazon Elastic Block Store (EBS) volumes, especially given the ease with which they can generate and manage snapshot backups. They are also copying snapshots between regions on a regular basis for disaster recovery and other operational reasons.
Today we are bringing the benefits of automation to EBS with the addition of new CloudWatch Events for EBS snapshots. You can use these events to add additional automation to your cloud-based backup environment. Here are the new events:
- createSnapshot – Fired after the status of a newly created EBS snapshot changes to Complete.
- copySnapshot – Fired after the status of a snapshot copy changes to Complete.
- shareSnapshot – Fired after a snapshot is shared with your AWS account.
A lot of AWS customers monitor the status of their snapshots by making repeated calls to the DescribeSnapshots function and then stepping through the paginated output in order to locate a specific snapshot. These new events open the door to all sorts of event-driven automation, including the cross-region copy that I mentioned earlier.
Using Snapshot Events
In order to get a better understanding of how this feature helps to automate data backup workflows, I’ll create a workflow that copies a completed snapshot to another region. First, I’ll create an IAM policy that grants appropriate permissions. Then I will incorporate an AWS Lambda function (created by my colleagues) that takes action on the createSnapshot event. Finally, I’ll create a CloudWatch Events rule to capture the event and route it to the Lambda function.
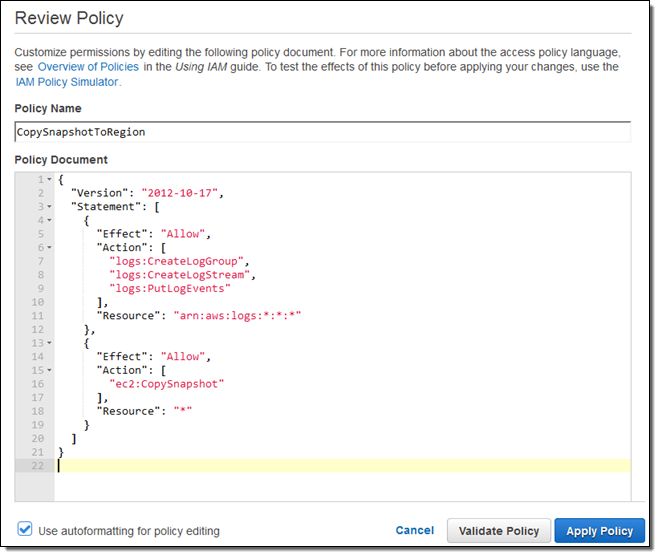
I start out by creating an IAM role (CopySnapshotToRegion) with this policy:
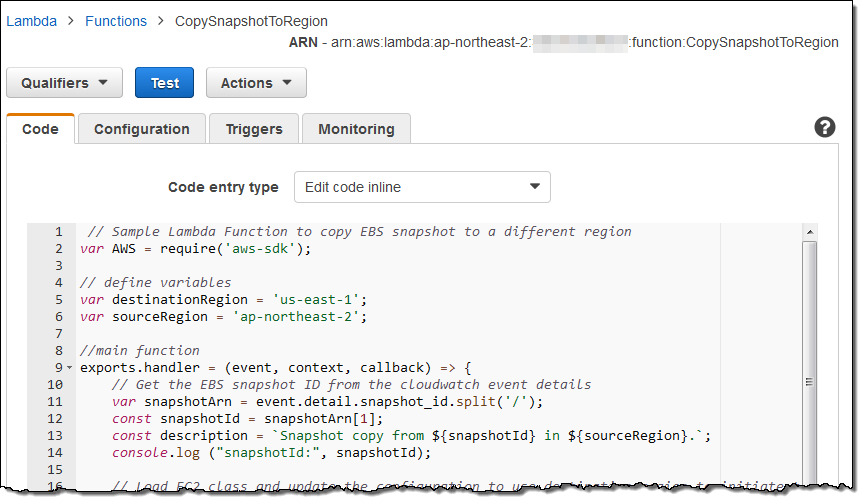
Then I created a new Lambda function (you can find the code at Amazon CloudWatch Events for EBS):
Next, I hopped over to the CloudWatch Events Console, clicked on Create rule, and set it up to handle successful createSnapshot events:
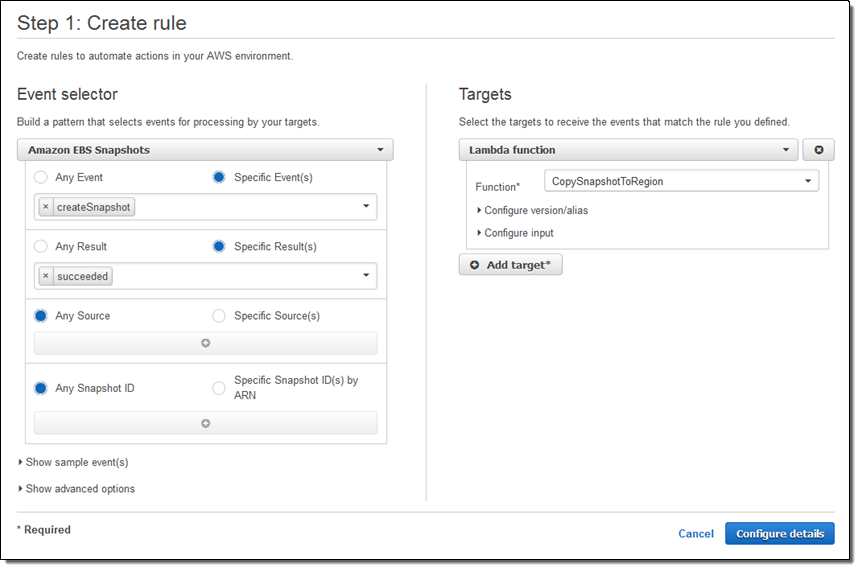
And gave it a name:
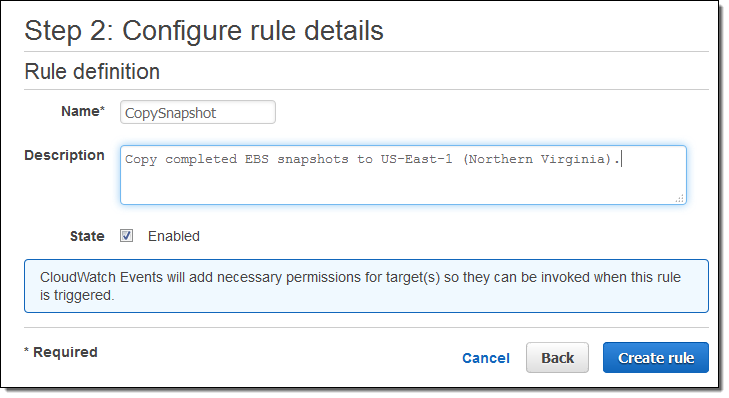
To test it out, I create a new EBS snapshot in my source region:
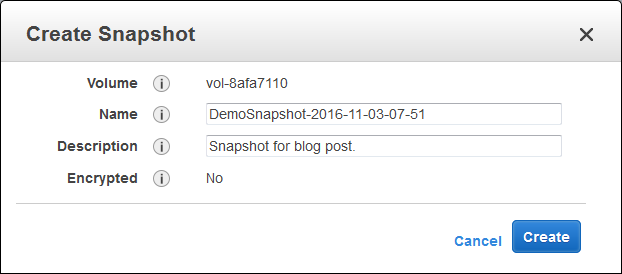
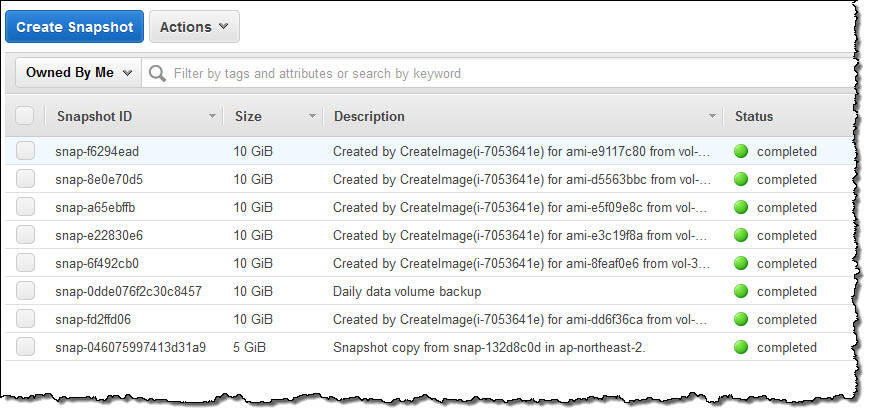
The function was invoked as expected and the snapshot was copied to the target region within seconds (in practice, the copy time will depend on the size of the snapshot):
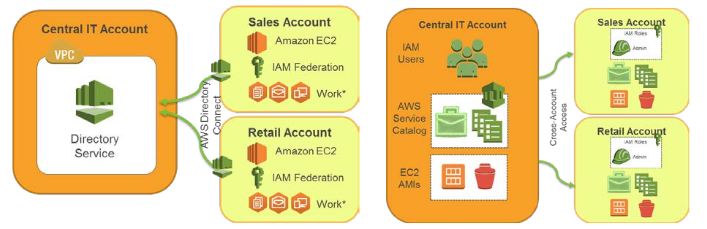
You can also use these events to make copies of snapshots that are shared with you from other accounts. Many AWS customers partition their usage across multiple accounts for various organizational and security reasons; take a look at our AWS Multiple Account Security Strategy to see our in-depth recommendations in this area. Here are two of the five models included therein:
Available Now
The new events are available in the US East (Northern Virginia), US East (Ohio), US West (Northern California), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), EU (Frankfurt), EU (Ireland), and South America (São Paulo) Regions and you can start using them today! Take a look and let me know what you come up with.
— Jeff;
PS – If you are a developer, development manager, or a product manager and would like to build systems like this, check out the EBS Jobs page.
Genome Engineering Applications: Early Adopters of the Cloud
Our friends at the Commonwealth Scientific and Industrial Research Organization (CSIRO) in Australia sent along the guest post below to tell us about how AWS powers an important new genome editing technique.
— Jeff
Recent developments in molecular engineering technology now enables the accurate editing of genomes. The new technology, called CRISPR-Cas9, can be programmed to recognize and edit specific locations in the genome by pattern-matching unique sequences of DNA. While this is a powerful new tool for researchers, the ability to scan and identify targets across the entire genome has created unprecedented demand for large-scale computation. Earlier this year, the US National Institutes of Health (NIH) has approved the use of these technologies for human health. This has the potential to revolutionize cancer treatments and also adds a new time-critical dimension to the compute requirements.
A New Approach to Cancer Treatments
Approximately two in five people will be diagnosed with cancer at some point during their lifetime and while overall cancer survival has doubled, there are still cancer types with very low survival rate, for example just 1% for pancreatic cancer. This is mainly due to the difficulty of finding therapeutic interventions that kill cancer cells but not harm the healthy tissue in the body.
The new NIH approved trial will leverage breakthroughs in the genome editing technology, CRISPR-Cas9, to develop a different treatment approach. In this, the patient’s own immune system is boosted through specific modifications of the cells that natively fight cancer. This has the potential of being effective for a wide range of different tumors, with the current trial including patients with specific blood and solid cancers, as well as melanoma.
Cloud Services for Computationally Guided Genome Engineering
This new application in human health requires an increase in robustness and efficiency of CRISPR-Cas9 design in order to meet the time constraints of clinical care. Built on AWS cloud-services, researchers in the eHealth program of the Commonwealth Scientific and Industrial Research Organization (CSIRO) in Australia, developed GT-Scan2, a novel software tool to address this issue.
“Compared to other available methods, GT-Scan2 identifies genomic location with higher sensitivity and specificity,” says Dr. Denis Bauer who is leading the transformational bioinformatics team.

GT-Scan2 shows the identified CRISPR target sites at the genomic position and annotates them with high or low activity as well as their off-target potential.
GT-Scan2 improves the effectiveness of the system by finding sites that are unique in the genome. This avoids diluting the effect due to “off-target”, which are other sites in the genome with high sequence similarity. It also optimizes robustness by finding sites that are easier to modify.
“While it was known that the three-dimensional genome organization plays a role in CRISPR binding, GT-Scan2 is the first tool to also leverage other components that are crucial for Cas9 activity,” says Dr. Laurence Wilson whose research focuses on computational genome engineering.
Specifically the off-target search is a compute intensive task traditionally reserved for researchers at large institutes with high-performance-compute infrastructure as every location in the 3 billion letter long genomic sequence needs to be investigated. GT-Scan2 democratizes the ability to find optimal sites by offering this complex computation as a cloud-service using AWS Lambda functions.
Scaling Instantaneously for Personalized Treatments
GT-Scan2 leverages the instantaneous scalability that the event-driven AWS Lambda service offers. This is crucial for personalized treatment, as complexity of the targeted gene can vary dramatically.
“The off-target search as well as the robustness analysis can be subdivided into independent, modular tasks that can run in parallel” says Aidan O’Brien who designed and implemented the system within weeks after its official Asia-Pacific launch in April this year at the AWS Summit 2016 attesting to the intuitive nature of the service. A typical job takes less than a minute and the variation between jobs range from 1 second to 5 minutes. This fast fluctuation in load over minutes rather than hours ruled out an EC2-based solution as new instances would come online too slowly to keep the runtime stable.
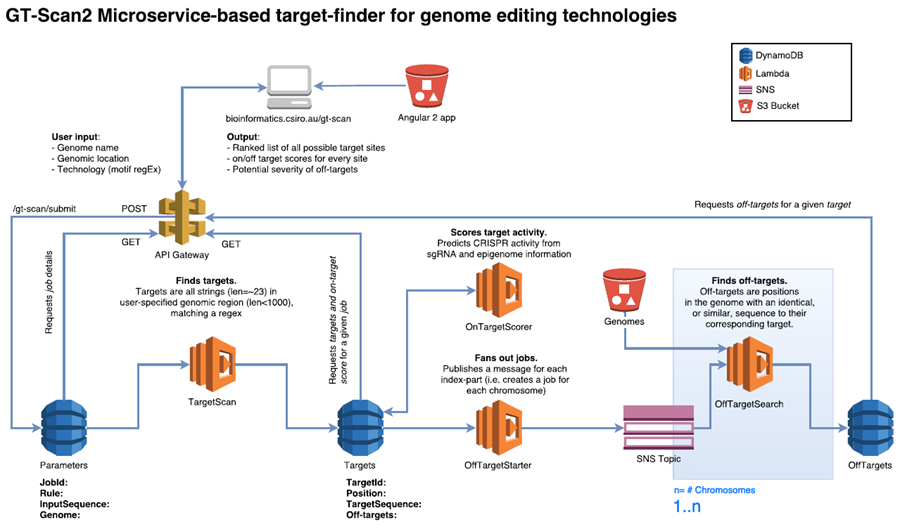
GT-Scan2 is served directly from S3 making it a static web app without server-side processing. It retrieves the dynamic content (such as job results and parameters) via API calls using API Gateway from a database (DynamoDB) using a JavaScript framework.
When a user submits a job, GT-Scan2 inserts the job parameters as an item into a DynamoDB table via an API call. This allows the solution to be freely scalable without creating a bottleneck. The database entry triggers the first Lambda function, which finds all putative CRISPR targets in the user-specified DNA sequence (fetched automatically upon user submission). Potential CRISPR target sites have fixed rules and can be easily found using a regular expression that completes in seconds and are inserted into a second DynamoDB table.
Adapting to leverage the power of Lambda-based microservices
All potential targets need to be evaluated for their off-target risk using the efficient string matching tool, Bowtie. Though Bowtie only requires a reduced representation of the 3 billion letter genomic sequence, the sizes of these index files exceed the storage limitation for each Lambda instance. “GT-Scan2 divides the genome into smaller blocks to fit the Lambda specifications” explains Adrian White (Research & Technical Computing, APAC) who supported the CSIRO team during development. For an average run, GT-Scan2 hence triggers 500-1000 individual Lambda functions, which simultaneously update the scores for the different putative targets in DynamoDB. During this process, the frontend is polling this table via API Gateway and updating the webpage as results come in, eliminating the need for server-side compute.
“AWS’s Lambda has given us a great framework to develop a future-ready software package able to support medical genome engineering applications,” says Dr. Bauer. “We are specifically impressed with the ability to instantaneously scale at run time by spawning more Lambda functions to cope with the varying complexity of the different genes.” Other benefits Dr. Bauer quotes include only paying for storage during periods of no use and jobs not competing with web server resources as the website is a static page with dynamic content updated through Angular 2 and the API Gateway, as well as not needing to maintain compute instances (security patches of OS).
“One of the best things about Lambda is that users will be able to easily swap-in different machine learning algorithms that are better suited for specific CRISPR applications” says Dr. Wilson.

The GT-Scan2 Team, from left, Denis Bauer, Laurence Wilson, Aidan O’Brien
“The computational genome engineering community is one of the early adopters of our AWS Lambda technology,” explains Dr. Mia Champion (Technical Business Development Manager, Scientific Computing). “GT-Scan2’s use of API Gateway and DynamoDB is a very neat solution to ensure scalability and their clever use of epigenomics really sets them apart from other recent applications using lambda to perform CRISPR searches. I am looking forward to seeing GT-Scan2 adopted in medical applications.”
Congratulations to the Winners of the Serverless Chatbot Competition!
 I announced the AWS Serverless Chatbot Competion in August and invited you to build a chatbot for Slack using AWS Lambda and Amazon API Gateway.
I announced the AWS Serverless Chatbot Competion in August and invited you to build a chatbot for Slack using AWS Lambda and Amazon API Gateway.
Last week I sat down with fellow judges Tim Wagner (General Manager of AWS Lambda) and Cecilia Deng (a Software Development Engineer on Tim’s team) to watch the videos and to evaluate all 62 submissions. We were impressed by the functionality and diversity of the entrees, as well as the efforts that the entrants put in to producing attractive videos to show their submissions in action.
After hours of intense deliberation we chose a total of 9 winners: 8 from individuals, teams & small organizations and one from a larger organization. Without further ado, here you go:
Individuals, Teams, and Small Organizations
Here are the winners of the Serverless Slackbot Hero Award. Each winner receives one ticket to AWS re:Invent, access to discounted hotel room rates, public announcement and promotion during the Serverless Computing keynote, some cool swag, and $100 in AWS Credits. You can find the code for many of these bots on GitHub. In alphabetical order, the winners are:
AWS Network Helper – “The goal of this project is to provide an AWS network troubleshooting script that runs on a serverless architecture, and can be interacted with via Slack as a chat bot.” GitHub repo.
B0pb0t – “Making Mealtime Awesome.” GitHub repo.
Borges – “Borges is a real-time translator for multilingual Slack teams.” GitHub repo.
CLIve – “CLIve makes managing your AWS EC2 instances a doddle. He understands natural language, so no need to learn a new CLI!”
Litlbot – “Litlbot is a Slack bot that enables realtime interaction with students in class, creating a more engaged classroom and learning experience.” GitHub repo.
Marbot – “Forward alerts from Amazon Web Services to your DevOps team.”
Opsidian – “Collaborate on your AWS infra from Slack using natural language.”
ServiceBot – “Communication platform between humans, machines, and enterprises.” GitHub repo.
Larger Organization
And here’s the winner of the Serverless Slackbot Large Organization Award:
Eva – “The virtual travel assistant for your team.” GitHub repo.
Thanks & Congratulations
I would like to personally thank each of the entrants for taking the time to submit their entries to the competition!
Congratulations to all of the winners; I hope to see you all at AWS re:Invent.
— Jeff;
PS – If this list has given you an idea for a chatbot of your very own, please watch our Building Serverless Chatbots video and take advantage of our Serverless Chatbot Sample.
Amazon Aurora Update – Call Lambda Functions From Stored Procedures; Load Data From S3
Many AWS services work just fine by themselves, but even better together! This important aspect of our model allows you to select a single service, learn about it, get some experience with it, and then extend your span to other related services over time. On the other hand, opportunities to make the services work together are ever-present, and we have a number of them on our customer-driven roadmap.
Today I would like to tell you about two new features for Amazon Aurora, our MySQL-compatible relational database:
Lambda Function Invocation – The stored procedures that you create within your Amazon Aurora databases can now invoke AWS Lambda functions.
Load Data From S3 – You can now import data stored in an Amazon Simple Storage Service (S3) bucket into a table in an Amazon Aurora database.
Because both of these features involve Amazon Aurora and another AWS service, you must grant Amazon Aurora permission to access the service by creating an IAM Policy and an IAM Role, and then attaching the Role to your Amazon Aurora database cluster. To learn how to do this, see Authorizing Amazon Aurora to Access Other AWS Services On Your Behalf.
Lambda Function Integration
Relational databases use a combination of triggers and stored procedures to enable the implementation of higher-level functionality. The triggers are activated before or after some operations of interest are performed on a particular database table. For example, because Amazon Aurora is compatible with MySQL, it supports triggers on the INSERT, UPDATE, and DELETE operations. Stored procedures are scripts that can be run in response to the activation of a trigger.
You can now write stored procedures that invoke Lambda functions. This new extensibility mechanism allows you to wire your Aurora-based database to other AWS services. You can send email using Amazon Simple Email Service (SES), issue a notification using Amazon Simple Notification Service (SNS), insert publish metrics to Amazon CloudWatch, update a Amazon DynamoDB table, and more.
At the appliction level, you can implement complex ETL jobs and workflows, track and audit actions on database tables, and perform advanced performance monitoring and analysis.
Your stored procedure must call the mysql_lambda_async procedure. This procedure, as the name implies, invokes your desired Lambda function asynchronously, and does not wait for it to complete before proceeding. As usual, you will need to give your Lambda function permission to access any desired AWS services or resources.
To learn more, read Invoking a Lambda Function from an Amazon Aurora DB Cluster.
Load Data From S3
As another form of integration, data stored in an S3 bucket can now be imported directly in to Aurora (up until now you would have had to copy the data to an EC2 instance and import it from there).
The data can be located in any AWS region that is accessible from your Amazon Aurora cluster and can be in text or XML form.
To import data in text form, use the new LOAD DATA FROM S3 command. This command accepts many of the same options as MySQL’s LOAD DATA INFILE, but does not support compressed data. You can specify the line and field delimiters and the character set, and you can ignore any desired number of lines or rows at the start of the data.
To import data in XML form, use the new LOAD XML from S3 command. Your XML can look like this:
<row column1="value1" column2="value2" />
...
<row column1="value1" column2="value2" />
Or like this:
<row>
<column1>value1</column1>
<column2>value2</column2>
</row>
...Or like this:
<row>
<field name="column1">value1</field>
<field name="column2">value2</field>
</row>
...To learn more, read Loading Data Into a DB Cluster From Text Files in an Amazon S3 Bucket.
Available Now
These new features are available now and you can start using them today!
There is no charge for either feature; you’ll pay the usual charges for the use of Amazon Aurora, Lambda, and S3.
— Jeff;
Running Express Applications on AWS Lambda and Amazon API Gateway
Express is a web framework for Node.js . It simplifies the development of “serverless” web sites, web applications, and APIs. In a serverless environment, most or all of the backend logic is run on-demand in a stateless fashion (see Mike Roberts’ article on Serverless Architectures for a more detailed introduction). AWS Lambda, when used in conjunction with the new Amazon API Gateway features that I blogged about earlier this month (API Gateway Update – New Features Simplify API Development), allows existing Express applications to be run in serverless fashion. When you use API Gateway you have the opportunity to take advantage of additional features such as Usage Plans which allow you to build a developer ecosystem around your APIs, and caching which allows you to build applications that are responsive and cost-effective.
In order to help you to migrate your Express applications to Lambda and API Gateway, we have created the aws-serverless-express package. This package contains a working example that you can use as a starting point for your own work.
I have two resources that you can use to migrate your Express code and applications to API Gateway and Lambda:
- Running Express Apps in AWS Lambda shows you how to use Claudia.js and the aws-serverless-express module to deploy your application. You simply remove the existing TCP listener, create a Lambda proxy wrapper, and deploy!
- Going Serverless: Migrating an Express Application to Amazon API Gateway and AWS Lambda goes in to a bit more depth than the previous post. For example, it shows you how to set up environment variables, manage database connections, and provides some guidance on efficient hosting of static assets. The post also details the entire release process and introduces some other Lambda and API Gateway features that might be of interest to you.
— Jeff;
Yemeksepeti: Our Shift to Serverless Architecture
 AWS Community Hero Onur Salk wrote the guest post below in order to tell you how he helped his employer to move to a serverless architecture.
AWS Community Hero Onur Salk wrote the guest post below in order to tell you how he helped his employer to move to a serverless architecture.
— Jeff;
I’m Onur Salk, AWS Community Hero, AWS Certified Solutions Architect – Professional, and organizer of the AWS user group in Turkey. As a Hero, I like to share my AWS experience and knowledge with the community on my personal blog and through meetups with the community. Today I want to share the story behind Yemeksepeti and our shift to serverless architecture.
The Story Behind Yemeksepeti
 Yemeksepeti is the biggest online food ordering company in Turkey. It lets users place food orders from affiliated network restaurants without charging any extra fees. At Yemeksepeti, we needed to set up a globally distributed service that is scalable, high-performing, and cost-effective. Our belief is that by designing a serverless architecture, we won’t have to worry about managing our servers and can remove a lot of operational burdens from our team. This means we can focus on running our code at scale.
Yemeksepeti is the biggest online food ordering company in Turkey. It lets users place food orders from affiliated network restaurants without charging any extra fees. At Yemeksepeti, we needed to set up a globally distributed service that is scalable, high-performing, and cost-effective. Our belief is that by designing a serverless architecture, we won’t have to worry about managing our servers and can remove a lot of operational burdens from our team. This means we can focus on running our code at scale.
At Yemeksepeti.com, we developed a real-time discount system called Joker about four years ago. The purpose of this system is to suggest discounts to customers that they normally cannot find for restaurants. The original Joker platform was developed in .NET and then integrated with the website and mobile devices using its REST API. We were asked to open the platform’s API to our sister companies operating in 34 countries, so that they can also provide real-time Joker discounts to their customers.
Initially, we thought we would share our code and let them integrate their applications. However, most of other countries were using different technology stack (programming languages, database, and so on). Although using our code might accelerate their development at first, they would have to maintain an unfamiliar system. We needed to find an integration method that was easier to implement and cheaper to maintain.
Our Requirements
This was a global project, and these were our five focus areas:
- Ease of management
- High availability
- Scalability
- Use in several regions
- Cost advantage
We evaluated these focus areas against several different processing models and came up with the following matrix:
| Ease of Management | High Availability | Scalability | Use in Several Regions | Cost Advantage | |
| IaaS
We could spin up some EC2 instances running IIS on top of Microsoft Windows Server and connected to an RDS DB instance. |
No. We need to take care of our servers. | Yes. We can distribute our servers to different AZs. | Yes. We can use Auto Scaling | Yes. We can use AMIs and copy between regions | Partially. There will be license fees and costs for running EC2 instances . |
| PaaS
We could use AWS Elastic Beanstalk. |
Partially. We need to take care of our servers. | Yes. We can distribute our servers to different AZs. | Yes. We can use Auto Scaling. | Yes. We can use environment configurations, AMIs, etc. | Partially. There will be license fees and costs for running EC2 instances. |
| FaaS
We could use AWS Lambda. |
Yes. AWS takes care of the services. | Yes. It is already highly available | Yes. It performs at any scale | Yes. We can export/import/upload our configurations easily. | Yes. There are no licenses and we pay only for what we use. |
We decided to use Faas (Functions as a Service). We started our project in the EU (Ireland) regions using the following services:
- Amazon Virtual Private Cloud
- Amazon API Gateway
- AWS Lambda
- Amazon Relational Database Service (RDS)
- Amazon Simple Storage Service (S3)
- Amazon CloudWatch
- Amazon Elasticsearch Service
Architecture
Our architecture looks like this:
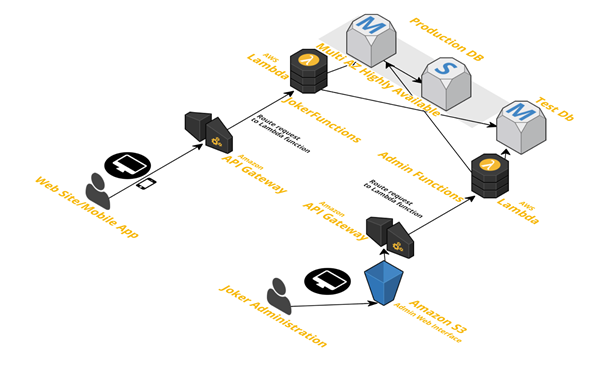
Amazon VPC: We use Amazon VPC to launch our resources in our private network.
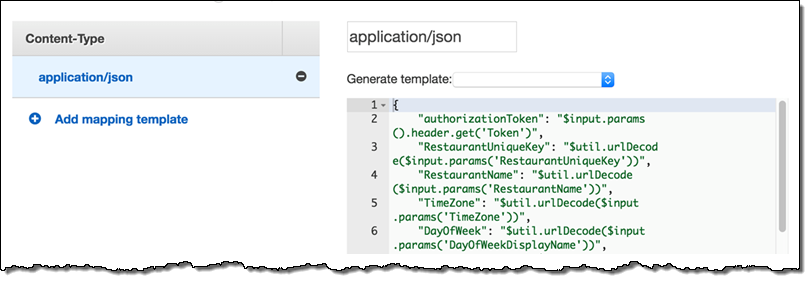
Amazon API Gateway: During the development phase, we started to develop the service in the EU (Ireland) region. At that time, AWS Lambda was not available in EU (Frankfurt). We created two APIs: one for web integration and the other for the admin interface. We used custom authorizers with JSON Web Tokens (JWT) to enable token-based authorization for our APIs. We used mapping templates to pass our variables to our Lambda functions.
In the development phase, there was only a test stage for each API.
During the production phase, AWS Lambda became available in Frankfurt. We decided to move the service there to benefit from low latency access from Turkey. We used the API Gateway Export API feature to export our configuration in Swagger format, and then imported it into Frankfurt. (Before the import, we changed the region definitions in the exported file to eu-central-1.) After that, we created a production stage and used stage variables to parameterize our database definitions of the Amazon RDS instances (like host, username, and so on). We also wanted to use our custom domain name. After we bought an SSL certificate for our domain, we created a custom domain name in the Amazon API Gateway console and created an alias for our CloudFront distribution name (Amazon API Gateway uses Amazon CloudFront in the background). Finally, we created an IAM role to enable Amazon CloudWatch logging for API calls, latency, and more.
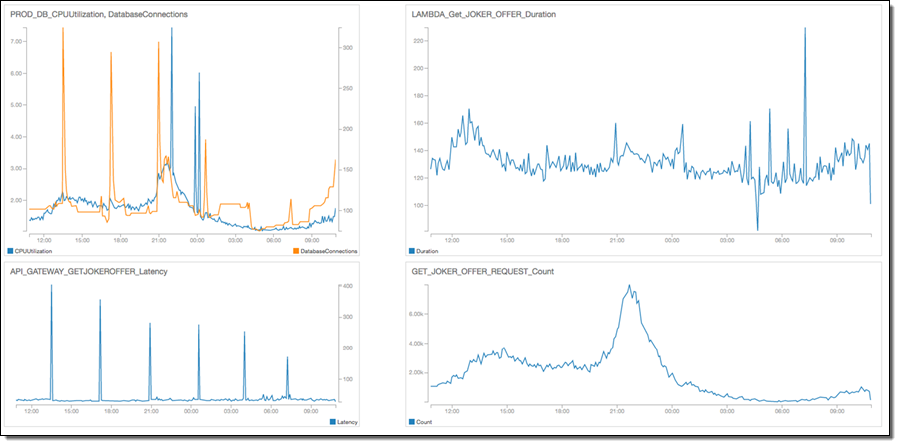
Metrics for Get_Joker_offer resource:

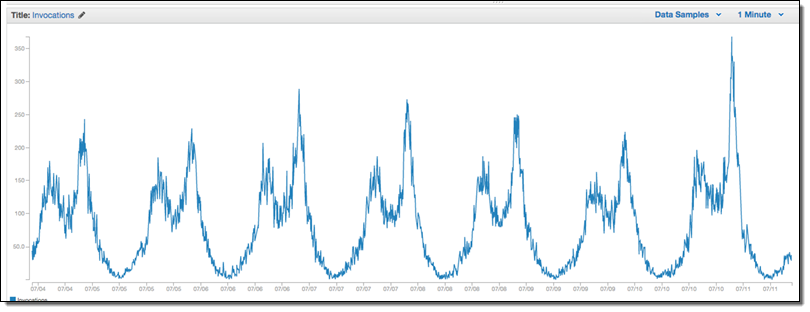
AWS Lambda: During the development phase, we used Python to develop our service and created 65 functions for integrating our API methods and scheduled tasks using CloudWatch Events Lambda triggers. Lambda VPC integration became available during the production phase, so we uploaded our functions to the Frankfurt region and integrated them with VPC.
Invocation count of Get_joker_offer Lambda function (The peaks correspond to lunch and dinner times (when people are hungry)):
Amazon RDS: During the development phase, we chose to use Amazon RDS for PostgreSQL. We created a single-AZ RDS instance to test our service. During the production phase, we needed to move our database because we migrated our APIs and functions to Frankfurt. We created a snapshot of our instance and using the Copy snapshot feature of RDS, we successfully moved our database. We launched two instances in our VPC: a multi-AZ instance for production and a single-AZ instance for test purposes. In our API stage variables, we defined the endpoint names of our RDS instances to map the staging to the appropriate instance. We also enabled automated backups for both instances.
Amazon S3: The Joker platform has an admin panel that’s used for managing and reporting Joker offers. To host this administration interface, which is basically a Single Page Application (SPA) with AngularJS, we used the static website hosting feature of Amazon S3. All of the logic and functionality is provided by methods running on Lambda, so we didn’t need a server for the admin interface:
Amazon CloudWatch: We use the service to monitor the usage of our important assets and to get alerts if something goes wrong. We created a custom dashboard to monitor the CPU of our production database, connection count, critical API latencies and function counts and durations.
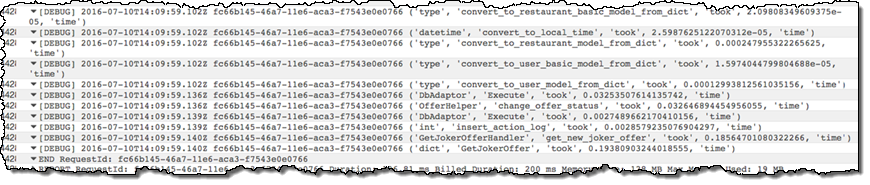
In our Python code, we log the durations of each inner method in CloudWatch to track performance and find any bottlenecks:
Here’s our CloudWatch dashboard:
Amazon ElasticSearch: During the development phase, Cloudwatch Logs streaming to Amazon ES became available in the Ireland region. Using this feature, we created a Kibana dashboard to monitor some other metrics from the logs we generate from our code. As soon as Amazon ES is available in the Frankfurt region, we will use it again.
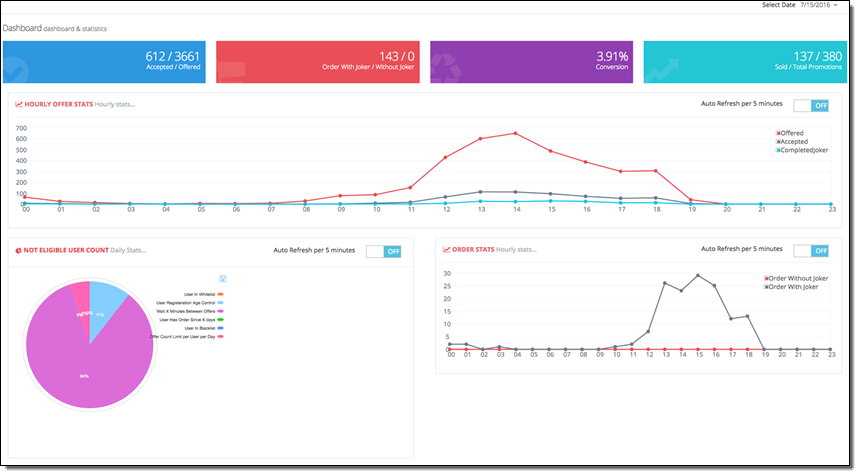
Initial Results
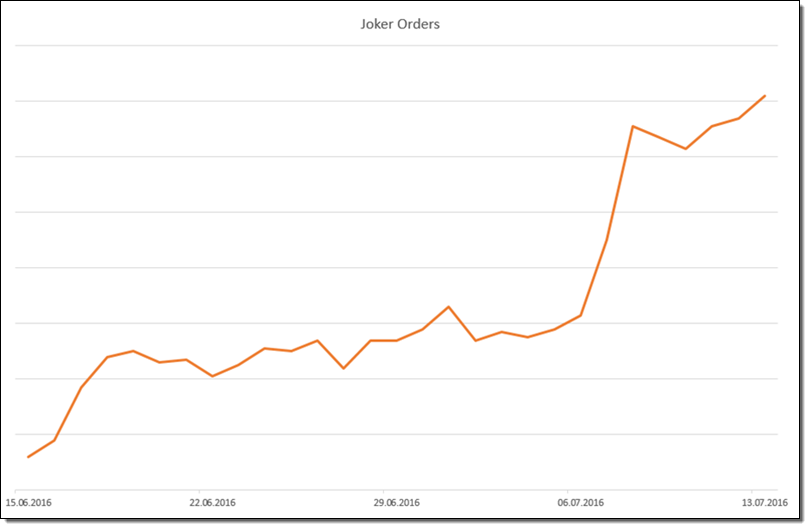
The Joker system is in production now, as a pilot for a small region of a country. As you can see from the following chart, the growth of the number of orders is promising. By leveraging serverless architecture, we didn’t have to install and manage an operating system and dependencies. Using Amazon API Gateway, AWS Lambda, Amazon S3, and Amazon RDS, our architecture runs in a highly available environment. We don’t need to learn and manage any master-slave replication features or third-party tools. As our service gets more requests, AWS Lambda adds more Lambda instance, so it runs at any scale. We are able to copy our service to another region using the features of AWS services as we did before going into production. Finally, we don’t run any servers, so we benefit from the cost advantage of serverless architecture.
Here is a representation of the number of orders placed through Joker:
What’s Next
We hope this service will spread to all 34 of the sister companies within Delivery Hero Holding. As the service is rolled out globally, we will deploy to other AWS regions. We plan to choose the region nearest to the company. To optimize our costs, we will purchase reserved instances for our RDS instances. Also, as we monitor our inner methods’ duration, we can re-factor and optimize our code and so that we can decrease our Lambda functions’ execution times.
We believe the future of the cloud is FaaS. We would like to experiment more as other features, services, and functions become available.
As an AWS Community Hero, I look forward to sharing the Yemeksepeti story with the AWS user group in Turkey. I’d like to help people explore and leverage serverless architecture.
— Onur Salk
Enter the AWS Serverless Chatbot Competition!
Earlier this month I was asked to be a judge for the AWS Serverless Chatbot Competition and I was happy to accept!
Build a Chatbot
 We want you to build a chatbot for Slack using AWS Lambda and Amazon API Gateway. You can also use other APIs (the Slack Events API will be helpful), additional services (AWS or otherwise), and other data sources. Your entry should be creative and original, and should provide genuine value to Slack users.
We want you to build a chatbot for Slack using AWS Lambda and Amazon API Gateway. You can also use other APIs (the Slack Events API will be helpful), additional services (AWS or otherwise), and other data sources. Your entry should be creative and original, and should provide genuine value to Slack users.
The AWS Free Tier provides you with access to Lambda, API Gateway, and other AWS services at no charge. New and existing AWS users get 1 million Lambda requests and 400,000 GB-seconds of compute time for free. New AWS users get 1 million API calls per month to the API Gateway for up to 12 months after signing up.
Your Entry
After you build your chatbot, I would encourage you to spend some time on the packaging and the marketing. Be sure to supply the following items as part of your entry:
- Demonstration video of your chatbot in action.
- Brief explanation of what it does and what makes it unique.
- Link to your public or private GitHub repo (include all files needed to run your chatbot).
- Instructions for testing and using your chatbot.
Your chatbot can be a new or existing application, but it must use Lambda and API Gateway. The code must function as shown in the video, and the submission must be in English. It also has to be substantially different from any other app submitted by the same submitter, team, or organization.
Prizes
Individuals, teams, and organizations with 50 or less employees are eligible for the Serverless Chatbot Hero Award. This award includes one ticket to AWS re:Invent and access to discounted hotel room rates, along with recognition at the Serverless State of the Union address, some cool swag, $100 in AWS credits, and publicity opportunities for their bot. We will make up to eight of these awards.
Larger organizations are eligible for a non-cash, recognition-only award.
See the FAQ for more information on rules and eligibility.
Timeline
Here’s the timeline for the competition:
- August 10 – September 29, 2016 – Submission period.
- October 3-7 – AWS Judging.
- October 15 – Winners announced.
Get Started Now
Here’s what you need to do to get started:
- Read the Rules and Eligibility Guidelines.
- Register for the AWS Serverless Chatbot Competition.
- Create AWS and Slack developer accounts.
- Visit the Resources Page to learn more about the APIs and services.
- Build your chatbot. Our sample code (aws-serverless-chatbot-sample) is a good place to start.
- Create your demo video and your other materials for the submission.
- Submit your materials before 5 PM ET on September 29, 2016.
I’m looking forward to seeing, using, and judging the entries!
Relevant Webinars
Here are some upcoming webinars that will help you to get started:
- August 24 – Getting Started with Serverless Architectures.
- August 30 – Building Serverless Chatbots.
You may also find these recordings of past webinars to be helpful:
- AWS Lambda – Event-driven Code for Devices and the Cloud.
- Build and Manage Your APIs with Amazon API Gateway.
— Jeff;