Category: AWS Lambda
コンテナやサーバレスアプリのデプロイツールとしてのAWS CloudFormation
SA岩永です。AWS上にシステムを構築する際に、アプリケーションのデプロイをどのように行うか?については多様なやり方が考えられますが、今日はAWS CloudFormationを使ったデプロイをご紹介したいと思います。CloudFormationはインフラ構築のツールとして考えられている方も多いと思いますが、最近は特にAmazon ECSやAWS LambdaといったComputeサービスへのアプリケーションデプロイツールとしての活用が進んでいます。AWSのリソースはAWS Command Line Interface (CLI)やSDK等での操作が可能なので自作のツール等を使われるのはもちろん1つの選択肢ですが、もしCloudFormationを検討されたことのない方は、ぜひこの投稿を参考にして頂けるとありがたいです。
デプロイツールとしてのCloudFormationのメリット
最初に結論をまとめておきます。CloudFormationを使ったデプロイには以下の様なメリットがあります。
- デプロイツール自体のインストールが不要、YAML/JSONを書くだけ、ブラウザからでもデプロイ可能
- 宣言的にデプロイが定義・実行できる
- アプリケーションに関連する他のAWSリソースも合わせて管理可能
現在お使いのデプロイツールで、逆に上記の様な観点で困ったことのある方は、この投稿をじっくり読んで頂くと良いと思います。
デプロイツール自体のインストールが不要、YAML/JSONを書くだけ、ブラウザからでもデプロイ可能
例えばCLIで行う様なデプロイツールの場合、そのツール自体のインストール等が必要になりますが、CloudFormationであればブラウザからテンプレートを指定するだけでデプロイできます。CloudFormationの一番のメリットはここです。アプリケーションの構成を記述したYAML or JSONのテンプレートファイルを用意するだけで、すぐにデプロイが可能です。
CloudFormationも実態はAWSのAPIを実行しながらリソースを作成・更新しますが、CloudFormationの場合にはAPIの実行そのものをCloudFormationのサービス側でやってくれます。例えばECSのデプロイで新しいTask Definitionを作成した後でそれを指定してServiceを更新するという依存関係のある2回のAPI操作を順番に実行する必要がありますが、CloudFormationに1回命令を送るだけで後のAPI操作はCloudFormationのサービスが代わりにやってくれます。なので、デプロイが終わるまで実行プロセスが待っている必要もないですし、複数人の排他的実行も実現できますし、さらに現在の状態と過去の履歴というデータの保存までもやってくれます。
もちろん、CloudFormation自体もAWSのサービスなので、CLI/SDKでの操作は可能です。もしもデプロイをCLIで実行して終わるまで待ちたい、ということであれば、aws cloudformation deployというコマンドを使うと更新が終わるまでポーリングしながら待ってくれます。この場合に必要なものはAWS CLIのインストールのみなので、そこまでハードルの高いものではありません。
宣言的にデプロイが定義・実行できる
AWSのAPIを利用しながらデプロイツールを自作する場合には、リソースの作成順序に気を払いながら、かつ途中で失敗した場合のエラーハンドリング等も考慮しつつ手続き的に実装する必要があります。これはシンプルな構成であればそこまで難しくはないのですが、対応したい機能が徐々に増えてくるとだんだんと実装が複雑化してきてしまいます。
CloudFormationで使うテンプレートは、手続きを記述するのではなく、希望する状態を宣言的に定義するものです。そのため、複雑な構成であっても簡潔さを保って記述することができますし、多くのケースで各リソース間の依存関係も自動で判断されるので、実行順序を考えて記述する必要もありません。もちろん、テンプレートにはパラメータを設定することも可能なので、例えばECSであれば新しく作成したコンテナイメージ名をパラメータにしておくと、デプロイはそのパラメータを更新するだけで済みます。
アプリケーションに関連する他のAWSリソースも合わせて管理可能
ECSやLambdaは、それ単体だけで利用するケースよりも、他のAWSのサービスも合わせて利用されることが多いと思います。例えば、AWS Identity and Access Management (IAM)のRoleは良く使われますし、データベースとしてAmazon DynamoDBを使ったり、ECSのコンテナへの負荷分散にElastic Load Balancingを使うことは非常に多く、場合によってはアプリケーションのデプロイ時にそれらのリソースの更新も行いたいケースもあります。
CloudFormationでは他のリソースも合わせて定義して操作させられるので、そういったケースに非常に強力なツールとなります。アプリケーションと同じテンプレートで作成することもできますし、昨年リリースされたCross Stack Referenceという機能を使うと、先に作成しておいたリソースをアプリケーション側から参照するといった使い方もできます。
CloudFormationを使ったECSのデプロイ例
こちらは、ECSへの継続的デプロイメントについて紹介した以下のブログをご参照頂くのが良いです。
ブログで紹介されている構成では、GitHubへのコードのpushをトリガーにして、イメージのビルドからECSのServiceの更新まで一貫したものを紹介していますが、Service更新部分はCloudFormationテンプレートを使って実施しています。また、AWS CodePipelineがデプロイ方式としてCloudFormationに対応しているので、簡単に設定することが可能です。
参考のために、Task DefinitionとServiceとIAM Roleを定義するYAMLテンプレート例を貼り付けておきます。
https://github.com/awslabs/ecs-refarch-continuous-deployment/blob/master/templates/service.yaml
Resources:
ECSServiceRole:
Type: AWS::IAM::Role
Properties:
Path: /
AssumeRolePolicyDocument: |
{
"Statement": [{
"Effect": "Allow",
"Principal": { "Service": [ "ecs.amazonaws.com" ]},
"Action": [ "sts:AssumeRole" ]
}]
}
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceRole
Service:
Type: AWS::ECS::Service
Properties:
Cluster: !Ref Cluster
Role: !Ref ECSServiceRole
DesiredCount: !Ref DesiredCount
TaskDefinition: !Ref TaskDefinition
LoadBalancers:
- ContainerName: simple-app
ContainerPort: 80
TargetGroupArn: !Ref TargetGroup
TaskDefinition:
Type: AWS::ECS::TaskDefinition
Properties:
Family: !Sub ${AWS::StackName}-simple-app
ContainerDefinitions:
- Name: simple-app
Image: !Sub ${AWS::AccountId}.dkr.ecr.${AWS::Region}.amazonaws.com/${Repository}:${Tag}
EntryPoint:
- /usr/sbin/apache2
- -D
- FOREGROUND
Essential: true
Memory: 128
MountPoints:
- SourceVolume: my-vol
ContainerPath: /var/www/my-vol
PortMappings:
- ContainerPort: 80
Environment:
- Name: Tag
Value: !Ref Tag
- Name: busybox
Image: busybox
EntryPoint:
- sh
- -c
Essential: false
Memory: 128
VolumesFrom:
- SourceContainer: simple-app
Command:
- /bin/sh -c "while true; do /bin/date > /var/www/my-vol/date; sleep 1; done"
Volumes:
- Name: my-volCloudFormationを使ったLambdaのデプロイ例
Lambdaの構成管理およびデプロイには、AWS Serverless Application Model (SAM)を使うことができます。これはCloudFormationの拡張表記であり、例えば以下のようなテンプレートを書くと簡単にAmazon API GatewayとLambda Functionをデプロイ(初回は構築含む)をすることができます。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: Outputs the time
Resources:
TimeFunction:
Type: AWS::Serverless::Function
Properties:
Handler: index.handler
Runtime: nodejs6.10
CodeUri: ./
Events:
MyTimeApi:
Type: Api
Properties:
Path: /TimeResource
Method: GETLambdaのデプロイを行う際、多くのケースでは依存ライブラリ等もまとめたzipファイルを作成し、Amazon Simple Storage Service (S3)にアップロードした上でFunctionを更新することになります。AWS SAMを使っているとこれをAWS CLIを使って簡単に実現できます。実装例は以下のドキュメントに詳しく紹介されています。
まとめ
この投稿では、AWS CloudFormationをコンテナやサーバレスアプリケーションをデプロイするためのツールとしてご紹介しました。多くの実際のユースケースで利用可能なものですのでご参考にして頂ければ幸いです。サーバレスアプリのデリバリパイプラインまで含めた実装を実際にご覧になりたい場合には、AWS CodeStarで作成されるプロジェクトも参考になるかと思いますので合わせてご参考頂ければと思います。
AWS X-Ray で AWS Lambda をサポート
本日、AWS X-Ray で AWS Lambda サポート の一般提供開始を発表しました。Jeff が GA で投稿したブログですでにご存知の方もいるかと思いますが (「Jeff の GA POST (Jeff’s GA POST)」)、X-Ray は分散アプリケーションの実行やパフォーマンス動作を分析する AWS サービスです。
複数の独立したコンポーネントを異なるサービスで実行するマイクロサービスベースのアプリケーションでは、従来の問題をデバッグする方法がうまく機能しません。アプリケーションでレイテンシーを分けることで、X-Ray はエラーや処理の低下、タイムアウトを迅速に診断することができます。それでは、シンプルな Lambda ベースのアプリケーションを構築し分析する方法をお見せしながら、独自のアプリケーションで X-Ray を使用する方法をご説明します。
今すぐ開始したい場合は、関数の設定ページで追跡を有効にすれば既存の Lambda 関数で簡単に X-Ray を使い始めることができます。

または AWS Command Line Interface (CLI) で関数の tracing-config を更新してください (必ず --function-name も忘れずに):
$ aws lambda update-function-configuration --tracing-config '{"Mode": "Active"}'
トレースモードをオンにすると、Lambda は関数を追跡しようとします (アップストリームサービスによって追跡されないよう明示的に指示されていない限り)。オフの状態では、アップストリームサービスによって追跡するよう明示的に指示されている場合のみ関数が追跡されます。トレーシングモードをオンにすると追跡の生成が始まり、アプリケーションとその間のコネクション (辺) におけるリソースのビジュアル表現が見られるようになります。
X-Ray デーモンは Lambda 関数のいくつかのリソースを使用することがあります。メモリ制限に近付いている場合、Lambda はメモリ不足エラーを回避するために X-Ray デーモンを終了しようとします。では、複数のサービスを使用する簡単なアプリケーションを構築して新しい統合を試してみましょう。
20 代が持つスマートフォンということで、
pictures
自分のスマホは自撮りの写真でいっぱいです (10000+!)。ということで、この機会に写真をすべて分析してみることにしました。Java 8 ランタイムを使用して、Amazon Simple Storage Service (S3) バケットにアップロードした新しい画像に反応するシンプルな Lambda 関数を作成します。写真には Amazon Rekognition を使用し、検出したラベルを Amazon DynamoDB に保存します。

まず、X-Ray のボキャブラリーをいくつか確認しておきましょう: サブセグメント、セグメント、トレースです。 分かりましたか? サービスグラフを生成するために X-Ray が処理するトレースをサブセグメントとセグメントが構成している、ということを覚えておけば X-Ray を理解しやすいと思います。
サービスグラフは見やすいビジュアル表現を提供します (様々なリクエストへの応答を別の色で表示)。アプリケーションロジックを実行しているコンピューティングリソースは、実行している作業に関するデータをセグメント形式で送信します。サブセグメントを作成すれば、データに関する注釈を追加したり、コードのタイミングをより細かく設定することができます。アプリケーションを経由するリクエストのパスは、トレースを使用して追跡されます。トレースでは、1 つのリクエストで生成されたセグメントをすべて収集します。つまり、S3 からの Lambda イベントを DynamoDB まで簡単に追跡することができるので、エラーやレイテンシーがどこで発生しているか把握することができます。
では、S3 バケットを作成してみましょう。このバケットの名称は selfies-bucketにします。DynamoDB テーブルは selfies-table、あとは Lambda 関数です。ObjectCreated で S3 バケットの Lambda 関数にトリガーを追加します。Lambda 関数コードは実にシンプルです。こちらでご覧ください。コードの変更なしに、JAR の aws-xray-sdk と aws-xray-sdk-recorder-aws-sdk-instrumentor パッケージを含むことで Java 関数で X-Ray を有効にすることができます。アップロードした写真をいくつかトリガーして X-Ray のトレースを見てみましょう。

データが取れました!トレースの 1 つをクリックすれば呼び出しの詳細情報を見ることができます。

最初の AWS::Lambda セグメントでは、関数のドウェル時間、実行待機時間、試行された実行数を見ることができます。次の AWS::Lambda::Function セグメントにはいくつかのサブセグメントが見られます。
- 初期設定のサブセグメントには関数ハンドラが実行する前の時間すべてが含まれます。
- アウトバウンドサービスコール
- 任意のカスタムセグメント (簡単に追加可能)
どうやら DyamoDB 側で問題が発生しているようです。エラーアイコンをクリックすれば、より詳しい情報と例外のスタックトレースを見ることができます。書き込みキャパシティーユニットが不足しているので、DynamoDB に調整されたことが分かります。数回のクリックまたは簡単な API コールで追加できます。そうするとサービスマップに表示される緑が増えていきます。

X-Ray SDK は X-Ray へのデータ放出をとても簡単にしますが、トークに X-Ray デーモンを使用する必要はありません。Python を使用している場合は fleece という rackspace からライブラリを確認できます。X-Ray サービスは興味深いものをたくさん備えています。詳細については「未定義 ()」ドキュメントをご覧ください。
個人的に @awscloudninja ボットで使用していますが、これはとても優れていると思います。ただし、これは公式のライブラリではなく AWS がサポートしていない点にご留意ください。時間節約、デバッグや操作に対する労力においても便利なので、個人的には今後のプロジェクトすべてで X-Ray を使う予定です。皆さんがどのように構築するのか楽しみにしています。使えそうなトリックやハックを見つけたら、ぜひお知らせください!
– Randall
AWS チャットボットチャレンジを開催 – Amazon Lex と AWS Lambda を使用した対話式でインテリジェントなチャットボットを作成
AWS 2017 サンフランシスコサミットのリリース内容やお知らせを細かくチェックしていたユーザーなら Amazon Lex サービスの一般提供が開始し、今すぐご利用いただけるようになったことをすでにご存知かもしれません。Amazon Lex は、開発者が音声やテキストを使用するアプリケーションで対話式のインターフェイス構築を可能にするフルマネージド型の AI サービスです。Lex は Amazon Alexa を使用する Amazon Echo のようなデバイスと同じディープラーニングを使用しています。Amazon Lex のリリースにより、開発者は独自のアプリケーションで違和感のないユーザーエクスペリエンスやリアルな会話のやり取りを構築できます。Amazon Lex は Slack、Facebook Messenger、Twilio SMS に対応しています。こうした人気のチャットサービスを使用し、ユーザーの音声やテキストのチャットボットを簡単に発行することができます。Amazon Lex サービスを試し、独自のアプリケーションに優れた機能を追加するには、今が絶好のチャンスです。
さて、いよいよお知らせです。
この度 AWS チャットボットチャレンジを開催することになりました! AWS チャットボットチャレンジは、問題を解決したり今後のユーザーに向けた付加価値を追加する、他に例のないユニークなチャットボットを構築するチャンスです。AWS チャットボットチャレンジはアマゾン ウェブ サービスと Slack の協力により実現しました。

チャレンジ
このチャレンジに参加する開発者は、Amazon Lex を使用して自然な対話式のチャットボットを構築し、バックエンドでロジックプロセスやデータプロセスを実行するために AWS Lambda と Lex の統合を利用することになります。対象となるボットは新しいものでも既存のものでも構いませんが、既存のボットの場合はこのチャレンジのエントリー期間中に Amazon Lex と AWS Lambda を使用できるように更新する必要があります。
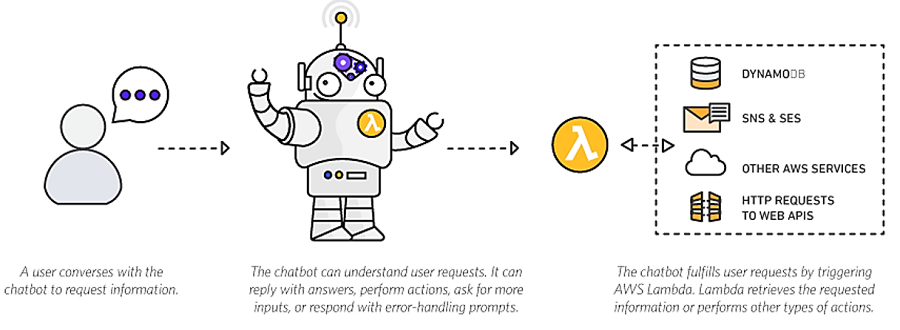
ソリューション構築時の制限は、あなたの想像力のみです。それでは、以下にボット作成やデプロイにおける創作力をサポートするアドバイスをいくつかご紹介します。チャットボットをよりユニークにするためのアドバイスについては次をご覧ください。
- Slack、Facebook Messenger または Twilio SMS にボットをデプロイする
- 独自のボットソリューション構築時に別の AWS サービスを活用する
- Amazon Polly のようなサービスを使用してテキスト読み上げ機能を導入
- ほかのサードパーティー API、SDK、サービスを活用
- Amazon Lex の構築済みエンタープライズコネクターを利用して Salesforce、HubSpot、Marketo、Microsoft Dynamics、Zendesk、QuickBooks といったサービスをデータソースとして追加
AWS Lambda を使用してボットをコスト効率良く構築する方法があります。Lambda には毎月、無料利用枠のリクエスト数 100 万件とコンピューティング時間 400,000 GB/秒 が含まれています。無料提供している毎月の使用量はすべてのお客様を対象とし、無料利用枠の期間である 12 か月が終了した後も無効にはなりません。さらに、Amazon Lex を新たにご利用のお客様は、初年度において 10,000 件までのテキストリクエストと 5,000 件までの音声リクエストを毎月無料でプロセスすることができます。詳細はこちらをご覧ください。AWS の無料利用枠では、AWS にサインアップしたその日から 12 か月に渡り無料利用枠のサービスをご利用いただけるほか、12 か月の無料期間が過ぎた後も自動的にそれが無効になることはありません。AWS の無料利用枠と関連サービスの詳細については AWS 無料利用枠の詳細ページをご覧ください。

参加方法
AWS チャットボットチャレンジには、参加者の居住国で成年に達した年齢であれば、個人またはチームでこのコンペティションに参加できます。参加申込の時点で企業や団体が正式に設立または法人化されていて、参加対象となるエリアで正当な企業として見なされている場合であれば、社員数が 50 人以下の企業も参加対象になります。また、参加対象地域で 50 人以上の社員から成る大規模な企業も参加することはできますが、その場合は現金が含まれない賞のみへの参加となります。チャットボットに寄せられたボットは次のカテゴリで審査されます。
- 顧客価値: ボットが問題を解決しユーザーに付加価値を提供
- ボットのクオリティ: ボットがユーザーの問題を独自の方法で解決、オリジナルでクリエイティブそして他のボットソリューションと差をつけていること
- ボットの実装: 開発者がいかに努力し優れたボットを構築し実行できるようにしたか検討一般的なフレーズで問いかけられたボットが、意図したように機能し質問を認識して応答できるかなど、ボットの機能について検討
賞について
優れたボットを作成した開発者に AWS チャットボットチャレンジ賞を授与します。1 等賞
- 5,000 USD
- AWS クレジット 2,500 USD 相当
- AWS re:Invent のチケット 2 枚
- Amazon Lex チームとのオンラインミーティング 30 分

- 受賞者は AWS AI ブログで紹介されます
- クールな賞品
2 等賞
- 3,000 USD
- AWS クレジット 1,500 USD 相当
- AWS re:Invent のチケット 1 枚
- Amazon Lex チームとのオンラインミーティング 30 分
- 受賞者は AWS AI ブログで紹介されます
- クールな賞品
3 等賞
- 2,000 USD
- AWS クレジット 1,000 USD 相当
- Amazon Lex チームとのオンラインミーティング 30 分
- 受賞者は AWS AI ブログで紹介されます
- クールな賞品
チャレンジのタイムライン
- エントリー開始日: 2017 年 4 月 19 日 午後 12:00 時 (PDT)
- エントリー終了日: 2017 年 7 月 18 日 午後 5:00 時 (PDT)
- 結果発表: 2017 年 8 月 11 日 午前 9:00 時 (PDT)
参加手続き
チャットボットチャレンジへの参加をご希望ですか?参加するには、次のチャレンジ上のルールと参加資格をご確認ください。
- AWS チャットボットチャレンジに登録
- AWS チャットボットの Slack チャネルに登録
- AWS でアカウントを作成
- ドキュメントやリソースへのリンクを掲載しているリソースページにアクセス
- 作動中のボットを映したデモ動画を撮影ボットの概要と用途についてドキュメントを作成
- ボットのコードをホストする GitHub リポジトリへのリンク、すべてのデプロイファイル、ボットをテストする上で必要な手順など、審査とテスト実施に要するボットへのアクセス方法を提供
- AWSChatbot2017.Devpost.com で 2017 年 7 月 18 日 午後 5:00 時 (ET) までにボットを提出します。ボットのアクセス権限の共有、Github リポジトリ、デプロイファイルも併せて提出してください。
概要
Amazon Lex では、ウェブアプリケーションやモバイルアプリケーションで対話を構築することができます。また、IoT デバイスの管理、カスタマーサポートの提供、トランザクションの更新情報を連絡したり、DevOps ワークロードの実施 (ChatOps) を可能にするチャットボットを構築することも可能です。Amazon Lex には AWS Lambda、AWS Mobile Hub、Amazon CloudWatch との統合が組み込まれています。そのため他の AWS サービスと簡単に統合することができ、AWS プラットフォームを使用してセキュリティ、モニタリング、ユーザー認証、ビジネスロジック、ストレージなどをチャットボットやアプリケーションで構築することができます。Slack、Facebook Messenger、Twilio SMS といったチャットサービスをサポートする Amazon Lex を活用して、音声やテキストのチャットボット機能を強化できます。Amazon Lex と AWS Lambda を使用してチャットボットや対話式インターフェイスを構築し AWS チャットボットチャレンジでクールな賞品を獲得してください。Amazon Lex と Amazon Lambda を使用して作成したボットに関する最近のリソースやオンラインテクトークもボット構築の参考になると思います。
- Amazon Lex の発表 – 2017 年 1 月 AWS オンラインテクトーク
- Amazon Lex のご紹介: 音声やテキストのチャットボット構築サービス – 2017 年 3 月 AWS オンラインテクトーク
- Amazon Lex のドキュメント: Amazon Lex と AWS Lambda の設計図 (Amazon Lex and AWS Lambda Blueprints)
- AWS AI ブログ: Amazon Lex でより優れたボットを構築 パート 1 (Building Better Bots Using Amazon Lex (Part 1))
- AWS AI ブログ: Amazon Lex でより優れたボットを構築 パート 2 (Building Better Bots Using Amazon Lex (Part 2))
- Slack ブログ: Amazon Alexa と同じディープラーニングテクノロジーをアプリで使用: Amazon Lex が Slack をサポート (Your app can now use the same deep-learning technology inside Amazon’s Alexa: Announcing Amazon Lex support for Slack)
- 欧州でのイベントは?Slack Dev Roadshow で Slack プラットフォームチームがホストするチャットボット構築方法のワークショップに参加
AWS チャットボットチャレンジに関するご質問は aws-chatbot-challenge-2017@amazon.com 宛てにメールで英語で問い合わせるか、ディスカッションボードに質問を投稿してください。 では、頑張ってコード作成に励む皆さんの幸運を祈ります!
– Tara
Amazon AppStream 2.0でデスクトップアプリケーションのストリームをスケールする

Deepak Sury, Principal Product Manager – Amazon AppStream 2.0
デスクトップアプリケーションを書き換えることなくWebブラウザにストリーミングしたいですか?Amazon AppStream 2.0はフルマネージドの、セキュアなアプリケーションストリーミングサービスです。このサービスでなにができるかを知るためのかんたんな方法はエンドユーザーエクスペリエンスを無料で試してみることです。
この記事では、AppStream 2.0環境をスケールさせて、コストを最適化する方法について解説します。さらにセットアップとモニタリングについていくつか付け加えます。
AppStream 2.0 ワークフロー
Image Builderを使用して自分のアプリケーションをAppStream 2.0にインポートします。Image BuilderでAWS Management Consoleからデスクトップエクスペリエンスに接続して、自分のアプリをインストールしてテストすることができます。そして、Image Builderのスナップショットとしてイメージを作成します。
アプリケーションをふくむイメージを作成したあと、インスタンスタイプを選択してストリーミングインスタンスのフリートを起動します。フリートのそれぞれのインスタンスは1ユーザーだけで使用され、フリートで使用されるインスタンスタイプがアプリケーションパフォーマンスによる必要と適合するようにします。最後に、フリートをスタックにアタッチしてユーザーアクセスをセットアップします。以下の図はワークフローのなかでのそれぞれのリソースの役割を示しています。
図1: AppStream 2.0のワークフローを記述

AppStream 2.0のセットアップ
使いはじめるためには、コンソールのクイックリンクからサンプルのAppStream 2.0スタックをセットアップします。このサンプルでは、スタックにds-sampleという名前を付け、サンプルイメージを選択して、stream.standard.mediumインスタンスタイプを選んでいます。セットアップしたリソースはAWSコンソールまたは、以下のようにdescribe-stacksやdescribe-fleetsを使用して確認することができます:
図2: AppStream 2.0スタックの確認

図3: AppStream 2.0フリートの確認

ストリーミング環境へのユーザーアクセスをセットアップするには、既存のSAML 2.0準拠のディレクトリを使用することができます。ユーザーは既存の認証情報を使用してログインすることができます。別のやり方として、クイックにストリーミング接続をテスト、または自分のWebサイトからストリーミングセッションをスタートするには、ストリーミングURLを作成することができます。コンソールで、Stacks、Actions、Create URLを選択するか、以下のようにcreate-streaming-urlを呼び出します:
図4: ストリーミングURLの作成

ブラウザにストリーミングURLをペーストして、表示されたアプリケーションを開くことができます。

これでサンプル環境のセットアップができましたので、スケーリングに移りましょう。
AppStream 2.0のスケーリングとコスト最適化
インスタントオンのストリーミング接続を提供するために、AppStream 2.0フリートのインスタンスは常時稼働しています。稼働中のインスタンスに課金され、それぞれの稼働中のインスタンスは同時に1ユーザーのみを受け付けます。コストを最適化するには、インスタンスの稼働台数を同時にアプリをストリーミングしたいユーザー数にあわせます。このセクションではそのための3つのオプションを紹介していきます:
- フリートのオートスケーリング
- スケジュールをベースにした固定フリート
- スケジュールによるフリートのオートスケーリング
フリートのオートスケーリング
インスタンスの稼働台数を動的に更新するには、フリートのオートスケーリングを使用することができます。この機能はフリートのサイズを自動的に最小値と最大値の間でオンデマンドにスケールさせることができます。これはコンスタントにユーザーの需要が変動し、需要に応じてフリートを自動的にスケールさせたい場合に便利です。スケーリングポリシーのセットアップと管理の方法については、Fleet Auto Scalingを参照してください。
フリートへの変更はAmazon CloudWatchメトリクスを利用してトリガすることができます:
- CapacityUtilization – すでに使用されている稼働中のインスタンスのパーセンテージ
- AvailableCapacity – 未使用でユーザーからの接続を受け付けることができるインスタンスの台数
- InsufficientCapacityError – ユーザーのリクエストに応答できる稼働中のインスタンスが存在しないときにトリガされるエラー
AWS SDKまたはAWSマネージメントコンソールを使用してスケーリングポリシーの作成とアタッチができます。コンソールを使用してポリシーをセットアップするのが便利です。以下のステップになります:
- AWSマネージメントコンソールで、AppStream 2.0を開きます。
- Fleetを選んで、フリートを選択し、Scaling Policiesを選びます。
- Minimum capacityとMaximum capacityで、フリートの値を入力します。
図5: スケーリングポリシーを設定するフリートタブ

- それぞれのセクションでAdd Policyを選んでスケールアウトとスケールインポリシーを作成します。
図6: スケールアウトポリシーの追加

図7: スケールインポリシーの追加

ポリシーを作成した後、フリートの詳細の一部として表示されます。

スケーリングポリシーはCloudWatchアラームによってトリガーされます。このアラームはコンソールを使用してスケーリングポリシーを作成したときに自動的に作成されます。CloudWatchコンソールからアラームの確認と変更ができます。
図8: フリートをスケーリングするためのCloudWatchアラーム

スケジュールをベースにした固定フリート
コストを最適化して予測可能な需要に対応するための別のやり方は時刻または曜日にもとづいて稼働するインスタンスの台数を固定することです。これはトレーニングクラス、コールセンターのシフト、学校のコンピュータラボなどのシナリオで異なる時刻に固定されたユーザー数がサインインする場合に便利です。AppStream 2.0のupdate-fleetコマンドを使用して稼働中のインスタンス数をかんたんに設定することができます。フリートのコンピュートキャパシティを希望する値にアップデートしてください。稼働中のインスタンス数は、以下のように設定した希望する値に応じて変動します:
図9: フリートの希望するキャパシティをアップデート

自動的にフリートサイズをアップデートするLambdaファンクションをセットアップします。以下の例にしたがって自分のファンクションをセットアップします。以前にLambdaを使用したことがない場合は、Step 2: Create a HelloWorld Lambda Function and Explore the Consoleを参照してください。
フリートサイズを変更するファンクションを作成するには
- Lambdaコンソールで、 Create a Lambda functionを選択します。
- Blank Functionブループリントを選択します。これは自分のコードを追加することができる空のブループリントを作成します。
- 今回はトリガーセクションをスキップします。あとで、時間を、または別のインプットをベースにしたトリガーを追加できます。
- Configure functionセクションでは:
- 名前と説明を入力します。
- Runtimeでは、Node.js 4.3を選択します。
- Lambda function handler and roleで、Create a custom roleを選択します。
- IAMウィザードで、例えばLambda-AppStream-Adminのようにロール名を入力します。デフォルトのままにします。
- IAMロールが作成されたあと、”AmazonAppStreamFullAccess”というAppStream 2.0のマネージドポリシーをロールにアタッチします。より詳細な情報は、Working with Managed Policiesを参照してください。これによりLambdaがあなたのかわりにAppStream 2.0 APIをコールすることができます。くわしくは、Controlling Access to Amazon AppStream 2.0を参照してください。
- のこりのフィールドではデフォルト値のままNext, Create functionを選択します。
- AppStream 2.0のフリートサイズを変更するには、Codeを選択して以下のようにサンプルコードを追加します:
JavaScript
'use strict'; /** This AppStream2 Update-Fleet blueprint sets up a schedule for a streaming fleet **/ const AWS = require('aws-sdk'); const appstream = new AWS.AppStream(); const fleetParams = { Name: 'ds-sample-fleet', /* required */ ComputeCapacity: { DesiredInstances: 1 /* required */ } }; exports.handler = (event, context, callback) => { console.log('Received event:', JSON.stringify(event, null, 2)); var resource = event.resources[0]; var increase = resource.includes('weekday-9am-increase-capacity') try { if (increase) { fleetParams.ComputeCapacity.DesiredInstances = 3 } else { fleetParams.ComputeCapacity.DesiredInstances = 1 } appstream.updateFleet(fleetParams, (error, data) => { if (error) { console.log(error, error.stack); return callback(error); } console.log(data); return callback(null, data); }); } catch (error) { console.log('Caught Error: ', error); callback(error); } }; - コードをテストします。Testを選択して”Hello World”テストテンプレートを使用します。はじめてこれを実行するには、Save and Testを選択します。以下のようにスケーリングのアップデートをトリガーするテストインプットを作成します。

- update-fleetコールの結果がアウトプットのテキストとして表示されます。CLIを使用してLambdaファンクションの実行結果を確認することもできます。
つぎに、タイムベーススケジュールをセットアップするために、Lambdaファンクションを呼び出すトリガーをセットします。
Lambdaファンクションのトリガーをセットするには
- Triggers, Add triggerを選択します。
- CloudWatch Events – Scheduleを選択します。
- Schedule expressionでは、cronを選択します。cronの値はあとで編集することができます。
- トリガーが作成された後、weekday-9am-increase-capacityのイベントを開きます。
- CloudWatchコンソールで、イベントの詳細を編集します。平日の午前8時にフリートをスケールアウトするには、時間を00 17 ? * MON-FRI *になるように調整します。(シアトル(太平洋時間)ではない場合は、それぞれのタイムゾーンに変更してください)
- 平日の終わりにトリガーする別のイベントを追加することもできます。

これでセットしたスケジュール時刻に合わせて自動的にスケールアウトとスケールインするトリガーをセットアップしました。
スケジュールでのフリートのオートスケーリング
もっと複雑なシナリオをマネージするためにフリートスケーリングと時間ベースのスケジュールのアプローチを組み合わせて使用することができます。これは業務時間と業務時間外とで稼働するインスタンス数をマネージしながら需要の変更に対応するのに便利です。時刻または日付に基づいてフリートの最小および最大サイズをプログラムから変更し、デフォルトのスケールアウトおよびスケールインポリシーを適用することができます。これによってスケジュールをベースにした予測可能な最小の需要に応答することができます。
たとえば、平日のはじめに、同時に一定数のユーザーがストリーミング接続をリクエストすることが予測されます。フリートがスケールアウトして要求を満たすまで待っていたくはありません。しかしながら、一日のうちに、需要がスケールインまたはアウトすることが予測され、フリートのサイズを需要に合わせたいと思います。
これを実現するには、コンソールからスケーリングポリシーをセットアップして、スケジュールをベースにフリートの最小、最大および希望するキャパシティの変更をトリガーするLambdaファンクションを作成します。以前作成したLambdaファンクションのコードを以下のようなコードで置き換えます:
'use strict';
/** This AppStream2 Update-Fleet function sets up a schedule for a streaming fleet **/
const AWS = require('aws-sdk');
const appstream = new AWS.AppStream();
const applicationAutoScaling = new AWS.ApplicationAutoScaling();
const fleetParams = {
Name: 'ds-sample-fleet', /* required */
ComputeCapacity: {
DesiredInstances: 1 /* required */
}
};
var scalingParams = {
ResourceId: 'fleet/ds-sample-fleet', /* required - fleet name*/
ScalableDimension: 'appstream:fleet:DesiredCapacity', /* required */
ServiceNamespace: 'appstream', /* required */
MaxCapacity: 1,
MinCapacity: 6,
RoleARN: 'arn:aws:iam::659382443255:role/service-role/ApplicationAutoScalingForAmazonAppStreamAccess'
};
exports.handler = (event, context, callback) => {
console.log('Received this event now:', JSON.stringify(event, null, 2));
var resource = event.resources[0];
var increase = resource.includes('weekday-9am-increase-capacity')
try {
if (increase) {
//usage during business hours - start at capacity of 10 and scale
//if required. This implies at least 10 users can connect instantly.
//More users can connect as the scaling policy triggers addition of
//more instances. Maximum cap is 20 instances - fleet will not scale
//beyond 20. This is the cap for number of users.
fleetParams.ComputeCapacity.DesiredInstances = 10
scalingParams.MinCapacity = 10
scalingParams.MaxCapacity = 20
} else {
//usage during non-business hours - start at capacity of 1 and scale
//if required. This implies only 1 user can connect instantly.
//More users can connect as the scaling policy triggers addition of
//more instances.
fleetParams.ComputeCapacity.DesiredInstances = 1
scalingParams.MinCapacity = 1
scalingParams.MaxCapacity = 10
}
//Update minimum and maximum capacity used by the scaling policies
applicationAutoScaling.registerScalableTarget(scalingParams, (error, data) => {
if (error) console.log(error, error.stack);
else console.log(data);
});
//Update the desired capacity for the fleet. This sets
//the number of running instances to desired number of instances
appstream.updateFleet(fleetParams, (error, data) => {
if (error) {
console.log(error, error.stack);
return callback(error);
}
console.log(data);
return callback(null, data);
});
} catch (error) {
console.log('Caught Error: ', error);
callback(error);
}
};
注:このコードを実行するには、Lambdaファンクションで使用されるロールにIAMポリシーを追加する必要があります。このポリシーによってLambdaがあなたのかわりにアプリケーションオートスケーリングサービスを呼び出すことができます。
図10: Lambdaでアプリケーションオートスケーリングを使用するインラインポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"iam:PassRole"
],
"Resource": "*"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"application-autoscaling:*"
],
"Resource": "*"
}
]
}利用状況のモニタリング
フリートのスケーリングをセットアップした後、AppStream 2.0でCloudWatchメトリクスを使用して、モニタリングのためのダッシュボードを作成することができます。これは確認した利用量をもとに時間ベースのスケーリングポリシーを最適化するのに役立ちます。
例えば、初期セットアップが非常に保守的でリソースをオーバープロビジョンしていたら、フリートの利用率が低い状態が長く続くでしょう。一方で、フリートサイズが小さすぎる場合、高利用率またはユーザーの接続をブロックしているキャパシティ不足のエラーがみられるでしょう。最大15ヶ月までCloudWatchメトリクスを確認してフリートスケーリングポリシーを調整することができます。
図11: カスタムAmazon CloudWatchメトリクスのダッシュボード

まとめ
これらはAppStream 2.0をスケーリングしてコストを最適化するためのいくつかのアイデアです。これが役に立ち、同様の記事を観たいと思ったらお知らせください。サービスに関してコメントがあれば、AWS forum for AppStream 2.0にフィードバックを投稿してください。
翻訳は渡邉が担当しました。原文はこちら。
AWS のサイトですか?AWS Lambda を使用したドメインの識別
以下のゲスト投稿で、私の同僚である Tim Bray は IsItOnAWS.com を構築した方法について説明しています。このサイトは、AWS の IP アドレスレンジのリストと Tim が記述した Lambda 関数を使用して、お気に入りのウェブサイトが AWS で実行されているかどうかを調べることを目的としています。
— Jeff;
AWS のサイトですか?
クリスマスの時期に遊び半分でプログラミングをしていたら、おもしろい Lambda 関数ができました。きっと気に入ってもらえると思います。指定したドメイン名 (または IP アドレス) (IPv6 でも可能) が、公表されている AWS IP アドレスレンジ に含まれているかどうかを調べてくれます。IsItOnAWS.com で実際に試してみることができます。構築の過程では、1 つの Lambda 関数で別の Lambda 関数を作成しています。JSON 形式の IPv4 および IPv6 CIDR で提供されているレンジのリストはここです。説明書はここで、Jeff Barr のブログ もあります。以下は、JSON 形式の IP レンジの例です。
これを見た瞬間、「IsItOnAWS.com ができるのではないか」と思いました。可能だと分かったので、これを構築しました。以下のようなサイトにしたいと思いました。
- サーバーレス (クールな人たちはみんなそうしているので)
- シンプル (数字の範囲の中で数値を調べるというシンプルな課題なので)
- 高速。当然ですよね。
データベースか否か 
構築はとても明快に思えました。IP レンジを表にまとめ、アドレスを調べるということです。テーブルはどこに配置すればいいでしょうか。Amazon DynamoDB にしようかと思いましたが、実質的に数値のレンジから検索するのは明快ではありませんでした。明快な所で SQL データベースも考えましたが、上記の 2 番目に当てはまりません。Redis やそれに似た方法を考えましたが、インスタンスのプロビジョンが必要で、上記の 1 番目に当てはまりません。数日間この問題を考え続けて行き詰ってしまいました。その時、1 つの疑問が浮かびました。レンジのリストはどれほど大きいのだろう。エントリの数は 1000 未満であることが分かりました。そうであれば、そもそもデータベースは必要ないのではないでしょうか。JSON を配列して、バイナリサーチすることにします。そうすると、配列はどこにすればいいでしょうか。Amazon S3 なら簡単でしょう。でも、上記の 3 番目を見てください。S3 は高速ですが、すべてのリクエストのループにそれが必要でしょうか。それで、配列リテラルとしてレンジを含む小さなファイルを生成し、それを IsItOnAWS Lambda 関数自体の中に含めることにしました。この方法だと、IP アドレスが変更されるたびに関数を再構築してアップロードする必要があります。アドレスを気にするのであれば、Amazon Simple Notification Service (SNS) トピックへの受信登録をし、変更されるたびに通知が届くようにできます (最近の私の経験によると、週に 1、2 回の頻度です)。そして、サブスクリプションを Lambda 関数に結び付けておきます。これで、だれもが必要とする道具をそろえることができたと感じました。
Lambda 関数は 2 つあります。1 つめは、 newranges.js で、変更通知を取得し、IP レンジのデータから JavaScript を生成し、2 つめの Lambda 関数である isitonaws.js へアップロードします。これには JavaScript が含まれています。注意深い読者の方は、これはすべて Node ランタイムに関係するとお分かりでしょう。典型的な async または waterfall である新しいレンジ関数は、当初思っていたよりはやや複雑です。
Postmodern IP アドレス
最初のタスクは IP レンジの取得で、直接的な HTTP GET です。その後、JSON をより検索しやすい形にします。当然ですが、IPv4 と IPv6 の両方のレンジがあります。作業を容易にするため、単純な文字列や数字のマッチングで検索できる 1 つの配列にまとめようと思いました。IPv6 アドレスは JavaScript の数値で扱うには大きすぎるので、文字列にする必要があります。IPv4 のスペースが IPv6 の ("::ffff:0:0/96") に組み込まれている方法はやや驚きでした。BMP マッピングが低ビットの Unicode に組み込まれているようなものだと思っていました。このような方法になっているのはなぜかと漠然と考えはしましたが、調査はしていません。すべての CIDR をクラッシュして整然とした検索可能な配列にするコードは煩雑になりましたが、目的は達成できます。
Lambda の中に Lambda を構築する
次に、実際に IsItOnAWS リクエストを扱う Lambda を構築します。zip ファイルである必要があり、NPM に作成に必要なツールがあります。後は、圧縮されたバイトを S3 に詰め込んでアップロードすれば、新しい Lambda 関数を作成できます。鋭い方はお気づきでしょうが、いったん zip を作成すれば、直接 Lambda にアップロードできます。フローを精錬するために後で生成された「レンジ」データ構造をダウンロードして確認したかったので、S3 を中間のステップとして使用しました。実際の IsItOnAWS ランタイムは、名前でアドレスを探すために DNS を「たたく」ことと、レンジ配列に使用したのと同じ形式にするために多少工夫すること以外は、かなりシンプルです。HTML テンプレートの作成などはせず、zip の中のファイルを読み込み、表示されない <div> があれば、それを結果に置き換えただけです。ただ、バイナリサーチの手法をコードにする必要はありました。10 年に 1 度あるかないかの作業でしたが、楽しくできました。
ピースをまとめる
すべてのコードを実行できるようになったら、Amazon API Gateway を使用して世界につなげてみたくなりました。以前これを実行したときは複雑な作業でしたが、今回は「プロキシリソースを通じて Lambda プロキシと統合された API を作成する」を参照していたので、比較的単純で予想外の事態はほとんど生じないと思えました。ただ、その説明は主に API の構築 (例:JSON in/out など) についてで、実際の使用例にはあまり触れられていません。実際に HTML を人に送信してブラウザに読み込ませる方法などは書かれていませんでしたが、その方法を考えるのは難しくありませんでした。以下はその方法です (Node より)。
一度すべてを API Gateway に接続できたら、最後のステップは isitonaws.com をそこに向かわせることです。そのため、このコードを記述したのは 12 月から 1 月にかけてでしたが、ブログにまとめるのは今になっています。当時は、Amazon Certificate Manager (ACM) 証明書は API Gateway で使用できませんでした。そして、時は 2017 年になり、証明書を承認して接続するのに古い学校の式典のようなことをする暇はありません。ACM により、証明書のプロセスはまったく思考を要しないものになっています。ACM と Let’s Encrypt が世に出たおかげで、今や非 HTTPS サイトを作成する理由は何もなくなりました。両方ともすばらしいツールですが、私のように API Gateway や CloudFront など AWS のサービスを使用している方であれば、ACM のほうがなじみやすいでしょう。自動更新もされる点は、きっと気に入るはずです。それで今や、ドメイン名を HTTPS と CloudFront 経由で API Gateway API に接続するのはとても簡単にできます。「API Gateway API のホスト名としてカスタムドメイン名を使用する」を参照してください。初めて試して、私の場合はうまくいきましたが、注意点があります (2017 年 3 月時点の話ですが)。最後のステップで ACM 証明書を API に接続する時、数分間、接続のために待機しなければなりませんが、これは普通のことです。幸い、私はあまり気にしていなかったため、あせって更新やキャンセルその他の操作はしませんでしたが、もしそうしていたら問題が生じていたかもしれません。ところで、API Gateway を使用する副次的な効果として、CloudFront を通してすべて実行されます。そのため、データベースを使わないので、高速な処理を期待できます。実際、ここバンクーバーでの話ですが、処理は高速に行われています。速度を計測する必要がないほど高速です。「IP レンジの変更」 SNS トピックに E メールで受信登録もしているので、変更があれば随時 E メールが送信されます。私はその通知を見てうれしくなります。自分の Lambda が新しい Lambda を記述して、すべてが自動で、手を煩わされずに、スムーズかつ高速に行われていると分かるからです。
— Tim Bray シニアプリンシパルエンジニア
AWS のサイトですか? AWS Lambda を使用したドメインの識別
以下のゲスト投稿で、私の同僚である Tim Bray は IsItOnAWS.com を構築した方法について説明しています。このサイトは、AWS の IP アドレスレンジのリストと Tim が記述した AWS Lambda 関数を使用して、お気に入りのウェブサイトが AWS で実行されているかどうかを調べることを目的としています。
— Jeff;
AWS のサイトですか?
クリスマスの時期に遊び半分でプログラミングをしていたら、おもしろい Lambda 関数ができました。きっと気に入ってもらえると思います。指定したドメイン名 (または IP アドレス) (IPv6 でも可能) が、公表されている AWS IP アドレスレンジ に含まれているかどうかを調べてくれます。IsItOnAWS.com で実際に試してみることができます。構築の過程では、1 つの Lambda 関数で別の Lambda 関数を作成しています。JSON 形式の IPv4 および IPv6 CIDR で提供されているレンジのリストはここです。説明書はここで、Jeff Barr のブログ もあります。以下は、JSON 形式の IP レンジの例です。
これを見た瞬間、「IsItOnAWS.com ができるのではないか」と思いました。可能だと分かったので、これを構築しました。以下のようなサイトにしたいと思いました。
- サーバーレス (クールな人たちはみんなそうしているので)
- シンプル (数字の範囲の中で数値を調べるというシンプルな課題なので)
- 高速。当然ですよね。
データベースか否か
構築はとても明快に思えました。IP レンジを表にまとめ、アドレスを調べるということです。テーブルはどこに配置すればいいでしょうか。Amazon DynamoDB にしようかと思いましたが、実質的に数値のレンジから検索するのは明快ではありませんでした。明快な所で SQL データベースも考えましたが、上記の 2 番目に当てはまりません。Redis やそれに似た方法を考えましたが、インスタンスのプロビジョンが必要で、上記の 1 番目に当てはまりません。数日間この問題を考え続けて行き詰ってしまいました。その時、1 つの疑問が浮かびました。レンジのリストはどれほど大きいのだろう。エントリの数は 1000 未満であることが分かりました。そうであれば、そもそもデータベースは必要ないのではないでしょうか。JSON を配列して、バイナリサーチすることにします。そうすると、配列はどこにすればいいでしょうか。Amazon S3 なら簡単でしょう。でも、上記の 3 番目を見てください。S3 は高速ですが、すべてのリクエストのループにそれが必要でしょうか。それで、配列リテラルとしてレンジを含む小さなファイルを生成し、それを IsItOnAWS Lambda 関数自体の中に含めることにしました。この方法だと、IP アドレスが変更されるたびに関数を再構築してアップロードする必要があります。アドレスを気にするのであれば、Amazon Simple Notification Service (SNS) トピックへの受信登録をし、変更されるたびに通知が届くようにできます (最近の私の経験によると、週に 1、2 回の頻度です)。そして、サブスクリプションを Lambda 関数に結び付けておきます。これで、だれもが必要とする道具をそろえることができたと感じました。Lambda 関数は 2 つあります。1 つめは、 newranges.js で、変更通知を取得し、IP レンジのデータから JavaScript を生成して、2 つめの Lambda 関数である isitonaws.js へアップロードします。これには JavaScript が含まれています。注意深い読者の方は、これはすべて Node ランタイムに関係するとお分かりでしょう。典型的な async または waterfall である新しいレンジ関数は、当初思っていたよりはやや複雑です。
Postmodern IP アドレス
最初のタスクは IP レンジの取得で、直接的な HTTP GET です。その後、JSON をより検索しやすい形にします。当然ですが、IPv4 と IPv6 の両方のレンジがあります。作業を容易にするため、単純な文字列や数字のマッチングで検索できる 1 つの配列にまとめようと思いました。IPv6 アドレスは JavaScript の数値で扱うには大きすぎるので、文字列にする必要があります。IPv4 のスペースが IPv6 の ("::ffff:0:0/96") に組み込まれている方法はやや驚きでした。BMP マッピングが低ビットの Unicode に組み込まれているようなものだと思っていました。このような方法になっているのはなぜかと漠然と考えはしましたが、調査はしていません。すべての CIDR をクラッシュして整然とした検索可能な配列にするコードは煩雑になりましたが、目的は達成できます。
Lambda の中に Lambda を構築する
次に、実際に IsItOnAWS リクエストを扱う Lambda を構築します。zip ファイルである必要があり、NPM に作成に必要なツールがあります。後は、圧縮されたバイトを S3 に詰め込んでアップロードすれば、新しい Lambda 関数を作成できます。鋭い方はお気づきでしょうが、いったん zip を作成すれば、直接 Lambda にアップロードできます。フローを精錬するために後で生成された「レンジ」データ構造をダウンロードして確認したかったので、S3 を中間のステップとして使用しました。実際の IsItOnAWS ランタイムは、名前でアドレスを探すために DNS を「たたく」ことと、レンジ配列に使用したのと同じ形式にするために多少工夫すること以外は、かなりシンプルです。HTML テンプレートの作成などはせず、zip の中のファイルを読み込み、表示されない <div> があれば、それを結果に置き換えただけです。ただ、バイナリサーチの手法をコードにする必要はありました。10 年に 1 度あるかないかの作業でしたが、楽しくできました。ピースをまとめるすべてのコードを実行できるようになったら、Amazon API Gateway を使用して世界につなげてみたくなりました。以前これを実行したときは複雑な作業でしたが、今回は「プロキシリソースを通じて Lambda プロキシと統合された API を作成する」を参照していたので、比較的単純で予想外の事態はほとんど生じないと思えました。ただ、その説明は主に API の構築 (例:JSON in/out など) についてで、実際の使用例にはあまり触れられていません。実際に HTML を人に送信してブラウザに読み込ませる方法などは書かれていませんでしたが、その方法を考えるのは難しくありませんでした。以下はその方法です (Node より)。
一度すべてを API Gateway に接続できたら、最後のステップは isitonaws.com をそこに向かわせることです。そのため、このコードを記述したのは 12 月から 1 月にかけてでしたが、ブログにまとめるのは今になっています。当時は、Amazon Certificate Manager (ACM) 証明書は API Gateway で使用できませんでした。そして、時は 2017 年になり、証明書を承認して接続するのに古い学校の式典のようなことをする暇はありません。ACM により、証明書のプロセスはまったく思考を要しないものになっています。ACM と Let’s Encrypt が世に出たおかげで、今や非 HTTPS サイトを作成する理由は何もなくなりました。両方ともすばらしいツールですが、私のように API Gateway や CloudFront など AWS のサービスを使用している方であれば、ACM のほうがなじみやすいでしょう。自動更新もされる点は、きっと気に入るはずです。それで今や、ドメイン名を HTTPS と CloudFront 経由で API Gateway API に接続するのはとても簡単にできます。「API Gateway API のホスト名としてカスタムドメイン名を使用する」を参照してください。初めて試して、私の場合はうまくいきましたが、注意点があります (2017 年 3 月時点の話ですが)。最後のステップで ACM 証明書を API に接続する時、数分間、接続のために待機しなければなりませんが、これは普通のことです。幸い、私はあまり気にしていなかったため、あせって更新やキャンセルその他の操作はしませんでしたが、もしそうしていたら問題が生じていたかもしれません。ところで、API Gateway を使用する副次的な効果として、CloudFront を通してすべて実行されます。そのため、データベースを使わないので、高速な処理を期待できます。実際、ここバンクーバーでの話ですが、処理は高速に行われています。速度を計測する必要がないほど高速です。「IP レンジの変更」 SNS トピックに E メールで受信登録もしているので、変更があれば随時 E メールが送信されます。私はその通知を見てうれしくなります。自分の Lambda が新しい Lambda を記述して、すべてが自動で、手を煩わされずに、スムーズかつ高速に行われていると分かるからです。
— Tim Bray、シニアプリンシパルエンジニア
Amazon ECS におけるコンテナ インスタンス ドレイニングの自動化方法
同僚のMadhuri Periが素晴らしい記事を書いてくれました。AutoScalingグループのクラスタをスケールダウンする際にインスタンスからタスクを事前に削除するために、コンテナ インスタンス ドレイニングを利用する方法です。
—–
Amazon ECSクラスタでは、クラスタからインスタンスを削除する必要があるタイミングというのがいくつかあります。例えば、システムを更新するとき、Dockerデーモンを更新するとき、あるいはクラスタのサイズをスケールダウンするときなどです。コンテナ インスタンス ドレイニング機能によって、クラスタ上のタスクに影響を与えることなく、コンテナインスタンスを削除することができます。この機能により、コンテナインスタンスがDRAINING状態である間はそのインスタンスに対して新しいタスクの配置がスケジュールされないようになり、利用可能なリソースがあればサービスがタスクをクラスタ上の他のコンテナインスタンスに移動してくれ、インスタンスを削除する前にタスクの移動が成功したことを待機できるようになります。
コンテナインスタンスの状態は、手動でDRAININGに変更することが可能です。しかしこの記事では、これらのプロセスを自動化するためにAutoScalingグループとAWS Lambdaを利用してコンテナ インスタンス ドレイニングを行う方法を説明します。
Amazon ECS オーバービュー
Amazon ECSはコンテナ管理サービスです。クラスタやEC2インスタンスの論理グループ上でDockerコンテナの実行、停止、そして管理を容易にしてくれます。ECSを使ってタスクを実行するとき、タスクはクラスタに配置されます。Amazon ECSは指定されたレジストリからコンテナイメージをダウンロードし、そしてそのイメージをクラスタ内のコンテナインスタンス上で実行します。
コンテナ インスタンス ドレイニングの状態を扱う
AutoScalingグループはライフサイクルフックをサポートしています。ライフサイクルフックは、インスタンスの起動や削除の前に独自の処理を完了するために呼び出されます。今回の例では、ライフサイクルフックは、2つの処理を実行するLambdaファンクションを呼び出します。
- ECSコンテナインスタンスの状態をDRAININGに変更します。
- コンテナインスタンス上にタスクが1つも残っていないことを確認します。もしドレイニング中のタスクがまだ存在する場合は、Lambdaファンクションを再度呼び出すためにSNSにメッセージを送信します。
コンテナインスタンス上で実行中のタスクがなくなるか、あるいはライフサイクルフックのハートビートタイムアウト(サンプルのCloudFormationテンプレートではTTL15分に設定)に達するか、どちらかの状態になるまでLambdaによってステップ2が繰り返されます。その後、制御はオートスケーリングのライフサイクルフックに戻され、そのインスタンスは削除されます。このプロセスを次の図に示します。

試してみましょう!
この記事で説明した一連のリソースをセットアップするためにCloudFormationテンプレートを使用します。このCloudFormationテンプレートを使用するには、あなたのアカウントのS3バケットにLambdaデプロイメントパッケージをアップロードする必要があります。このテンプレートは次のリソースを作成します。
- VPCと関連するネットワーク要素(サブネット、セキュリティグループ、ルートテーブルなど。)
- ECSクラスタ、ECSサービス、そしてサンプルのECSタスク定義
- 削除のライフサイクルフックと2つのEC2インスタンスが設定されたAutoScalingグループ
- Lambdaファンクション
- SNSトピック
- Lambdaを実行するために必要なIAMロール
CloudFormationスタックを作成し、インスタンスの終了イベントをトリガーすることによってどのようにこのスタックが機能するのか見ていきます。
Amazon EC2のコンソールにおいて、AutoScalingグループを選択し、CloudFormationによって作成されたAutoScalingグループの名前(CloudFormationテンプレートのリソースのセクションから)を選択します。
操作、編集を選択し、インスタンスの希望の数を “1” に減らすようにサービスを更新します。これによって、2つのインスタンスのどちらか一方で終了プロセスが開始されます。
AutoScalingグループのインスタンスタブを選択します。1つのインスタンスのライフサイクルの状態が “Terminating:Wait” という値を示すはずです。

この状態になると、ライフサイクルフックが発火してSNSにメッセージが送信されます。そして、SNSメッセージトリガーに反応してLambdaファンクションが実行されます。
Lambdaファンクションによって、ECSコンテナインスタンスの状態がDRAININGに変更されます。その後、ECSサービススケジューラによってこのインスタンス上のタスクは停止され、利用可能なインスタンス上でタスクが起動されます。
ECSのコンソールに移動すれば、コンテナインスタンスの状態がDRAININGになっていることを確認できます。

タスクが全て完了すると、AutoScalingグループのアクティビティ履歴でEC2インスタンスの削除を確認できます。

どのように動作しているか
少しLambdaファンクションの内部的な動作を見てみましょう。ファンクションはまず最初に、受け取ったイベントのLifecycleTransitionの値が autoscaling:EC2_INSTANCE_TERMINATING にマッチするかをチェックします。
マッチする場合は “checkContainerInstanceTaskStatus” という関数が呼び出されます。この関数は、受け取ったEC2インスタンスIDのコンテナインスタンスIDを取得しコンテナインスタンスの状態を ‘DRAINING’ に変更します。
続いてインスタンス上で実行中のタスクがあるかがチェックされます。実行中のタスクが存在する場合、このLabmdaファンクションを再度トリガーするためにSNSトピックにメッセージが発行され、このLambdaファンクションのプロセスは終了となります。
Lambdaファンクションは、コンテナインスタンス上に実行中のタスクがない時には、ライフサイクルフックを終了しこのEC2インスタンスの削除に進みます。
まとめ
コンテナ インスタンス ドレイニングによって、クラスタのスケールダウンや新しいAMIのロールアウトのような運用業務がシンプルになります。例えばこの記事で説明された構成に加えて、CloudFormationやCodePipelineを利用して、新しいインスタンスの起動や終了を一括実行するローリングデプロイメントの環境を構築することもできます。
コンテナ インスタンス ドレイニングについてもっと知りたい場合は、Amazon ECS 開発者ガイドを参照してください。
ご質問やご提案があれば、ぜひ以下にコメントしてください。
(翻訳はSA畑が担当しました。原文はこちら)
AWS Lambda – 2016 年を振り返って
2016 年は AWS Lambda、Amazon API Gateway、そして、サーバーレスコンピューティングテクノロジーにとって、控えめに言ってもすばらしい年となりました。もしかすると、AWS Lambda および Amazon API Gateway でのサーバーレスコンピューティングについて耳にしたことがない方がいらっしゃるかもしれませんので、これらのすばらしいサービスについてご紹介したいと思います。AWS Lambda を使用すると、サーバーをプロビジョニングまたは管理しなくてもコードを実行できます。このイベント駆動型のサーバーレスコンピューティングサービスにより、開発者は、ほぼすべての種類のアプリケーションまたはバックエンドで機能を簡単にクラウドへ移行できます。Amazon API Gateway は非常にスケーラブルで、信頼性が高く、堅牢な API を大規模にすばやく構築するのに役立ち、作成した API の維持およびモニタリングの機能も提供します。2016 年のサーバーレスの勢いの締めくくりとして、AWS チームは re:Invent でサーバーレスソリューションの構築をさらに簡単にする強力なサービス機能を発表しました。その機能には次のものがあります。
- AWS Greengrass: Lambda および AWS IoT を使用して、接続された IoT デバイスのローカルでのコンピューティング、メッセージング、データのキャッシングを実行します。https://aws.amazon.com/blogs/aws/aws-greengrass-ubiquitous-real-world-computing/
- Lambda@Edge Preview: グローバル AWS エッジロケーションでコードを実行でき、Amazon CloudFront のリクエストに応じてトリガーされることで、エンドユーザーのネットワークレイテンシーを削減できる Lambda の新しい機能です。https://aws.amazon.com/blogs/aws/coming-soon-lambda-at-the-edge/
- AWS Batch Preview: 今後予定されているバッチジョブとしての Lambda 統合を含む AWS コンピューティングサービスにおけるワークロードの計画、スケジューリング、実行のコンピューティング用バッチです。https://aws.amazon.com/blogs/aws/aws-batch-run-batch-computing-jobs-on-aws/
- AWS X-Ray: マイクロサービスアーキテクチャを使用してビルドされたもの、Java、Node.js、.NET で記述されたもの、EC2、ECS、AWS Elastic Beanstalk にデプロイされたものなど、分散アプリケーションの分析とデバッグを実行します。今後予定されている AWS Lambda をサポートします。https://aws.amazon.com/blogs/aws/aws-x-ray-see-inside-of-your-distributed-application/
- Continuous Deployment for Serverless: サーバーレスアプリケーションのための継続的デプロイパイプラインを作成する AWS のサービスです。https://aws.amazon.com/blogs/compute/continuous-deployment-for-serverless-applications/
- Step Functions: 視覚的なワークフローを使用して、分散アプリケーションとマイクロサービスのコンポーネントを調整する信頼性の高い方法です。https://aws.amazon.com/blogs/aws/new-aws-step-functions-build-distributed-applications-using-visual-workflows/
- Dead Letter Queues: キューまたは他の通知システムへの Lambda 関数の失敗の通知をサポートします。
- C# Support: C# コード は AWS Lambda でサポートされる言語です。
- API Gateway Monetization: API Gateway と AWS Marketplace の統合
- API Gateway Developer Portal: 独自の開発者ポータルの作成を始めることができるオープンソースのサーバーレスウェブアプリケーションです。
Jeff が Step Functions などの分散アプリケーションやマイクロサービスを構築するための前述の新しいサービス機能についてほとんど紹介したので、一般的なサーバーレスユースケースの例であるリアルタイムのストリーム処理を使って、まだ説明されていない最後の 4 つの新しい機能について紹介しましょう。ストリーム処理のユースケースについてのこの説明では、データのストリームを処理する Lambda 関数から送られることのあるエラー通知のために、デッドレターキューを実装します。ストリームの処理には Node.js で記述された既存の Lambda 関数を用い、C# 言語を使って書き換えます。その後、API Gateway と AWS Marketplace の統合を利用して Lambda が支援する API の収益化の例を構築します。これは楽しみです。それでは、始めましょう。サンフランシスコとオースティンでの AWS 開発者デーの期間中、私はリアルタイムのストリーム処理で AWS Lambda を活用する例を、Twitter ストリーミング API を使ったストリーミングソリューションを見せるデモを作成して紹介しました。この例の方法に沿って、デッドレターキュー (DLQ)、C# サポート、API Gateway 収益化の特徴、API Gateway Developer Portal のオープンソースのテンプレートを紹介していきます。デモでは、「awscloud」または「serverless」 (またはその両方) のキーワードを含むコンソールまたはウェブアプリケーションのストリームのツイートを Twitter ストリーミング API から集めました。それらのツイートはリアルタイムで Amazon Kinesis Streams に送信され、Lambda が新しいレコードを検出し、NoSQL データベースである Amazon DynamoDB にツイートを書き込むことでストリーミングのバッチを処理します。これで、リアルタイムのストリーミング処理のデモのワークフローを理解できたので、Kinesis からのバッチレコードを処理する Lambda 関数についてより詳しく見てみましょう。まず、以下のとおり、Lambda 関数 DevDayStreamProcessor には、バッチサイズが 100 で DevDay2016Stream という名前の Kinesis ストリームであるイベントソース、またはトリガーがあります。Lambda 関数は新しいレコードのために定期的にストリームをポーリングし、レコードのバッチ、このケースではストリームで検出されたツイートを自動的に読み取って処理します。
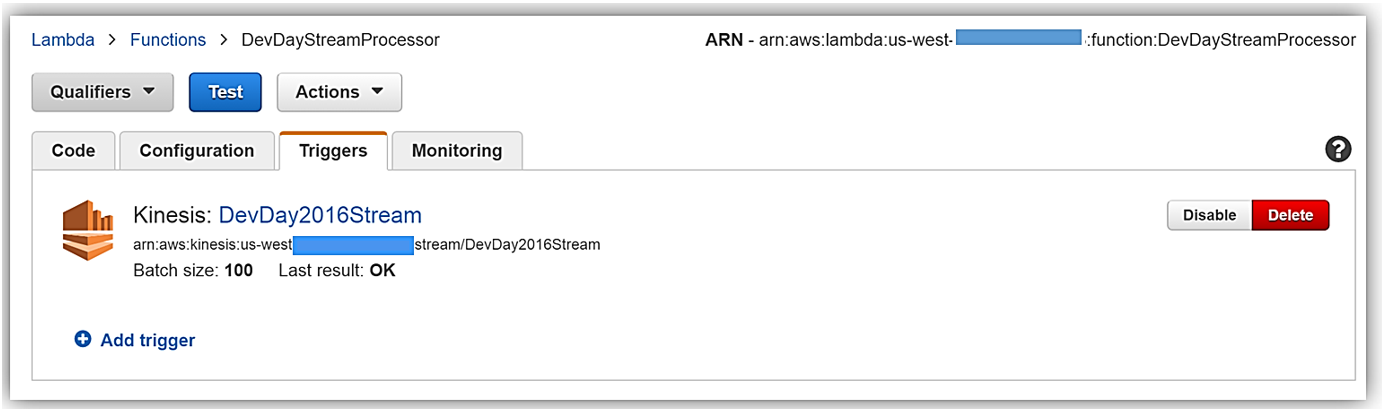
次に、Node.js 4.3. で記述された Lambda 関数のコードを調べます。以下に示す Lambda 関数のセクションは、Kinesis ストリームからのツイートレコードのバッチをループし、各レコードを解析し、一連の JSON データに必要なツイート情報を書き込みます。一連の JSON のツイート項目は Lambda ハンドラーの外部にある ddbItemsWrite 関数に渡されます。
'use strict';
console.log('Loading function');
var timestamp;
var twitterID;
var tweetData;
var ddbParams;
var itemNum = 0;
var dataItemsBatch = [];
var dbBatch = [];
var AWS = require('aws-sdk');
var ddbTable = 'TwitterStream';
var dynamoDBClient = new AWS.DynamoDB.DocumentClient();
exports.handler = (event, context, callback) => {
var counter = 0;
event.Records.forEach((record) => {
// Kinesis data is base64 encoded so decode here
console.log("Base 64 record: " + JSON.stringify(record, null, 2));
const payload = new Buffer(record.kinesis.data, 'base64').toString('ascii');
console.log('Decoded payload:', payload);
var data = payload.replace(/[\u0000-\u0019]+/g," ");
try
{ tweetData = JSON.parse(data); }
catch(err)
{ callback(err, err.stack); }
timestamp = "" + new Date().getTime();
twitterID = tweetData.id.toString();
itemNum = itemNum+1;
var ddbItem = {
PutRequest: {
Item: {
TwitterID: twitterID,
TwitterUser: tweetData.username.toString(),
TwitterUserPic: tweetData.pic,
TwitterTime: new Date(tweetData.time.replace(/( \+)/, ' UTC$1')).toLocaleString(),
Tweet: tweetData.text,
TweetTopic: tweetData.topic,
Tags: (tweetData.hashtags) ? tweetData.hashtags : " ",
Location: (tweetData.loc) ? tweetData.loc : " ",
Country: (tweetData.country) ? tweetData.country : " ",
TimeStamp: timestamp,
RecordNum: itemNum
}
}
};
dataItemsBatch.push(ddbItem);
counter++;
});
var twitterItems = {};
twitterItems[ddbTable] = dataItemsBatch;
ddbItemsWrite(twitterItems, 0, context, callback);
};
以下に示す ddbItemsWrite 関数は、Kinesis ストリームから処理された一連の JSON のツイートレコードを取り出し、バッチオペレーションを使用してレコードの複数の項目を同時に DynamoDB テーブルに書き込みます。この関数は、個々のテーブルのスロットリングによる書き込みリクエストの失敗を避けるため、エクスポネンシャルバックオフアルゴリズムを実装することにより、未処理の項目を再試行する DynamoDB のベストプラクティスを活用します。
function ddbItemsWrite(items, retries, ddbContext, ddbCallback)
{
dynamoDBClient.batchWrite({ RequestItems: items }, function(err, data)
{
if (err)
{
console.log('DDB call failed: ' + err, err.stack);
ddbCallback(err, err.stack);
}
else
{
if(Object.keys(data.UnprocessedItems).length)
{
console.log('Unprocessed items remain, retrying.');
var delay = Math.min(Math.pow(2, retries) * 100, ddbContext.getRemainingTimeInMillis() - 200);
setTimeout(function() {ddbItemsWrite(data.UnprocessedItems, retries + 1, ddbContext, ddbCallback)}, delay);
}
else
{
ddbCallback(null, "Success");
console.log("Completed Successfully");
}
}
}
);
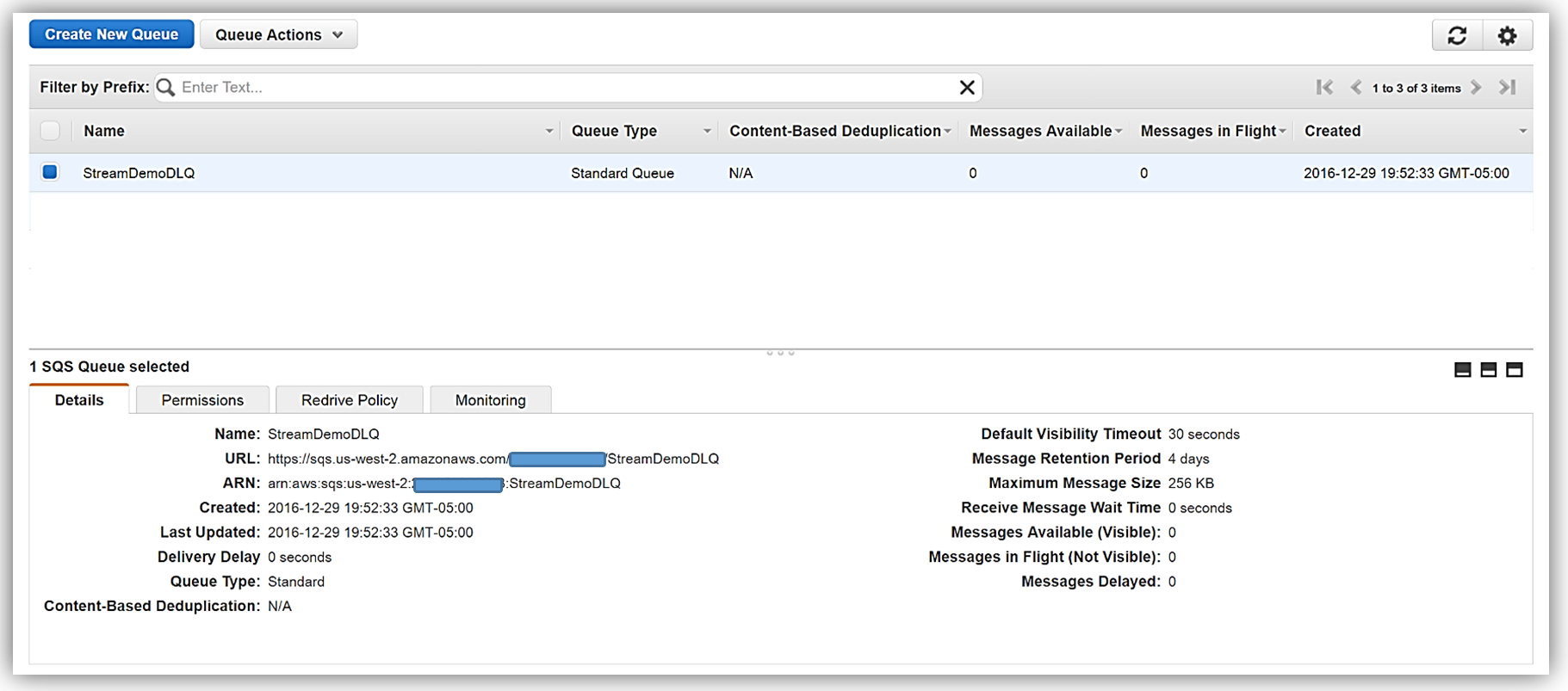
}現在、この Lambda 関数は期待通りに動作しており、Twitter ストリーミング API から Kinesis に取得されたツイートを問題なく処理します。しかし、この関数には、DynamoDB テーブルへのバッチ書き込みリクエストを処理するときにエラーが発生するという欠陥があります。Lambda 関数で、現在のコードでは、DynamoDB batchWrite 関数が 単一呼び出しにつき最大 25 の書き込み (PUT) リクエストで最大 16 MB のデータで構成されている必要があることが考慮されていません。そのため、ddbItemsWrite 関数を送信する前に、コードを適切に変更して ddbItemsWrite 関数を 25 のバッチに対応させるか、または、ハンドラー組み込み関数で項目を 25 リクエストの一連のグループにします。25 以上のツイート項目のバッチが送信されると検証の例外が発生します。これは、小規模なテストシナリオでは検出されにくくても、本稼働ワークロードでは失敗となるバグのよい例です。 デッドレターキュー これで、ddbItemsWrite Lambda 関数に例外をスローさせるイベント、または、レコードを処理する際に失敗となるイベントを認識できたので、デッドレターキュー (DLQ) を活用するのに最適なシナリオとなります。AWS Lambda DLQ 機能は Amazon S3、Amazon SNS、AWS IoT のような非同期イベント、または直接の非同期呼び出しでのみ使用可能で、Amazon Kinesis または Amazon DynamoDB ストリームのようなストリーミングイベントのソース向けではないので、最初のステップはこの Lambda 関数を 2 つの関数に分けることです。最初の Lambda 関数は Kinesis ストリームの処理に対応し、2 つめの関数は最初の関数で処理されたデータを取り出し DynamoDB にツイート情報を書き込みます。その後、上記のとおり DynamoDB へのツイートのバッチを書き込む際に生じるエラーのために、2 つめの Lambda 関数で DLQ をセットアップします。ターゲットを DLQ にセットアップするときに 2 つのオプションがあります。Amazon SNS トピック、または Amazon SQS キューです。この説明の中では、Amazon SQS キューの使用を選択します。そのため、DLQ を使用する際の最初のステップは、SQS 標準キューの作成です。標準キュータイプは高トランザクションスループットのあるキューです。メッセージが最低 1 回配信され、メッセージの別のコピーも配信されます。メッセージが、送信された順序とは異なる順序で配信されることがあります。SQS キューとキュータイプの詳細については、「Amazon SQS ドキュメント」をご覧ください。私のキュー、StreamDemoDLQ が作成されたら、この選択したキューの詳細タブから ARN をつかみます。コンソールを使用してこの関数に DLQ リソースを指定しない場合は、この SQS キューをエラーとイベント失敗通知のための DLQ ターゲットとして識別するため、Lambda 関数のためにキューの ARN が必要です。また、この SQS キューにアクセスする目的で Lambda 実行ロールポリシーにアクセス許可を追加するために ARN を使用します。
Lambda 関数に戻り、[Configuration] タブを選択して [Advanced settings] セクションを開きます。[DLQ Resource] フィールドで SQS を選択し、[SQS Queue] フィールドのドロップダウンから 私の [StreamDemoDLQ] キューを選択します。
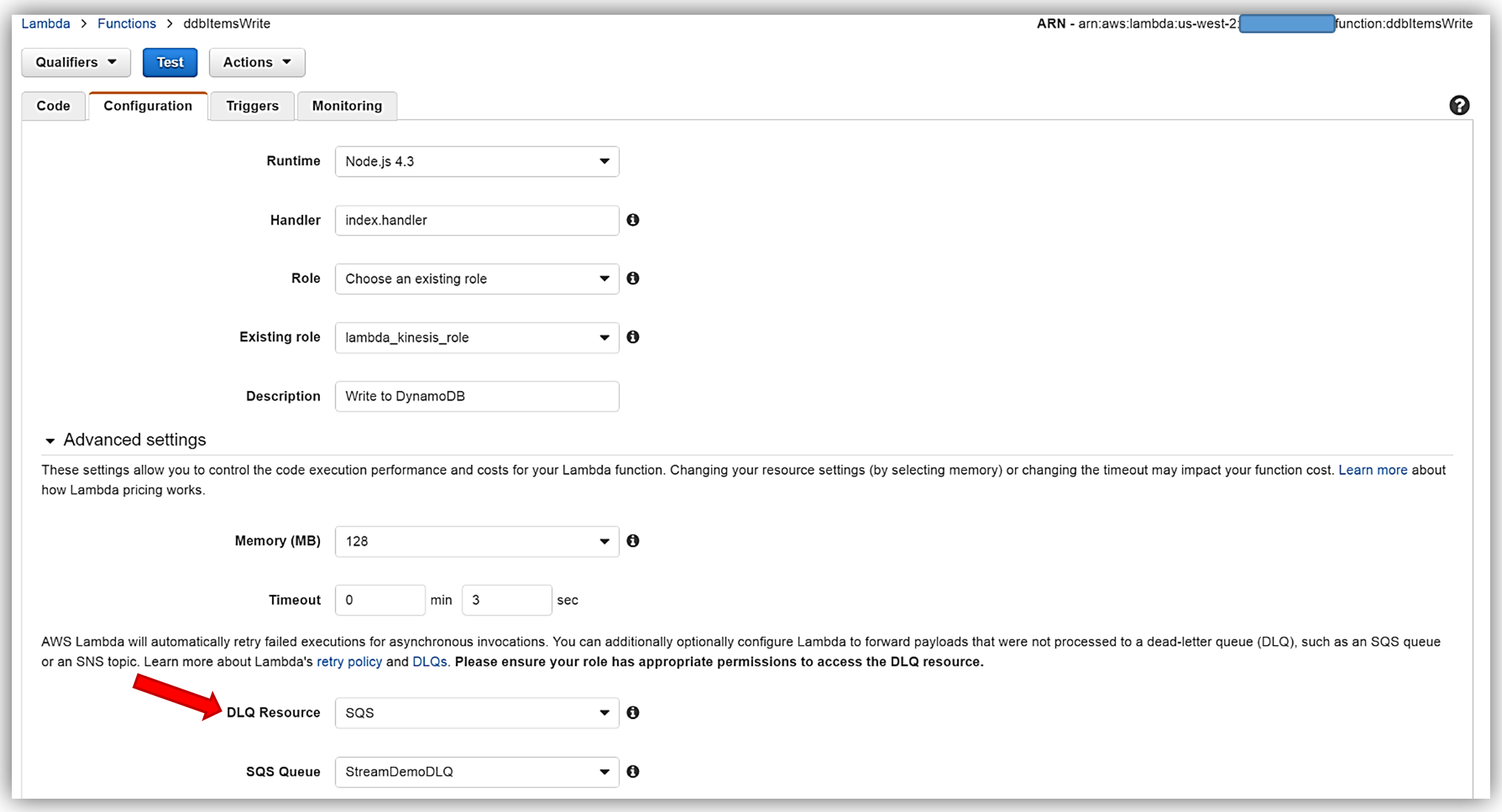
SQS DLQ へ正常にメッセージを送信するには、Lambda 関数の実行ロールは明示的に sqs:SendMessage のアクセスを許可する必要があります。そのため、私の Lambda ロール lambda_kinesis_role に以下の SQS アクセス権限のための IAM ポリシーがあることを確認しました。
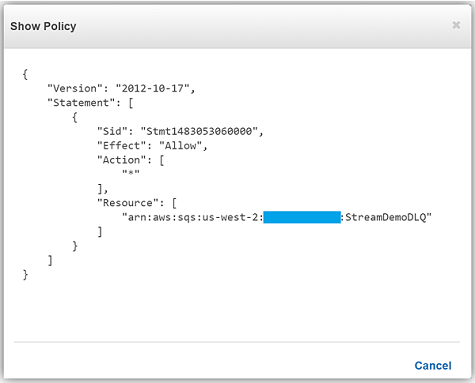
これで、Amazon SQS を使用して Lambda 関数のためのデッドレターキューを正常に設定できました。Lambda のデッドレターキューの詳細については、「AWS Lambda 開発者ガイド」の「トラブルシューティングとモニタリング」セクションをお読みください。また、デッドレターキューに関する「AWS コンピューティングブログの投稿」をご確認ください。
C# Support
前述のとおり、AWS re:Invent で Lambda に追加された別のすばらしい特徴は、オープンソース .NET Core 1.0 プラットフォームによる C# 言語のサポートです。Lambda コンソールはまだコンパイル済み言語の編集を提供していないので、C# Lambda 関数を記述するには、AWS Toolkit、Yeoman、または .NET CLI で Visual Studio のツールを使用できます。C# で記述された Lambda 関数をデプロイするには、AWS ToolKit for Visual Studio の Lambda プラグインを使用するか、または .NET Core コマンドラインでデプロイパッケージを作成します。C# Lambda 関数ハンドラーをクラスのインスタンスまたは静的メソッドとして定義する必要があります。2 つの関数パラメーターがあります。1 つめは、イベントデータである入力型で、もう 1 つは、タイプ ILambdaContext の Lambda コンテキストオブジェクトです。AWS のサービスのイベントデータ入力オブジェクトタイプには以下のものがあります。
- Amazon.Lambda.APIGatewayEvents
- Amazon.Lambda.CognitoEvents
- Amazon.Lambda.ConfigEvents
- Amazon.Lambda.DynamoDBEvents
- Amazon.Lambda.KinesisEvents
- Amazon.Lambda.S3Events
- Amazon.Lambda.SNSEvents
Lambda の C# サポートの詳細について説明したので、DevDayStreamProcessor Lambda 関数を C# 言語で書き換えましょう。この例では、Lambda 関数を記述するのに Visual Studio IDE を使用します。また、関数をデプロイするのに、AWS Lambda Visual Studio プラグインを活用します。Lambda で AWS Toolkit for Visual Studio を使用するには、Visual Studio 2015 Update 3 バージョンと NET Core ツールが必要なことに留意してください。Visual Studio 2015 Update 3 と .NET Core のインストールの詳細については、こちらをお読みください。Visual Studio を使用して C# 関数を作成するには、新しいプロジェクトを開始し、[AWS Lambda Project (.NET Core)] を選択して ServerlessStreamProcessor という名前を付けます。
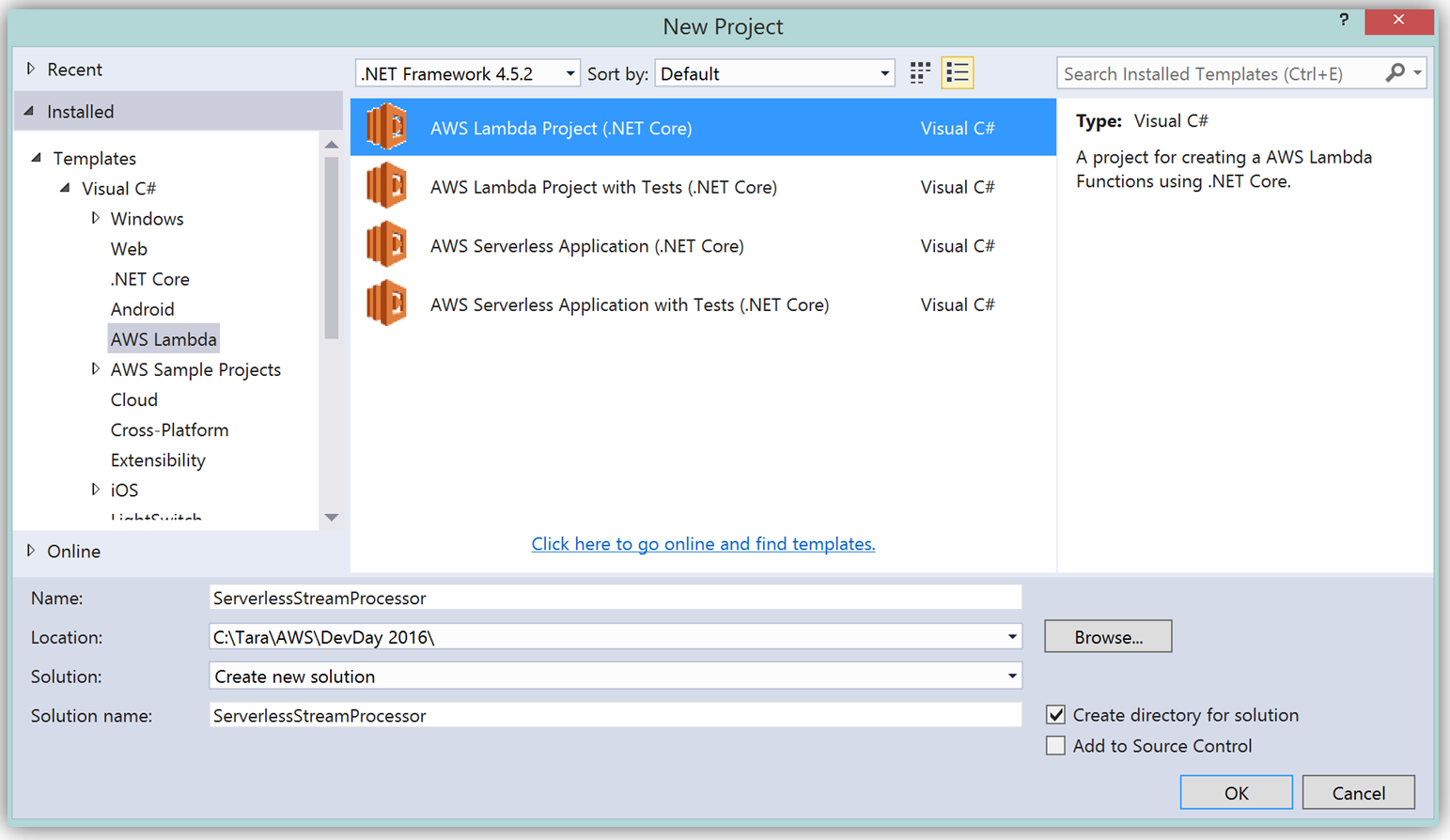
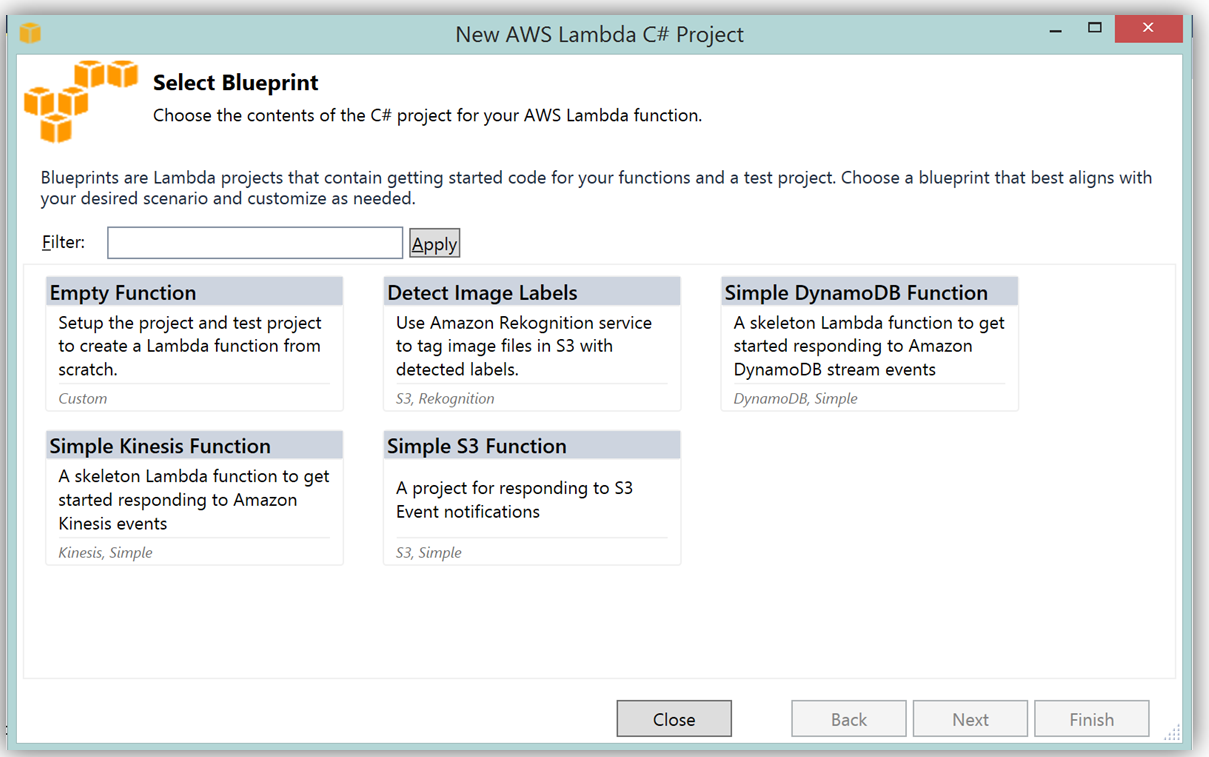
この関数を記述するのに AWS Toolkit for Visual Studio を活用することの大きな利点は、Lambda コンソールを使用するのと同様の方法で Visual Studio の中で Lambda 設計図を使用できることです。それで、DevDayStreamProcessor を C# でレプリケートするために、Simple Kinesis Function 設計図を選択します。
Lambda 関数を C# で記述する場合、クラスの宣言やターゲットのハンドラー関数を Lambda 関数としてマークする必要はありません。また、CloudWatch ログを記述する場合は、標準 C# の Console クラスの WriteLine 関数を使用するか、ILambdaContext インターフェイスの一部である ILambdaContext の LogLine 関数を使用することができます。所定の Kinesis ストリームにアクセスするためのテンプレートでは、C# Lambda 関数の ServerlessStreamProcessor を記述するために Node.js コードの DevDayStreamProcessor と同じ変数名を使用します。以下の C# Lambda ハンドラー関数をご覧ください。
using System.Collections.Generic;
using Amazon.Lambda.Core;
using Amazon.Lambda.KinesisEvents;
using Amazon.DynamoDBv2;
using Amazon.DynamoDBv2.DataModel;
using Newtonsoft.Json.Linq;
// Assembly attribute to enable the Lambda function's JSON input to be converted into a .NET class.
[assembly: LambdaSerializerAttribute(typeof(Amazon.Lambda.Serialization.Json.JsonSerializer))]
namespace ServerlessStreamProcessor
{
public class LambdaTwitterStream
{
string twitterID, timeStamp;
int itemNum = 0;
private static AmazonDynamoDBClient dynamoDBClient = new AmazonDynamoDBClient();
List<TwitterItem> dataItemsBatch = new List<TwitterItem>();
public void FunctionHandler(KinesisEvent kinesisEvent, ILambdaContext context)
{
DynamoDBContext dbContext = new DynamoDBContext(dynamoDBClient);
context.Logger.LogLine($"Beginning to process {kinesisEvent.Records.Count} records...");
foreach (var record in kinesisEvent.Records)
{
context.Logger.LogLine($"Event ID: {record.EventId}");
context.Logger.LogLine($"Event Name: {record.EventName}");
// Kinesis data is base64 encoded so decode here
string tweetData = GetRecordContents(record.Kinesis);
context.Logger.LogLine($"Decoded Payload: {tweetData}");
tweetData = @"" + tweetData;
JObject twitterObj = JObject.Parse(tweetData);
twitterID = twitterObj["id"].ToString();
timeStamp = DateTime.Now.Millisecond.ToString();
itemNum++;
context.Logger.LogLine(timeStamp);
context.Logger.LogLine($"Twitter ID is: {twitterID}");
context.Logger.LogLine(itemNum.ToString());
TwitterItem ddbItem = new TwitterItem()
{
TwitterID = twitterID,
TwitterUser = twitterObj["username"].ToString(),
TwitterUserPic = twitterObj["pic"].ToString(),
TwitterTime = DateTime.Parse(twitterObj["time"].ToString()).ToUniversalTime().ToString(),
Tweet = twitterObj["text"].ToString(),
TweetTopic = twitterObj["topic"].ToString(),
Tags = twitterObj["hashtags"] != null ? twitterObj["hashtags"].ToString() : String.Empty,
Location = twitterObj["loc"] != null ? twitterObj["loc"].ToString() : String.Empty,
Country = twitterObj["country"] != null ? twitterObj["country"].ToString() : String.Empty,
TimeStamp = timeStamp,
RecordNum = itemNum
};
dataItemsBatch.Add(ddbItem);
}
context.Logger.LogLine(JObject.FromObject(dataItemsBatch).ToString());
ddbItemsWrite(dataItemsBatch, 0, dbContext, context);
context.Logger.LogLine("Success - Completed Successfully");
context.Logger.LogLine("Stream processing complete.");
}C# で記述された Kinesis ストリームプロセッサと当初の Node.js コード間の注意すべき差異はわずかです。C# Lambda 関数でデフォルトでサポートされている入力パラメータータイプは System.IO.Stream タイプであるため、Kinesis base64 文字列は、設計図で提供されている GetRecordContents 関数で StreamReader (エンコーディングは ASCII) を使用してデコードされます。
private string GetRecordContents(KinesisEvent.Record streamRecord)
{
using (var reader = new StreamReader(streamRecord.Data, Encoding.ASCII))
{
return reader.ReadToEnd();
}
}ツイートのデータを DynamoDB テーブルに書き込むために、Visual Studio 内で NuGet パッケージマネージャーを経由して DynamoDB; AWSSDK.DynamoDBv2 の AWS .NET SDK NuGet パッケージを Lambda 関数プロジェクトに追加しました。また、DynamoDB テーブルに保存されるデータにマッピングするために .NET データオブジェクトとして TwitterItem も作成しました。DynamoDB 用の AWS .NET SDK 高レベルプログラミングインターフェイス、オブジェクト永続性モデルを使用して、ddbItemsWrite C# 関数の BatchWrite オブジェクトクラスを介して書き込む TwitterItem オブジェクトのコレクションを作成しました。
private async void ddbItemsWrite(List<TwitterItem> items, int retries, DynamoDBContext ddbContext, ILambdaContext context)
{
BatchWrite<TwitterItem> twitterStreamBatchWrite = ddbContext.CreateBatchWrite<TwitterItem>();
try
{
twitterStreamBatchWrite.AddPutItems(items);
await twitterStreamBatchWrite.ExecuteAsync();
}
catch (Exception ex)
{
context.Logger.LogLine($"DDB call failed: {ex.Source} ");
context.Logger.LogLine($"Exception: {ex.Message}");
context.Logger.LogLine($"Exception Stacktrace: {ex.StackTrace}");
}
}
AWS Toolkit for Visual Studio を使用して、C# Lambda 関数を作成する別のメリットは、1 回クリックするだけで Lambda 関数を直接 AWS にデプロイできることです。ソリューションエクスプローラーでプロジェクト名を選択し、右クリックすると、メニューオプションに Publish to AWS Lambda が出て、AWS へのデプロイ用の Lambda 関数について含めるべき情報のメニューが表示されます。
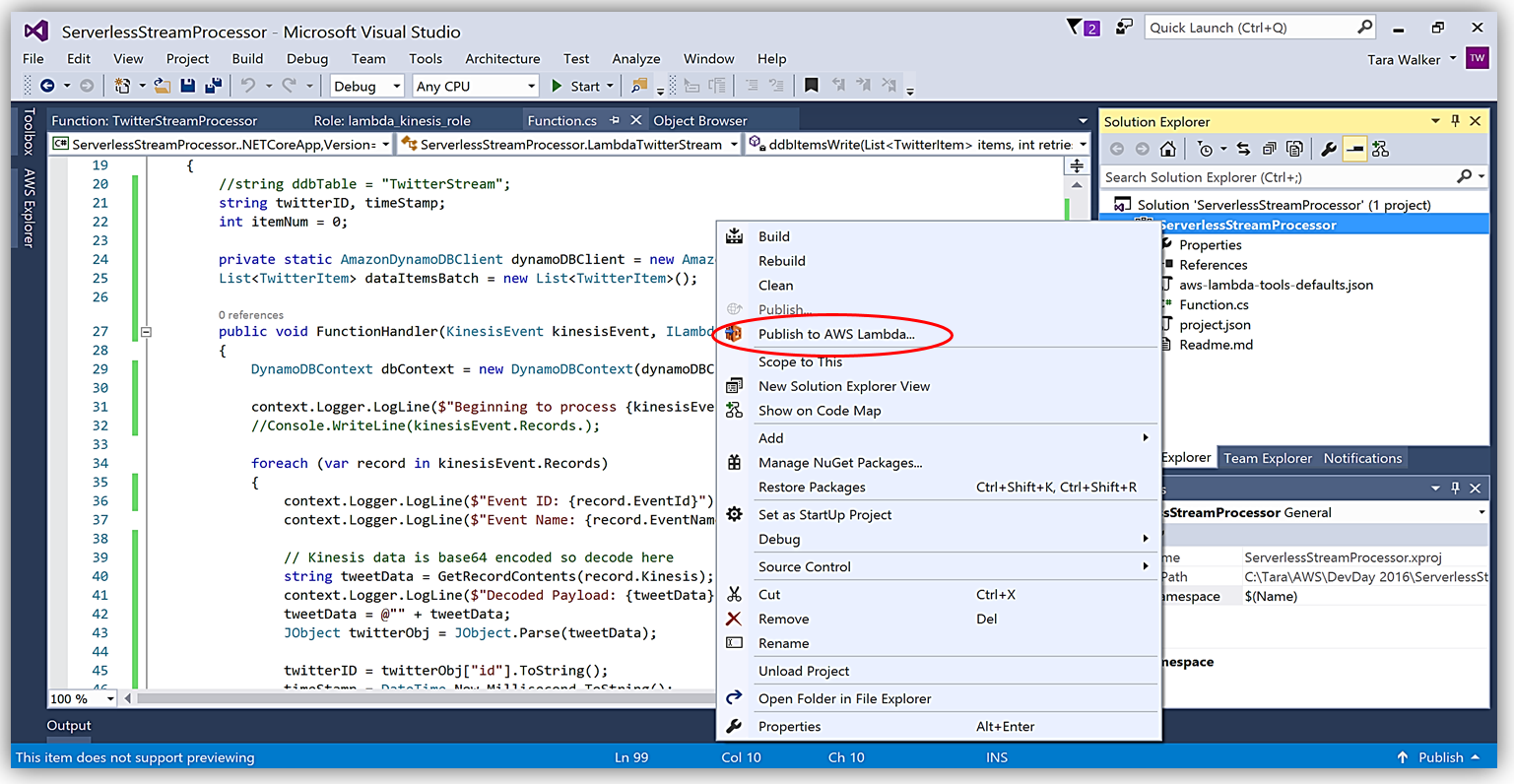
ハンドラー関数の署名は Assembly :: Namespace :: ClassName :: Method の命名法に従います。したがって、ここに示される C# Lambda 関数の署名は ServerlessStreamProcessor :: ServerlessStreamProcessor.LambdaTwitterStream :: FunctionHandler であることに注意してください。この情報は [Upload to AWS Lambda] ダイアログボックスに提供され、[Next] を選択して、関数にロールを割り当てます。
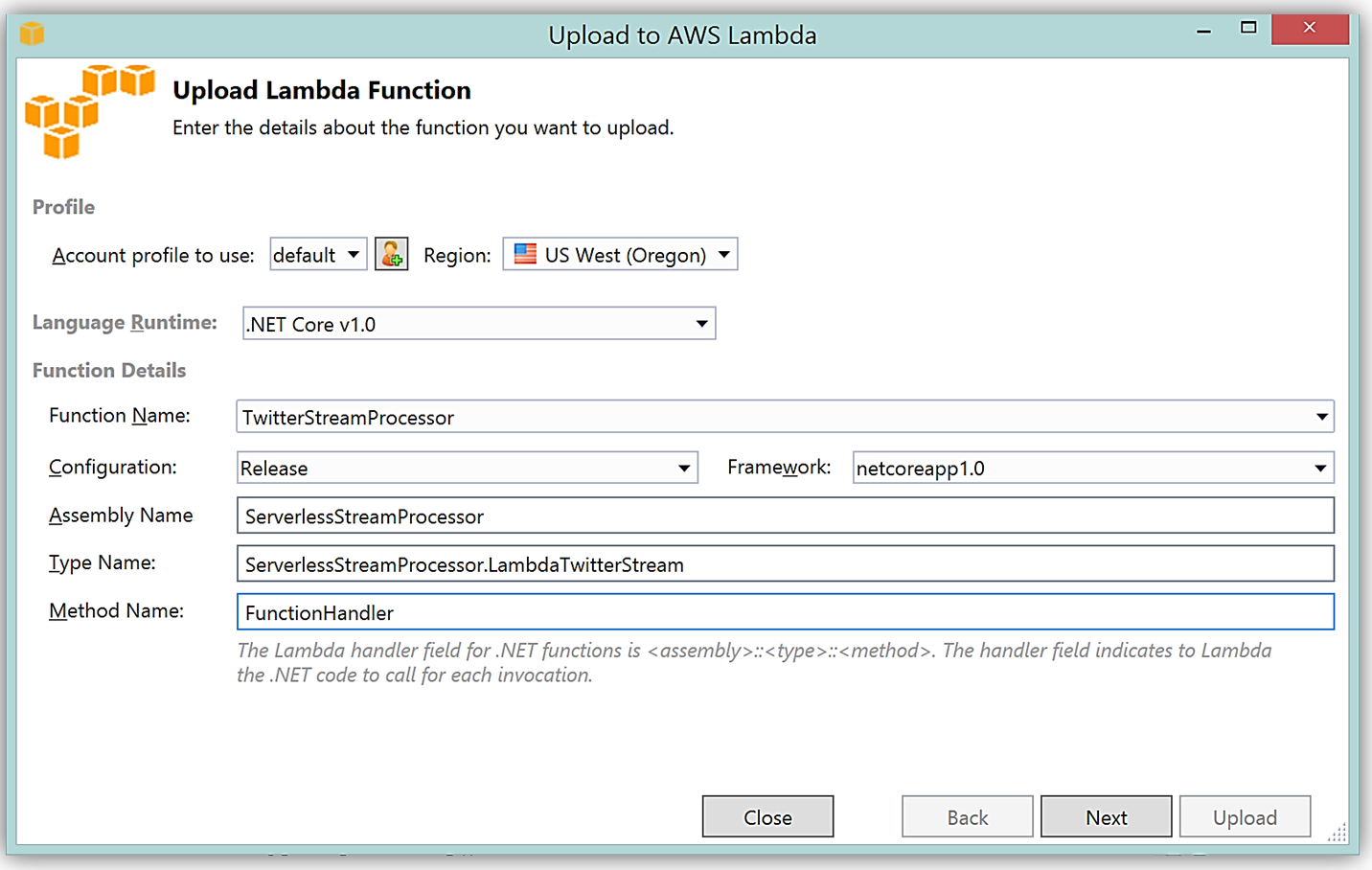
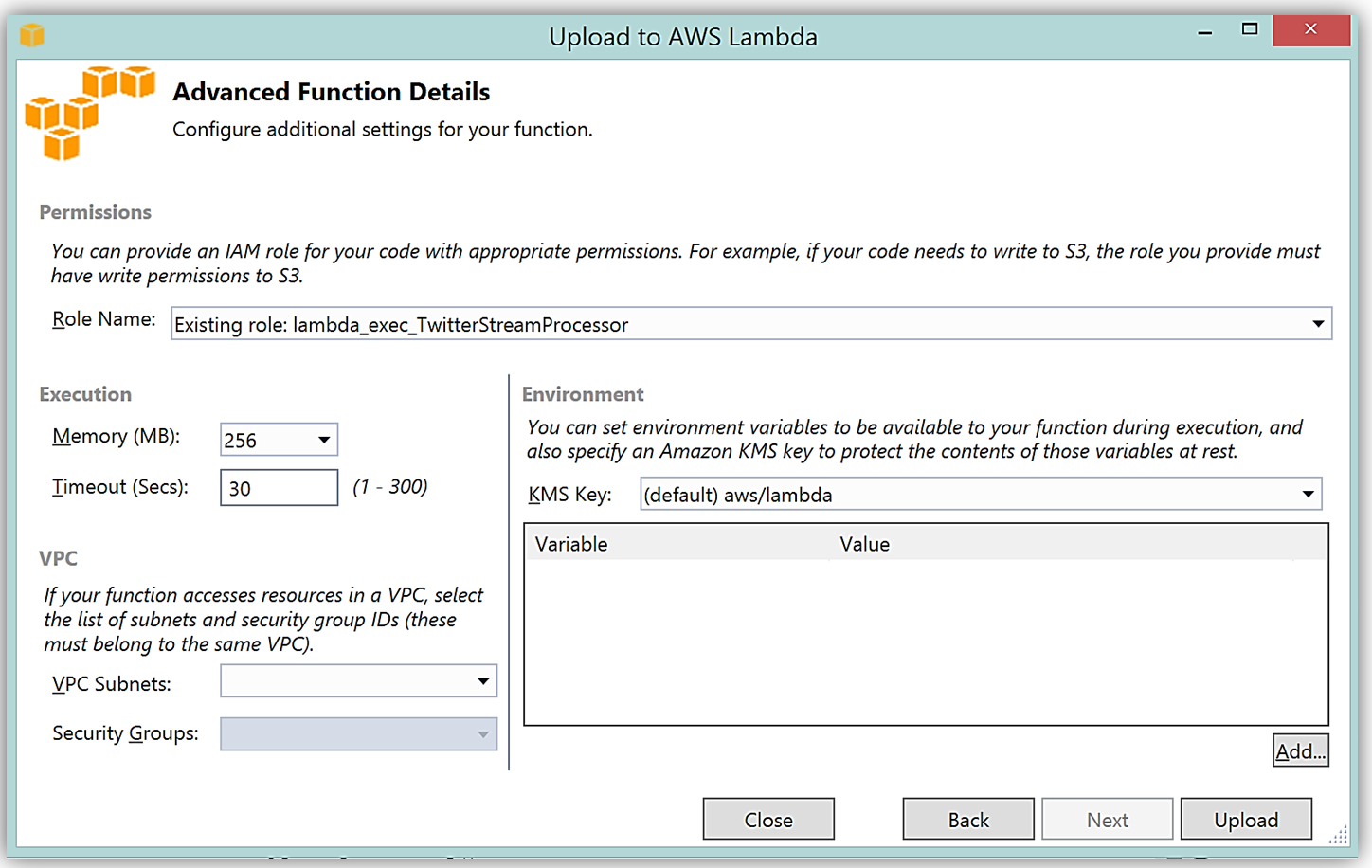
完了すると、AWS toolkit が提供するプラグイン (以下に示す) を使用して Lambda コンソールまたは Visual Studio で、Lambda 関数開発の反復アプローチのためにトリガーするイベントソースのサンプルデータを使用してテストできます。
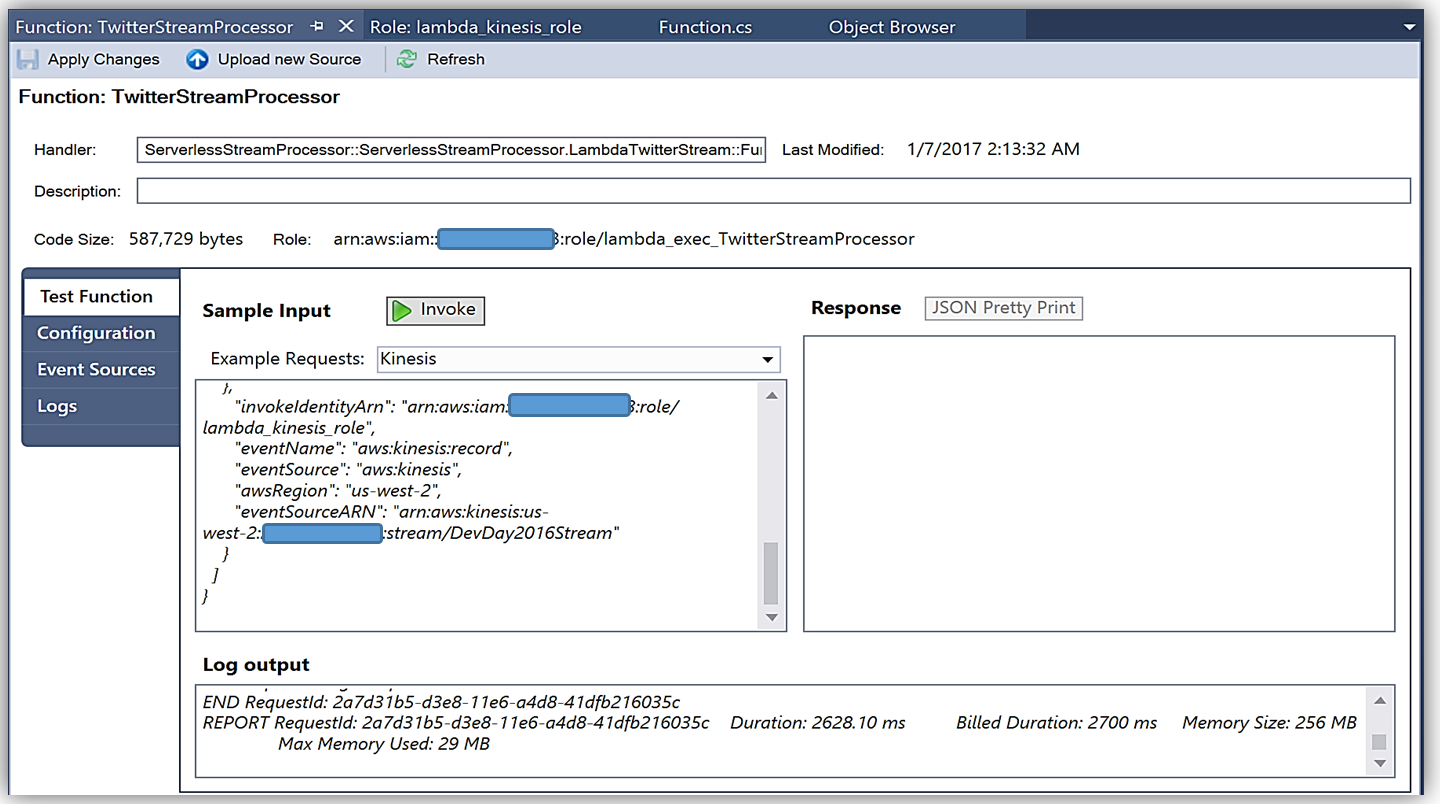
C# 言語を使用した AWS Lambda 関数の作成に関しての詳細については、「AWS Lambda 開発者ガイド」、またはコンピューティングブログの C# のサポートを発表した投稿をご覧ください。
API Gateway 収益化および開発者ポータル
マイクロサービスモーメンタムに従ってきたのなら、マイクロサービスのソリューションを構成する個別のサービスへのアクセスと公開を管理するためにスマートエンドポイントの使用または REST API 経由での API gateway の使用 (またはその両方) が必要なアーキテクチャーパターンを認識している場合があります。Amazon API Gateway により RESTful API の作成と管理をして AWS Lambda 関数、外部 HTTP エンドポイント、他の AWS のサービスを公開できるようになります。加えて、Amazon API Gateway により、クライアントおよび外部開発者が、HTTP プロトコル、または、プラットフォーム/言語対象の SDK を介してデプロイされた API にアクセスできるようになります。AWS Marketplace の SaaS サブスクリプションの導入と API Gateway と AWS Marketplace との統合により、AWS Marketplace の API Gateway を使用して、作成した API を顧客が直接利用できるようにすることで、API の収益化が可能になりました。AWS のお客様は、既存の AWS アカウントを使用して、マーケットプレイスで公開されている API をサブスクライブして支払うことができます。API Gateway と AWS Marketplace との統合により、AWS Marketplace で開始するプロセスは簡単です。開始するには、Amazon API Gateway で、使用プラン機能を有効にしていることを確認する必要があります。
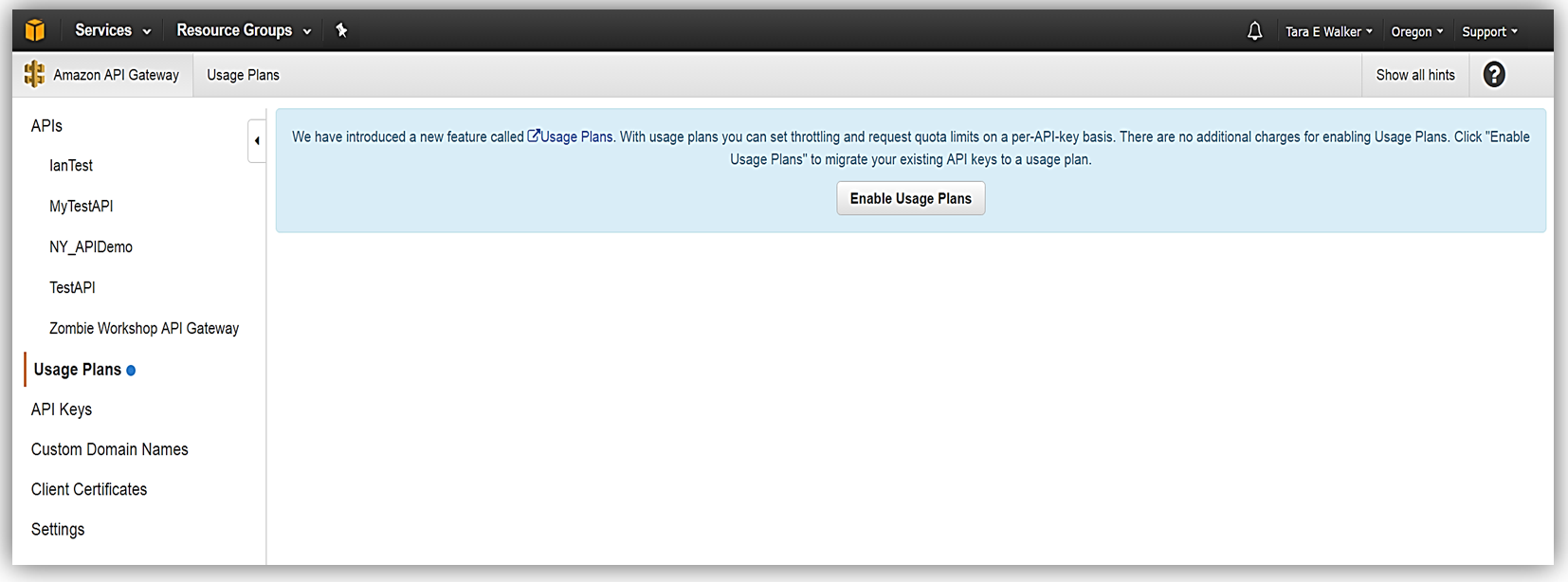
有効化した後、使用プランを作成します。目標のレートおよびバーストリクエストのしきい値を使用して、スロットリングを有効にし (必要に応じて)、最後に、一定のタイムフレームあたりの目標リクエストのクォータを指定して、クォータを有効にします (選択した場合)。
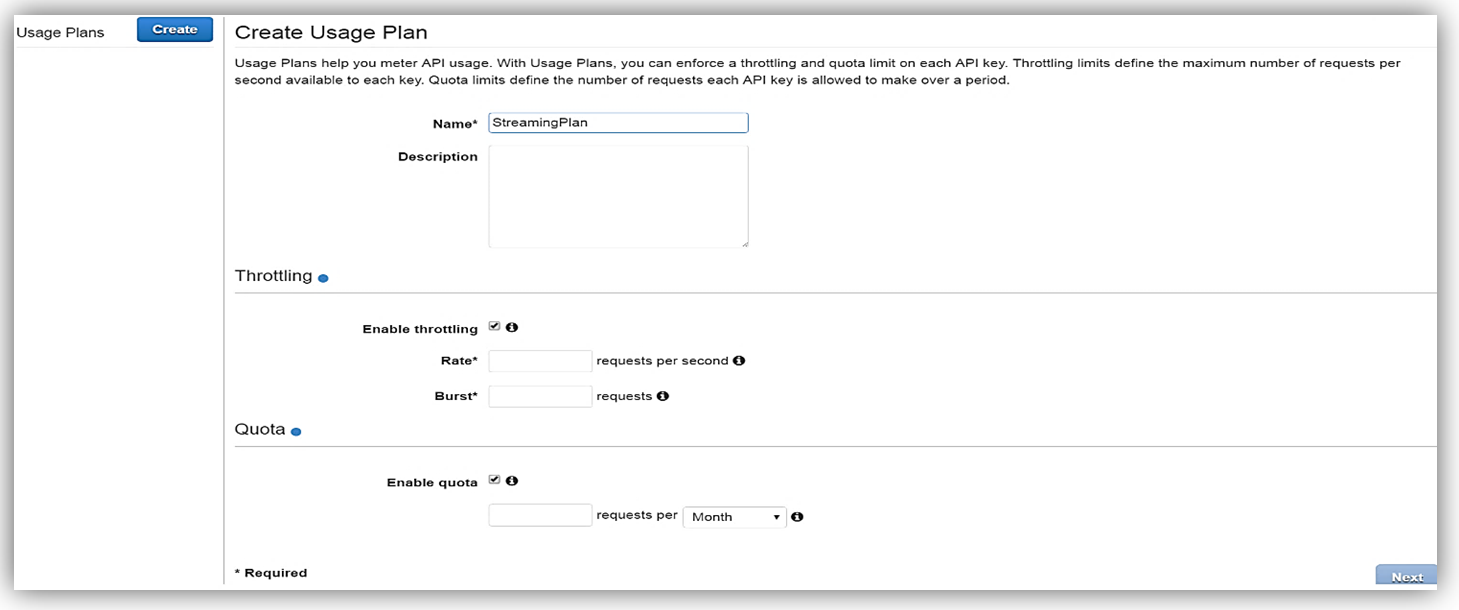
次に、使用プランと関連付ける API と関連するステージを選択します。特定の API を使用プランに関連付けることを選択できないため、これはオプションの手順であることに注意してください。
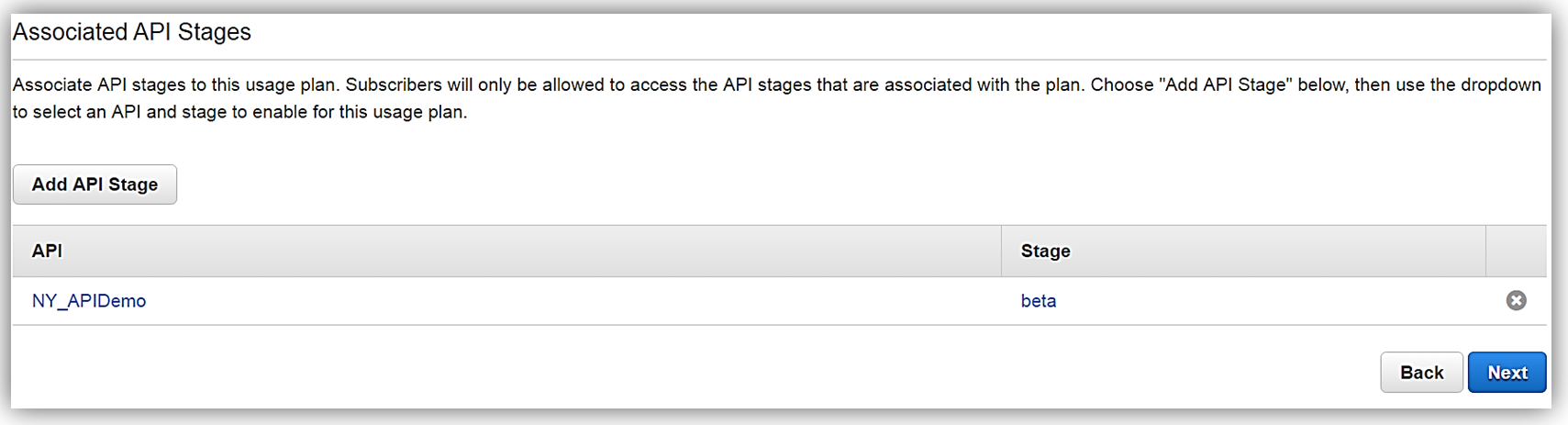
あとは、API キーを使用プランに追加または作成するだけです。使用プランの作成において、この手順もまたオプションであることにご注意ください。
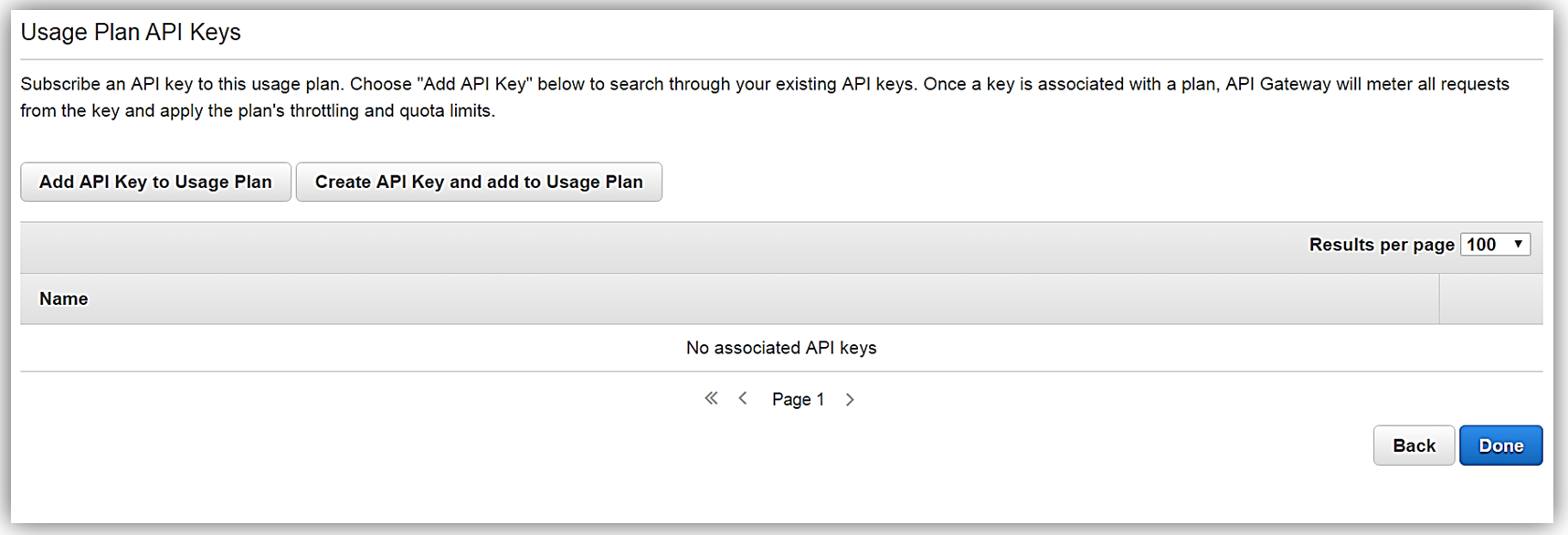
使用プラン StreamingPlan ができたので、マーケットプレイスで API を販売する準備のための次のステップに進むことができます。さまざまな API とその制限を使用して、複数の使用プランを作成し、これらのプランを AWS Marketplace で、差別化された API 製品として販売するオプションがあります。
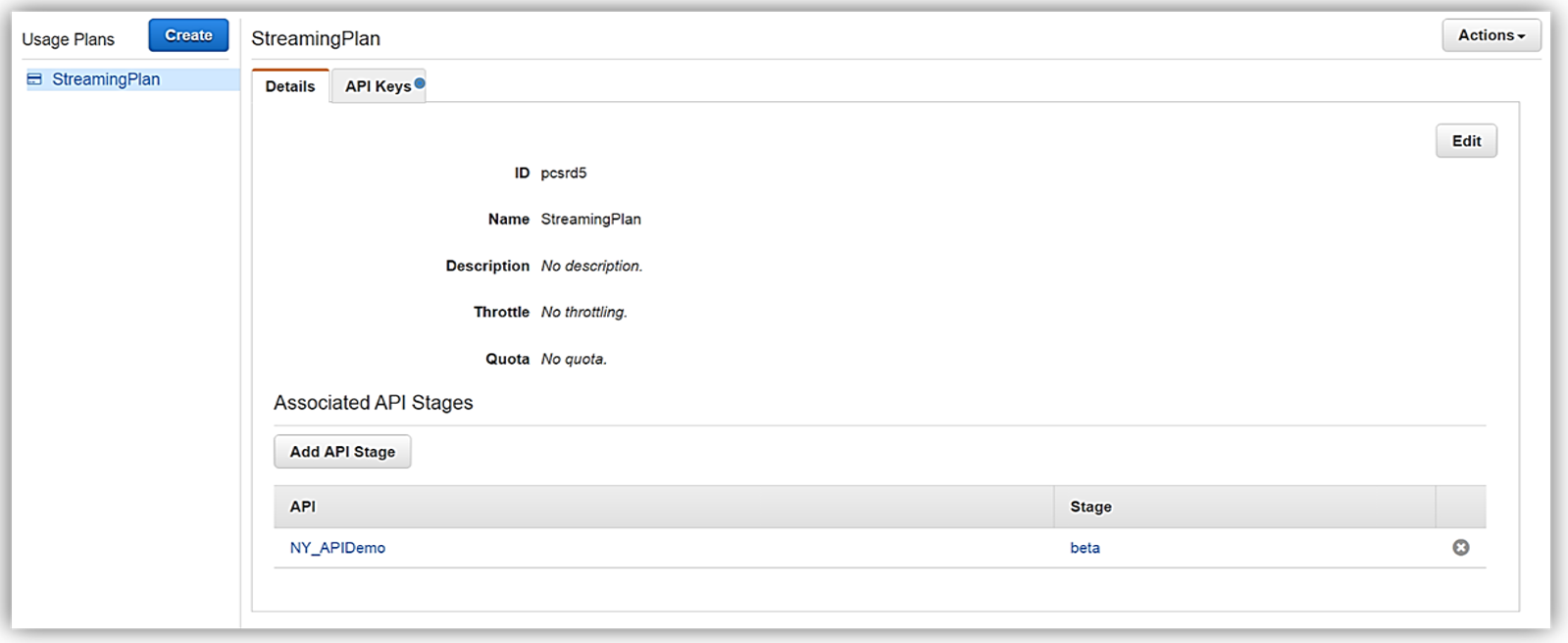
ただし、顧客が新しい API 製品を購入できるようにするため、AWS Marketplace では、各 API 製品にサブスクリプションリクエストを処理する外部開発者ポータルがあり、API の詳細情報および使用管理機能を提供する必要があります。このようなマーケットプレイスでの外部開発者ポータルに対する顧客のニーズにより、新しいオープンソース API Gateway 開発者ポータルサーバーレスウェブアプリケーションの実装が誕生しました。API Gateway 開発者ポータルプロジェクトの目標は、開発者のサインアップを許可しつつ、顧客が数ステップの簡単な手順に従って、API Gateway で構築した API のカタログをリスト表示するサーバーレスウェブアプリケーションを作成することです。API Gateway 開発者ポータルは AWS Serverless Express に構築されており、AWS により発行されたオープンソースライブラリーで、Node.js Express フレームワークを使用して、ウェブアプリケーション/サービスを構築するために AWS Lambda および Amazon API Gateway を利用する際に役立ちます。加えて、API Gateway 開発者ポータルアプリケーションは AWS SAM (サーバーレスアプリケーションモデル) テンプレートを使用して、そのサーバーレスリソースをデプロイします。AWS SAM は簡略化された CloudFormation テンプレートおよび仕様で、AWS でのサーバーレスアプリケーションの管理とデプロイを簡単にします。API Gateway ポータルを使用して開発者ポータルを構築するには、GitHub から aws-api-gateway-developer-portal プロジェクトをクローン作成することから始めます。
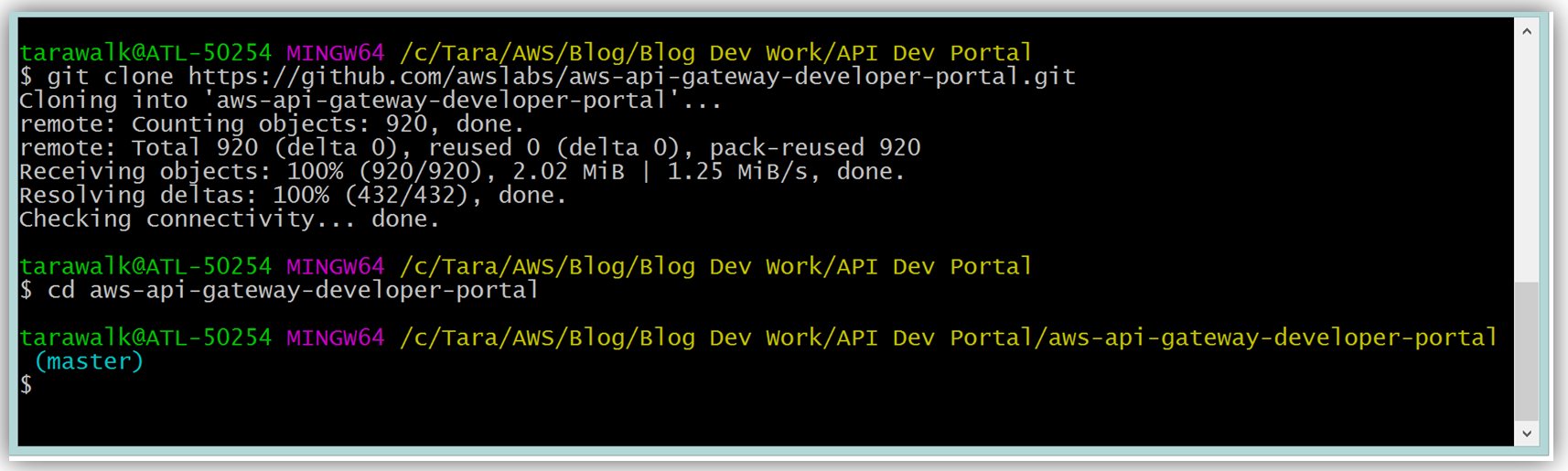
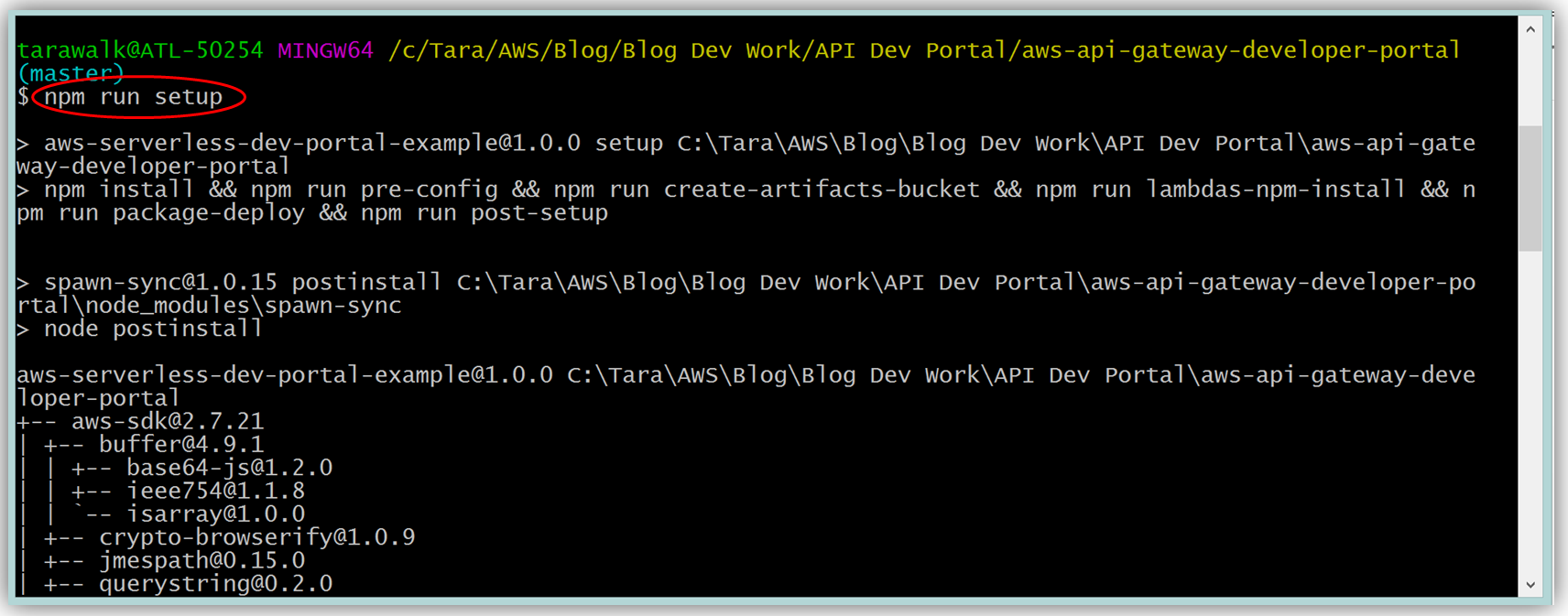
AWS CLI および Node.js の最新版をインストール済みであれば、Mac および Linux OS ユーザー用のコマンドラインで、“npm run setup” を実行して、開発者ポータルを設定します。Windows ユーザーは、コマンドラインで “npm run win-setup” を実行して、開発者ポータルを設定します。
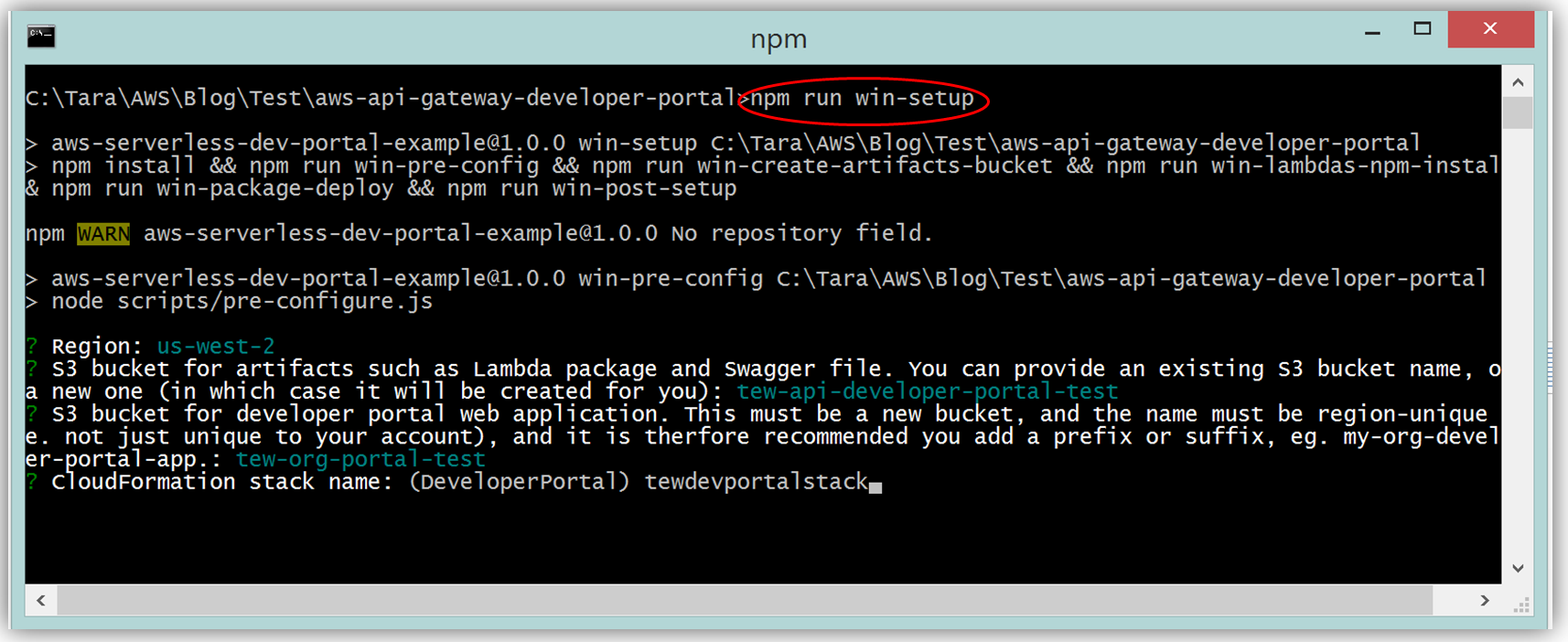
結果として、S3 で実行する機能的なサンプル開発者ポータルウェブサイトができ、これをカスタマイズして独自の API 用の開発者ポータルを作成できます。
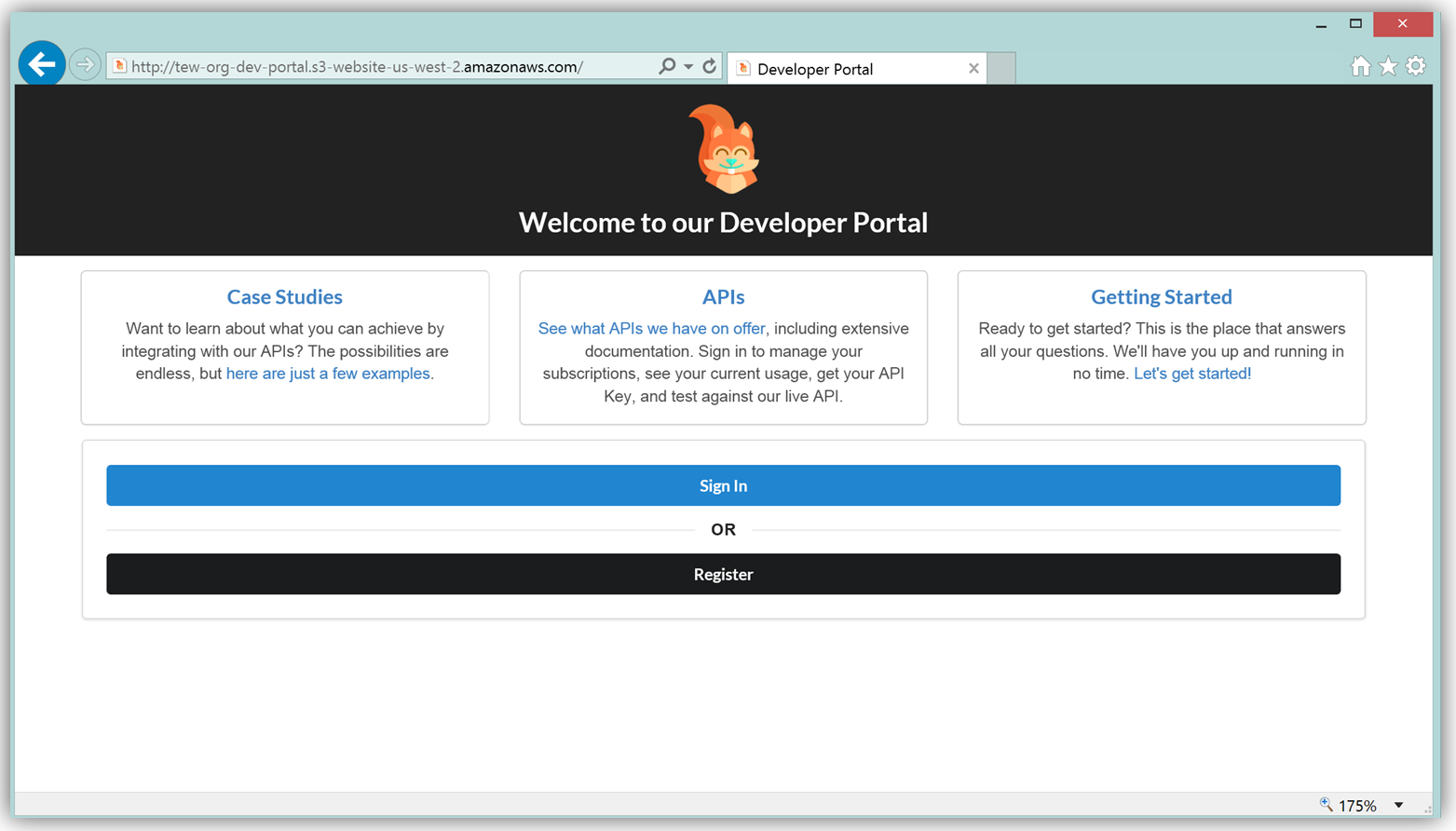
サンプルの開発者ポータルウェブサイトのフロントエンドは、React JavaScript ライブラリを使用して構築されており、バックエンドは aws-serverless-express ライブラリを使用して、AWS Lambda 関数が実行されています。加えて、SNS イベントソースを使用した Lambda 関数は、顧客が AWS Marketplace コンソールを介して API をサブスクライブまたはサブスクライブ解除する際の通知のためのリスナーとして作成されています。このリファレンスプロジェクトを使用した API Gateway 開発者ポータルウェブアプリケーションの構築、カスタマイズ、デプロイの手順についての詳細は、アーキテクチャと実装について詳細に説明している「AWS コンピューティングブログの投稿」を参照してください。 API を収益化する次の主なステップは、AWS Marketplace でアカウントを作成することです。アカウントをまだ作成していない場合、登録は「AWS Marketplace Seller Guide」で説明されている必要な前提条件を満たしていることを確認し、AWS Marketplace 管理ポータルのセラー登録フォームに入力するだけです。以下で、セラー登録フォームの冒頭のスナップショットを確認できます。
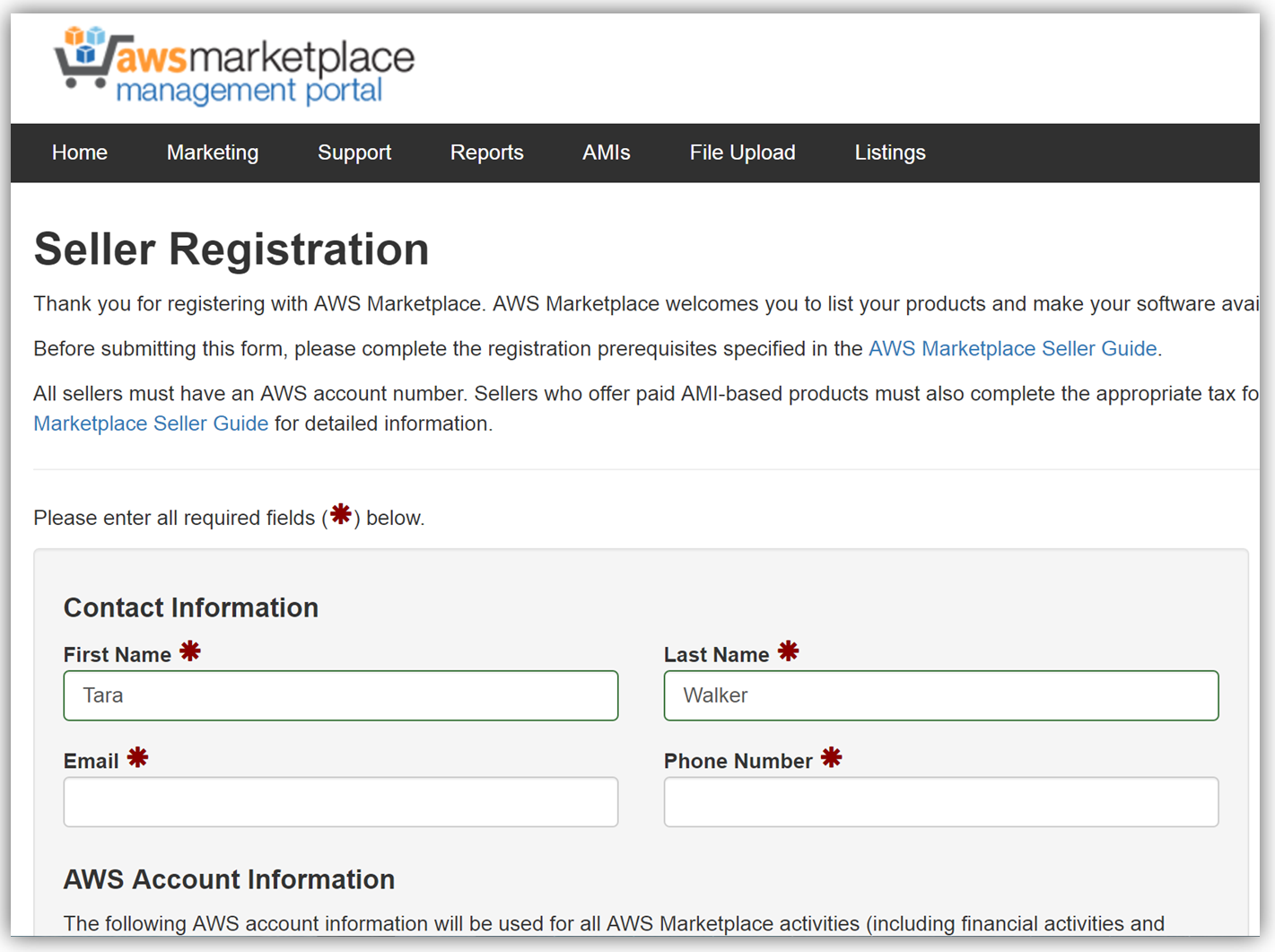
API を一覧表示するには、API を説明する製品ロードフォームに入力し、API の価格を設定して、API サブスクリプションプロセスをテストする AWS アカウントの ID を指定します。このフォームを入力する場合、API 開発者ポータル用の URL も送信する必要があります。販売者登録が完了したら、AWS Marketplace 製品コードが指定されます。Marketplace 製品コードを API 使用プランと関連付ける必要があります。この手順を完了するために、API Gateway コンソールにログインし、API 使用プランに移動します。[Marketplace] タブに移動し、製品コードを入力します。これにより、API Gateway は、API が使用されると測定データを AWS Marketplace に送信します。
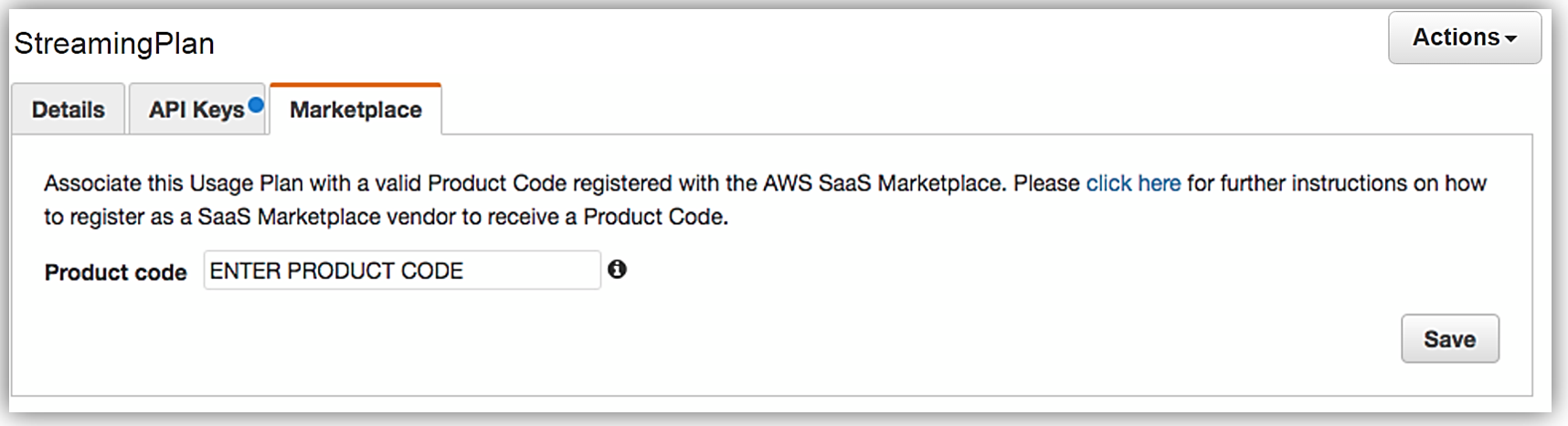
Amazon API Gateway が管理する API が使用プランにパッケージ化され、付随する API 開発者ポータルが作成され、販売者アカウント登録が完了し、製品コードが API プランと関連付けられたので、AWS Marketplace で API を収益化する準備ができました。API Gateway で作成された API の収益化に関する詳細については、関連するブログの投稿と API Gateway 開発者ガイドドキュメントを確認してください。
要約
ご覧いただいたとおり、AWS チームは 2016 年中、サーバーレスアーキテクチャの作成およびデプロイにおける顧客エクスペリエンスを向上させるため、また、API Gateway が管理する API を生成し、収益をあげるためのメカニズムを提供するため努力してきました。AWS Lambda および Amazon API Gateway の製品のドキュメントをご覧になり、これらのサービス、およびすべての新しくリリースされた機能の詳細を確認してください。
– Tara
AWS LambdaのC#サポートの発表
本日、AWS Lambdaのサポート言語としてC#を発表しました。新しいオープンソースの.NET Core 1.0ランタイムを使用すると、さまざまな一般的な.NETツールからC#コードをAWS Lambdaに簡単に公開できます。 .NET開発者は、C#言語と使い慣れた.NETツールを使用して、Lambda関数とサーバーレス アプリケーションを作成できます。 Visual Studio、Yeoman、およびdotnet CLIにおけるツール サポートによって、C#で記述された個々のLambda関数またはサーバーレスアプリケーション全体をLambdaおよび Amazon API Gatewayに簡単に展開できます。
LambdaはAWSサーバーレスプラットフォームの中核です。もともと2015年に発売されたLambdaでは、インフラストラクチャやスケーリングを心配することなく、Node.js、Python、およびJavaコードをAWSに展開することができます。これにより、開発者はアプリケーションのビジネスロジックに集中でき、インフラストラクチャの維持と拡張に時間を費やす必要がありません。今日まで、.NET開発者はこのモデルを利用することができませんでした。サポートされている言語のリストにC#を追加し、サーバーレスアプリケーションを作成すためにLambdaとAPIゲートウェイを利用する新しいカテゴリの開発者ができたことを嬉しく思っています。
C#でのLambda
単純なC#ラムダ関数を見てください。 既にNode.js、Python、JavaでLambdaを使っていたなら、これはよく分かるはずです:
using System;
using System.IO;
using System.Text;
using Amazon.Lambda.Core;
using Amazon.Lambda.DynamoDBEvents;
using Amazon.Lambda.Serialization.Json;
namespace DynamoDBStreams
{
public class DdbSample
{
private static readonly JsonSerializer _jsonSerializer = new JsonSerializer();
[LambdaSerializer(typeof(JsonSerializer))]
public void ProcessDynamoEvent(DynamoDBEvent dynamoEvent)
{
Console.WriteLine($"Beginning to process {dynamoEvent.Records.Count} records...");
foreach (var record in dynamoEvent.Records)
{
Console.WriteLine($"Event ID: {record.EventID}");
Console.WriteLine($"Event Name: {record.EventName}");
string streamRecordJson = SerializeObject(record.Dynamodb);
Console.WriteLine($"DynamoDB Record:");
Console.WriteLine(streamRecordJson);
}
Console.WriteLine("Stream processing complete.");
}
private string SerializeObject(object streamRecord)
{
using (var ms = new MemoryStream())
{
_jsonSerializer.Serialize(streamRecord, ms);
return Encoding.UTF8.GetString(ms.ToArray());
}
}
}
}Lambdaでサポートされている他の言語と同様に、関数の入力と戻り値の型を扱うための選択肢がいくつかあります。最も基本的な選択は、System.IO.Streamの低レベルストリームインタフェースを使用することです。また、アプリケーションのアセンブリレベルまたはメソッドレベルでデフォルトのシリアライザを適用することも、Amazon.Lambda.Coreライブラリによって提供されるILambdaSerializerインターフェイスを実装することによって独自のシリアライゼーションロジックを定義することもできます。
ProcessDynamoEvent関数の関数シグネチャを見て、シグネチャ内のDynamoDBEventに注意してください。これは、Lambdaが提供するAmazon.Lambda.Coreライブラリと、他のAWSイベントタイプのためのさらに多くのクラスから来ています。このNuGetパッケージにプロジェクトの依存関係を追加すると、staticなLambdaロガー、シリアライゼーション インターフェイス、およびLambdaコンテキストオブジェクトのC#実装にアクセスできます。
ロギングでは、C#Consoleクラス、Amazon.Lambda.Core.LambdaLoggerクラスのLogメソッド、またはコンテキストオブジェクトのLoggerプロパティによって提供される静的なWriteメソッドまたはWriteLineメソッドを使用できます。 C#プログラミングモデルの詳細については、「AWS Lambda開発者ガイド」を参照してください。
AWS Toolkit for Visual Studio
AWS Toolki for Visual Studio は、.NET Core Lambda関数とサーバーレスアプリケーションの開発、テスト、および展開をサポートします。 このツールキットには、容易に開発を始めるために、次の2つの新しいプロジェクトテンプレートが用意されています: AWS Lambda Projectテンプレートは、単一のC#Lambda関数を持つ単純なプロジェクトを作成します。 AWS Serverlessアプリケーションテンプレートは、AWS Serverless Application Model(AWS SAM)に従って、小さなAWSサーバーレスアプリケーションを作成します。 このテンプレートは、API GatewayのRESTエンドポイントを介して公開された複数のラムダ関数で構成された完全なサーバーレスアプリケーションを開発する方法を示しています。 また、AWS SAMでは、アプリケーションがプロジェクトのテンプレートの一部として使用するAWSリソースをモデル化できます。

コードが準備できたら、プロジェクトを右クリックし、ソリューションエクスプローラで[Publish to AWS Lambda…]を選択してVisual Studioから直接展開できます。 そこから、デプロイメント・ウィザードがデプロイメント・プロセスをガイドします。

.NET Core CLIを使用したクロスプラットフォーム開発
.NET Coreの優れた機能の1つは、クロスプラットフォームのサポートです。 従来の.NETフレームワークでは、開発者はWindows上でアプリケーションを構築して実行する必要があります。 ただし、.NET Coreを使用すると、任意のプラットフォームでC#コードを開発し、任意のプラットフォームに展開することができます。Windowsで開発しておらず、AWS Toolkit for Visual Studioにアクセスできない場合でも、.NETツールを使用してC#Lambda関数とサーバーレスアプリケーションをAWSに簡単に公開できます。 AWS Toolkit for Visual Studioを使用していても、dotnet CLIの使い方を知ることは、ビルドとデプロイメントプロセスの自動化に役立ちます。.NET Coreプロジェクトを作成したら、Yeomanのようなツールを使用してdotnet CLIのLambdaツールを有効にします。 Amazon.Lambda.ToolsのNuGetパッケージに依存するツールを新しいプロジェクトに追加するだけです。

Amazon.Lambda.Tools NuGetパッケージは、新しいdotnet CLIにコマンドを追加します。これにより、使用しているプラットフォームに関係なく、Lambda関数とサーバレスアプリケーションをAWSにデプロイできます。 Windows上のVisual Studioで開発している場合でも、dotnet CLIのAWS Lambdaツールは、アプリケーションのCI / CDパイプラインを設定するのに役立ちます。dotnet CLIの新しいラムダコマンドの詳細については、プロジェクトディレクトリに「dotnet lambda help」と入力してください。

まとめ
我々は、.NET Core ランタイムを通してC#アプリケーションに対してAWS Lambdaを利用可能にすることに興奮しています。 C#Lambda関数の作成に関する詳細は、「AWS Lambda開発者ガイド」を参照してください。 AWS Toolkit for Visual Studioをダウンロードして開始するか、dotnet CLIのLambda拡張を確認してください。
原文: Announcing C# Support for AWS Lambda (翻訳: SA福井)
Lambda@Edge – プレビュー
ちょうど先週、私が Hacker News上で書いたコメントがきっかけでAWSのお客様から興味深いメールを頂きました。
彼はS3上でホストしているシングルページのアプリケーションを動作させていて(こちらについてはAmazon S3で静的なWebサイトの運用が可能に をご覧下さい。)、Amazon CloudFrontを経由して少ないレイテンシーで提供していると教えてくれました。そのページは、AWS Elastic Beanstalk上でホストしているAPIを使って、それぞれのユーザー向けにカスタマイズして表示するいくつかの動的な要素を含みます。
彼が説明してくれた彼の課題はこちらです。
適切に検索エンジンのインデックスを取得するために、またFacebookやTwitterないで正しく表示するためのコンテンツのプレビューをするためには、それぞれのページが事前に表示されたバージョンを提供する必要があります。こちらを実現するには、一般ユーザーがヒットするたびに、私たちのサイトはノーマルのフロントエンドをCloudFrontから提供する必要があります。しかし、もしユーザーエージェントがGoogle / Facebook / Twitter等にマッチする場合は、その代りに私たちは事前に表示されたバージョンへリダイレクトさせる必要があります。
私たちはこのユースケースについてよく分かっており、興味深いソリューションを準備中であることを彼に秘密を漏らすことなく伝えました。他のお客様もまた、エッジにおいてクイックな判定によりカスタマイズしたいと伝えてくれてました。
お客様に近いロケーションでHTTPリクエストを”賢く”処理しなければならないユースケースがあることがわかりました。これらには、HTTPヘッダの検査および変更、アクセスコントロール(特定のcookieを必要とする)、デバイス検出、A/Bテスト、クローラーまたはbotsのための処理または特別な対応、レガシーシステムに適応させるためにユーザーフレンドリーなURLを書き換えるユースケースを含みます。多くのこれらのユースケースは、シンプルなパターンマッチングやルールによって表現可能なユースケースよりも多くの処理や判定を必要とします。
Lambda@Edge
これらのユースケースのサポートを提供するために、私はLambda@Edgeのプレビューをラウンチしています。この新しいLambdaベースの処理モデルにより、ますます増加するAWSエッジロケーションのネットワーク内で動作するJavaScriptコードを書くことが出来ます。
CloudFrontのディストリビューションを通して流れるリクエストやレスポンスを処理する軽量なロジックを書くことができます。4つの異なるイベントに対するレスポンスの中でコードを実行できます。
Viewer リクエスト – あなたのコードは、コンテンツがキャッシュされるか否かに関わらず、あらゆるリクエストにおいて動作します。こちらがシンプルなヘッダ処理用のコードです。
exports.viewer_request_handler = function(event, context) {
var headers = event.Records[0].cf.request.headers;
for (var header in headers) {
headers["X-".concat(header)] = headers[header];
}
context.succeed(event.Records[0].cf.request);
}Origin リクエスト – リクエストされたコンテンツがエッジでキャッシュされていない時に、Originに転送される前にコードを実行します。ヘッダを追加したり、既存のヘッダを編集したり、URLを編集したりすることが可能です。
Viewer レスポンス – キャッシュされているか否かに関わらず、すべてのレスポンスにおいてコードを実行します。Viewerに戻す必要のないヘッダをクリーンアップするためにこちらを利用できます。
Origin レスポンス – キャッシュミスにより Originへコンテンツを取りに行き、エッジへレスポンスを戻した後でコードを実行します。
リクエストやレスポンスに含まれるURLやメソッド、HTTPバージョン、クライアントIPアドレス、ヘッダなどのさまざまな要素へコードからアクセスできます。まず最初にヘッダを追加、削除、そして編集することができるようになる予定です。すぐに、bodyを含むすべての値に対して読み込み/書き込みの完全なアクセスができるようになる予定です。
JavaScriptコードは、リクエスト/レスポンスパスの一部になるでしょう、そしてそれは効率的で、重要で、自己完結型のものでなければなりません。他のWebサービスをコールすることは出来ません、また他のAWSリソースへアクセスできません。128MBメモリ内で動作しなければならず、また50ms以内で完了しなければなりません。
開始するには、新しいLambda function を作成して、あなたのディストリビューションをトリガーとして設定し、新しいエッジランタイムを選択します。
その後で通常通りコードを書きます。Lambdaはエッジロケーションでの舞台裏での処理をしてくれます。
興味深いですか?
このクールな新しい処理モデルはいくつかのとてもクールな新しいアプリケーションや開発ツールの作成を導いてくれると信じています。あなたがこちらを使って何をもたらしてくれるか待ちきれません。
私たちは本日Lambda@Edgeの制限付きのプレビューをラウンチします、そして利用者を募集しています。もしあなたが関連しそうなユースケースをお持ちで、こちらを試す準備が出来れいれば、ぜひこちらにご応募ください。
翻訳は舟崎が担当しました。原文はこちらです。