Category: Amazon EC2
EC2 リザーブドインスタンスの更新 – Convertible RI とリージョン単位の利点
EC2 リザーブドインスタンスはほぼ 8 年前に発表されました。2009 年に開始されたモデルには 2 つの利点があります。キャパシティーの予約と、アベイラビリティーゾーン内の特定のインスタンスの使用に適用される大幅な割引です。長年にわたり、お客様からの意見や要望に基づいてモデルを改良し、スケジュールされたリザーブドインスタンス、リザーブドインスタンスの予約内容の変更機能、リザーブドインスタンスマーケットプレイスでのリザーブドインスタンス (RI) の売買機能などのオプションを追加してきました。今回、リザーブドインスタンスモデルを再び強化することになりました。その内容は以下のとおりです。
リージョン単位の利点 – 多くのお客様から、割引がキャパシティーの予約よりも重要だという意見や、柔軟性が増すなら割引率は下がっても構わないという意見を頂いていました。そこで今回からは、Standard RI に関連付けるキャパシティーは予約されずに、リージョン内のいずれかの AZ で実行したインスタンスに RI の割引が自動的に適用されるように選択可能になりました。
Convertible リザーブドインスタンス – Convertible RI では、柔軟性を増しながらも高い割引 (On-Demand に比べて通常 45% の割引) を受けられます。リザーブドインスタンスに関連付けたインスタンスファミリーやその他のパラメータはいつでも変更できます。たとえば、新しいインスタンスタイプを利用するために C3 RI を C4 RI に変換したり、アプリケーション用にメモリの増量が必要になった場合に C4 RI を M4 RI に変換したりできます。また、EC2 の値下げを徐々に活用するために Convertible RI を使用することもできます。
それでは、詳しく見ていきましょう。
リージョン単位の利点
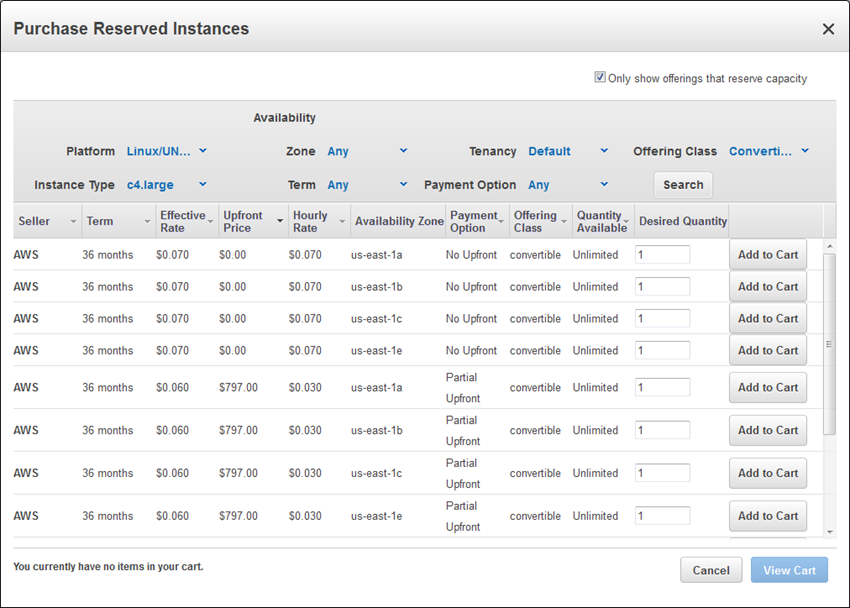
リザーブドインスタンス (Standard または Convertible) がリージョン内のすべてのアベイラビリティーゾーン間で自動的に適用されるように設定可能になりました。リージョン単位の利点により、リージョン内のすべてのアベイラビリティーゾーン間で RI がインスタンスに自動的に適用されることで、RI の割引の適用範囲が広がります。この利点を使用すると、キャパシティーの予約は行われません。代わりに、キャパシティーを予約するためのアベイラビリティーゾーンの選択が必要になります。インスタンスを頻繁に起動、使用、終了する動的な環境では、この新しい利点により、柔軟性が増し、RI を適用する最適なインスタンスの選択にかかる時間が短くなります。Auto Scaling によって起動されて Elastic Load Balancing によって接続されるインスタンスで水平スケーリングされるアーキテクチャでは、この新しい利点が大きな価値をもたらす可能性があります。AWS Management Console で [Purchase Reserved Instances] をクリックした後、[Search] をクリックすると、この新しい利点のある RI が表示されます。
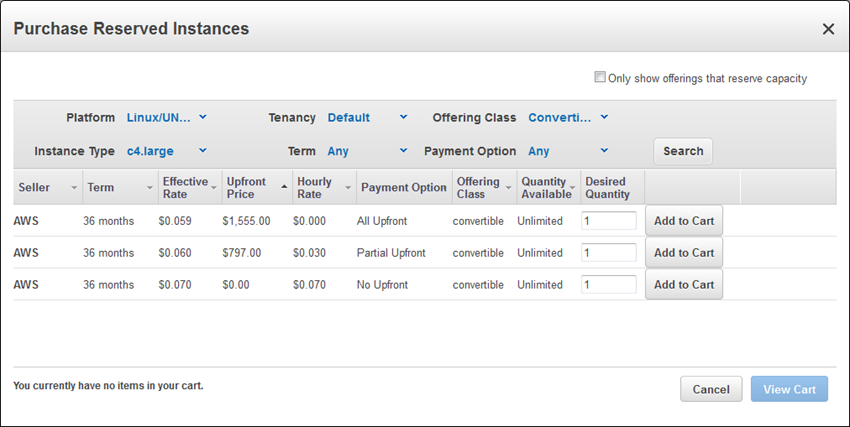
1 つのアベイラビリティーゾーンに適用され、かつキャパシティーが予約される RI を購入する場合は、[Only show offerings that reserve capacity] チェックボックスをオンにできます。
Convertible RI
多くの場合、RI を購入するお客様の目的は、ワークロードに見合った価格で得をすることです。ただし、長期的な要件をまだ把握できない場合に、新しい Convertible RI を利用することもできます。要件が変化した場合は、設定を変更した別の Convertible リザーブドインスタンスに交換するだけで済みます。契約条件をリセットすることなく、新しいインスタンスタイプやオペレーティングシステム、テナントを設定した Convertible RI に交換できます。また、この交換は無料でいつでも可能です。
交換を行うときは、交換元の RI と同等以上の新しい RI を取得する必要があります。場合によっては、差額を支払う必要があります。交換プロセスは各 Convertible RI の定価に基づきます。この価格は交換元の RI の残存期間分の支払い額の合計になります。
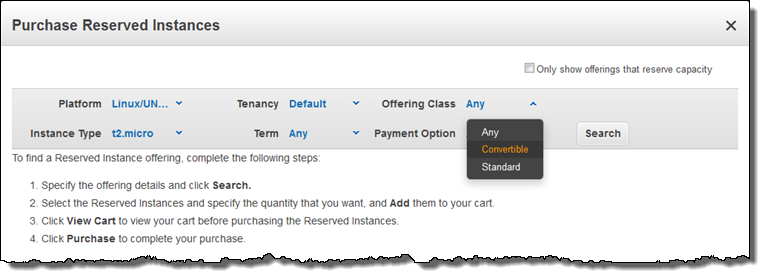
Convertible RI を購入するには、[Search] をクリックする前に、[Offering Class] を [Convertible] に変更してください。
Convertible RI では、キャパシティーが予約されるだけでなく、On-Demand に比べて通常 45% の割引を受けられます。Convertible RI は、3 年契約に基づく現在のすべての EC2 インスタンスタイプに適用できます。3 つのすべての支払いオプション (前払いなし、一部前払い、全額前払い) を使用できます。
今すぐ利用可能
上記の購入と交換のオプションはすべて、AWS Management Console、[CLI]、AWS Tools for Windows PowerShell、または [Reserved Instance APIs] (DescribeReservedInstances、PurchaseReservedInstances、ModifyReservedInstances など) からアクセスできます。
Convertible RI とリージョン単位の利点は、AWS GovCloud (US) と China (Beijing) を除くすべてのパブリック AWS リージョンで使用できます (これらの 2 つのリージョンでも、まもなく使用可能になる予定)。
— Jeff;
Amazon EC2 の新しい P2 インスタンスタイプ – 最大 16 GPU
私は長期に渡る技術やビジネスの動向を見ながら、自ら使用しブログに書くことができる製品やサービスの成り立ちを観察することが好きです。今回のブログを準備している時に、3 つのトレンドが頭に浮かびました。
- ムーアの法則 – 1965 年に予測されたムーアの法則は、半導体のトランジスタ数の集積度は毎年 2 倍になるというものです。
- 大量市場/大量生産 – 人類が生み出しその使用を楽しんでいる技術は大量の半導体を消費しており、大きなマーケットシェアになっています。
- 専門化 – 上記の動向から隙間市場さえ専用製品を取り扱う大規模な市場になることも可能です。
このような動向に合わせて業界が進むに連れ、過去 10 年ほどの間に興味深いチャレンジがいくつか浮上しました。次のリストをご覧ください (箇条書きで考える癖がついていますね)。
- 光の速度 – トランジスタ密度が増加しても、光速にはスケーリングの限界があります (コンピューターの先駆者 Grace Hopper が頻繁に指摘していますが、電気はナノ秒で約 1 フィートの距離を移動することができます)。
- 半導体物理学 – トランジスタのタイム変換 (オンまたはオフ) の基本的限界により CPU が達成可能なサイクル時間の最低値を判断することができます。
- メモリボトルネック – 有名な von Neumann Bottleneck は CPU の追加能力値を制限します。
 GPU (グラフィックスプロセッシングユニット) はこうした動向から生まれたもので、いくつものチャレンジに対応しています。プロセッサがクロック速度の上限に達しても、設計者はムーアの法則でより多くのトランジスタを使用することができます。従来のアーキテクチャに対し、より多くのキャッシュやメモリを追加するためにトランジスタを使用することができますが von Neumann Bottleneck はそれを制限します。逆に、現在では専用ハードウェア (GPU 消費の先駆けとしてはゲームなど) が大きな市場になっています。これらをまとめると、GPU はスケールアップ (プロセッサ速度の上昇やボトルネックメモリ) の代わりにスケールアウト (より多くのプロセッサと平行する蓄積したメモリ) を行っていることが分かります。Net-net: GPU は多くのトランジスタを使用して大量の処理能力を提供する上で効率的な方法です。
GPU (グラフィックスプロセッシングユニット) はこうした動向から生まれたもので、いくつものチャレンジに対応しています。プロセッサがクロック速度の上限に達しても、設計者はムーアの法則でより多くのトランジスタを使用することができます。従来のアーキテクチャに対し、より多くのキャッシュやメモリを追加するためにトランジスタを使用することができますが von Neumann Bottleneck はそれを制限します。逆に、現在では専用ハードウェア (GPU 消費の先駆けとしてはゲームなど) が大きな市場になっています。これらをまとめると、GPU はスケールアップ (プロセッサ速度の上昇やボトルネックメモリ) の代わりにスケールアウト (より多くのプロセッサと平行する蓄積したメモリ) を行っていることが分かります。Net-net: GPU は多くのトランジスタを使用して大量の処理能力を提供する上で効率的な方法です。
こうしたバックグランドを踏まえた上で最新の EC2 インスタンスタイプ、P2 についてご説明します。このインスタンスは大規模な機械学習、詳細な学習、計算流体力学 (CFD)、耐震解析、分子モデリング、ゲノム、金融工学のワークロードに対応できるように設計されています。
新しい P2 インスタンスタイプ
この新しいインスタンスタイプは 8 NVIDIA Tesla K80 アクセラレーター まで組み込むことが可能です。それぞれ NVIDIA GK210 GPU ペアを実行します。各 GPU はそれぞれ 12 GB のメモリ (メモリ帯域幅 240 GB/秒 経由でアクセス可能) と、2,496 の並列処理コアを提供します。ECC メモリ保護も含んでいるため、シングルビットエラーの修正とダブルビットエラーの検出を可能にします。ECC メモリ保護と倍精度の浮動操作の組み合わせにより、こうしたインスタンスは上記のワークロードすべてにおいて最適です。
インスタンスのスペックは次をご覧ください。
| インスタンス名 | GPU カウント | vCPU カウント
|
メモリ | 並列処理コア
|
GPU メモリ
|
ネットワークパフォーマンス
|
| p2.xlarge | 1 | 4 | 61 GiB | 2,496 | 12 GB | 高 |
| p2.8xlarge | 8 | 32 | 488 GiB | 19,968 | 96 GB | 10 ギガビット |
| p2.16xlarge | 16 | 64 | 732 GiB | 39,936 | 192 GB | 20 ギガビット |
インスタンスはすべて 2.7 GHz で実行している Intel の Broadwell プロセッサで AWS 固有バージョンを使用しています。p2.16xlarge は C ステートと P ステートのコントロールを可能にするほか、1 コアまたは 2 コアで実行している場合に 3.0 GHz まで高速化することができます。
GPU は CUDA 7.5 とそれ以降では OpenCL 1.2 と GPU コンピューティング API をサポートします。p2.8xlarge と p2.16xlarge の GPU は一般的な PCI fabric 経由で接続します。これにより低レイテンシーのピアツーピア GPU から GPU 転送を可能にします。
インスタンスはすべて新しい Enhanced Network Adapter を使用します (ENA – 詳しくは「Elastic Network Adapter – Amazon EC2 のハイパフォーマンスネットワークインターフェイス」をご覧ください)。また、上記の表のようにプレイスメントグループ内で使用した場合は低レイテンシーで 20 Gbps までサポートすることができます。
単一インスタンスでパワフルなマルチ vCPU プロセッサと適切に連携している複数の GPU と、同じ機能を持つ別のインスタンスへの低レイテンシーアクセスがあれば、スケールアウト処理で非常に優れた階層を作成することができます。
- One vCPU
- マルチ vCPU
- 1 個の GPU
- 単一インスタンスでマルチ GPU
- プレイスメントグループ内の複数のインスタンスでマルチ GPU
P2 インスタンスは VPC のみを対象にしており、64 ビット、HVM スタイル、EBS-backed AMI を使用する必要があります。この機能は US East (Northern Virginia)、US West (Oregon)、Europe (Ireland) リージョンにてオンデマンドインスタンス、スポットインスタンス、リザーブドインスタンス、専用ホストとして今日からご利用いただけます。下記は私が P2 インスタンスで NVIDIA ドライバと CUDA ツールキットをインストールした時の例です。その前に CUDA ツールキットに十分な余裕があった EBS ボリューム ( /ebs) と関連のサンプルで作成、フォーマット、アタッチ、マウントしてから実行しました (10 GiB あれば十分です)。
$ cd /ebs
$ sudo yum update -y
$ sudo yum groupinstall -y "Development tools"
$ sudo yum install -y kernel-devel-`uname -r`
$ wget http://us.download.nvidia.com/XFree86/Linux-x86_64/352.99/NVIDIA-Linux-x86_64-352.99.run
$ wget http://developer.download.nvidia.com/compute/cuda/7.5/Prod/local_installers/cuda_7.5.18_linux.run
$ chmod +x NVIDIA-Linux-x86_64-352.99.run
$ sudo ./NVIDIA-Linux-x86_64-352.99.run
$ chmod +x cuda_7.5.18_linux.run
$ sudo ./cuda_7.5.18_linux.run # Don't install driver, just install CUDA and sample
$ sudo nvidia-smi -pm 1
$ sudo nvidia-smi -acp 0
$ sudo nvidia-smi --auto-boost-permission=0
$ sudo nvidia-smi -ac 2505,875
以下の点に注意してください。 NVIDIA-Linux-x86_64-352.99.run と cuda_7.5.18_linux.run はインタラクティブプロジェクトです。ライセンス契約に同意しオプションをいくつか選択してパスを入力する必要があります。私が設定した CUDA ツールキットと実行時のサンプルは次の通りです。 cuda_7.5.18_linux.run:
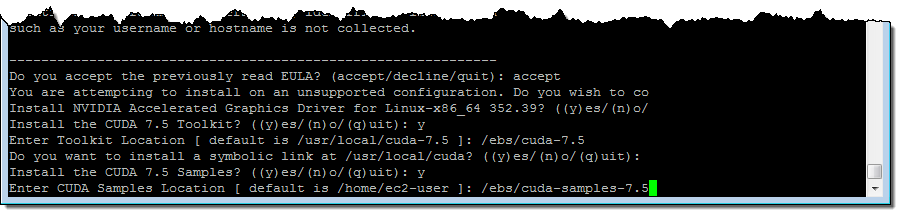
P2 と OpenCL の一例
設定をすべて完了してから、この Gist を p2.8xlarge インスタンスにコンパイルしました。
[ec2-user@ip-10-0-0-242 ~]$ gcc test.c -I /usr/local/cuda/include/ -L /usr/local/cuda-7.5/lib64/ -lOpenCL -o testレポートは次の通りです。
[ec2-user@ip-10-0-0-242 ~]$ ./test
1. Device: Tesla K80
1.1 Hardware version: OpenCL 1.2 CUDA
1.2 Software version: 352.99
1.3 OpenCL C version: OpenCL C 1.2
1.4 Parallel compute units: 13
2. Device: Tesla K80
2.1 Hardware version: OpenCL 1.2 CUDA
2.2 Software version: 352.99
2.3 OpenCL C version: OpenCL C 1.2
2.4 Parallel compute units: 13
3. Device: Tesla K80
3.1 Hardware version: OpenCL 1.2 CUDA
3.2 Software version: 352.99
3.3 OpenCL C version: OpenCL C 1.2
3.4 Parallel compute units: 13
4. Device: Tesla K80
4.1 Hardware version: OpenCL 1.2 CUDA
4.2 Software version: 352.99
4.3 OpenCL C version: OpenCL C 1.2
4.4 Parallel compute units: 13
5. Device: Tesla K80
5.1 Hardware version: OpenCL 1.2 CUDA
5.2 Software version: 352.99
5.3 OpenCL C version: OpenCL C 1.2
5.4 Parallel compute units: 13
6. Device: Tesla K80
6.1 Hardware version: OpenCL 1.2 CUDA
6.2 Software version: 352.99
6.3 OpenCL C version: OpenCL C 1.2
6.4 Parallel compute units: 13
7. Device: Tesla K80
7.1 Hardware version: OpenCL 1.2 CUDA
7.2 Software version: 352.99
7.3 OpenCL C version: OpenCL C 1.2
7.4 Parallel compute units: 13
8. Device: Tesla K80
8.1 Hardware version: OpenCL 1.2 CUDA
8.2 Software version: 352.99
8.3 OpenCL C version: OpenCL C 1.2
8.4 Parallel compute units: 13
ご覧のように、すぐに使用できる勝利能力が膨大にあることが分かりました。
AMI の新たな詳細学習
このブログの冒頭で触れましたが、こうしたインスタンスは機械学習、詳細な学習、計算流体力学 (CFD)、構造計算、分子モデリング、ゲノム、金融工学のワークロードに最適です。
1 つ以上の P2 インスタンスの活用を可能にするため、本日 AMI の詳細学習 をリリースしました。詳細学習は、もっとも複雑でより大量な計算トレーニングプロセスを要するレベルの低い機械学習の予測に比べ、より信頼性が高い予測 (スコアまたは障害性) を生成できる可能性を備えています。幸い、新世代の詳細学習ツールは単一インスタンスにおける複数の GPU や複数の GPU を含む複数のインスタンスに渡り、トレーニングワークを分散させることができます。
新しい AMI には次のフレームワークが含まれています。いずれもインストールおよび設定済みで人気の MNIST データベースに対してテストも行われています。
MXNet – 柔軟性に優れ移動可能、詳細学習において効率的なライブラリです。C++、Python、R、Scala、Julia、Matlab、JavaScript を含む幅広いプログラミング言語に渡り宣言型プログラミングや命令型プログラミングをサポートします。
Caffe – 発現、速度、モジュール性を念頭に設計された詳細学習のフレームワークです。Berkeley Vision and Learning Center (BVLC) と様々なコミュニティの協力者により開発されました。
Theano – この Python ライブラリは多次元配列に関与する数式を定義、最適化、評価します。
TensorFlow™ – データフローグラフ (グラフの各ノードが算術演算で、各エッジは多次元データ間の通信を表示) を使用した数値計算のオープンソースライブラリです。
Torch – 機械学習アルゴリズムのサポートを備えた GPU 指向の科学計算フレームワークです。すべて LuaJIT 経由でアクセスすることができます。
次の README ファイル ( ~ec2-user/src ) でフレームワークの詳細をご覧ください。
AMIs from NVIDIA
興味があれば次の AMI も合わせてご覧ください。
- NVIDIA ドライバ使用の Windows Server 2012
- Amazon Linux の NVIDIA CUDA ツールキット 7.5
- Ubuntu 14.04 の NVIDIA DIGITS 4
— Jeff;
M4 インスタンスタイプの拡張 – 新しい M4.16xlarge
EC2 の M4 インスタンスはバランスの良いコンピューティング、メモリ、ネットワーキングリソースを提供し、様々なタイプのアプリケーションに適しています。
AWS は M4 インスタンスを去年リリースし (過去のブログを参照)、large から 10xlarge まで 5 つのサイズをご提供しました。そして本日、64 vCPU と 256 GiB の RAM を使用する m4.16xlarge をリリースしました。仕様情報については次をご覧ください。
| インスタンス名 | vCPU カウント
|
RAM
|
インスタンスストレージ | ネットワークパフォーマンス | EBS 最適化 |
| m4.large | 2 | 8 GiB | EBS のみ | 中 | 450 Mbps |
| m4.xlarge | 4 | 16 GiB | EBS のみ | 高 | 750 Mbps |
| m4.2xlarge | 8 | 32 GiB | EBS のみ | 高 | 1,000 Mbps |
| m4.4xlarge | 16 | 64 GiB | EBS のみ | 高 | 2,000 Mbps |
| m4.10xlarge | 40 | 160 GiB | EBS のみ | 10 Gbps | 4,000 Mbps |
| m4.16xlarge | 64 | 256 GiB | EBS のみ | 20 Gbps | 10,000 Mbps |
新しいインスタンスは Intel Xeon E5-2686 v4 (Broadwell) プロセッサをベースにし EC2 専用に最適化されています。プレイスメントグループ内の Elastic Network Adapter (ENA) と使用した場合、インスタンスは低レイテンシーのネットワーク帯域幅で最大 20 Gbps まで実現することができます。ENA の詳細については過去のブログ「Elastic Network Adapter – Amazon EC2 のハイパフォーマンスネットワークインターフェイス」をご覧ください。
m4.10xlarge のように m4.x16large でも C ステートをコントロールして複数のコアを使用する場合に高度のターボ周波数を有効にすることができます。P ステートをコントロールしてパフォーマンスの変動性を低下させることができます (こうした機能の詳細については過去のブログ「新しい C4 インスタンス」をご覧ください)。
オンデマンドインスタンスとリザーブドインスタンスを購入することができます。詳しくは EC2 料金表ページをご覧ください。
今すぐ利用可能
本日のリリースに伴い China (Beijing)、South America (Brazil)、AWS GovCloud (US) リージョンで M4 インスタンスが利用可能になりました。
— Jeff;
Amazon Linux AMI 2016.09 の紹介
同僚の Sean Kelly は Amazon Linux AMI チームに所属しています。今回のゲスト投稿では彼が最新バージョンについてご紹介します。
— Jeff;
 Amazon Linux AMI は Amazon EC2 で使用するために保守管理している Linux イメージです。
Amazon Linux AMI は Amazon EC2 で使用するために保守管理している Linux イメージです。
Amazon Linux AMI の新しいメジャーバージョンは、1 つ以上のリリース候補を含む公開テスト段階を完了した後に提供します。リリース候補は EC2 フォーラムで告知します。皆様からのフィードバックをお待ちしています。
2016.09 のリリース
AWS は本日、全リージョンと現行世代の EC2 インスタンスタイプすべてに対応する 2016.09 Amazon Linux AMI をリリースしました。Amazon Linux AMI は HVM モードと PV モードの他に、EBS-backed と Instance Store-backed の AMI もサポートします。
この新しいバージョンの AMI はいつもの方法で起動できます。次のコマンドを実行して既存の EC2 インスタンスをアップグレードすることもできます。
$ sudo yum clean all
$ sudo yum update次にインスタンスを再起動します。
新機能
Amazon Linux AMI のロードマップにはお客様からのリクエストを大いに反映させています。お客様からのリクエストに応え、そして既存の機能一式を最新状態で維持するため、今回のリリースには多数の機能を追加しました。
Nginx 1.10 – 多くのお客様から頂いたリクエストをもとに、Amazon Linux AMI 2016.09 リポジトリには最新で安定性を備えた Nginx 1.10 リリースを含んでいます。最新バージョンをインストールまたはアップグレードするには次のコードを使用してください。 sudo yum install nginx。
PostgreSQL 9.5 – 多数のお客様から PostgreSQL 9.5 のリクエストを頂きました。今後は、この他にご提供している PostgreSQL とは別のパッケージとしてご利用いただけるようになりました。PostgreSQL 9.5 を入手するには次のコードを使用してください。 sudo yum install postgresql95。
Python 3.5 – Python 3.5 は Python 3.x シリーズの最新バージョンで、既存の Python エクスペリエンスと統合されています。Amazon Linux AMI リポジトリから入手可能です。これは依存関係のインストールや管理に使用できる関連の virtualenv と pip パッケージを含みます。/usr/bin/python のデフォルトの Python バージョンは、既存の Python パッケージと同様に他の手段で管理することもできます。Python 3.5 と関連の pip や virtualenv パッケージをインストールするには、次のコードを使用してください。 sudo yum install python35 python35-virtualenv python35-pip。
Amazon SSM Agent – Amazon SSM エージェントでは Run Command を使用して EC2 インスタンスで設定したりスクリプトを実行することができます。Amazon Linux 2016.09 リポジトリで入手可能です (詳しくは「インスタンスをリモートで管理する」をご覧ください)。エージェントをインストールするには次のコマンドを実行します。 sudo yum install amazon-ssm-agent 次で開始します。 sudo /sbin/start amazon-ssm-agent。
詳細
Amazon Linux AMI のすべての新機能に関する詳細はリリースノートをご覧ください。
— Sean Kelly、Amazon Linux AMI チーム
PS – Amazon Linux AMI チームで働くことに興味がある方は Linux キャリア採用ページをご覧ください。
新機能 – EC2 スポットフリートの Auto Scaling
EC2 スポットフリートモデル(詳しくは「Amazon EC2 スポットフリート API – 1 回のリクエストで数千台のスポットインスタンスを制御」をご覧ください)では、1 回のリクエストで EC2 インスタンスのフリートを作成できます。お客様はフリートのターゲットキャパシティーを指定し、1 時間あたりの入札価格を入力して、フリートに含めるインスタンスタイプを選択するだけです。
バックグランドで、AWS は最安値のスポットインスタンスを起動することにより、必要なターゲットキャパシティー(インスタンスまたは仮想 vCPU の数で表記)を維持します。やがて、フリート内のインスタンスが価格上昇により終了されると、その時点で最安値の交換用のインスタンスが起動されます。
新しい Auto Scaling
今回、Auto Scaling の追加により、スポットフリートモデルが強化されました。Amazon CloudWatch メトリックスに基づいて、フリートをスケールアップ/ダウンできるようになりました。メトリックスには、EC2、Amazon EC2 Container Service、Amazon Simple Queue Service (SQS) などの AWS サービスのものを使用できます。代わりに、アプリケーションからパブリッシュしたカスタムメトリックスを使用して、Auto Scaling が開始されるようにもできます。いずれにせよ、これらのメトリックスを使用してフリートのサイズを制御することで、条件や負荷が変わったとしてもアプリケーションの可用性、パフォーマンス、コストをきめ細かく制御できます。以下に示しているのは、この機能の使用開始に必要ないくつかの概念です。
- コンテナ – CPU やメモリの使用率メトリックスを使用して、Amazon ECS で動作しているコンテナベースのアプリケーションをスケーリングします。
- バッチジョブ – SQS キュー内のメッセージ数に基づいて、キューベースのバッチジョブをスケーリングします。
- スポットフリート – スポットフリートメトリックス(
MaxPercentCapacityAllocation など)に基づいて、フリートをスケーリングします。 - ウェブサービス – 測定された応答時間と 1 秒あたりの平均リクエスト数に基づいて、ウェブサービスをスケーリングします。
スポットフリートコンソール、AWS Command Line Interface (CLI)、または AWS CloudFormation を使用するか、AWS SDKs のいずれかにより API 呼び出しを行うことで、Auto Scaling を設定できます。
私はフリートの起動から始めました。フリートをスケールアップ/ダウンできるようにするために、リクエストタイプとして [Request and Maintain] を使用しました。
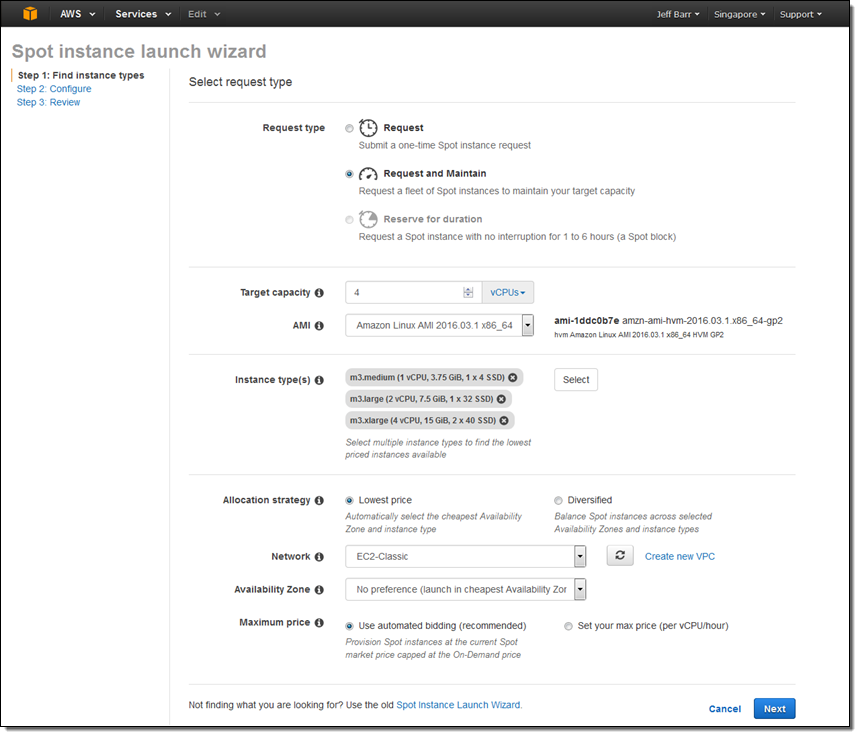
フリートは 1 分ほどで稼働状態になりました。
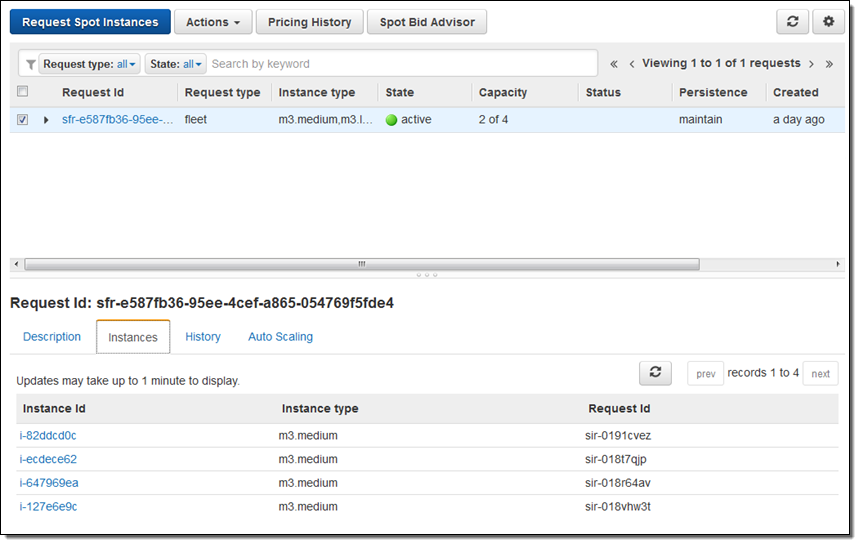
続いて、例示用に SQS キューを作成し、いくつかのメッセージをそのキューに入れて、CloudWatch アラーム(AppQueueBackingUp)を定義しました。このアラームは、キューに 10 件以上のメッセージが入ると起動されます。
また、アラーム(AppQueueNearlyEmpty)も定義しました。このアラームは、キューが空になりそう(メッセージが 2 件以下)になると起動されます。
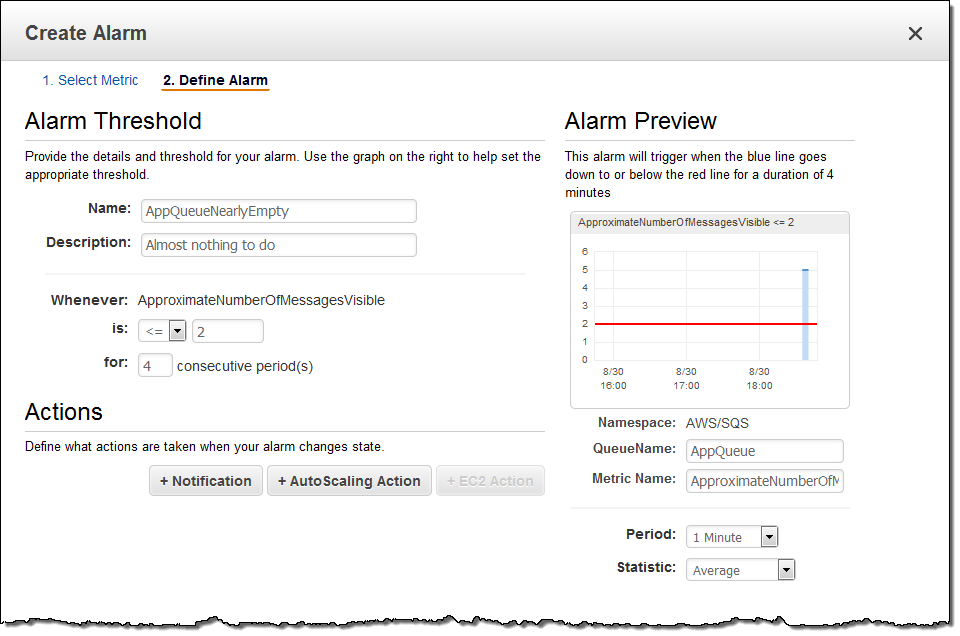
最後に、このアラームをフリートの ScaleUp と ScaleDown のポリシーにアタッチしました。
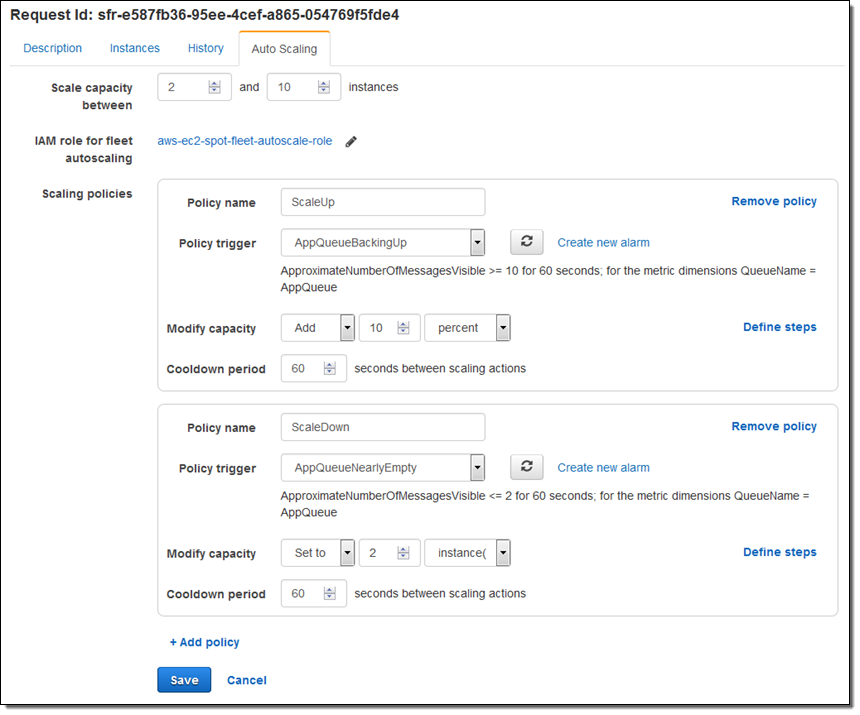
この記事を書き始める前に、SQS キューに 5 件のメッセージを入れました。フリートを起動して、スケーリングポリシーを設定してから、さらに 5 件のメッセージを追加して、アラームが起動されるのを待ちました。
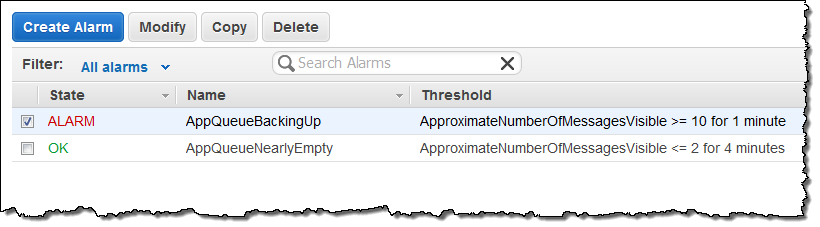
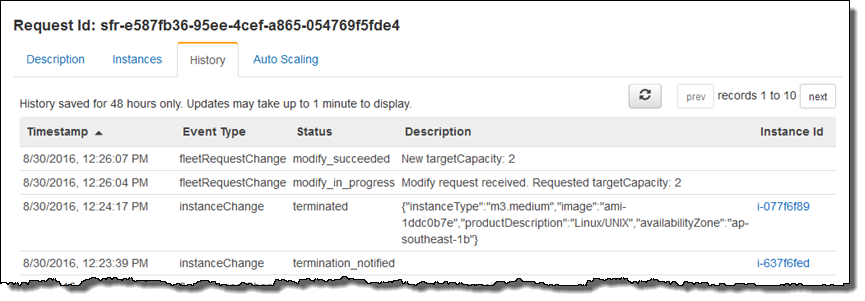
その後、フリートにチェックインすると、キャパシティーが想定どおりに増加したことがわかりました。この結果は [History] タブに表示されました("New targetCapacity: 5")。
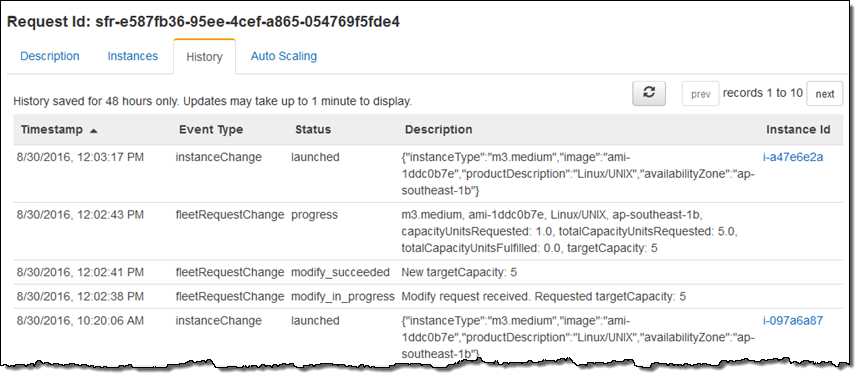
仕上げとして、キューからすべてのメッセージを消去し、植物の水やりをして戻ると、フリートが想定どおりスケールダウンされたことがわかりました("New targetCapacity: 2")。
今すぐ利用可能
この新機能は、スポットインスタンスがサポートされているすべてのリージョンで、今すぐ利用し始めることができます。
— Jeff;
新発表 – X1インスタンスのクラスタによるSAP HANAの稼働
SAP HANAの大規模ワークロードにおける新しい利用方法をお伝えするために、私の同僚のSteven Jonesが寄稿してくれました。
— Jeff;
AWSクラウド上でSAP HANAのような大規模なインメモリデータベースやインメモリアプリケーションを稼働させるため、Amazon EC2 メモリ最適化インスタンスファミリーに新しいX1インスタンスタイプとして、2TBのRAMを搭載したx1.32xlargeの利用開始を5月に発表しました。
X1インスタンスのシングルノード構成でのSAP HANAにおけるSAP認定取得を同時に発表し、それ以来、SAP S/4HANAとSuite on HANAといったOLTP、またBusiness Warehouse on HANAにBIといったOLAPにおける幅広い用途で、世界中の多くのお客様にご利用いただいています。とはいえ、クラスタ化されたX1インスタンスによるスケールアウト構成でのSAP HANAの提供のご要望も多くいただいていました。
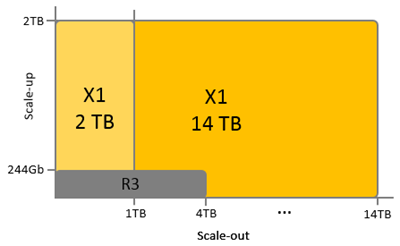 SAP認定プロセスに応じたSAP HANAスケールアウト構成の広範囲なテストとベンチマークを終え、本日、高度に最適化された次世代データウェアハウスSAP BW/4HANAの新発表と同時に、X1インスタンスの最大7ノード、つまり14TBのRAMに対応したSAP BW/4HANAを含むOLAPシナリオの大規模スケールアウト構成におけるSAP認定取得を発表できることを嬉しく思います。 拡張性、柔軟性、コスト効果の高いSAP社の新しいフラッグシップのデータウェアハウスであるSAP BW/4HANAのローンチを私たちがサポートできることに非常に興奮しています。
SAP認定プロセスに応じたSAP HANAスケールアウト構成の広範囲なテストとベンチマークを終え、本日、高度に最適化された次世代データウェアハウスSAP BW/4HANAの新発表と同時に、X1インスタンスの最大7ノード、つまり14TBのRAMに対応したSAP BW/4HANAを含むOLAPシナリオの大規模スケールアウト構成におけるSAP認定取得を発表できることを嬉しく思います。 拡張性、柔軟性、コスト効果の高いSAP社の新しいフラッグシップのデータウェアハウスであるSAP BW/4HANAのローンチを私たちがサポートできることに非常に興奮しています。
以下は7台のX1インスタンスで稼働する大規模(14TBメモリ)なスケールアウト構成を表示したSAP HANA Studioのスクリーンショットです:
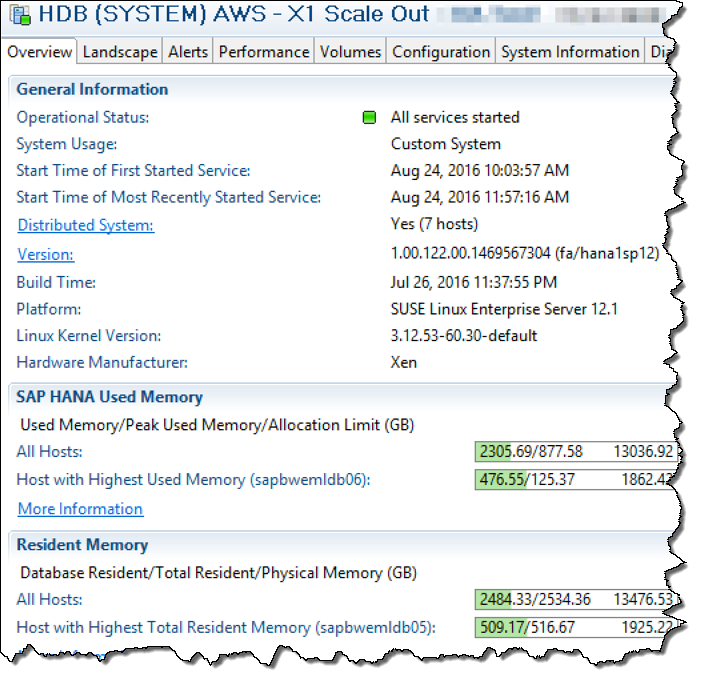
そして、これはほんの始まりに過ぎません。私たちは他のサイズでのX1インスタンスを利用可能にする計画があり、より大きな50TBメモリまでのクラスタ構成を研究室でテストしています。もし、14TBメモリを超える大規模なスケールアウト構成が必要な場合は、ご支援しますので、ぜひご相談ください。
コストと複雑性の削減
多くのお客様が複数のR3インスタンスによるスケールアウト構成でSAP HANAを稼働してきました。今回の新しい認定により、コストと複雑性の両方が削減できる、より少ないインスタンス数での大規模スケールアウト構成に統合できる可能性があります。統合戦略における詳細はSAP HANA Migration Guideをご参照ください。
柔軟性のある高可用性オプション
AWSプラットフォームでは、可用性が求められるSAP S/4HANAやSAP BW/4HANAのような環境で使われる重要なSAP HANAを保護するために、お客様のご要望に応じた様々なオプションを提供しています。実際に、従来型のホスティングプロバイダーやオンプレミスのスケールアウト構成でSAP HANAを稼働しているお客様からは、ハードウェア障害に迅速に対応できるように予備のハードウェアやスタンバイノードを購入し非常に高額なメンテナンス契約料を支払わなければならない、とよくお伺いします。他には、残念ながら、何も起こりませんようにと祈って、この余分なハードウェアをなしで済ませようとされています。
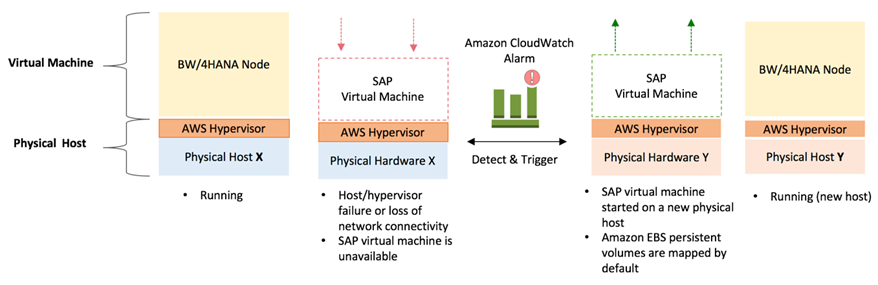
AWSプラットフォーム上で活用されている便利なオプションの一つは、Amazon EC2 Auto Recoveryと呼ばれるソリューションです。AWSに起因するハードウェア障害や問題が発生したときに自動的に正常なホスト上で復旧するよう、EC2インスタンスを監視するAmazon CloudWatch アラームを簡単に作成できます。復旧されたインスタンスは、アタッチされたEBSボリュームやホスト名、IPアドレス、AWSインスタンスIDなどの構成情報も元のインスタンスと同じものです。Amazon CloudWatchの標準料金(例えば、米国東部では月当たりアラームごとに0.10ドル)が適用されます。実質、ハードウェア異常への迅速な復旧のために、私たちの持つ空いているキャパシティをすべてお客様の予備機として活用することが可能です。
開始方法
最新のAWS Quick Start Reference Deployment for SAP HANAを使うことで、十分にテストされたX1インスタンスでのシングルノード構成、およびスケールアウト構成のSAP HANAの本稼働環境を1時間もかからずにご利用いただけます。
Amazon Web Services上でのSAP HANAの導入を計画される際には、ベストプラクティスとガイダンスとしてSAP HANA Implementation and Operations Guide もご確認ください。
AWSとSAPのエキサイティングな共同発表に立ち合いに、9月7日にベイエリアにいらっしゃいませんか?ここから登録いただき、サンフランシスコでお会いしましょう!
来られないでしょうか?SAPをご利用のお客様にAWSとSAP社が共同でご提供する価値を知っていただくためにも、太平洋標準時で9月7日朝7時から9時のライブストリーミングにご参加ください。
皆様のご参加をお待ちしております。
— Steven Jones, Senior Manager, AWS Solutions Architecture
翻訳はPartner SA 河原が担当しました。原文はこちらです。
EC2 Run Command のアップデート – 通知を使用したコマンド実行の監視
AWS が昨年末に EC2 Run Command を立ち上げてから、クラウドやオンプレミス環境で同機能をご利用されているお客様の様子を目にすることができ大変喜ばしく思っています。本機能のリリース直後には Linux インスタンスのサポート、コマンドの管理と共有をよりパワフルに、そしてハイブリッドとクロスクラウド管理を追加しました。そして本日より、中国(北京) と アジアパシフィック (ソウル) リージョンで EC2 Run Command をご利用いただけるようになりました。AWS のお客様は、定期的に行うシステム管理タスクを自動化したりカプセル化するために EC2 Run Command を使用しています。ローカルユーザーやグループの作成、該当の Windows アップデートの検索とインストール、サービス管理やログファイルのチェックなどを行っています。こうしたお客様は EC2 Run Command を基本的な構成要素として使用しているため、実際に実行するコマンドの進行状況をより把握しやすいように可視性の改善を求めています。また、各コマンドや各コードブロック実行の開始時、コマンド実行の完了時、そしてどのように完了したのかといった詳細情報を素早く取得できることを希望されています。このように非常に重要なユースケースに対応するため、コマンド内のコマンドやコードブロックで変更があった場合にステータス状況を通知できるようにしました。さらに、複数の異なる統合オプションを提供するにあたり、CloudWatch Events または SNS を通じて通知を受信できるようにしました。こうした通知により、EC2 Run Command を基本的な構成要素として使用できるようになります。コマンドをプログラムで呼び出し、結果が戻り次第プロセスを進めることができます。例えば、各インスタンスで重要なシステムファイルやメトリックスのコンテンツをキャプチャするコマンドを作成し実行することができます。コマンドが実行すると EC2 Run Command は S3 で出力を保存します。通知ハンドラーは S3 からオブジェクトを取得し、該当アイテムまたは確認が必要なアイテムをスキャンしてから不適切だと思われる点があれば通知を作成します。
Amazon SNS を使用して実行するコマンドをモニタリング
EC2 インスタンスでコマンドを実行し SNS を使用して進行状況を監視してみましょう。手順 (モニタリングコマンド) に従い、S3 バケット (jbarr-run-output)、SNS トピック (command-status)、オンインスタンスエージェントが代理で通知を送信できるようにする IAM ロール (RunCommandNotifySNS) を作成しました。SNS トピックに自分のメールアドレスを追加し、コマンドを入力しました。

次にバケット、トピック、ロール (Run a command ページの下方にあります) を特定しました。
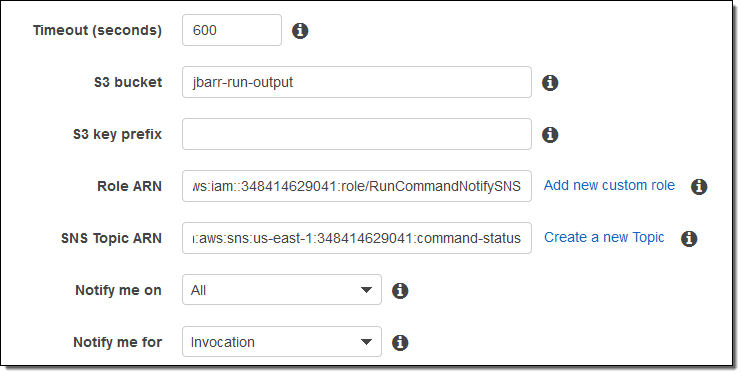
すべてのステータス変更 (進行状況、成功、タイムアウト、キャンセル、失敗など) の通知を受信できるようにすべてを選択しました。各インスタンスのステータスに関する通知も届くように呼び出しも選択しました。呼び出しの代わりにコマンドを選択してコマンドレベルで通知を受信する方法もあります。実行をクリックしたら、選択した各インスタンスでコマンドが実行され次第、一連のメールが届きました。サンプルは次をご覧ください。
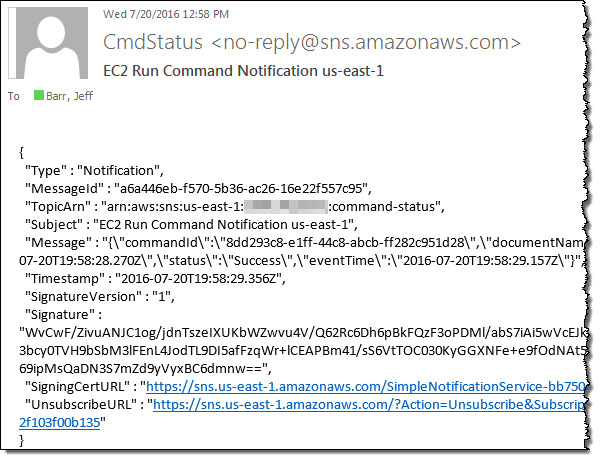
実際の環境では、通知の受信とプロセスはプログラムで行います。
CloudWatch Events を使用して実行するコマンドをモニタリング
CloudWatch Events を使用してコマンド実行を監視することもできます。SQS キューの AWS Lambda 関数もしくは AWS Kinesis ストリームに通知を送信することもできます。分かりやすく説明するため、この例では非常にシンプルな Lambda 関数を使用しました。
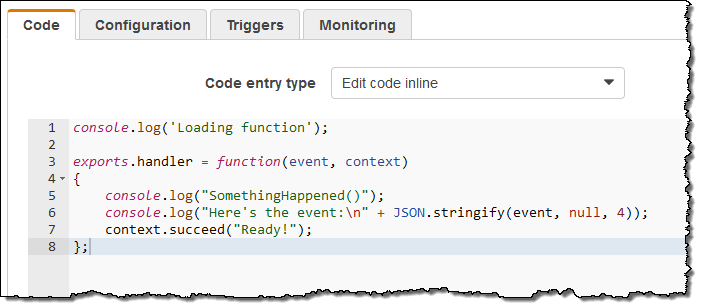
Run Command が発行するすべての通知の関数すべてを呼び出すルールを作成しました (下記を見ればお分かりのように必要に応じてさらに具体的なものにすることもできます)。
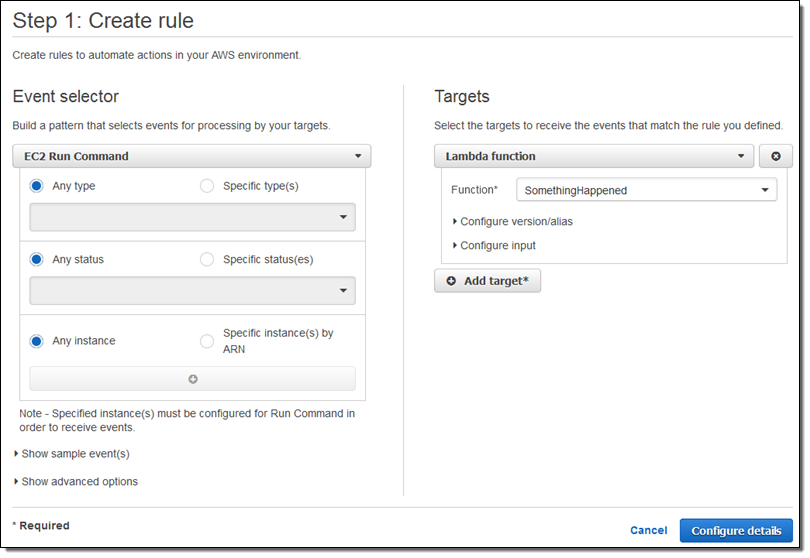
ルールを保存してから別のコマンドを実行し、数秒後に CloudWatch のメトリックスを確認しました。
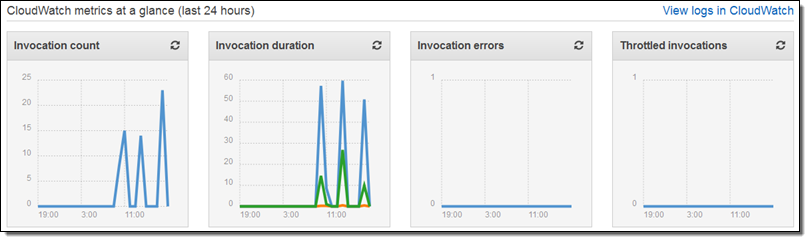
CloudWatch のログも確認しコードの出力も検査しました。
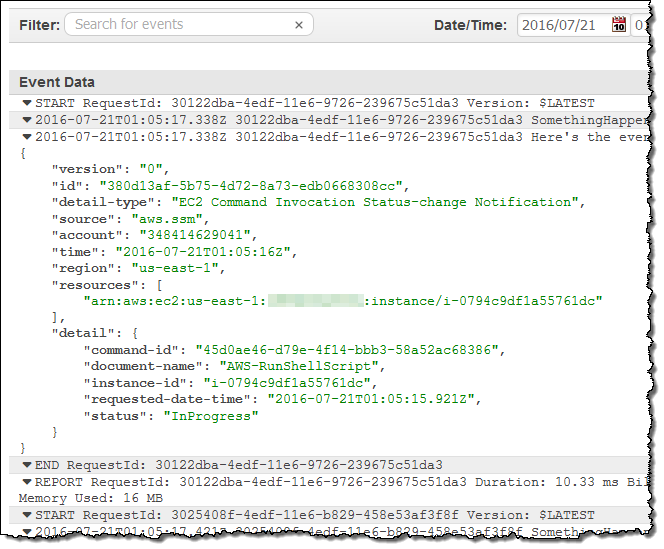
今すぐご利用いただけます
この機能は本日よりご利用可能になりました。SNS を使用したモニタリングは アジアパシフィック (ムンバイ) と AWS GovCloud (US) を除くすべての AWS リージョンでお使いいただけます。CloudWach Events からのモニタリングは アジアパシフィック (ムンバイ)、中国(北京)、AWS GovCloud (US) を除くすべての AWS リージョンでご利用いただけます。
— Jeff
Elastic Network Adapter – Amazon EC2 向けの高性能パフォーマンスネットワークインターフェイス
AWS をご利用されているお客様の多くは、複数の EC2 インスタンスに渡り密結合のシステムを作成し、利用可能なすべてのネットワーク帯域幅を有効に活用されています。本日、AWS はこの非常に一般的なユースケースを対象に、今まで以上に優れたサポートを提供する Elastic Network Adapter (ENA) をリリース致しました。新しい X1 インスタンスタイプを対象とする ENA には追加費用もなく、プレイスメントグループ内で使用した場合、低レイテンシーで安定したパフォーマンスを最大 20 Gbps でご提供します。ENA のメリット
ENA は X1 インスタンスで見られる最新のプロセッサと合わせて運用できるように設計されています。こうしたプロセッサは多数の仮想 CPU (X1 の場合は 128) を含むため、ネットワークアダプターなどの共有リソースを効率的に使用することが重要です。高いスループットやパケット毎秒 (PPS) のパフォーマンスを提供しながら、ENA は数々の方法でホストプロセッサのロードを最小限に抑えます。以下の例をご覧ください。
- チェックサム生成 – ENA はハードウェアの IPv4 ヘッダーチェックサム生成と TCP / UDP の一部のチェックサム生成を処理します。
- マルチキューデバイスインターフェイス – ENA は複数の配信を使用し、キューを受信して内部のオーバーヘッドを削減します。
- 受信側による実行 – ENA は適切な vCPU が処理するように着信パケットを誘導します。これにより障害を回避しキャッシュの有効性を高めることができます。
こうした機能は可能な限りプロセッサのワークロードを軽くし、ネットワークパケットと生成または処理を行う vCPU 間で短く効率的なパスを作成するために構築されています。ENA の使用
X1 インスタンス間で 20 Gbps のパフォーマンスを実現するには、プレイスメントグループから起動してください。ENA のその他のメリットは、低レイテンシーや安定したパフォーマンスをインターネットやプレイスメントグループ外からの通信においても提供することです。新しい ENA ドライバは最新の Amazon Linux AMI でご利用いただけます。また、近日中に Windows AMI にも対応する予定です。お客様自身の AMI での利用につき、ソースフォーム (Linux および Windows) でもご使用いただけます。ドライバは Intel の Data Plane Developer Kit (DPDK) を使用してパケットプロセスのパフォーマンスやスループットを高めます。ご自分で AMI を作成される場合は、 enaSupport の属性を設定してください。 コマンドラインからの作成については次をご覧ください。
$ aws ec2 modify-instance-attribute --instance-id INSTANCE_ID --ena-support trueENA をサポートしていないインスタンスで AMI を使用することもできます。今後のプラン
上記の通り、現在 ENA は X1 でご利用いただけます。今後 EC2 インスタンスタイプでも使用可能になる予定です。
EC2インスタンスのコンソールスクリーンショット
ユーザーがAmazon EC2を使用するために既存のマシンイメージをクラウドに移行するとき、ドライバや起動パラメータ、システム構成、そして進行中のソフトウェアアップデートなどによる問題に出くわすことがあります。これらの問題によってインスタンスにRDP(Windowsの場合)やSSH(Linuxの場合)経由で接続できなくなり問題判別を難しくします。従来のシステムでは、物理コンソールでログメッセージや何が起きているのかを特定して理解するための手がかりが見つかることがあります。
インスタンスの状態をより可視化しやすくするために、インスタンスコンソールのスクリーンショットを生成してキャプチャできる機能を提供します。インスタンスが稼働中またはクラッシュした後にスクリーンショットを生成することができます。
こちらがコンソールからスクリーンショットを生成する方法です(インスタンスはHVM仮想化を使用している必要があります):
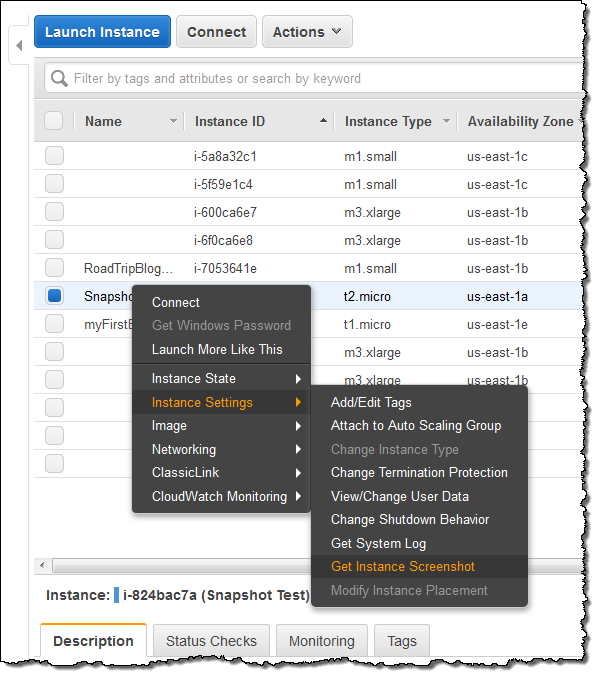
そしてこちらがその結果です:
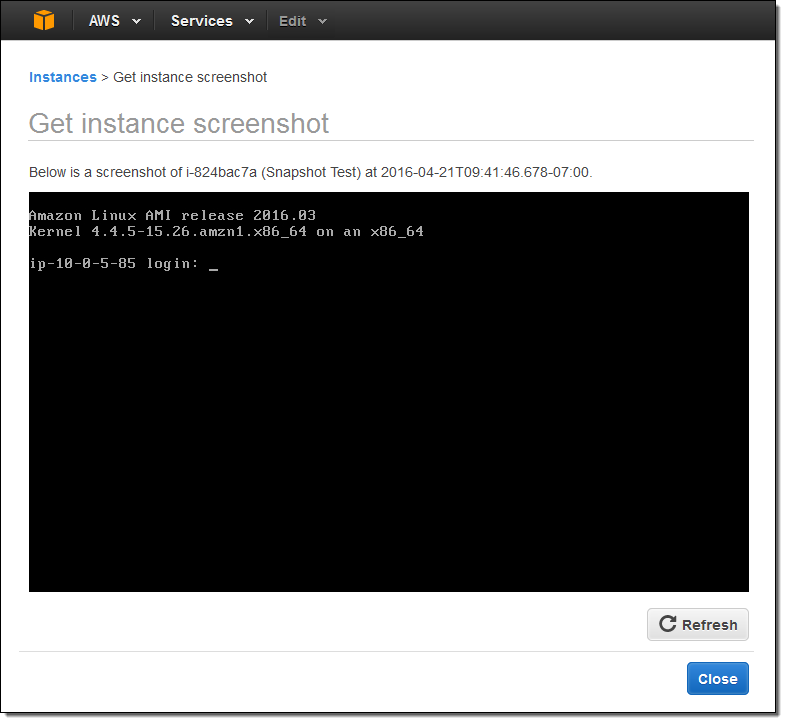
Windowsインスタンスでも使用することができます:
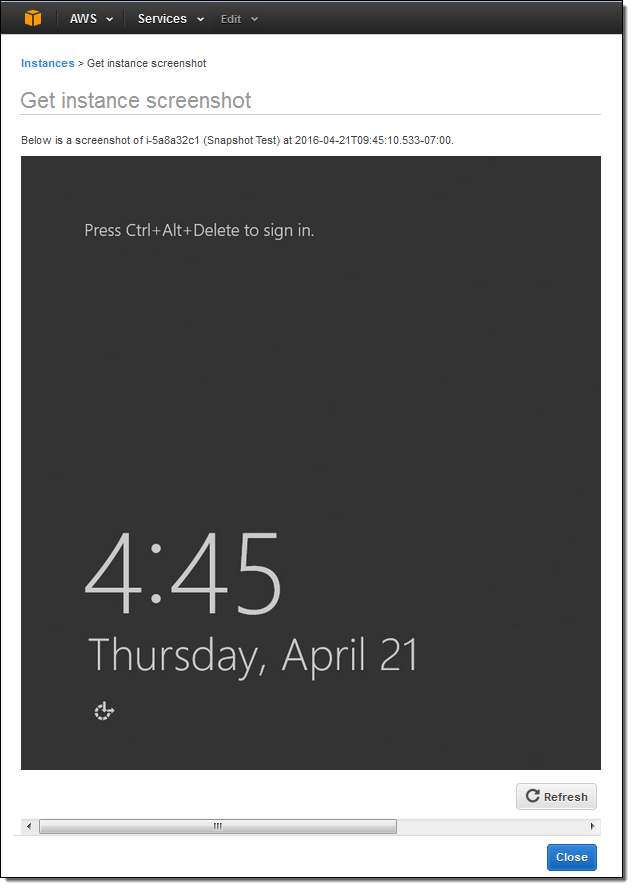
CLI (aws ec2 get-console-screenshot)またはEC2 API(GetConsoleScreenshot)を使用してスクリーンショットを作成することもできます。
いますぐ利用可能
この機能は本日から米国東部(北バージニア)、米国西部(オレゴン)、米国西部(北カルフォルニア)、ヨーロッパ(アイルランド)、ヨーロッパ(フランクフルト)、アジアパシフィック(東京)、アジアパシフィック(シンガポール)、アジアパシフィック(シドニー)、そして南アメリカ(ブラジル)リージョンで利用可能です。これに関連する追加コストはありません。
— Jeff;
翻訳はSA渡邉(@gentaw0)が担当しました。原文はこちら。
EC2のX1インスタンス – メモリー重視のワークロードに対応可能
多くのAWSのお客様はメモリー性能を必要とするビッグデータ、キャッシング、および分析系のワークロードを実行しており、増え続けるメモリー量に対応したEC2インスタンスについてのご要望をいただいていました。
昨年の秋、初めて新しいインスタンスタイプX1についての計画をお伝えしました。今日、このインスタンスタイプのインスタンスサイズx1.32xlargeが利用可能になったことを発表します。このインスタンスの仕様は以下です:
- プロセッサー: 2.3GHzの4 x Intel™ Xeon E7 8880 v3 (Haswell) – 64コア / 128 vCPUs
- メモリー: Single Device Data Correction (SDDC+1)を実現した1,952 GiB
- インスタンスストレージ: 2 x 1,920 GB SSD
- ネットワーク帯域幅: 10 Gbps
- 専用のEBS帯域幅: 10 Gbps (デフォルトでEBS最適化、追加料金不要)
Xeon E7 プロセッサーはターボ・ブースト2.0(最大3.1GHzまで)、AVX 2.0、AES-NI、そして非常に興味深いTSX-NI命令をサポートしています。AVX 2.0(Advanced Vector Extensions)は、HPCやデータベース、ビデオ処理といったワークロードの性能を向上できます; AES-NIは、AES暗号化を使用するアプリケーション速度を向上します。新しいTSX-NI命令は、トランザクションメモリーと呼ばれる素晴らしい機能をサポートします。この命令は、並列性が高いマルチスレッドアプリケーションにおいて、メモリーアクセスを必要としたときに行われる低レベルのロックとアンロックの数を削減することで、非常に効率的な共有メモリーの使用を可能とします。
X1インスタンスは、米国東部(バージニア北部)、米国西部(オレゴン)、欧州(アイルランド)、欧州(フランクフルト)、アジアパシフィック(東京)、アジアパシフィック(シンガポール)、そしてアジアパシフィック(シドニー)リージョンで準備ができており、利用申請をしていただければできるだけ早く稼働させようと思っています。また、あまり遠くない将来に、X1インスタンスを他のリージョンで、および他のインスタンスサイズを提供する計画があります。
米国東部(バージニア北部)リージョンの場合、3年契約の一部前払いで1時間あたり3.970ドルでご利用いただけます; 詳細な情報はEC2の料金ページをご覧ください。今日時点で、リザーブドインスタンスとDedicated Host Reservationsを購入することができます; スポット価格は短期的なロードマップにあります。
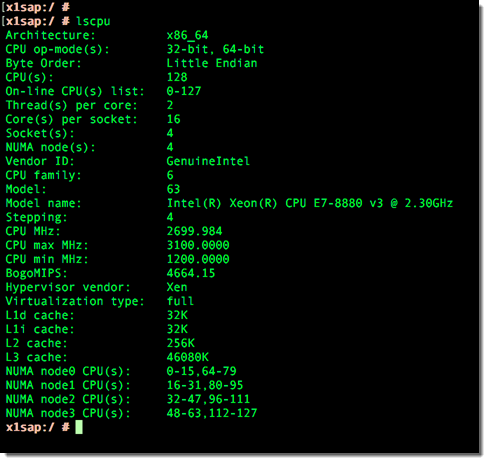
x1.32xlargeが動いているスクリーンショットをいくつか記載します。lscpuで4ソケットにわたり128vCPUsが搭載されていることが表示されています:
システム起動時のカーネルがアクセス可能な総メモリーです:

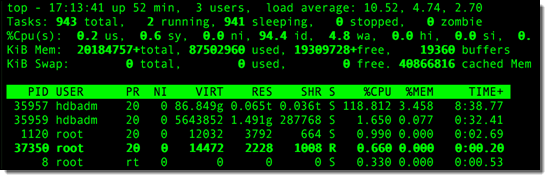
topコマンドでは膨大な数のメモリーとプロセスが表示されています:
エンタープライズ規模のSAPワークロードに対応可能
X1インスタンスは、本稼働ワークロードにおけるSAP認定を取得しています。SAP HANAに必要とされるSAP OLAPとOLTPの両ワークロードの性能要件を満たしています。
お客様は、オンプレミスからAWSに移行できますし、もちろん新規構築することもできます。次世代ビジネススイートSAP S/4HANA、または以前のバージョンのどちらも稼働させることができます。
現在、多くのAWSのお客様が、複数のR3インスタンスを並べたスケールアウト構成でSAP HANAを稼働させています。これらのワークロードの多くは1台のX1インスタンスで実行できるようになります。この構成であれば、構築も容易で、運用コストも抑えられます。後述していますが、構成オプションの詳細情報は最新のSAP HANA Quick Start にて提供いたします。
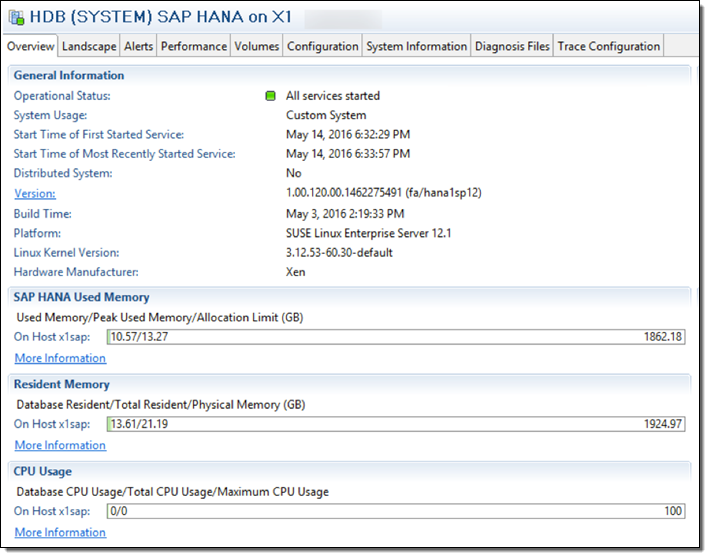
X1インスタンスで実行された環境をSAP HANA Studioでみると次のようになります:
X1インスタンスでSAP HANAを稼働させる場合、災害対策(DR)や高可用性(HA)においても複数の興味深いオプションがあります。例えば:
- 自動リカバリー – RPO (Recovery Point Objective)とRTO(Recovery Time Objective)にもよりますが、EC2 Auto Recoveryを使うことでシングルインスタンスで稼働することができるかもしれません
- ホットスタンバイ – 2つのアベイラビリティゾーンでX1インスタンスを稼働し、SAP HANAシステムレプリケーションによって予備インスタンスと同期することができます
- ウォームスタンバイ / 手動フェイルオーバー – プライマリーのX1インスタンスとセカンダリーには永続ストレージが付与された小さなインスタンスで構成することもできます。フェイルオーバーが必要となった場合、セカンダリーインスタンスを停止し、インスタンスタイプをX1に変更し、再起動します。このユニークなAWSならではのオプションであれば、低コストを維持しながら、迅速な復旧が実現できます
今日のローンチにあわせてSAP HANA Quick Startを更新しています。新規のVPCもしくは既存のVPC内に、十分に検証済みのSAP HANAが1時間以内で利用可能です:
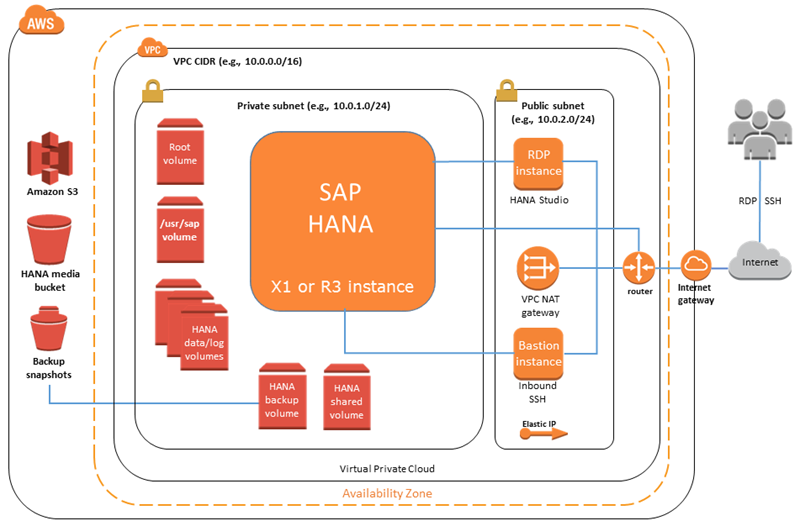
このクイックスタートは 、インスタンスと関連するストレージを構成し、SAP HANAと前提となるOSパッケージをインストールするのにお役立ちいただけます。
また、私たちはSAP HANA Migration Guideも公開しました。現行のオンプレミスもしくはAWS上で稼働するSAP HANAワークロードのAWSへの移行をお手伝いします。
— Jeff;
翻訳はPartner SA 河原が担当しました。原文はこちらです。